实体关系提取方法与流程
本发明涉及信息抽取技术领域,特别涉及一种实体关系提取方法。
背景技术
关系抽取从纯文本中获取知识三元组是最直接的方法,其原理是通过对于实体对及其所在的句子建模分析后给出准确的关系预测。例如,对句子“stevejobswastheco-founderandceoofappleandpixar”中的“stevejobs”和“apple”进行关系抽取得到的结果应该是知识三元组[stevejobs,founder,apple]。传统的关系提取模型都是基于有监督的学习算法,然而有监督学习的关系抽取方法都需要高质量的人工标注训练集,无法实现完全的关系自动化抽取。为了突破关系抽取中关系类别的限制,stanford的mintz等人在2009年提出了远程监督的方法实现不需要人工标注的关系提取。远程监督的方法是指用现有的知识库作为先验知识进行关系数据集的标注。假设一个知识三元组k在知识库中存在,并且k中的两个实体[a,b]都出现在了句子s中,那么s被标注为知识三元组k的一个实例。远程监督以此构建训练数据,省去了人工标注数据集的工作,并且能够大大的扩展关系提取的边界。然而,远程监督的方法有明显的缺陷,在很多情况下,其基本假设并不成立,也就是会有所谓的错误标注[缺点]问题。例如,在句子“stevejobspassedawaythedaybeforeappleunveilediphone4sin2011”中同样包含“stevejobs”和“apple”,然而该句话并不表达“founder”的关系。为了解决错误标注问题,riedel和hoffmann分别提出了两种多实例学习的解决方案。多实例学习是指将对句子的标注改为对“句袋”的标注,实际训练时以“句袋”中最可能正确标注的句子进行指导训练。在多实例学习的基础上,surdeanu提出了多实例多标签学习,目的给“句袋”标注更多的标签以更加符合实际情况。angeli结合了部分监督的主动学习算法解决远程监督关系提取问题。在此之后,很多学者给出了诸多其他解决方案,例如利用矩阵变换的算法,利用马尔科夫逻辑的算法,等等。
随着神经网络的再次崛起,学者们也不满足于基于词法和语法模式来提取关系特性,关注点转移到充分利用关系的语义特征。最开始的研究工作是将新型的神经网络结构应用在关系抽取的任务中来,例如清华大学刘康团队应用了卷积神经网络在关系分类任务上,并取得了很好的效果。基于卷积神经网络在关系分类方面成功的应用,刘康团队进一步提出了基于卷积神经网络的远程监督关系提取模型pcnn。该模型通过卷积层、piecewise池化层和softmax分类层,提取关系特征并予以匹配相应的关系。pcnn的方法虽然改进了特征提取的方式,但是解决错误标注问题方面仍然用的比较传统的多实例学习算法,因此取得的提升有限,无法体现神经网络语义特征提取的强大能力。因此,随着注意力模型的兴起,清华刘志远团队率先应用注意力模型优化错误标注问题,提出了pcnn+att的模型。该模型在pcnn网络结构的基础上添加了注意力模型。所谓注意力模型指的是最终特征的选择不再均等地考虑所有候选集,而是为不同的候选实例赋予不同的注意力权重。因此,pcnn+att改进了传统多实例学习的解决错误标注问题的方式,通过给“句袋”中的每个句子赋予不同的权重来削弱错误标注问题带来的影响。这种做法的好处是显而易见的,模型将会利用到更多的正样本来提取相应关系的特征。同样利用注意力模型的还有刘康团队,他们利用实体的描述信息生成注意力权重。近一年以来,刘志远团队提出了利用多语言相同关系的特征互补性质实现多语言的关系提取,该模型利用多语言关系特征互相做注意力加权,在标准数据集上取得了不错的成果。此外,很多学者在不同网络结构上做出了很多尝试,比如利用卷积神经网络实现关系分类;构建双向循环卷积网络;对于模型中的误差建模,不同任务互相校验;结合语法树的信息;在句子和词的层面分别应用注意力模型,跨句子的实体关系提取。最近,伊利诺伊大学香槟分校的韩家炜团队提出了实体关系协同抽取的模型cotype;北京大学常宝宝团队提出了“软标签”的关系提取算法。“软标签”方法使得训练数据中的句子标签在训练过程可变,模型会给予更可能对的标签而不完全依照原始标签。
