一种上位多目标测试用例优先级排序方法与流程
本发明属于软件测试技术领域,尤其是软件回归测试技术领域,具体涉及一种上位多目标测试用例优先级排序方法。
背景技术:
在软件演化过程中,测试用例优先级(testcaseprioritization,tcp)技术作为一种高效实用的回归测试技术,通过将测试用例按照某种测试目标进行排序来获得更高的测试效率,对于提高缺陷的早期检测速率和降低测试成本有重要的意义。随着工业测试要求的不断提高,只针对单一测试目标对测试用例序列进行优化已不能够满足工业测试需求,因为实际测试过程中需考虑多种因素对软件质量的影响,例如测试成本、时间和代码修改等因素,多目标测试用例优先排序问题(multi-objectivetestcasesprioritization,motcp)是目前回归测试中急需解决的一个重要问题。
多目标测试用例优先级排序问题是目前软件回归测试领域中的一个研究热点,由于在多目标测试用例优先排序中多个目标一般存在冲突关系,为了搜索到多个目标的最优解集,普遍采用的工程方法是将多目标测试用例优先排序问题转化为组合优化问题采用启发式方法解决。debkalyanmoy等提出带精英策略的快速非支配排序遗传算法(non-dominatedsortinggeneticalgorithmii,nsga-ii)解决多目标优化问题,虽然nsga-ii运行速度快,解集的收敛性较好,但是遗传算法中选择、交叉、变异等操作相对复杂,算法性能不理想。tyagimanika等用于求解多目标优化问题的粒子群算法(multi-objectiveparticleswarmoptimization,mopso)解决测试用例优先排序,但mopso收敛性不好。陈云飞等为提高粒子在迭代过程中的多样性,参照遗传算法中的交叉操作提出了一种基于pso的测试用例预优化方法,采用顺序交叉和单点交叉的方法对粒子进行更新。由于测试用例序列中存在上位基因段,上位基因段能表达解的原本性状,对适应值的影响起到决定性作用,本发明针对多目标的测试用例优先排序问题,利用上位交叉方法对粒子群优化算法中速度及位置的更新方式进行重新定义,提出了一种基于上位性的多目标测试用例优先排序方法,提高回归测试效率,有助于尽早发现软件缺陷。
技术实现要素:
在进行软件回归测试时,由于测试成本、时间等多因素的影响,通常有多个测试目标需要被满足,因此一个测试用例排序结果的优劣需要从多个指标来进行评价。在多目标测试用例优先排序中,普遍情况下求得使多个评价指标均达到单目标时的最优化是难以做到的,需要求解问题的非支配解集,但传统的方法得到的非支配解集分布不够广泛,适应值欠佳,因此需要发掘测试用例序列的特性寻找新的高效的多目标测试用例优先级方法。
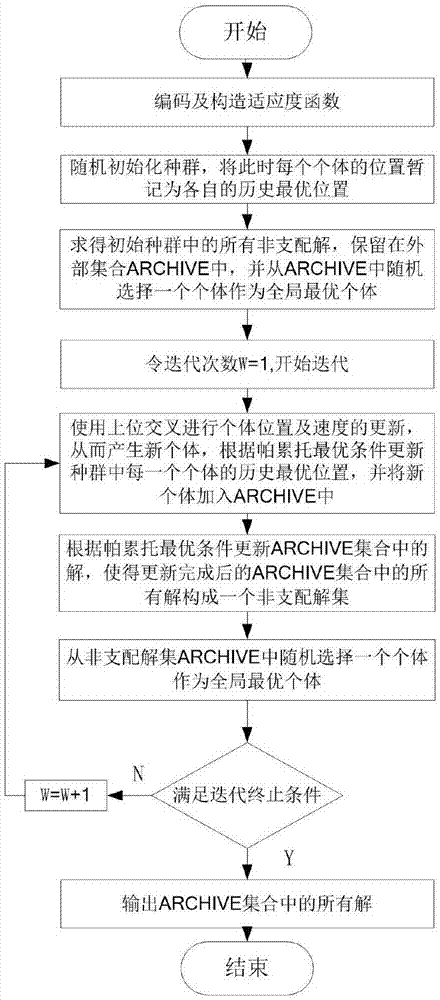
本发明的技术方案为:一种上位多目标测试用例优先级排序方法,具体包括以下几个步骤:
步骤一:记录回归测试中的各个测试用例的分支覆盖情况和有效执行时间得到测试用例分支覆盖矩阵a和有效执行时间向量v;假设某待测程序有m个分支,用n个测试用例进行测试,若测试用例集用φ表示,φ={t1,t2,…,ti,…,tn},其中ti(1≤i≤n)为测试用例集中的第i个测试用例,构造的分支覆盖矩阵a的大小为n×m,有效执行时间向量v的大小为n,待测程序中分支编号的范围是1到m,测试用例编号的范围是1到n,第i个测试用例的有效执行时间为eti,若第i个测试用例执行中覆盖了第j个分支,则aij=1,否则aij=0;
步骤二:编码;针对给定的待测程序和测试用例集,给每一个测试用例一个1到n的编号,测试用例执行优先排序序列就是测试用例编号的一个全排列,个体被编码为一个测试用例编号全排列串,编码的长度为测试用例的个数n;
