一种基于遗传算法-神经网络的热负荷预测方法与流程
本发明涉及供暖系统
技术领域:
,尤其涉及一种基于遗传算法-神经网络的热负荷预测方法。
背景技术:
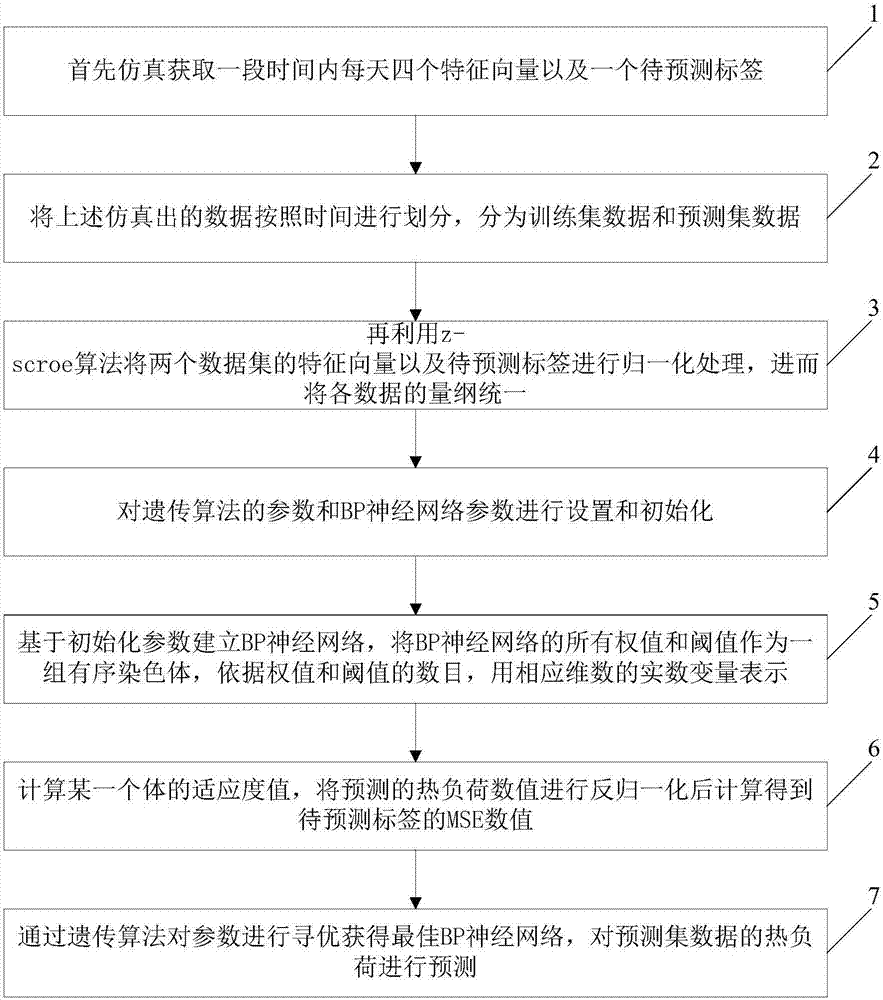
由于我国当前集中供暖系统的控制发展不够完善,经常出现用户端无法满足按需供暖,所以合理的热量生产显得十分重要,现有技术中常用的热负荷预测方法主要有时间序列预测法、情景分析预测法和人工神经网络法等,其中:时间序列预测法通过时间序列模型来描述的运行规律,最终确定热负荷的预测数学公式,通过数学公式来计算出未来的热负荷的需求,虽然对于供暖系统热负荷的预测速度快,准确度高,但是建立模型的过程复杂,没有考虑到特殊天气的变化因素,因此对于实时预测或数据波动大的情况预测效果并不理想。情景分析预测法将多个建筑物进行组合,确定区域内建筑物的热负荷的情景。它能提供最可能出现的热负荷预测结果,属于高概率性预测,精度较高,但结果依赖于各个热负荷的变化规律,一旦出现突发情况,预测偏差将无法估量。人工神经网络预测法不用依赖具体的复杂数学模型就能够处理非线性问题,能够自组织、自学习和自适应,并且有强大的非线性映射与泛化能力,但是确定网络参数耗时耗力,缺乏一定理论指导,神经网络基于经验风险最小化的缘故使其易陷入局部极小值,预测速度也较为缓慢。技术实现要素:本发明的目的是提供一种基于遗传算法-神经网络的热负荷预测方法,该方法可以克服传统人工神经网络容易陷入局部极小值的缺点,并对热负荷进行有效预测,保证了热负荷预测的准确性。本发明的目的是通过以下技术方案实现的:一种基于遗传算法-神经网络的热负荷预测方法,所述方法包括:步骤1、首先仿真获取一段时间内每天四个特征向量以及一个待预测标签;其中,所述四个特征向量包括室外干球温度、太阳照度、风速和湿球温度;待预测标签为热负荷数值;步骤2、将上述仿真出的数据按照时间进行划分,分为训练集数据和预测集数据;步骤3、再利用z-scroe算法将两个数据集的特征向量以及待预测标签进行归一化处理,进而将各数据的量纲统一;步骤4、对遗传算法的参数和bp神经网络参数进行设置和初始化;步骤5、基于初始化参数建立bp神经网络,将bp神经网络的所有权值和阈值作为一组有序染色体,依据权值和阈值的数目,用相应维数的实数变量表示;步骤6、计算某一个体的适应度值,将预测的热负荷数值进行反归一化后计算得到待预测标签的mse数值;步骤7、通过遗传算法对参数进行寻优获得最佳bp神经网络,对预测集数据的热负荷进行预测。由上述本发明提供的技术方案可以看出,上述方法可以克服传统人工神经网络容易陷入局部极小值的缺点,并对热负荷进行有效预测,保证了热负荷预测的准确性。附图说明为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他附图。图1为本发明实施例提供的基于遗传算法-神经网络的热负荷预测方法流程示意图;图2为本发明实施例所建立bp神经网网络结构体示意图。具体实施方式下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明的保护范围。下面将结合附图对本发明实施例作进一步地详细描述,如图1所示为本发明实施例提供的基于遗传算法-神经网络的热负荷预测方法流程示意图,所述方法包括:步骤1、首先仿真获取一段时间内每天四个特征向量以及一个待预测标签;其中,所述四个特征向量包括室外干球温度、太阳照度、风速和湿球温度;待预测标签为热负荷数值;步骤2、将上述仿真出的数据按照时间进行划分,分为训练集数据和预测集数据;步骤3、再利用z-scroe算法将两个数据集的特征向量以及待预测标签进行归一化处理,进而将各数据的量纲统一;该步骤中,进行归一化处理采用的计算公式为:其中,xi,j代表待归一化的第i组数据的第j维数据;μj代表第j维特征的均值;σj代表第j维特征的标准差;x′i,j代表归一化后的第i组数据的第j维数据。