基于遗传优化算法的分阶布料排样方法与流程
本发明涉及染布印染的质量实时监控方法领域,尤其涉及一种基于遗传优化算法的分阶布料排样方法。
背景技术
排样作为服装生产基本环节和重要工序,在服装企业和布料加工厂具有重要的地位,能否做到科学、合理的排样对布料利用率的高低乃至裁剪、缝纫等过程都会造成严重的影响。传统的方法主要借助人工,这种方法不仅效率低下,费财费力,目前借助计算机辅助排样主要依靠经验数据方法、贪婪算法、模拟退火、穷尽算法等算法尝试解决布料排样的问题,布料的利用率不高而且单次计算时间太长。
布料排样问题是一种计算复杂度很高的组合优化问题,具有很高的工程应用价值,采用降阶再优化的方法,可以为布料排样问题提供合理的排样方案,计算速度快,提高布料利用率,从而降低生产成本,提高企业竞争力。
技术实现要素:
为解决上述技术问题,本发明的目的在于提供一种实现多线并行的同时能够准确地对布料进行排样,并且计算速度快、效率高、布料利用率高的基于遗传优化算法的分阶布料排样方法。
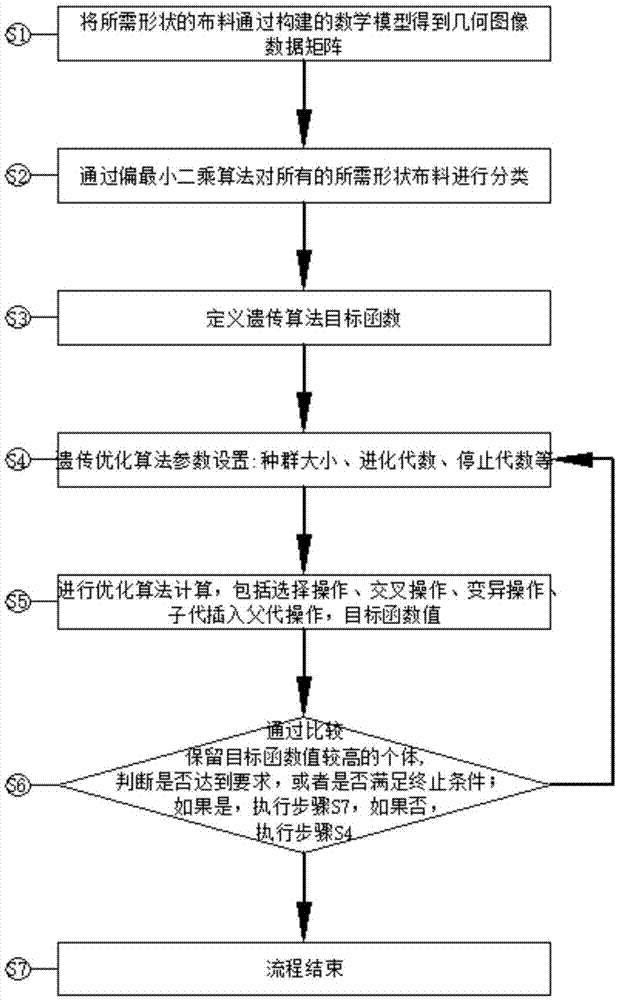
本发明提供的基于遗传优化算法的分阶布料排样方法,包括以下步骤:
s1、将若干排样件和原材料的几何图形通过建构数学模型的方法进行构建;
s2、通过所述步骤s1构建若干所述排样件的几何轮廓数据矩阵,根据若干所述排样件的特点,利用偏最小二乘算法对若干所述排样件进行分类;
s3、定义遗传优化算法目标函数,优化排样问题即布料利用率最大属于最优化问题;
s4、设置遗传优化算法相关参数:种群大小、进化代数、停止代数;
s5、运行遗传优化算法,包括选择操作、交叉操作、变异操作、子代插入父代操作,计算目标函数值;
s6、通过比较保留目标函数值较高的个体,判断是否达到要求或者是否满足终止条件;如果是,执行步骤s7,如果否,执行步骤s4;
s7、流程结束。
进一步的,所述步骤s1中若干所述排样件和原材料的几何图形由直线和曲线组成,所述曲线也可以按一定的精度离散成直线段。
进一步的,所述步骤s1中将若干所述排样件通过建构数学模型的方法转化为几何轮廓数据矩阵的步骤包括:
设g(a)为排样件g旋转角度a后的图形,g(a)最大和最小的x,y坐标值分别为xmax、xmin、ymax、ymin,以间距为1mm的水平扫描线顺序扫描g(a)的多边形区域,经过g(a)的扫描线条数n=int(ymax-ymin),计算扫描线与表变形的相交区间,对于一条扫描线,可以分为四个步骤实现:
①求交点:计算扫描线与过变形各边的交点;
②交点取舍:交点中,如果是多边形的局部最高点或者局部最低点的极值点,交点算作零个或者两个交点,如果是顶点但不是极值点,交点只算一个;
③排序:把所有交点按递增顺序进行排序;
④交点配对:第一个与第二个,第三个与第四个等等,每对交点就代表扫描线与多边形区域的一个相交区间;
因此,所述排样件可以看作是由一系列水平线段区间组成,由于平面坐标中任何图形都只有x,y两个方向,可以用2×n形式的矩阵来表示,得到若干所述排样件的几何轮廓数据矩阵。
进一步的,所述步骤s2中利用偏最小二乘算法即pls对若干所述排样件进行分类,构建回归模型的步骤包括:给定数据自变量x∈rn×p和响应变量y∈rn×1,pls在x,y之间建立的模型为:y=xb+v,b∈rp×q是回归模型系数矩阵,n是自变量矩阵的样本个数,p是自变量个数,v∈rn×1是模型的残差矩阵。
进一步的,若干所述排样件包括矩形或多边形排样件。
更进一步的,所述多边形的排样件面积采用以下公式进行计算:设m边形的顶点是pk(xk,yk),k=1,2,···,m,pm+1=p1(顶点p1,p2,···,pk沿多边形边界正方向排列),多边形排样件g的面积sg可以表示为:
进一步的,所述遗传优化算法目标函数采用的数字模型为:
进一步的,所述遗传优化算法中决定了个体的染色体排列形式以及个体从搜索空间的基因型变换到解空间的表现型的解码方法的染色体编码方法,所述解空间的表现型为若干所述排样件的排样测序和各自的旋转角度,若干所述排样件的旋转角度是通过每一个所述排样件的重心为参考点进行旋转。
进一步的,所述选择操作采用比例选择方法,所述交叉操作采用双点交叉,所述变异操作采用次序变异,形成一个新的个体。
进一步的,对所述步骤s2中利用偏最小二乘算法对若干所述排样件进行分类的方法包括根据若干所述排样件的面积大小和边数进行分类,并对各类别的所述排样件分别采用所述遗传优化算法进行排样优化。
本发明提供的基于遗传优化算法的分阶布料排样方法,具有以下优势:
(1)应用本发明可以实现对布料做到科学、合理的排样,大大的提高布料的利用率,节省了大量人工成本,减少工人的劳动力量,效率高速度快;
(2)采用先对所有排样件分类,分阶段采用遗传优化算法,可以大大提高遗传优化算法的计算效率;
(3)本发明所用的算法充分考虑自变量相互之间、自变量和因变量之间的非线性关系,使得计算结果更加准确。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,并可依照说明书的内容予以实施,以下以本发明的较佳实施例并配合附图详细说明如后。
附图说明
图1是本发明提供的基于遗传优化算法的分阶布料排样方法的流程框图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
参见图1,本发明提供的一种基于遗传优化算法的分阶布料排样方法的一较佳实施例如下。
由于排样问题属于np(非多项式时间问题)完全问题,随着待排样件数量的增加,解空间呈指数倍地放大,会出现组合爆炸现象,即计算时间的无限延长;本发明提出了一种先对待排样件分类降阶,同一类的待排样件可以极大的缩小解空间,再利用遗传优化算法求最优解,从而提高求解效率,减少计算时间。
将所需形状布料几何图形通过建构数学模型的方法,所需形状布料,即排样件,不规则形状的排样件及原材料的几何轮廓由直线和曲线组成,曲线也可以按一定的精度离散成直线段,排样对象最终为可能带有内孔特征或者无效区域的多边形,既可以是凸的也可以是凹的,将排样件通过构建数学模型的方法转化为数据矩阵:
设g(a)为排样件g旋转角度a后的图形,g(a)最大和最小的x,y坐标值分别为xmax、xmin、ymax、ymin,以间距为1mm的水平扫描线顺序扫描g(a)的多边形区域,经过g(a)的扫描线条数n=int(ymax-ymin);计算扫描线与表变形的相交区间,对于一条扫描线,可以分为四个步骤实现:
(1)求交点:计算扫描线与过变形各边的交点;
(2)交点取舍:交点中,如果是多边形的局部最高点或者局部最低点的极值点,交点算作零个或者两个交点,如果是顶点但不是极值点,交点只算一个;
(3)排序:把所有交点按递增顺序进行排序;
(4)交点配对:第一个与第二个,第三个与第四个等等,每对交点就代表扫描线与多边形区域的一个相交区间;
排样件可以看作是由一系列水平线段区间组成,由于平面坐标中任何图形都只有x,y两个方向,可以用2×n形式的矩阵来表示,得到排样件的数据矩阵。
多边形排样件面积采用以下公式:设m边形的顶点是pk(xk,yk),k=1,2,···,m,pm+1=p1(顶点p1,p2,···,pk沿多边形边界正方向排列),多边形排样件g的面积sg可以表示为:
判断待排样件的凸凹性,其方法:假设顺时针任意三个顶点pi-1,pi,pi+1,在以pi-1pi+1直线为x轴的坐标系下,若顶点pi的y坐标为正,顶点pi为凸点,若为负,顶点pi为凹点;带排样件的所有顶点为凸点时,该待排样件为凸面多边形,否则为凹面多边形。
利用pls构建构回归模型如下:给定数据自变量x∈rn×p和响应变量y∈rn×1,pls在x,y之间建立如下模型:
y=xb+v
这里b∈rp×q是回归模型系数矩阵,n是自变量矩阵的样本个数,p是自变量个数,v∈rn×1是模型的残差矩阵。