步骤三:构造适应度函数;选择用平均分支覆盖率(averagepercentageofbranchcoverage,apbc)和有效执行时间(effectiveexecutiontime,eet)两个目标作为适应度函数来衡量一个测试用例优先排序序列的优劣;针对任一个体,tbi表示首个覆盖程序中第i个分支的测试用例在该测试用例优先排序序列中所处的位置。执行完序列上的前m'个测试用例时,能够覆盖被测程序中的所有分支,eti表示执行测试用例优先排序序列中第i个测试用例花费的时间。由此可以构造适应度函数apbc和eet,
步骤四:随机初始化种群;设定种群规模为n,即种群中包含n个个体,随机初始化各个粒子为测试用例编号的全排列,并作为该粒子的历史最优,随机初始各个粒子的初始速度为一个测试用例编号的全排列,计算各个个体的适应值,根据种群中所有个体之间帕托累关系计算初始种群的非支配解集archive,从种群的archive中随机取一个粒子作为全局最优粒子,设置最大迭代次数max;令迭代次数w=1,开始迭代:
步骤五:采用上位交叉的方法产生新的子个体,选择两个本次没有更新的个体作为父代个体,针对父代个体1和父代个体2,其子代个体1和子代个体2的具体产生过程如下:
1)随机产生两个整数k1、k2作为交叉点,k1,k2∈[0,n-1],其中n为测试用例集中测试用例的数目;
2)将父代个体1上两个交叉点之间的基因直接复制到其对应的子代个体1中,作为该子代个体对应位置上的基因;
3)遍历父代个体2,剔除与父代个体1上两个交叉点之间相同的基因,记剩余基因形成的序列为s1;
4)以子代个体1上第一个没有基因的位置作为起始位置,用s1中的基因依次填充子代个体1上没有基因的位置,形成完整的子代个体1;
5)将父代个体2上两个交叉点之间的基因直接复制到其对应的子代个体2中,作为该子代个体对应位置上的基因;
6)遍历父代个体1,剔除与父代个体2上两个交叉点之间的基因相同的基因,记剩余基因形成的序列为s2;
7)以子代个体2上第一个没有基因的位置作为起始位置,用s2中的基因依次填充子代个体2上没有基因的位置,形成完整的子代个体2;
步骤六:使用步骤五的上位交叉方法对粒子进行更新,针对上位交叉后产生的两个子代个体,如果两个子个体是帕累托支配关系,则选择支配的子个体作为交叉结果,如果是帕累托非支配关系,则任选一个子个体作为交叉结果。针对第i个粒子,首先对迭代完成后的个体历史最优解pi(k)与全局最优解pg(k)进行上位交叉得到一个表示粒子速度的增量vi'(k+1);然后vi'(k+1)与粒子当前的速度vi(k)进行上位交叉得到粒子更新后的速度vi(k+1);最后,对粒子当前位置xi(k)和更新后的速度vi(k+1)进行上位交叉得到粒子更新后的位置xi(k+1);
步骤七:对于第i个粒子,若当前粒子能支配比该粒子局部最优位置,则将粒子的当前位置作为该粒子的历史最优解;
步骤八:更新当前种群的非支配解集archive,将当前粒子和非支配解集archive中各个个体进行帕累托支配关系计算,如果当前粒子支配archive中某些个体,则用当前粒子替换其支配的archive集中支配的个体,如果和当前archive中所有个体是非支配关系,则加入archive集;
步骤九:全局最优粒子是从非支配解集archive随机选择一个粒子作为全局最优粒子;
步骤十:如果当前的迭代次数达到最大迭代次数max,则archive集中所对应的粒子代表测试用例排序方案就是帕累托最优解集,结束循环;否则,w=w+1,返回步骤五。
本发明有益效果
发明中提出一种上位多目标测试用例优先级排序方法,采用上位交叉进行多目标测试用例优先级排序,上位交叉使得新粒子可以更多得继承当前粒子上的优良性状(序列),提高了求解质量;本方法生成的多目标测试用例优先级排序解集分布范围广、适应值更高,有助于在回归测试过程中尽早发现软件缺陷,降低测试成本。
附图说明
附图1为一种上位多目标测试用例优先级排序方法的流程图。
附图2为多目标测试用例优先级排序不同方法的适应值分布图。
具体实施方式
以javascript单元测试框架jasmine的测试用例优先级排序为例,结合附图1对本发明提出的一种用于回归测试的上位多目标测试用例优先级排序方法的具体实施方式进行说明。
