基因分类方法与装置与流程
本发明属于基因分类技术领域,具体涉及基因分类方法与装置。
背景技术
基因数据分类是当下信息和决策领域的研究重点和热点问题,由于基因数据具有小样本、高维数、高噪声、高冗余等特点,采用传统数据分析方法可能面临耗费时间较长、分类精度不足等问题。由于基因数据的这些特点,基因数据处理是实现基因表达数据分类高效、准确、可靠的必要步骤。
relieff算法(属性加权算法)是典型的filter方法,是效率较高的维数约简方法,主要用于解决多分类、数据缺失和存在噪声等问题。其核心思想是一种权值搜索的属性子集选择方法,它为每个属性赋予一个权值,这个权值表征了属性与类别的相关性,其思想为好的属性应该使同类的样本接近,不同类的样本之间远离,通过不断调整权值逐步凸现属性的相关程度。例如,吴辰文等撰写的《基于relieff和蚁群算法的基因选择方法》(该论文发表在期刊《计算机应用研究》的2018年第35卷第9期第31页到第35页),该论文中基于特征权重的算法在基因选择时仅能提高标签关联度高的权重,剔除权重值低的基因,不能有效的去除冗余基因。
蚁群算法是一种用于求解组合优化问题的元启发式方法,其思想是模拟生物世界中蚂蚁觅食行为。蚂蚁在搜索食物时,在其走过的路径上释放一种信息激素,以此指导自己和同类的运动方向。当某些路径上走过的蚂蚁越多时,信息素强度就越大,后来蚂蚁选择该路径的概率也越高,从而更增加了该路径的信息素强度。例如,夏亚梅等撰写的《基于改进蚁群算法的服务组合优化》(该论文发表在期刊《计算机学报》的2012年第35卷第2期的第2270页到第2281页),该文章中基于蚁群算法在选择特征时存在收敛速度慢、极易陷入局部最优等缺点。
技术实现要素:
本发明的目的是提供一种基因分类方法与装置,用于解决现有技术无法有效去除冗余或无效基因的问题。
为解决上述技术问题,本发明提出一种基因分类方法,包括以下步骤:
1)根据设定基因的变异系数,采用属性加权算法为基因样本中的每个基因配置权重系数,按照权重系数从大到小的顺序,依次选取前n1个基因,作为候选基因集;
2)利用蚁群算法在所述候选基因集中选取最优子集作为基因子集,并利用该基因子集进行基因分类。
本发明首先设定基因的变异系数,采用属性加权算法初步筛选出前n1个基因作为候选基因集,然后再在候选基因集中进行再次筛选,利用蚁群算法在候选基因集中选取基因子集,有效去除了冗余或无效的基因。
为了避免随意选取基因样本导致配置的权重系数不准确,进一步,步骤1)还包括:
获取基因表达谱数据集,基因表达谱数据集包括m个基因样本,m≥2,每个基因样本包括n个基因;将m个基因样本分成同类基因样本和不同类基因样本,在同类基因样本中,对每种基因挑取样本数据求均值作为对应基因样本实例的值,按照属性加权算法依据基因样本实例对每个基因配置权重系数,得到每个基因在各基因样本中的权重系数。
为了避免训练数据的溢出,另外也能简化规则,更易于用户的理解,还包括对所述候选基因集中的n1个基因进行规则剪枝,保留权重系数大于平均权重系数的基因。
为了提高基因的信息素浓度,信息素会随着时间的流逝被淹没,进一步,步骤1)中每个基因的权重系数的更新公式如下:
式中,a0是原始基因表达谱数据集的基因集,a是筛选后的基因表达谱数据集的基因子集,w[a]为更新后的权重系数,w[a0]为更新前的权重系数,cvnear为同类的最近邻基因样本集合的差异系数,diff(a,xi,h)为基因样本xi与h内各基因样本在基因样本属性a上的差异量化表示,xi为第i个基因样本,h表示与基因样本xi同类的最近邻基因样本集合,m为累积重复次数,k为最近邻样本个数,cvmiss为不同类的最近邻基因样本集合的差异系数,p(c)为目标样本数c占样本总数的比例,mj(c)代表不同类别c中的第j个最近邻样本,p(class(xi))为xi类目标样本数占样本总数的比例,diff(a,xi,mj(c))为基因样本xi与mj(c)内各基因样本在基因样本属性a上的差异化量。