以上实体关系提取的方法均取得了较好的效果,但是仍存在诸多不足。例如,远程监督构造的数据集质量太低。由于知识库的不完整,所以利用知识库生成的负样本的质量非常的低,因此对于关系特征的提取,以及关系提取质量的考核都存在很大问题。
技术实现要素:
本发明的目的在于提供一种实体关系提取方法,以解决使用现有技术中实体关系提取的方法的不足。
为解决上述技术问题,本发明提供一种实体关系提取方法,所述实体关系提取方法包括:
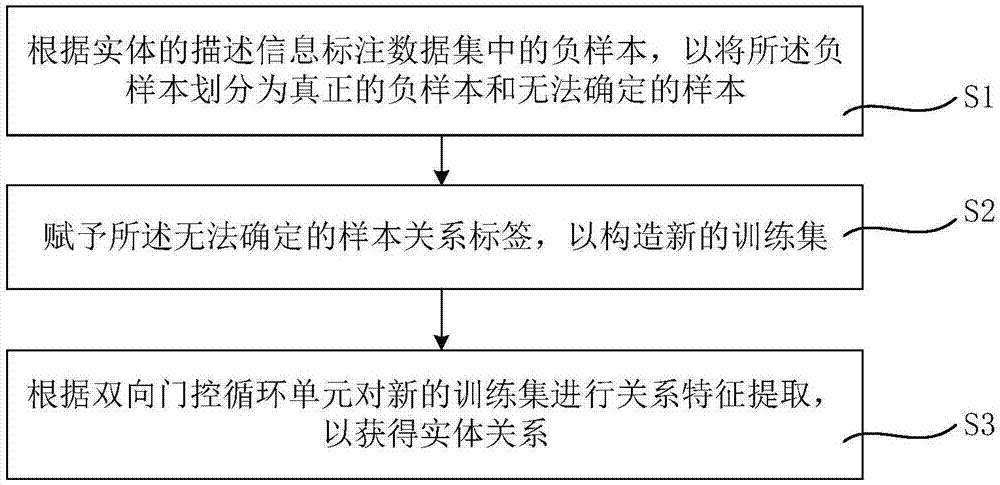
根据实体的描述信息标注数据集中的负样本,以将所述负样本划分为真正的负样本和无法确定的样本;
赋予所述无法确定的样本关系标签,以构造新的训练集;
根据双向门控循环单元对新的训练集进行关系特征提取,以获得实体关系。
可选的,在所述的实体关系提取方法中,所述赋予所述无法确定的样本关系标签的方法如下:
根据对抗生成网络的生成模型给所述无法确定的样本生成关系标签;
根据对抗生成网络的判别模型判断所述关系标签的真伪,并将真的关系标签赋予所述无法确定的样本。
可选的,在所述的实体关系提取方法中,所述赋予所述无法确定的样本关系标签的方法中还包括:
训练所述生成模型和所述判别模型的性能使两者性能都达到最优。
可选的,在所述的实体关系提取方法中,训练所述生成模型和所述判别模型的性能达到最优所采用的优化公式如下:
其中,g代表生成模型,d代表判别模型,pdata(x)描述真的关系标签分布;pc(c)描述生成的关系标签的分布。
可选的,在所述的实体关系提取方法中,所述赋予所述无法确定的样本关系标签的方法如下:
根据实体的类型信息给所述无法确定的样本生成关系标签。
可选的,在所述的实体关系提取方法中,所述根据实体的类型信息给所述无法确定的样本生成关系标签的过程如下:
根据实体的类型信息推断实体对的关系,并将所有推断结果构建为候选关系;
计算所述候选关系的损失函数,最大化整个候选关系的可能概率优化整个关系特征提取网络,以确定最佳的实体对的关系;
根据最佳的实体对的关系给所述无法确定的样本生成关系标签。
可选的,在所述的实体关系提取方法中,所述计算所述候选关系的损失函数采用如下公式:
j(θ)=αjtruth(θ)+βjgen(θ);
其中,
可选的,在所述的实体关系提取方法中,所述负样本为:实体的描述信息中没有互相包含名字的实体对。
可选的,在所述的实体关系提取方法中,根据实体的描述信息标注数据集中的负样本后,标注后的数据集包括正样本、真正的负样本和无法确定的样本。
可选的,在所述的实体关系提取方法中,所述数据集为标准数据集。
在本发明所提供的实体关系提取方法中,所述实体关系提取方法先根据实体的描述信息标注数据集中的负样本,以将所述负样本划分为真正的负样本和无法确定的样本;接着,赋予所述无法确定的样本关系标签,以构造新的训练集;最后,根据双向门控循环单元对新的训练集进行关系特征提取,以获得实体关系。通过根据实体的描述信息标注数据集中的负样本,有效的优化了数据集;通过赋予所述无法确定的样本关系标签来构造新的训练集,以提高训练集的准确性,进而提高了提取实体的关系的精准度。
附图说明
图1是本发明一实施例中实体关系提取方法的流程图;
图2是本发明一实施例中基于nyt和new-nyt,pcnn和pcnn+att在prcurve上的效果比较图;
图3是本发明一实施例中采用本发明方法和对比方法在prcurve上的效果比较图。
具体实施方式
以下结合附图和具体实施例对本发明提出的实体关系提取方法作进一步详细说明。根据下面说明和权利要求书,本发明的优点和特征将更清楚。需说明的是,附图均采用非常简化的形式且均使用非精准的比例,仅用以方便、明晰地辅助说明本发明实施例的目的。
请参考图1,其为本发明的实体关系提取方法的流程图。如图1所示,所述实体关系提取方法包括:
首先,执行步骤s1,根据实体的描述信息标注数据集(将标注前的数据集简称为nyt)中的负样本(此时,标注后形成新的数据集,后续称为new-nyt),以将所述负样本划分为真正的负样本和无法确定的样本;
接着,执行步骤s2,赋予所述无法确定的样本关系标签,以构造新的训练集;
接着,执行步骤s3,根据双向门控循环单元对新的训练集进行关系特征提取,以获得实体关系。
