基于双循环图的虚假评论检测方法与流程
本发明属于网络安全技术领域,具体涉及基于双循环图的虚假评论检测方法。
背景技术:
大多数电子商务允许用户对其服务和质量进行线上评论,线上评论逐渐成为消费者购物的依据,用户对商店的线上评论将极大地影响该商店的口碑和销售。用户评论在推荐系统方面发挥重要作用,大量真实有效的评论数据能使推荐系统产生有效的推荐,从而给消费者提供正确的商店或产品推荐。
受利益驱使,某些用户会故意撰写与现实不符的评论,即虚假评论,目的在于夸大或诋毁某一家商店,使其获取的利益最大化,甚至出现一些商店雇佣大量网络水军,集中地撰写大量的虚假评论用以提高自身评价或诋毁竞争对手的现象。这些虚假评论对商店的点评系统进行了攻击,直接影响到数据的真实性,对消费者的消费行为进行了误导。相应地,大量的虚假评论对推荐系统作用的发挥也产生了的影响,推荐系统将给消费者提供错误的推荐。通过有效检测虚假评论,过滤虚假评论及其用户,能在一定程度上还原出相对真实自然的评论环境,从而对消费者进行正确的消费引导。因此,实现高效的虚假评论过滤至关重要。
当前针对虚假评论的检测方案主要分为两种:基于评论文本内容的过滤检测系统和基于用户行为特征的过滤检测系统。而基于评论文本内容的虚假评论检测分为三种:基于语法分析的虚假评论检测、基于语义分析的虚假评论检测、基于文本元数据分析的虚假评论检测。其中,基于评论文本内容的虚假检测的方案有局限性,虽然能在众包平台得到的评论数据集上获得较高的准确率,但是由于真实环境下的虚假评论文本在语义、语法上具有较强的迷惑性,与众包平台得到的评论有较大的区别,因此在真实环境的数据集下,基于评论文本内容的检测方式效果有待提高。其次,对评论文本的理解和分析不准确,计算成本高等缺陷增大了文本检测方法的局限性。
而用户自身携带的属性(如用户所拥有的朋友数等)及其行为特征(如最大日评论数、地理位置、个人评价与主流评价之间的评论偏差等)更容易被利用成为虚假用户检测的评估因素,因为虚假用户在这些行为特征方面与真实用户往往有较大的差异。基于行为特征的检测方法主要分为:
基于虚假用户群体行为的检测方法,主要通过对虚假用户间的关系提取群组特征或聚类从而对虚假用户群体进行检测。
基于虚假用户个体的行为检测方法,通过对虚假用户的反常行为特征的检测,也有通过对用户、商店和评论之间的关系构建图结构,通过迭代计算来进行检测。然而由于考虑因素较少,基于图的过滤算法存在着置信度初始值的可信度低、过滤效果欠佳的问题。
综上所述,如何对用户行为特征进行挖掘,得到更好的虚假评论过滤器,在提升虚假评论检测效果方面上有着极其重要的理论与实践意义。
技术实现要素:
为提高虚假评论过滤器对虚假评论的检测效果,本发明的目的是提供一种基于双循环图的虚假评论检测方法,该虚假评论检测方法基于可靠用户和评论置信度数据的循环利用,采用优化用户和商店置信度的方式从而提高虚假评论过滤器的检测效果。
为实现上述发明目的,本发明提供以下技术方案:
一种基于双循环图的虚假评论检测方法,包括:
(1)采用原始图过滤器计算原始评论数据的评论置信度和用户置信度,并对用户置信度进行筛选获得可靠用户;
(2)利用原始图过滤器计算可靠用户对应的评论数据的商店置信度;
(3)将原始图过滤器中的评论置信度更新为步骤(1)获得的评论置信度,利用原始图过滤器计算原始评论数据的用户置信度;
(4)以步骤(2)获得的商店置信度和步骤(3)获得的用户置信度作为初始值,构建加权图过滤器;
(5)利用加权图过滤器计算原始评论数据的商店置信度、用户置信度和评论置信度,根据评论置信度筛选获得虚假评论。
与现有技术相比,本发明具有的有益效果为:
对评论数据进行了循环利用,得到了更为合理的用户和商店置信度初始值。对评论相似集与非相似集进行重新划分,优化了评论一致性。检测方法采用了加权图的方式,合理地增加了用户评论次数相关的权重函数。从而达到了对虚假评论进行检测的效果。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图做简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动前提下,还可以根据这些附图获得其他附图。
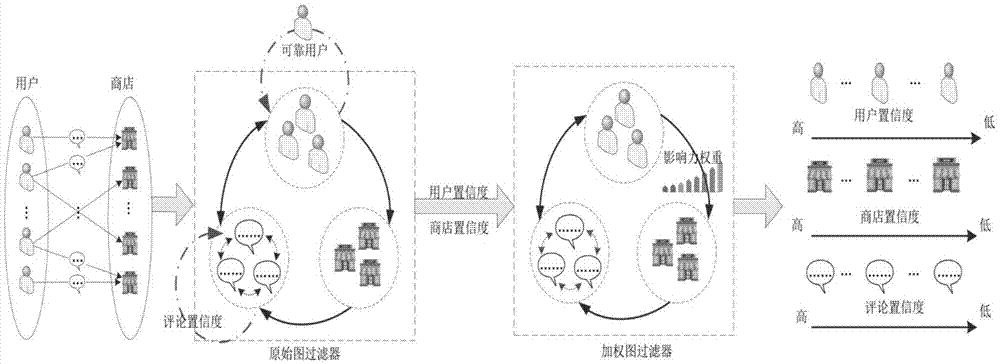
图1是实施例提供的基于双循环图的虚假评论检测方法的流程框图;
图2是实施例提供的衡量用户影响力的times权重函数的曲线图;
图3是实施例提供的用于可靠用户划分的用户置信度频度分布图。
具体实施方式
为使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例对本发明进行进一步的详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不限定本发明的保护范围。
如图1所示,本实施例提供的基于双循环图的虚假评论检测方法包括:
s101,采用原始图过滤器计算原始评论数据的评论置信度和用户置信度,并对用户置信度进行筛选获得可靠用户。
s101中,所述评论置信度和用户置信度的计算为:
评论置信度的计算:
评论v的置信度记为h(v),取值范围为(-1,1),其计算公式为:
h(v)=|r(γv)|an(v,δt)(1)
其中,an(v,δt)表示在δt时间内n条评论的评论一致性,γv为评论v对应商店的id,r(γv)表示评论v所评论商店的置信度;
用户r的评论置信度hr为:
其中,nr为用户r的评论数,
用户置信度的计算:
用户r的置信度记为t(r),取值范围为(-1,1),其计算公式为:
评论置信度初始值为0,用户置信度的初始值为1,将原始评论数据中商店和用户作为横轴和纵轴,用户对商店的评分作为元素值,构建矩阵,利用上述公式(1)~(3)计算评论置信度和用户置信度。
其中,公式(1)中,所述an(v,δt)的计算为:
其中,t(ki)表示相似集sv,a内用户置信度,t(kj)表示非相似集sv,d内
用户置信度,对相似集sv,a与非相似集sv,d的划分有如下定义:
sv,a={i||ψi-ψj|<δ}(7)
sv,d=sv\sv,a(8)
其中,sv为时间δt内商店的所有评论集合。γi表示评论id,|ψi-ψj|表示一条打分信息ψi与周围的打分分值ψj相差小于δ时被划分为相似集sv,a,否则被划分为非相似集sv,d,δ设置为1。
所述用户置信度进行筛选获得可靠用户包括:
将所有用户置信度以用户置信度-频数曲线呈现成用户置信度频度分布,如图3所示;
以用户置信度-频数曲线中靠近用户置信度最小取值的波谷对应的用户置信度作为第一个界点p1,以小于该第一个界点p1的所有用户置信度对应的用户作为可靠用户;
且以用户置信度-频数曲线中靠近用户置信度最大取值的波谷对应的用户置信度作为第二个界点p2,以大于该第二个界点p2的所有用户置信度对应的用户作为可靠用户。
s102,利用原始图过滤器计算可靠用户对应的评论数据的商店置信度。
s102中,商店置信度初始值设为1,将可靠用户对应的评论数据按照以下公式计算商店置信度:
其中,r(s)表示商店s的置信度,
上述获得的可靠部分用户和评论置信度数据循环利用,获得了可靠的商店置信度和用户置信度,为加权图过滤器的构建提供基础。