进一步,采用欧氏距离算法分别求取与基因样本xi同类的最近邻基因样本集合,以及与基因样本xi不同类的最近邻基因样本集合。
为了突出反映变量之间相关关系的密切程度,增大相关性大的路径可见度,进一步,所述蚁群算法中采用以下适应度函数在所述候选基因集中选取下一基因:
式中,
为提高重要基因的信息素浓度,防止蚂蚁留下的信息素随着时间的流逝被淹没,所述蚁群算法中采用如下蚁群的信息素更新公式:
τij(t+δt)=(1-ρ)τij(t)+δτij(t)+ω(j)
式中,t为时刻,τij(t+δt)为i基因和j基因更新后的信息素值,δτij(t)为所有蚂蚁走过之后增加的信息素总和,ρ为信息素挥发系数,
为解决上述技术问题,本发明还提出一种基因分类装置,包括处理单元,用于执行实现以下步骤的指令:
1)根据设定基因的变异系数,采用属性加权算法为基因样本中的每个基因配置权重系数,按照权重系数从大到小的顺序,依次选取前n1个基因,作为候选基因集;
2)利用蚁群算法在所述候选基因集中选取最优子集作为基因子集,并利用该基因子集进行基因分类。
进一步,步骤1)中每个基因的权重系数的更新公式如下:
式中,a0是原始基因表达谱数据集的基因集,a是筛选后的基因表达谱数据集的基因子集,w[a]为更新后的权重系数,w[a0]为更新前的权重系数,cvnear为同类的最近邻基因样本集合的差异系数,diff(a,xi,h)为基因样本xi与h内各基因样本在基因样本属性a上的差异量化表示,xi为第i个基因样本,h表示与基因样本xi同类的最近邻基因样本集合,m为累积重复次数,k为最近邻样本个数,cvmiss为不同类的最近邻基因样本集合的差异系数,p(c)为目标样本数c占样本总数的比例,mj(c)代表不同类别c中的第j个最近邻样本,p(class(xi))为xi类目标样本数占样本总数的比例,diff(a,xi,mj(c))为基因样本xi与mj(c)内各基因样本在基因样本属性a上的差异化量。
进一步,步骤1)还包括:
获取基因表达谱数据集,基因表达谱数据集包括m个基因样本,m≥2,每个基因样本包括n个基因;将m个基因样本分成同类基因样本和不同类基因样本,在同类基因样本中,对每种基因挑取样本数据求均值作为对应基因样本实例的值,按照属性加权算法依据基因样本实例对每个基因配置权重系数,得到每个基因在各基因样本中的权重系数。
进一步,还包括对所述候选基因集中的n1个基因进行规则剪枝,保留权重系数大于平均权重系数的基因。
进一步,采用欧氏距离算法分别求取与基因样本xi同类的最近邻基因样本集合,以及与基因样本xi不同类的最近邻基因样本集合。
进一步,所述蚁群算法中采用以下适应度函数在所述候选基因集中选取下一基因:
式中,
进一步,所述蚁群算法中采用如下蚁群的信息素更新公式:
τij(t+δt)=(1-ρ)τij(t)+δτij(t)+ω(j)
式中,t为时刻,τij(t+δt)为i基因和j基因更新后的信息素值,δτij(t)为所有蚂蚁走过之后增加的信息素总和,ρ为信息素挥发系数,
附图说明
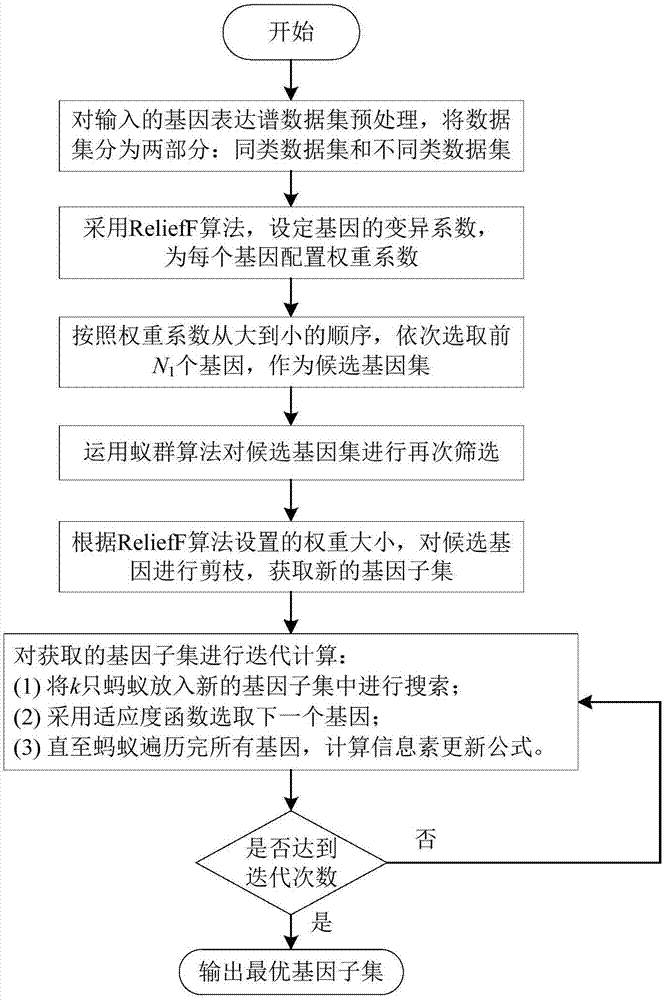
图1是本发明的一种基因分类方法流程图。
具体实施方式
下面结合附图对本发明的具体实施方式作进一步的说明。
本发明的一种基因分类方法,包括以下步骤:
1)根据设定基因的变异系数,采用属性加权算法为基因样本中的每个基因配置权重系数,按照权重系数从大到小的顺序,依次选取前n1个基因,作为候选基因集。
