基于人工智能设备的分层稀疏张量压缩方法与流程
本发明属于人工智能领域,具体涉及一种基于图形的数据的分层稀疏张量压缩方法。
背景技术:
人工智能(ai)处理是近来的热门话题,它既是计算和内存密集型,也要求高性能-功耗效率。使用cpu和gpu等当前设备加速并不容易,许多如gpu+tensorcore、tpu、cpu+fpga和aiasic等解决方案都试图解决这些问题。gpu+tensorcore主要着眼于解决计算密集问题,tpu着眼于计算和数据重用,cpu+fpga/aiasic注重提高性能-功耗效率。
在人工智能处理中,由于神经元激活和权重剪枝,许多数据是零。为了使用这些稀疏性,需要发明一种压缩方法,能通过跳过零神经元或卷积权重来节省计算量和功耗,减少所需的缓存存储空间,并通过不传输零数据来增加dram带宽。
当前虽然有许多类似的解决方案,但是他们只使用单层压缩方案,而这个不具有明显的优势。通过具有两层或更多层的位元掩码,如果高级掩码为0,我们可以轻松地移除高级别的数据,这意味着该分支中的全部为零,但是传统的单层掩码压缩不能够获得此结果。
技术实现要素:
本发明针对现有技术中的不足,提供一种基于图形的数据的分层稀疏张量压缩方法。该方法使用基于瓦片的分层压缩方案,可以很容易地知道哪个瓦片具有所有的零,以将其从管道中移除,这可以消除许多不必要的数据移动并节省时间和功耗。
为实现上述目的,本发明采用以下技术方案:
一种基于人工智能设备的分层稀疏张量压缩方法,其特征在于:
硬件架构包括:主机、前叶引擎、顶叶引擎、渲染器引擎、枕形引擎、颞叶引擎和内存;前叶引擎从主机得到5d张量,将其分为若干组张量,并将这些组张量发送至顶叶引擎;顶叶引擎获取组张量并将其分成若干张量波,顶叶引擎将这些张量波发送到渲染器引擎,以执行输入特征渲染器,并将部分张量输出到枕形引擎;枕形引擎积累部分张量,并执行输出特征渲染器,以获得发送到颞叶引擎的最终张量;颞叶引擎进行数据压缩,并将最终张量写入内存中;
硬件架构中设有分层缓存设计:颞叶引擎中设有l3缓存,颞叶引擎连接到dram内存控制器以从dram内存中获取数据;顶叶引擎中设有一个l2缓存和一个在神经元块中的l1缓存;
在dram内存中,不仅保存神经元表面的存储空间,并为掩码块加上一个元曲面;读取数据时,首先读取掩码,然后计算非零数据的大小,并且只读取非零数据;在高速缓存中,只存储非零数据;处理数据时,只使用非零数据。
为优化上述技术方案,采取的具体措施还包括:
该压缩方法中,数据逐块存储在dram中,每个块具有相同的内存大小,块中的非零行被打包并移动到块的开始部分,块中的所有其他数据都是无用的。
当数据传输到l3缓存时,只有非零的数据会被读取并存储在l3缓存中;位掩码的元曲面也存储在dram中,并在数据之前读取,在颞叶引擎中计算效果数据长度以进行数据读取;当l3缓存向l2缓存发送数据时,解压超级瓦片并将压缩后的瓦片数据发送到l2缓存。
在l2缓存中,数据以瓦片压缩格式进行存储,数据被解压、重组、重新压缩并发送到l1缓存,这些经过压缩的数据被读取并发送到计算机核心,带有位置的未压缩数据存储在寄存器文件中进行处理。
当枕形引擎得到输出结果时,数据被压缩,位掩码和非零数据被发送到颞叶引擎,颞叶引擎进一步压缩数据并将数据发送至dram。
本发明的有益效果是:在人工智能设备中使用这种数据压缩方案,可以节省dram带宽并移除流水线中的数据以及计算单元中的零数据,只将压缩数据存储在缓存中,减少了ai数据的缓存存储,与竞争对手相比,可以获得更高的性能和功效。
附图说明
图1是人工智能特征图。
图2是矩阵乘法图。
图3是人工大脑引擎的流程图。
图4是引擎级架构图。
图5是可扩展架构的细节图。
图6是特征图中的瓦片层次视图。
图7是瓦片和超级瓦片的示例图。
图8是压缩瓦片和超级瓦片的示例图。
具体实施方式
现在结合附图对本发明作进一步详细的说明。
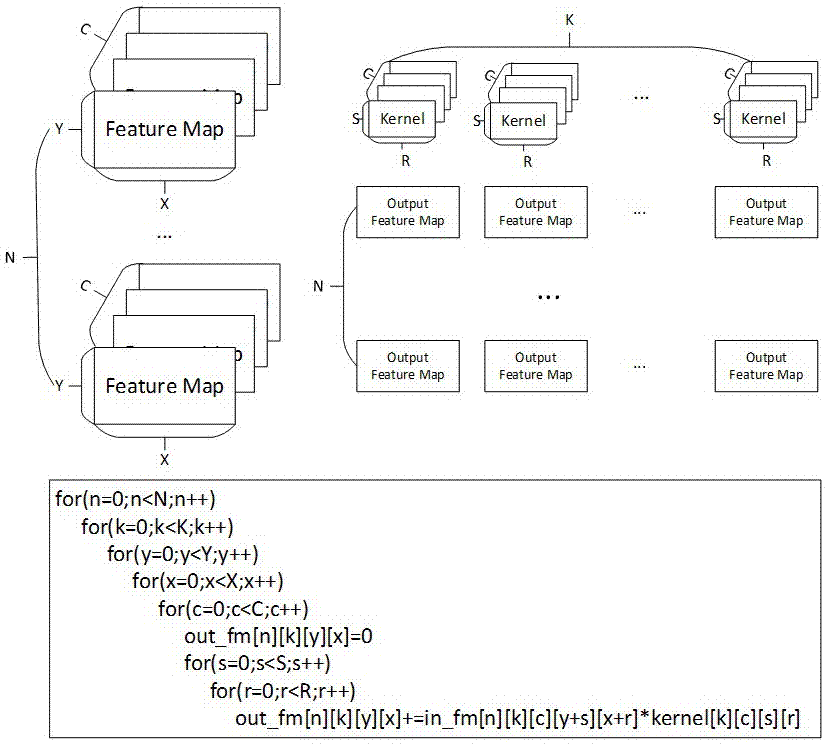