针对s1,经研究发现,原始的自动关系抽取方法中数据集的构建都是基于知识库,包括对于负样本的生成。负样本的生成逻辑为,不在知识库中记录的实体对,即为没有关系的负样本。然而知识库高度不完整,实际上未在知识库中记录的实体对可能具有某种关系,知识尚未被收录到知识库。因此,传统方法生成的负样本包含了大量噪音。
通常,当两个实体对包含某种关系时,实体对中的两个实体的描述信息(来自于wikipedia)里通常会包含对方。基于此项观察,本发明在研发阶段统计了正样本中,描述包含彼此的实体对数量,发现96.3%的正样本符合此项规律。因此,可以推断出正样本的实体描述信息通常会互相包含名字,那么该命题的逆反命题同样成立,也即实体描述没有互相包含名字的实体对通常会是负样本。基于这个大概率成立的假设,重新标注了原始数据集,将标注后的原始数据集分割成三份:正样本不变,负样本分为真正的负样本和无法确定的样本。
具体的,s2中,所述赋予所述无法确定的样本关系标签的方法可以选取如下两种方式中的任一种:
方法1(wds-gan):根据对抗生成网络(也称神经网络模型,简称为gan)给无法确定的样本生成正确的关系标签(即真的关系标签)。
具体的,神经网络模型(或对抗生成网络)包括判别模型d和生成模型g,方法1的核心即为利用对抗生成网络的生成模型给所述无法确定的样本生成关系标签;利用对抗生成网络的判别模型判断所述关系标签的真伪,并将真的关系标签赋予所述无法确定的样本。本方法通过最大最小博弈算法训练判别模型d和生成模型g这两个模型,力争最大化生成模型的生成关系标签的能力的同时,也最大化判别模型判别生成的关系标签真伪的能力,最终达到平衡态时,生成模型和判别模型的性能都达到了最优。
其中,训练所述生成模型和所述判别模型的性能达到最优所采用的优化公式如下:
式子中,g代表生成模型,d代表判别模型,pdata(x)描述真的关系标签分布;pc(c)描述生成的关系标签的分布。
方法2(wds-type):根据实体的类型信息给所述无法确定的样本生成关系标签。
方法2具体包括如下步骤:
s2.1,根据实体的类型信息推断实体对的关系,并将所有推断结果构建为候选关系;
s2.2,计算所述候选关系的损失函数,最大化整个候选关系的可能概率优化整个关系特征提取网络,以确定最佳的实体对的关系;其中,计算所述候选关系的损失函数采用如下公式:
j(θ)=αjtruth(θ)+βjgen(θ);
其中,
s2.3,根据最佳的实体对的关系给所述无法确定的样本生成关系标签。
为了较好的理解方法2的方案,下面结合实例进行说明:通常,抽取的关系可以表示为[a,r,b],其中r为关系,a和b分别称之为关系的头尾实体。在大部分知识库里,关系的头尾实体的类型信息是被严格定义的。例如,关系“organization/founder”的头实体类型必须是“founder”,而尾实体的类型需要是“organization”。同样地,实体的类型信息在知识库中也有定义。因此,可以根据实体的类型信息推断实体对的关系,例如,当实体对[a,b]的类型信息中有符合关系r的头尾实体类型信息时,该实体对[a,b]很有可能是关系r的一个实例。当然,同样的实体可以被定义多个类型信息,如“person”,“founder”,“professor”等等。因此,根据实体的类型信息推断出来的关系可能包含多种关系,将这些可能的关系放在一起称为候选关系。基于实体的类型信息生成的关系标签,构造了更加准确的训练集,进而通过双向门控循环单元(bgru)进行关系特征提取,在此基础上进行进一步的关系抽取。但是值得注意的是,候选关系集合并非单一关系,因此在进行关系特征提取时需要特殊处理候选关系的损失函数,目的是通过最大化整个候选关系的可能概率优化整个关系特征提取网络。
为了验证本发明的实体关系提取方法的准确性,发明人在业内标准数据集上做了多组对比试验。具体在所有数据集、评价标准、对比方法和实验效果等四个方面阐述本发明的实体关系提取方法的有效性。
数据集:原始数据集(即实体的描述信息标注的数据集)是业内标准数据集nyt-10(newyorktime),该数据集由纽约时报上3年的文章构成需要标注的句子,并用知识库freebase进行标注。
