一种基于大规模网络进行高效聚类方法与流程
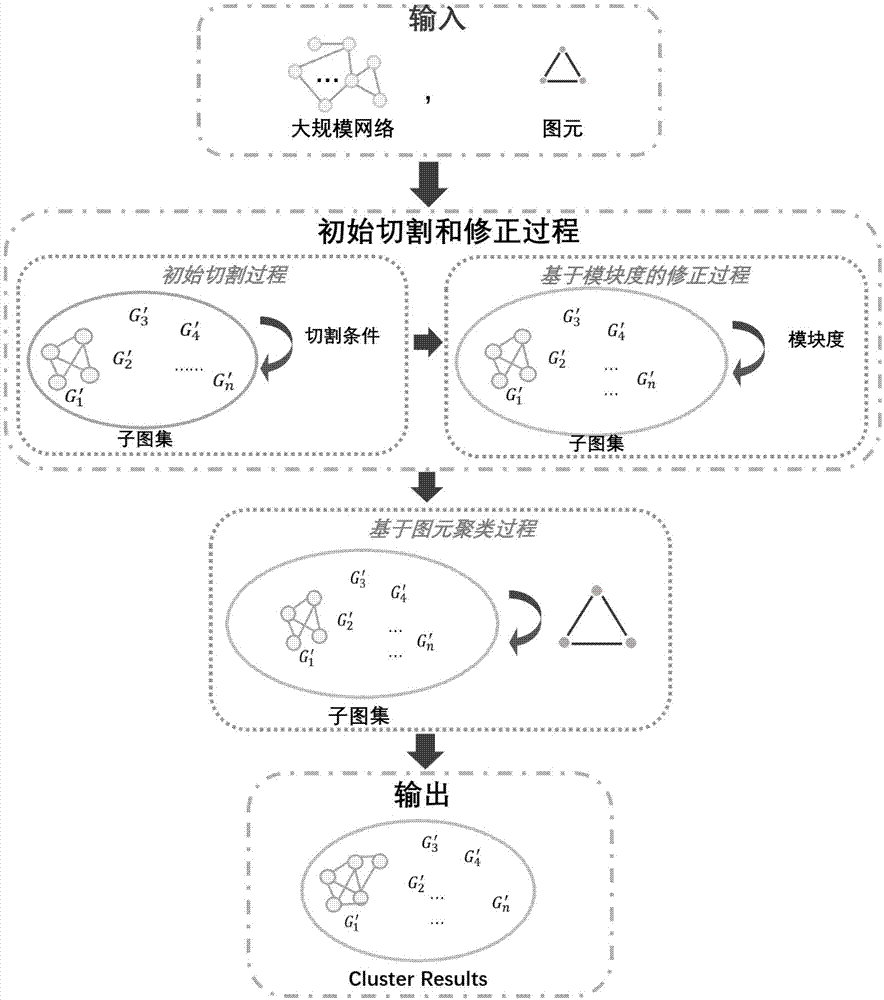
本发明涉及网络科学领域中一种基于大规模网络进行高效聚类方法,尤其涉及一种基于网络高阶图元的高效大规模网络聚类方法。
背景技术
人类行为和社会关系的复杂化使得数据规模不断增大,不同的社会个体、智能设备以及其间的复杂联系构成了复杂的大规模网络。网络规模的日益增大使得网络聚类关系挖掘面临着效率低的问题,并且冗余数据对于网络有效关系的挖掘造成了干扰。聚类算法k-means和gspan难以满足大规模网络聚类问题中对于高效性和准确性的要求。因此,高效率和高精度的大规模网络聚类方法有待于研究人员的进一步探索。
技术实现要素:
本发明的目的主要针对现有研究的一些不足之处,提出基于高阶图元的大规模网络聚类系统,通过将大规模网络的连接特性基于聚类网络的四个条件进行初始切割处理以提高聚类效率,并且首次将三角图元作为网络聚类的最小单元对子图网络进行并行聚类,降低网络维度,提高聚类效率,为大规模网络聚类提供了一种新思路。
本发明的技术方案:
一种基于大规模网络进行高效聚类方法,步骤如下:
(1)根据聚类结果要求的不同,确定网络划分的条件;给出四个条件,包括节点和子图两个方面的连接属性,并根据选择的条件对大规模网络进行初始切割,得到网络切割之后的子图集合;
对于大规模网络划分过程中充分考虑节点和划分得到的子图的连接标准,即节点划分归属问题考虑节点和子图的两方面的连接属性;
对于无向无权网络g=(v,e),定义网络邻接矩阵为h={hi,j}n×n,定义
条件一:
条件二:
条件三:
条件四:
条件一和条件二从节点方面保证某子图内部节点具有高度的内聚性,条件三和条件四从子图的整体角度对子图分割进行限制;条件一把网络切割成许多规模较小的子图,而条件四则最终生成少量规模较大的子图;条件二和条件三则的切割结果则介于以上二者之间;根据具体聚类结果的要求不同,对条件进行选择;
针对选定的切割条件,采用启发式策略,选取网络中度最大的节点作为根节点,并对其邻居节点根据切割条件进行迭代归属划分,最终得到给定输入网络子图;
当某一次迭代结束,分为两种情况:第一种无候选节点,即上一次划分的节点没有未划分的邻居节点,此时则在原网络中选择一个新的根节点,该节点需满足,节点与新子图连接的边数占其总边数的1/2,且节点度最大;此时,则继续迭代;另一种情况,没有新的子图产生,则整个迭代过程结束;
(2)根据模块度的概念,对步骤(1)中得到的子图集进行合并优化处理,使得网络划分的子图集的模块度最大化;
根据步骤(1)中得到的网络子图集,利用模块度对子图划分结果进行优化处理;模块度是社区发现问题中,衡量网络社区划分的指标,定义如下:
其中,i和j代表网络中的两个节点,hi,j为g的邻接矩阵中的值;当节点i和节点j被划分到同一个子图sisj=1,否则,该值为-1;