如图1所示,人工智能特征图通常可以描述为四维张量[n,c,y,x]。这四个维度为,特征图维度:x、y;通道维度:c;批次维度:n。内核可以是四维张量[k,c,s,r]。ai工作是给出输入特征图张量和内核张量,我们根据图1中的公式计算输出张量[n,k,y,x]。
人工智能中的另一个重要操作是矩阵乘法,这个操作也可以映射到特征图处理中。在图2中,矩阵a可以映射到张量[1,k,1,m],矩阵b映射到张量[n,k,1,1],结果c是张量[1,n,1,m]。
此外,还有其他的操作,比如规范化、激活,这些可以在通用硬件运算器中支持。
我们提出一个硬件架构来有效地支持这些操作,人工智能工作可以被视为5维张量[n,k,c,y,x],在每一维度中,我们把这些工作分成许多组,每一组可以进一步被分成若干波。在我们的体系结构中,第一个引擎-前叶引擎(frontalengine,简称fe)从主机得到5d张量[n,k,c,y,x],并将其分为许多组张量[ng,kg,cg,yg,xg],并将这些组发送给顶叶引擎(parietalengine,简称pe)。pe获取组张量并将其分成若干波,将这些波发送到渲染器引擎,以执行输入特征渲染器(if-shader),并将部分张量[nw,kw,yw,xw]输出到枕形引擎(occipitalengine,简称oe)。oe积累部分张量,并执行输出特征渲染器(of-shader),以获得发送到下一个引擎-颞叶引擎(temporalengine,简称te)的最终张量。te进行一些数据压缩,并将最终的张量写到内存中。图3为该设计的流程图。
在硬件架构中,有分层缓存设计,图4和图5显示了这些层次结构。在te中有l3缓存,te连接到dram内存控制器以从dram内存中获取数据。在pe中有一个l2缓存,和一个在神经元块中的l1缓存。
在压缩方案中,数据逐块存储在dram中,每个块具有相同的内存大小。例如,大小为16x16x2=512字节,块中的非零行被打包并移动到块的开始部分,块中的所有其他数据都是无用的,并不需要关心它们。当数据传输到l3缓存时,只有非零的数据会被读取并存储在l3缓存中,这意味着l3缓存实际上被放大了。位掩码的元曲面也存储在dram中,并在数据之前读取,在te中计算有效数据长度以进行数据读取。当l3缓存向l2缓存发送数据时,它会解压超级瓦片并将压缩后的瓦片数据发送到l2缓存。
在l2缓存中,数据以瓦片压缩格式进行存储,数据将被解压、重组、重新压缩并发送到l1缓存。这些经压缩的数据会被读取且被发送到计算机核心,而带有位置的未压缩数据存储在寄存器文件进行处理。
当oe得到输出结果时,它将被压缩,位掩码和非零数据将被发送到te,te进一步压缩数据并将数据发送至dram。
该方法使用基于瓦片的分层压缩方案,瓦片层次视图、瓦片和超级瓦片的示例图、压缩瓦片和超级瓦片的示例图分别见图6、图7、图8。因此可以很容易地知道哪个瓦片具有所有的零,以将其从管道中移除,这可以消除许多不必要的数据移动并节省时间和功耗。
在dram中,不保存神经元表面的存储空间,为掩码块加上一个元曲面。但是读取数据时,首先会读取掩码,然后计算非零数据的大小,并且只读取这些非零数据以节省dram带宽。而在高速缓存中,只会存储非零数据,因此所需的存储空间被减少(没有零数据被存储在高速缓存中)。当处理数据时,只使用非零数据。
该方法使用位元掩码来确定数据是否为零,层级压缩方案中有三层:瓦片、线和点。从dram读取位掩码和非零数据,因此通过不读取零数据来节省带宽。处理数据时,若它们的位元掩码为零,能轻松地移除瓦片数据。
我们将此发明用在我们的ai设备中,使用这种压缩方案,可以节省dram带宽并移除流水线中的数据并移除计算单元中的零数据。因此,与竞争对手相比,我们可以获得更高的性能和功效。
需要注意的是,发明中所引用的如“上”、“下”、“左”、“右”、“前”、“后”等的用语,亦仅为便于叙述的明了,而非用以限定本发明可实施的范围,其相对关系的改变或调整,在无实质变更技术内容下,当亦视为本发明可实施的范畴。
以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!