2)利用蚁群算法在所述候选基因集中选取最优子集作为基因子集,并利用该基因子集进行基因分类。
本发明首先对传统属性加权算法进行改进,设定基因的变异系数,采用属性加权算法初步筛选出n1个基因作为候选基因集,然后再在候选基因集中进行再次筛选,利用蚁群算法在在候选基因集中选取基因子集,根据该基因子集进行基因分类,筛选出有病基因和无病基因,有效去除了冗余或无效的基因。
具体的,传统属性加权算法配置每个基因的权重系数。relieff算法(属性加权算法)根据属性的重要性进行次序排列,将高于指定阈值的属性作为属性子集,对于任意一个样本集合x中的实例xi,基本的relieff算法可以表示为:
首先找出k个与xi同类的最近邻的样本实例集合h。设diff(a,xi,h)是n*1的矩阵,表示对象xi与h内各对象在样本属性a上的差异量化表示:
式中j=1,2,…,k。hj为样本实例集合h第j个样本实例。
其次,找出与xi不同类的样本实例中k个最近邻的样本集合m(c)。设diff(a,xi,m(c))是n*1矩阵,xi为在与m(c)内各对象在样本属性a上的差异量化表示:
式中:mj(c)为样本实例集合m(c)第j个样本实例,p(c)为c目标样本数占样本总数的比例,p(c)=c类目标本数/集合x的样本总数,p(class(xi))为xi类目标样本数占样本总数的比例。
具体的属性加权算法参见作者吴辰文等发表的论文《基于relieff和蚁群算法的基因选择方法》所记载的内容。该论文发表在期刊《计算机应用研究》的2018年第35卷第9期第31页到第35页,具体的网址为http://www.arocmag.com/article/02-2018-09-009.html。
为了提高基因的信息素浓度,信息素会随着时间的流逝被淹没,本发明对传统属性加权算法进行了改进,其差异系数被重新定义为:
其中,k为基因个数,
式中,a0是原始基因表达谱数据集的基因集,a是筛选后的基因表达谱数据集的基因子集,w[a]为更新后的权重系数,w[a0]为更新前的权重系数,cvnear为同类的最近邻基因样本集合的差异系数,diff(a,xi,h)为基因样本xi与h内各基因样本在基因样本属性a上的差异量化表示,xi为第i个基因样本,h表示与基因样本xi同类的最近邻基因样本集合,m为累积重复次数,k为最近邻样本个数,cvmiss为不同类的最近邻基因样本集合的差异系数,p(c)为目标样本数c占样本总数的比例,mj(c)代表不同类别c中的第j个最近邻样本,p(class(xi))为xi类目标样本数占样本总数的比例,diff(a,xi,mj(c))为基因样本xi与mj(c)内各基因样本在基因样本属性a上的差异化量。
差异系数进一步减少了计算时的不稳定性,使得在突发情况下依然能有较稳定的结果。同时使相同样本间距离减小,不同样本间的距离增大,使权重区分更加明显。
进一步,也可以采用以下改进的属性加权算法配置权重系数:
首先,要对样本属性权重值做出最有效的评估,必须使选取的累积样本尽量均匀地覆盖于每个样本类别的整个样本数据集中。由于m次迭代使用的样本都是随机选择,即使是同一组训练样本集,每运行一次该算法,算法随机选中的样本点都不可能完全相同,这样造成了权重值波动。
为了避免随意选取基因样本导致配置的权重系数不准确,第一个改进点在于,步骤1)还包括获取基因表达谱数据集的步骤,基因表达谱数据集包括m个基因样本,m≥2,每个基因样本包括n个基因;将m个基因样本分成两部分,即同类基因样本和不同类基因样本。在同类基因样本中,对每种基因挑取多个样本数据求均值作为该基因样本实例的值,按照属性加权算法,依据基因样本实例对每个基因配置权重系数,得到每个基因在各基因样本中的权重系数。