步骤一:针对一个待测程序jasmine,使用回归测试中已经设计好的24个测试用例作为测试用例集进行测试,jasmine的源程序有95个分支,将测试用例对待测程序的分支覆盖情况进行记录,得到测试用例对待测程序的分支覆盖信息矩阵a;若测试用例集用φ表示,φ={t1,t2,…,ti,…,tn},其中ti(1≤i≤n)为测试用例集中的第i个测试用例,构造的分支覆盖信息矩阵a的大小为24×95,待测程序中分支编号的范围是1到95,测试用例编号的范围是1到24,第i个测试用例的有效执行时间为毫秒单位的时间,例如524ms。若第i个测试用例执行中覆盖了第j个分支,则aij=1,否则aij=0;
步骤二:编码;针对给定的待测程序和测试用例集,个体表示一个测试用例优先级排序序列,测试用例优先级排序序列就是测试用例编号所组成的有序序列,即每一个个体被编码为一个有序测试用例编号串,编码的长度为测试用例的个数24,因此编码中包含1至24这24个不重复的自然数,例如,个体可以编码为(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24);
步骤三:构造适应度函数;针对任意一个体,tbi为首个可以覆盖到待测程序中第i个分支bi的测试用例在该测试用例执行序列中所处的次序。假如执行完序列上的前5个测试用例时,能够覆盖被测程序中的所有分支。由此可以构造适应度函数apbc和eet,
其中tbi(1≤i≤95)可以使用分支覆盖信息矩阵a进行计算,针对被覆盖的分支bi,在a中查找第一个覆盖到该分支的测试用例在该测试用例序列中所处的次序,那么这个次序就是tbi的数值,例如,针对程序中的第二个分支,第一个覆盖到该分支的测试用例在该测试用例序列中所处的次序为5,那么tb2=5;eet表示测试用例优先排序序列首次达到分支全覆盖时执行测试用例的时间总和,例如,某测试用例优先排序序列首次达到分支全覆盖时执行了该序列上前5个测试用例,其执行时间分别为504ms,527ms,517ms,521ms,497ms,那么eet=504+527+517+521+497=2566(ms);
步骤四:随机初始化种群;设定种群规模为150,即种群中包含150个粒子,某次实验中随机初始化的种群中的粒子为(篇幅限制这里只列举了前五个和后五粒子的编码)(6,1,23,14,15,20,18,19,9,7,16,21,10,4,3,8,13,5,22,17,2,12,11,24),(4,11,5,23,13,2,3,14,7,8,9,10,22,16,12,17,1,15,6,21,18,19,20,24),(20,14,4,8,13,16,18,12,11,5,2,23,10,7,22,1,9,21,19,3,6,15,17,24),(4,12,16,14,23,21,1,3,11,5,10,9,20,22,8,2,7,18,17,13,6,15,19,24),(2,11,16,12,4,10,22,21,7,18,17,23,5,8,9,6,3,13,1,19,14,20,15,24),……………………………………(11,14,19,5,8,9,12,15,20,13,16,18,6,10,4,23,3,21,7,2,1,22,17,24),(4,3,11,14,1,10,20,5,13,21,18,19,23,22,15,6,12,7,8,17,16,2,9,24),(12,23,19,2,4,6,5,7,9,22,10,17,3,14,8,11,20,13,18,15,1,16,21,24),(13,9,22,8,17,20,7,15,18,10,11,16,6,4,5,21,23,3,2,19,14,12,1,24),(6,7,8,23,16,11,20,14,21,18,15,1,5,3,17,10,4,2,12,9,19,22,13,24),分别计算种群中150个个体的apbc和eet,计算结果为(篇幅限制这里只列举了前五个粒子的计算结果)<0.7861842105263158,9964>,<0.7949561403508772,10561