通过将步骤(1)中的任意两个子图进行循环合并求解模块度,若模块度增长,则将两子图进行合并,否则继续循环;最终得到模块度最大的网络划分;
(3)将步骤(2)中得到的子图集合进行基于高阶三角形图元的聚类处理,利用网络传导率,低传导率被划分为两个子图,得到最终的聚类结果;
步骤3):步骤2)中的得到的子图集是基于网络节点的连接特性进行初始划分,该集合包含若干规模较大的子图,并不能满足聚类的细粒度要求;
(3.1)根据传导率的概念基于三角形图元对网络建模降维,首先定义图元m,方法中运用二元组m(b,a)表示图元,其中a是网络节点集合,xa是一个选择函数,set(·)表示将(有序)元组表示为(无序)集合的一种运算符。可以表示为set((v1,v2,…,vk))={v1,v2,…,vk},表示将节点组(v1,v2,…,vk)无序化为{v1,v2,…,vk}的过程。因此对于一个图元可以定义表征如下:
m(b,a)={set(v),set(xa(v))|v∈vk,v1,v2,…,vkdistinct,av=b}
根据m(b,a)对网络图元的表征,构建网络基于图元的网络邻接矩阵wm,对角矩阵dm,拉普拉斯矩阵lm以及归一化的拉普拉斯矩阵
lm=dm-wm
(3.2)本步骤中首先计算输入网络对应的归一化的拉普拉斯矩阵
(3.3)此步骤主要是对2)中的子图集进行并行化聚类。步骤3.2)将对应网络的节点进行排序,因此,按照此顺序,该过程将序列化的网络节点依次添加到新的子图中,并计算传导率,从最小的传导率节点处将输入子图进行切割,得到最终的大规模网络聚类集合。
对于给定网络g和三角形图元m,基于图元的传导率定义如下:
其中,
本发明的有益效果:本发明采用了给出了一系列基于节点和簇的连接特性的网络切割算法对大规模网络进行初始切割处理,以提高网络聚类效率。通过进行基于网络图元传导率的谱聚类过程,充分考虑了网络全局性连接关系,并且运用图元代替节点作为网络分析的最小单元对网络进行聚类分析,对于网络聚类提出了结构上的连接要求。实验验证了本聚类方法的高效率和精确性。本发明提供了大规模网络聚类的一种新高效方法,为大规模网络数据关系挖掘提供了一种新的解决方案。
附图说明
图1为本发明的整体系统结构,包括三个子过程,大规模网络初始切割过程,基于模块度的子图集合修正过程以及基于高阶图元的聚类并行过程。
图2为本发明中基于高阶图元的聚类并行过程的详细计算过程,此过程基于高阶图元对网络进行降维表征,计算邻接矩阵,对角矩阵以及拉普拉斯矩阵,并结合了谱聚类的核心思想,针对最小传到率对网络子图进行聚类操作。
图3为不同规模学术网络数据集通过不同的聚类方法得到的簇节点的内聚性compactness(cp),证明了本方法得到学术合作网络的聚类结果具有高度的内聚性,可以得到低cp值的聚类结果。
图4为不同facebook数据集通过不同方法得到的聚类结果的cp值,验证了本方法在社交网络中的聚类结果的精确性。