pls建立模型是基于x,y的主成分分解,其形式:
y=tqt+f
x=tpt+e
这里t∈rn×m是自变量x的主成分矩阵,m是主成分的个数,p∈rp×m和q∈rn×1分别是x和y的载荷矩阵,e∈rn×p和f∈rn×1分别是残余矩阵。
由于自变量x是t的线性组合,因变量y是t的线性组合,可以得到y=f(x),即偏最小二乘算法模型。
排样件的几何轮廓数据矩阵,根据排样件的特点:矩形、凸面多边形、凹面多边形、面积大小等,利用偏最小二乘算法对所有排样件进行分类,对面积均匀、边相对少的一类排样件作为一类,而对面积较大、不规则的和面积较小、不规则的排样件作为一类,剩余的排样件作为一类;分别作为一类分别采用遗传优化算法进行排样优化。
利用偏最小二乘算法模型所有待排样件分成gm,gn,gk,···等多个集合,针对每个不同特点的集合分别构建目标优化函数;构建目标优化函数一般采用下述数学模型:
其中,x=[x1,x2,···,xm]为决策变量,f(x)为目标函数,x∈r和r∈u为约束条件,u是基本空间,r是u的一个子集;针对不同的待排样件集合,结束条件有所不同,也是通过这里设置来降低解空间,以提高计算效率,减少计算时间。
遗传优化算法中染色体编码方法,即排样件的变换,决定了个体的染色体排列形式,还决定了个体从搜索空间的基因型变换到解空间的表现型的解码方法,这里解空间的表现型指的是排样件的排样测序和各自的旋转角度。
对于排样件的变换有两个因素决定,旋转角度和镜像;选择对排样件的重心为参考点对其进行旋转,这样对不同的排样件能够以统一的方法来实现。
变换实现方法如下:对于一个排样件,可以得到其的重心坐标g(xf,yf),其中xf=∑xi/m,yf=∑yi/m,i=1,2,3,···,m,m为排样件顶点数,绕其重心进行旋转变换的公式如下:
由(x,y,1)=(x0,y0,1)tf,可以得到:
x=x0cosθ-y0sinθ+(1-cosθ)xf+yfsinθ
y=x0cosθ+y0sinθ+(1-cosθ)yf-xfsinθ
其中,(x0,y0)为旋转前的坐标,(x,y)为旋转后的坐标,θ旋转角度。
镜像主要是基于x轴和y轴的对称变换。
遗传优化算法中参数设置,选择操作采用比例选择方法,适应度较高的个体被遗传到下一代群体中概率较大;交叉操作采用双点交叉;变异操作采用次序变异,形成一个新的个体。
遗传优化算法中遗传参数设置,种群大小、交叉概率和变异概率采用浮动数值,都随待排样件的数量变化而变化;种群大小m随着待排样件的数量而变化,若有n个待排样件,染色体的每一个基因位长为3,因此m=3n;个体的交叉概率和变异概率与个体适应度成反比,以保证适应度高的个体得以保存而遗传到一代,而适应度低的个体得以改善。
通过比较保留目标函数值较高的个体,判断是否达到要求,或者是否满足终止条件;如果是,执行步骤s7,如果否,流程结束。
综上,排样问题探讨是如何在原材料上科学、合理的布局待排样,在满足订单毛坯需求的情况下,减少原材料消耗,排样的方案直接关系产品的生命周期和生产成本,影响到工厂的生产效率和经济效益;一个较好的排样方案不但可以直接减少材料的浪费,降低材料成本,而且可以简化加工操作、降低制费用,直接给工厂带来经济效益,提高竞争力。
本发明通过构建数学模型从待排样件得到矩阵数据,利用最小二乘法算法根据待排样件的特点进行分类降阶,再利用遗传优化算法求最优解,从而提高求解效率,减少计算时间,相比传统方法,计算速度快,提高布料利用率,从而降低生产成本,提高企业竞争力。
以上仅是本发明的优选实施方式,并不用于限制本发明,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变型,这些改进和变型也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!