>,<0.8081140350877193,10808>,<0.8019736842105264,12182>,<0.7975877192982457,11643>…….,根据种群中所有个体之间帕托累关系,计算得到的初始种群的非支配解集archive中包含3个解,分别为(4,16,10,5,18,15,21,23,14,22,11,1,9,20,8,13,19,7,3,6,12,17,2,24),(19,8,10,13,15,1,21,18,23,6,11,4,7,9,22,20,14,17,16,2,12,3,5,24),(7,2,9,20,19,14,13,4,11,22,18,21,1,12,23,16,5,3,17,15,6,10,8,24),它们对应的apbc和eet计算结果分别为<0.8879385964912281,7167>,<0.8883771929824562,10132>,<0.8304824561403509,6678>,从种群的archive中随机取一个粒子作为全局最优粒子,这里选取(7,2,9,20,19,14,13,4,11,22,18,21,1,12,23,16,5,3,17,15,6,10,8,24);设置最大迭代次数max=100;令迭代次数k=1,开始迭代;
步骤五:采用上位交叉(记作
步骤六:使用步骤五的上位交叉方法对粒子进行更新,针对上位交叉后产生的两个子代个体,如果两个子个体是帕累托支配关系,则选择支配的子个体作为交叉结果,如果是帕累托非支配关系,则任选一个子个体作为交叉结果。这里计算步骤五中两个子个体的适应值分别为<0.7440789473684211,9653>和<0.7756578947368421,12182>,互为帕累托非支配关系,随机选择第一个子个体作为交叉结果;假如在某次迭代过程中,针对当前种群中某一粒子,其历史最优解pi(k)为(3,1,13,15,12,17,9,18,8,22,23,2,21,11,16,14,6,5,4,20,7,10,19,24),上次迭代完成后得到的全局最优解pg(k)是(9,7,8,4,20,21,17,13,11,5,2,1,3,19,6,12,14,23,18,10,16,22,15,24),对pi(k)与pg(k)进行步骤五中的上位交叉操作得到一个表示粒子速度的增量vi'(k+1),为(9,7,13,8,4,20,21,17,11,5,2,1,3,19,6,12,14,23,18,10,16,22,15,24);然后,该粒子当前的速度vi(k)(9,12,2,22,16,17,1,11,3,21,8,19,18,20,5,10,23,7,14,6,4,13,15,24),与vi'(k+1)进行步骤五中的上位交叉操作得到粒子更新后的速度vi(k+1),为(9,12,2,17,1,11,3,21,8,19,20,5,7,6,4,13,14,23,18,10,16,22,15,24);最后,对粒子当前位置xi(k)(9,12,22,13,17,1,11,2,3,16,21,8,19,18,20,5,10,23,7,14,6,4,15,24),和更新后的速度(9,12,2,17,1,11,3,21,8,19,20,5,7,6,4,13,14,23,18,10,16,22,15,24)进行上位交叉得到粒子更新后的位置xi(k+1),为(9,12,17,1,19,20,11,2,3,16,21,8,5,7,6,4,13,14,23,18,10,22,15,24),该粒子适应值为<0.8081140350877193,10724>;
步骤七:对于第i个粒子,若当前粒子能支配该粒子的历史最优位置,则将粒子的当前位置作为该粒子的历史最优位置;步骤六中粒子的历史最优位置是<0.8028508771929824,10956>,被该粒子的新位置支配,因此将粒子的当前位置(9,12,17,1,19,20,11,2,3,16,21,8,5,7,6,4,13,14,23,18,10,22,15,24)作为该粒子的历史最优位置;