图5为不同规模学术网络数据集通过不同的聚类方法得到的簇节点的分离性separation(sp),表明了本方法得到的学术网络的聚类结果各个簇之间具有较大距离,具有较大的sp值,验证了聚类结果的精确性。
图6为不同facebook数据集通过不同方法得到的聚类结果的sp值,同样具有较大的sp值,因此验证了聚类方法的有效性。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面将对本发明的具体实施方式作进一步的详细描述。
本发明实例提供了一种基于网络高阶图元的高效大规模网络聚类方法,该方法包括:
步骤1:选择真实可聚类的数据集,基于四个条件对初始输入网络进行切割。
学术大数据领域:分别提取美国物理协会aps学术数据集(2009-2013)和微软mag计算机学科(1980-2015)数据集中学者合作信息,构建大规模学者合作网络。aps数据集包括159724名学者的96908篇论文,mag数据集包括社交网络领域:选择facebook的八个不同领域的社交网络,详细信息如表1所示。
表一facebook数据集信息
tab.1informationoffacebookdataset
1.1)对aps和mag数据集数据规模较大,本实验中,为了验证方法的高效性,按照年份对数据集进行分类,得到不同大小的子数据集,以此来构建不同规模的网络,节点数分别为1000,3000,10000,30000,50000,80000,120000,150000。facebook社交网络则按照网络领域直接作为输入。
1.2)利用数据集中的节点和边信息构建网络,如图1所示的系统架构,首先对输入网络进行基于点连接性的切割,来降低网络规模。限制条件越少时间消耗越少,本次试验中将四个条件作为最大时间消耗的输入,进而通过与其他聚类算法进行时间消耗对比来验证方法高效性。
步骤2:通过步骤1)中得到的子图集,根据模块度对子图集进行修正优化,本修正优化过程中可能不会使1)中的结果集产生很大的变化,甚至可能不变。该修正优化过程如图1所示。
步骤3:根据2)子图集合以及输入表征的三角形图元结构,计算每一个子图的邻接矩阵wm,对角矩阵dm,拉普拉斯矩阵lm以及归一化的拉普拉斯矩阵
通过以上步骤,我们可以以较小的时间消耗得到大规模网络的较准确地聚类结果。
本实验利用簇内连接紧密性compactness和簇间距离separation对网络聚类精度进行验证,如图3,图4,图5和图6所示。
上表为不同规模的aps,mag数据集和facebook数据集在本方法的时间消耗,以及与k-means方法的对比。对比突出了本方法的高效性。
以上的所述乃是本发明的具体实施例及所运用的技术原理,若依本发明的构想所作的改变,其所产生的功能作用仍未超出说明书及附图所涵盖的精神时,仍应属本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!