其次,为了找出最近邻的样本实例,第二个改进点在于,采用欧氏距离算法分别求取所述与基因样本xi同类的最近邻基因样本集合,以及所述与基因样本xi不同类的最近邻基因样本集合。欧氏距离是基于合理性计算原理的基础上对真实数据直接进行计算,这种直观的计算使得结果与真实数据的情况更加贴切,量化数据间的差异,因此求得的最近邻基因样本比较直观。
由于基因种类过多,而有关基因数据很少,作为其他实施方式,可以根据relieff算法,排除部分无关基因,按照权重排序取前n1个权重大的基因数据,在一次搜索结束后,对信息素重新排序,并在下一次搜索时,随机选取前n1个权重较大的基因数据,如此可加快收敛速度,排除局部最优解,同时使得运行时间缩减。
上述候选基因集中选取最优子集的过程既可以利用传统蚁群算法,也可以利用改进的蚁群算法。蚂蚁算法(蚁群算法)是一种模拟蚂蚁智能行为的仿生优化算法,没有视觉的蚂蚁运动时会在通过的道路上释放出一种特殊的信息素。其碰到一个未通过的岔口时,就会根据信息素随机挑选一条路径,在行走的过程中持续释放等量的信息素,该信息素会随着时间的推移逐渐挥发,而距离较长的路径的信息素挥发时间相对长,因此其信息素浓度相对较低。蚂蚁算法是指用来描述这一由简单个体组成的群体所表现出的极其复杂的行为特征的方法。
传统蚁群算法的基本规则为:
式中:j∈allowedk,
在蚂蚁留下信息素的同时,为避免因残留信息素过多造成路径上启发信息被淹没,信息素会随着时间的流逝而挥发,设ρ为信息素挥发系数,其中,0≤ρ≤1,t+δt时刻i节点和j节点上的信息素更新规则为
τij(t+δt)=(1-ρ)τij(t)+δτij(t)
上式中:
上式中:q为信息素的强度;lk为第k只蚂蚁在该次循环中经过的距离。
采用如下算法:
输入:训练集d(p*n矩阵),迭代次数i,蚂蚁个数k,每次迭代中蚂蚁选择的属性数量ng;
输出:约简后的训练集d。
s1.信息素
s2.fori:=1tot;ec[i,j](ec为边计数器)初始化为0,任意i,j=1,2,…,n。
s3.蚂蚁放入任意地方,根据状态转换规则,选择下一个基因,即将第k个蚂蚁移至新选择的基因,增加访问边对应的边计数器。
s4.使用适应度函数评估所选特征子集,寻找全局最优解。
s5.应用信息素更新规则更新信息素值,进行下一次迭代,在迭代中保持全局最佳子集。
s6.满足迭代次数时输出全局最佳子集。
具体的蚂蚁算法见作者夏亚梅等发表的《基于改进蚁群算法的服务组合优化》记载的内容,该论文发表在期刊《计算机学报》的2012年第35卷第2期第2270页到2281页。
改进的蚁群算法包括三个改进点,使用时可以采用如下任意一个或几个改进点:
第一个改进点在于,在选取n1个基因作为候选基因集后,需要对候选基因集中的n1个基因权重剪枝,保留权重大于平均值的基因,使得运算速度更快。该平均值是所有基因的权重系数的平均值,作为其他实施方式,也可以设定一个阈值,选择权重系数大于设定阈值的基因。
在待选基因的概率分布公式中,
式中,
为了减少了计算时的不稳定性,使相同样本间距离减小,不同样本间的距离增大,第三个改进点在于,蚁群算法中采用如下蚁群的信息素更新公式:
τij(t+δt)=(1-ρ)τij(t)+δτij(t)+ω(j)
式中,t为时刻,τij(t+δt)为i基因和j基因更新后的信息素值,δτij(t)为所有蚂蚁走过之后增加的信息素总和,ρ为信息素挥发系数,
引入权重后,使得信息素的浓度计算更加精准,并尽可能排除了差异数据的干扰。使运算过程更具有稳定性,运算结果更加准确。
具体的,以肿瘤基因选择为例,首先采用relieff算法计算权重筛选出与类别标签相关性强的基因,进行降序排列,根据排序结果过滤掉无关基因,选择与分类属性相关度较高的数据作为候选基因集,再利用蚁群算法进行规则剪枝,迭代进行,最终获得基因个数最少,分类准确率最高的基因集合作为最优解,为确保实验结果的稳定性及可靠性,采用改进的c4.5(c4.5是用于产生决策树的算法,产生的决策树可以被用作分类目的)计算精确度,算法流程如图1所示,其具体步骤如下:
输入:原始基因表达谱数据集set;
输出:基因集合s。
p1.对原始基因数据进行预处理,即将set的初始值设置为0。
p2.采用改进的relieff算法的权重公式对每一个基因的权重进行计算,根据权重大小,进行降序排列。
p3.按排列顺序,去除冗余基因,获得与分类属性关联度较高的预选基因子集。
p4.定义新的规则,进行规则剪枝,除去规则外数据,把蚂蚁随机放入一个基因;relieff算法能够处理大量实例的高维数据集,但不能去除属性之间的相关度高的冗余属性,利用蚁群的剪枝规则,依据属性之间的相关度进行剪枝筛选,是去除冗余属性的一种精确的筛选方法。
p5.将k只蚂蚁随机放入基因。
p6.按照本发明的概率公式计算待选基因的概率分布,选择下一个基因,重复p6至蚂蚁完成各自的周游。
p7.利用本发明的信息素更新公式更新信息素,设置迭代次数,通过多次迭代步骤p5至步骤p7,确定最优子集。
p8.分别计算上述方法在测试样本集上的误分率,返回获得的基因子集s。
基于上述步骤进行实验做进一步验证,选用4个基因表达谱数据集colon、leukemia、prostate和lung,均从http://featureselection.asu.edu/datasets.php的网址下载得到,其数据的详细信息如表1所示。
表14个基因表达谱数据描述
由表1可以看出,样本数在63到204之间,基因数在2000到12600之间,是典型的高维度小样本数据,实验目的通过研究样本构建模型,对测试样本进行评估。
利用上述数据,本发明具体的实验过程为:
将relieff算法和蚁群算法结合起来,relieff算法求权重系数,将权重系数作为蚁群算法的基础数据。并且在此基础上经过一系列的改进,达到运行速率快,结果更精确,基因分类更加明显,程序牢固性高的特点。实验主要分为2部分,第一部分是新算法对不同基因数在分类精度上的实验结果;第二部分是不同的基因选择方法在准确率上的比较。
实验环境的操作系统为windows10,intel酷睿i55200u,主频1.50ghz,内存为4.0gb。
第一步,在relieff算法求权重的过程中,在选取每个基因的数据时,我们采用每次循环选取n个随机数据求得平均数作为被测基因,并在权重的计算公式中引入差异系数。
第二步,将relieff算法求得的权重数据放入蚁群算法,进行规则剪枝,在蚁群算法中将alpha系数(即α)为设为relieff算出来的权重的绝对值(即ω),用相似度r来求beta系数(即β),在信息素公式里面引入权重进行计算。
为探究基于relieff和蚁群算法的基因选择方法(relieffandantcolonyalgorithm-basedgeneselectionmethod,rfac-gs)对所选的基因数对分类精度的影响,现给出3种分类算法在3个数据集上的分类性能对比,对原始数据集直接进行分类(originaldatasetprocessing,简称odp),采用支持向量机进行的分类方法(supportvectormachine,简称svm),采用随机森林方法进行分类(randomforest,简称rf)为。各个方法的精确度如表2所示,表中acc表示精确度。
表23个基因表达谱数据集在4种方法下的分类精度结果