步骤八:更新当前种群的非支配解集archive,将当前每一个粒子和非支配解集archive中各个个体进行帕累托支配关系计算,如果当前粒子支配archive中某些个体,则用当前粒子替换其支配的archive集中支配的个体,如果和当前archive中所有个体是非支配关系,则加入archive集;例如,某次迭代后archive中包含的4个个体的适应值为<0.8760964912280702,5935>,<0.9028508771929825,7448>,<0.8796052631578948,6068>,<0.9067982456140351,9258>,当前迭代过程中一通过上位交叉更新后的粒子的适应值为<0.9073489539854868,8472>,该粒子支配原archive中适应值为<0.9067982456140351,9258>的个体,并且它与原archive中适应值为<0.8760964912280702,5935>,<0.9028508771929825,7448>,<0.8796052631578948,6068>,的个体互为非支配解,因此使用该粒子替换<0.9067982456140351,9258>对应的粒子,此时archive中个体的适应值更新为<0.8760964912280702,5935>,<0.9028508771929825,7448>,<0.8796052631578948,6068>,<0.9073489539854868,8472>;接着,当前迭代过程中一通过上位交叉更新后的粒子适应值为<0.9111842105263158,12157>粒子,由于该粒子与上述更新后archive中的所有个体互为非支配解,因此将该粒子直接加入archive集;
步骤八:全局最优粒子是从非支配解集archive随机选择一个粒子作为全局最优粒子;
步骤九:如果当前的迭代次数达到最大迭代次数100,则archive集中所对应的粒子代表测试用例排序方案就是帕累托最优解集,结束循环,例如,某次实验中算法迭代100次后,archive中的个体为(4,15,21,19,9,13,14,11,8,7,2,16,22,3,17,18,20,10,1,12,5,6,23,24),(21,4,11,8,9,2,19,13,23,17,7,18,16,15,22,14,6,12,3,20,5,1,10,24),(4,21,9,19,13,15,11,8,2,16,18,1,23,10,22,3,17,20,7,12,5,6,14,24),(15,21,19,9,13,4,11,2,16,3,17,20,10,18,14,8,7,22,1,12,5,6,23,24),对应的适应值分别是<0.9287280701754387,4850>,<0.905921052631579,4204>,<0.9256578947368421,4392>,<0.9291666666666667,8718>。
通过以上过程可以实现一种用于回归测试的上位多目标测试用例优先级排序方法,针对jasmine程序的分支覆盖信息,分别将基于单点交叉的多目标测试用例优先级排序方法、基于顺序交叉的多目标测试用例优先级排序方法以及本发明中的方法各执行30次。图2是针对是三种方法,在30次实验中,取每次实验中100次迭代后archive中的解集绘制的解的散点图。从图2可以看出,一方面,在有效执行时间相同的前提下,本方法能够普遍得到更高apbc值的排序方案,因此在求解多目标的测试用例优先排序问题时本方法更有效;另一方面,使用本方法得到的排序方案的分布范围较广,给软件测试工程师提供更多的测试方案选择。
实例分析表明,本发明提出的一种用于回归测试的上位多目标测试用例优先级排序方法与基于单点交叉的多目标测试用例优先级排序方法、基于顺序交叉的多目标测试用例优先级排序方法相比,本方法所得排序方案质量好,生成的非支配解集分布范围广,是一种有效的用于回归测试的测试用例优先级排序方法。
- 还没有人留言评论。精彩留言会获得点赞!