s103,将原始图过滤器中的评论置信度更新为s101获得的评论置信度,利用原始图过滤器计算原始评论数据的用户置信度。
s104,以s102获得的商店置信度和s103获得的用户置信度作为初始值,构建加权图过滤器。
具体地,构建的加权图过滤器为:
步骤(2)获得的商店置信度和步骤(3)获得的用户置信度作为初始值;
评论置信度hr计算公式为:
其中,
h(v)=|r(γv)|an(v,δt)(12)
其中,an(v,δt)为在δt时间内n条评论的评论一致性,γv为评论v对应商店的id,r(γv)表示评论v所评论商店的置信度;
用户置信度t(r)计算公式为:
商店置信度r(s)计算公式为:
其中,
其中,τr为用户r对商店s的评论次数,τmax为对商店s进行评论的所有用户中最大评论次数。
构建的加权图过滤器中,引入了以用户评论次数为基础来衡量用户影响力的权重函数,该权重函数能够提升商店置信度的可靠性。
公式(12)中的an(v,δt)的计算公式为:
其中,t(ki)表示相似集sv,a内用户置信度,t(kj)表示非相似集sv,d内用户置信度,对相似集sv,a与非相似集sv,d的划分有如下定义:
sv,a1={i||ψi-ψj|<δ}(19)
其中,|ψi-ψj|表示一条打分信息ψi与周围的打分分值ψj的评分偏差,δ为评分相似阈值;
如果评分为4分的用户数大于评分为2分的用户数时:
sv,a2={i|ψi=5}(20)
如果评分为4分的用户数小于评分为2分的用户数时:
sv,a2={i|ψi=1}(21)
则:
sv,a=sv,a1∪sv,a2(22)
sv,d=sv\sv,a(23)
在构建的加权图过滤器中,采用上述方法重新划分了评论相似集与非相似集,以此来进一步优化评论一致性,进而提高评论置信度和用户置信度的可靠性和准确性。
上述阈值参数μ的取值为3。
s105,利用加权图过滤器计算原始评论数据的商店置信度、用户置信度和评论置信度,根据评论置信度筛选获得虚假评论。
具体地,首先,利用加权图过滤器计算原始评论数据的商店置信度、用户置信度和评论置信度;然后,对商店置信度、用户置信度和评论置信度分别进行排序;最后,筛选排序靠后评论置信度对应的评论作为虚假评论。
上述虚假评论检测方法中,首先利用原始图过滤器获得商店置信度和用户置信度,然后基于该商店置信度和用户置信度构建加权图过滤器,利用构建的加权图过滤器计算原始评论数据的商店置信度、用户置信度和评论置信度,以此来筛选获得虚假评论,该方法能够提高虚假评论的加测准确性。
实验例:
实验例采用的三个yelp数据集分别为:
yelpchi数据集,包含67395条评论,38063个用户和201家商店;
yelpnyc数据集,包含359052条评论,160225个用户和923家商店;
yelpzip数据集,包含608598条评论,260277个用户和5044家商店。
采用上述虚假评论检测方法对三个yelp数据集进行测试,测试结果为:
yelpchi数据集中虚假用户约占用户总数的20.33%,虚假评论约占评论总数的13.23%;yelpnyc数据集中虚假用户约占用户总数的17.79%,虚假评论约占评论总数的10.27;yelpzip数据集中虚假用户约占用户总数的23.91%,虚假评论约占评论总数的13.22%。
由此可知,本实施例提供的虚假评论检测方法能够很准确地检测虚假评论和虚假用户。
以上所述的具体实施方式对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的最优选实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!