具体流程为:1)在纽约时报官网上抓取三年的所有文章,并且分成70万左右的句子;2)利用斯坦福的命名实体标注工具标注出所有的命名实体;3)将一句话中的两个命名实体构成一个实体对,通过在知识库freebase中寻找该实体对的关系,然后为包含这个实体对的所有句子标注上相应的关系。最终形成关系数为53,句子数为74万左右的数据集,包括16万的正样本和58万负样本。
在nyt-10中有16万正样本,其余均为负样本,然后经过基于实体描述的自动化标标注之后,发现有多达34万的负样本并不准确,因此本发明所构造新的数据集new-nyt数据集,新的数据集包含53类关系,16万正样本,24万负样本以及34万不确定样本。
评价标准:采用自动化的评价标准,通过逼近生成数据集中的关系分布来衡量关系提取模型的准确性。主要评价指标有准确率-召回率曲线(prcurve)和前n条预测的准确率(p@n)。前者衡量方法在整个测试集上表现出的性能,后者关注在高置信度区域的方法有效性。
对比方法:主要的对比对象为pcnn及pcnn+att两种方法。前者通过卷积神经网络提取关系特征,在nyt-10上取得了较好的效果。后者是对前者的一个改进,在卷积神经网络基础上添加了注意力模型,同样在nyt-10上取得了当前最好的效果。
实验效果:
从以下几个角度证明本发明的实体关系提取方法的有效性:重构数据集new-nyt的有效性;本发明的方法和对比方法比较在prcurve上的有效性;本发明的方法和对比方法比较在p@n上的有效性。
1)new-nyt的有效性:
如图2所示内容可知,在新的数据集new-nyt上,传统方法pcnn和pcnn+att都在prcurve上取得了较好的效果,比原始数据集有显著的提升。
同时,对于模型在两个数据集上的结果中高置信度的部分(置信度前300条)进行手动标注,发现new-nyt更贴近真是情况,因此重新标注的new-nyt是更好的数据集。
2)pr(precision-recall)curve:
利用新的数据集new-nyt,发明人测试了对比方法及自己方法在prcurve上的效果,具体如图3所示:
图3中,wds-gan和wds-type是本发明生成关系标签的两种方法,pcnn和pcnn+att是对比方法,pcnn+att+u是略作改进的对比方法,改进的方法是将不确定数据标注成负样本加入训练集。从图3中可以明显看出本发明的两个方法优于所有对比方法。wds-gan和wds-type的准确率在全召回率上高于pcnn和pcnn+att。即便是和改进的对比方法pcnn+att+u相比,本发明的两个方法在高召回率,例如r>0.25,上有非常明显的优势。量化到prcurve的面积上,对比方法中最好的pcnn+att的prcurve的面积是0.51,本发明方法最优面积为0.55,提高了7.8%。
3)p@n:
为了量化本发明方法的效果,本发明分别测量了置信度前100、200和300个预测的准确度。同时,为了说明本发明方法在同实体对下不同句子数量的影响,将测试集构造成one、two、all三种设置。one测试集里面的实体对分别只有一个句子,two测试集里面的实体对有两个不同的句子表示,all数据集里的实体对保留了所有句子。具体实验结果如表1所示:
表1:本发明方法和对比方法在p@n上的效果对比表
从表1可以看出,方法wds-gan和wds-type整体上优于所有的对比方法,并有较大幅度的提升。另一方面,本发明的方法,尤其wds-type在整体的准确率上已经到到非常高的标准,在各类测试集上p@100甚至达到97%。
综上,在本发明所提供的实体关系提取方法中,所述实体关系提取方法先根据实体的描述信息标注数据集中的负样本,以将所述负样本划分为真正的负样本和无法确定的样本;接着,赋予所述无法确定的样本关系标签,以构造新的训练集;最后,根据双向门控循环单元对新的训练集进行关系特征提取,以获得实体关系。通过根据实体的描述信息标注数据集中的负样本,有效的优化了数据集;通过赋予所述无法确定的样本关系标签来构造新的训练集,以提高训练集的准确性,进而提高了提取实体的关系的精准度。
上述描述仅是对本发明较佳实施例的描述,并非对本发明范围的任何限定,本发明领域的普通技术人员根据上述揭示内容做的任何变更、修饰,均属于权利要求书的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!