由表2可以看出,在lung数据集中,本发明方法的分类正确率为99.5%,远高于其他3种算法的84.62%、86.37%和86.36%;在leukemia数据集中,本发明算法的分类正确率为95.8%,高于其他3种算法的94.44%、94.10%和90.18%;但在prostate数据集中,本发明的分类正确率为89.2%,略低于svm和rf方法,这说明本发明采用信噪比进行无关基因过滤时,错误的过滤掉了对分类影响较大的基因,从而影响了分类正确率。实验结果表明,本发明在3个数据集上都表现出了好的分类效果,不仅能够选择出关联度高、低冗余度的基因子集,而且有效地提高了基因分类算法的正确率。
为了充分证明本发明的有效性,利用本发明提出的基于relieff和蚁群算法的基因选择方法(rfac-gs)与其他三种常用的基因选择方法进行比较,其中,吴辰文等撰写的《基于relieff和蚁群算法的基因选择方法》中提出了relieff采用权值搜素属性子集,调整权值凸显属性相关程度;hallm.a.等发表的《correlation-basedfeatureselectionfordiscreteandnumericclassmachinelearning》(proceedingofthe17thinternationalconferenceonmachinelearning,sanfrancisco,2000:359-366)中提出了基于相关性的特征选择方法(correlation-basedfeatureselection,cfs),采用基于属性与标签相关性的启发式方法来评价属性的重要性;zhangy.等发表的《geneselectionalgorithmbycombiningrelieffandmrmr》(bmcgenomics,2008,9:1-10)提出了基于relief最大相关最小冗余算法(maximumrelevanceminimumredundancy-relief,mrmr-relief),它是一种二阶消除算法,该算法首先应用relieff算法筛选掉权重较低的属性,然后通过冗余度和相关性计算来选择属性子集。实验结果如表3所示。
表33个基因表达谱数据集在4种方法下选择的基因个数
表3给出了四种基因选择算法在三种数据集上所选基因个数。其中本发明利用的基因选择方法所选择的基因个数最少,relieff次之,而mrmr-relief所选基因最多。从三个数据集的运行结果可以看出,改进后的蚁群算法数据结果差异较大,优势显著。本发明利用relieff算法算出来的权重本身就对基因进行了比重上的分类,对其的改进使得权重的计算更加精准,同时权重结果又贴合真实数据。在此基础上,使得蚁群算法搜索更加快速,运行效率高,结果不会脱离真实数据。同时,蚁群算法信息素公式的改进使运算结果更加准确,且具有稳定性,排除了一些差异数据的干扰。
本发明首先对基因数据进行降维,通过改进relieff算法,筛选出与类别标签相关性强的基因,很大程度的进行了降维,在蚁群算法中引入权重和相似度,通过迭代运行,显著提高了基因分类的精度和运行速度以及计算的稳定性。
对应上述基因分类方法,本发明还提出一种基因分类装置,包括处理单元,用于执行实现以下步骤的指令:
1)根据设定基因的变异系数,采用属性加权算法为基因样本中的每个基因配置权重系数,按照权重系数从大到小的顺序,依次选取前n1个基因,作为候选基因集;
2)利用蚁群算法在所述候选基因集中选取最优子集作为基因子集,并利用该基因子集进行基因分类。
上述实施例中所指的基因分类装置,实际上是基于本发明方法流程的一种计算机解决方案,即一种软件构架,可以应用到计算机中,上述装置即为与方法流程相对应的处理进程。由于对上述方法的介绍已经足够清楚完整,故不再详细进行描述。
以上所述仅为本发明的优选实施例,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的权利要求范围之内。
- 还没有人留言评论。精彩留言会获得点赞!