步骤4、对遗传算法的参数和bp神经网络参数进行设置和初始化;该步骤中,遗传算法的参数包括种群数量、群体规模、基因长度、交叉概率和变异概率;例如可以设置种群数量为200个,群体规模为50,每个基因长度为10,各初始参数见下表1所示:表1参数数值种群数量200群体规模50基因长度10交叉概率0.05变异概率0.5bp神经网络参数包括输入神经元个数、隐层神经元个数、输出神经元个数和编码长度,其中:输入神经元个数为特征向量的维数;隐层神经元个数根据需要进行设置,例如本实例中可以设置为25;输出神经元个数为待预测标签的维度;编码长度的计算公式为:s=r×s1+s1×s2+s1+s2式中,s为编码长度;r为输入神经元个数;s1为隐层神经元个数;s2为输出神经元个数。步骤5、基于初始化参数建立bp神经网络,将bp神经网络的所有权值和阈值作为一组有序染色体,依据权值和阈值的数目,用相应维数的实数变量表示;这里,所有权值和阈值包括输入层到隐层的权阵、隐层到输出层的权阵、隐层阈值和输出层阈值。举例来说,如图2所示为本发明实施例所建立bp神经网网络结构体示意图,经过编码后的基因表示为:x=[ω11,ω12,…ωmn,v11,v12,…vpm,θ1,θ2,…θm,t1,t2,…tp]其中,ωi,j代表输入层的第j个神经元对隐含层的第i个神经元的阈值;vi,j代表隐含层的第j个神经元对输出层的第i个神经元的阈值;θi表示隐含层第i个神经元的阈值;ti表示输出层第i个神经元的阈值。步骤6、计算某一个体的适应度值,将预测的热负荷数值进行反归一化后计算得到待预测标签的mse数值;本实例中是计算50个个体的预测精度mse数值,上述反归一化计算公式表示为;式中,yi代表归一化的第i个样本点的热负荷,μ代表热负荷的均值,σ代表热负荷的标准差,y′i代表反归一化后的第i个样本点的热负荷。步骤7、通过遗传算法对参数进行寻优获得最佳bp神经网络,对预测集数据的热负荷进行预测。该步骤中,通过遗传算法对参数进行寻优获得最佳bp神经网络的过程为:采用轮盘赌形式选取优秀个体;将上一代优秀个体进行单点交叉,形成新的个体;基于新的个体进行步骤6的操作得到待预测标签的mse数值,若满足最优终止条件,则结束,获得最优网络的所有权值和阈值的数值;若不满足,则继续迭代最优个体。另外,在迭代过程中,还可以对种群中个体的某一编码值进行变动,提高算法的随机搜索能力以及防止算法出现“早熟”而终止。本发明实施例所述热负荷预测方法的实现过程具体为:首先利用dest软件仿真出一年中的1-3月份的每日室外干球温度、太阳照度、风速和湿球温度以及热负荷数值,且将1-2月份的数据作为训练集,3月份的数据作为预测集;继而用z-score算法对数据进行归一化处理;对网络的所有权值和阈值设置为自变量,以及目标函数设置,本发明的目标函数设置为反归一化后的标签的mse数值;然后通过遗传算法对参数进行寻优获得最佳bp神经网络对3月份的热负荷进行预测。值得注意的是,本发明实施例中未作详细描述的内容属于本领域专业技术人员公知的现有技术。以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本
技术领域:
的技术人员在本发明披露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书的保护范围为准。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1