一种宠物知识图谱的半自动化构建方法与流程
本发明涉及宠物管理的技术领域,特别是,涉及一种宠物知识图谱的半自动化构建方法。
背景技术:
随着经济社会的发展,宠物越来越多地出现在人们生活当中,家庭结构和人口结构的变化使得宠物进入了更多的家庭。据京东《2017宠物消费趋势报告》的分析,目前中国宠物已经突破1亿只。互联网是人们很重要的获取宠物百科知识和宠物医疗知识的来源之一。大多数的宠物主人缺乏宠物知识,当他们需要了解这方面的知识的时候,大多的宠物主人主要是通过互联网上google和百度之类的搜索引擎来获取知识。然而这会花费宠物主人很多时间来判断哪些内容包含了自己想要的信息,很多时候,用户想要获取进一步的知识,还需要自己再一次的阅读和筛选。这导致了信息检索的效率比较低下,用户会对搜索引擎返回的大量信息感到迷茫。因此人们对可以提交用自然语言表达的宠物相关问题,系统会返回相关又准确的答案的问答系统有着非常迫切的需求。目前基于知识库的问答聊天机器人有微软小冰、百度的度秘等等。因此构建关于宠物知识库对实现智能问答有研究意义和应用价值。
目前国内外大型互联网公司纷纷推出知识图谱以改善服务质量,同时当今也涌现出了人类医学的知识图谱,并且发展迅速。但在宠物领域尚未出现成熟、专业的知识图谱。
技术实现要素:
本部分的目的在于概述本发明的实施例的一些方面以及简要介绍一些较佳实施例。在本部分以及本申请的说明书摘要和发明名称中可能会做些简化或省略以避免使本部分、说明书摘要和发明名称的目的模糊,而这种简化或省略不能用于限制本发明的范围。
鉴于上述和/或现有技术中存在的问题,提出了本发明。
因此,本发明其中一个目的是提供一种宠物知识图谱的半自动化构建方法。
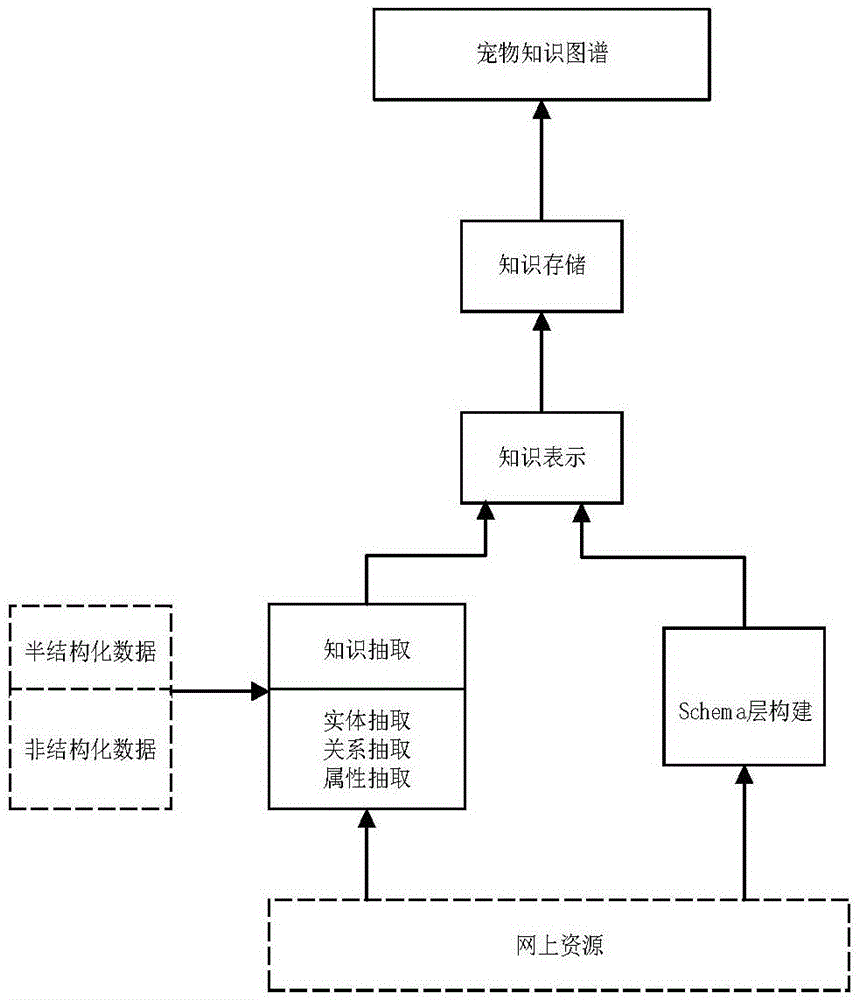
为解决上述技术问题,本发明提供如下技术方案:一种宠物知识图谱的半自动化构建方法,包括,第一步,构建schema层,采用自顶而下的方式构建宠物知识图谱;第二步,数据的抽取,包括从半结构化数据中抽取和从非结构化数据中抽取,所述从半结构化数据中抽取是从半结构化的数据源中进行实体、关系和属性的抽取,所述从非结构化数据中抽取是从非结构化的数据中进行命名实体识别和抽取;第三步,知识表示,选择orientdb原生图数据支持的属性图模型来进行知识表示;第四步,知识存储,将获取的数据通过orientdb图数据库存储。
作为本发明宠物知识图谱的半自动化构建方法的一种优选方案,其中:所述schema层,包括宠物品种、宠物疾病、疾病症状和宠物食物。
作为本发明宠物知识图谱的半自动化构建方法的一种优选方案,其中:所述宠物品种的属性定义包括中文名、别名、体型、毛长、英文名、智商、原产地、体重、寿命、价格、肩高、毛色和功能;所述宠物疾病的属性定义包括科属、概述、发病原因、诊断标准、治疗方法和防治方法;所述宠物食物的属性定义为可食性。
作为本发明宠物知识图谱的半自动化构建方法的一种优选方案,其中:所述schema层根据所述宠物品种、所述宠物疾病、所述疾病症状和所述宠物食物之间的关系分为三种定义语义关系,分别为,所述宠物品种与所述宠物疾病之间存在关系,定义为有疾病;所述宠物疾病与所述疾病症状之间存在关系,有症状;所述宠物品种与所述宠物食物之间存在关系,吃食物。
作为本发明宠物知识图谱的半自动化构建方法的一种优选方案,其中:所述从半结构化数据中抽取,是指从网页中提取网页正文,抽取宠物品种以及属性、宠物疾病以及属性、宠物食物以及食物属性的实体;所述从非结构化数据中抽取,采用crf与症状词典结合的方法。
作为本发明宠物知识图谱的半自动化构建方法的一种优选方案,其中:所述知识表示,将所述知识图谱模型通过w3c提出的资源描述框架或者属性图来表示。
作为本发明宠物知识图谱的半自动化构建方法的一种优选方案,其中:所述知识存储,是将获取的schema层数据和实例层数据进行知识的整合和存储,所述存储的语言使用类sql。
本发明的有益效果:在宠物领域提供的基于数据抽取的知识图谱的构建方法,并且详细的描述了整个构建过程,通过实例展示了本文构建的知识图谱,旨在为宠物领域构建比较高质量的知识库。填补了国内在宠物领域知识图谱的缺失。该知识库为宠物领域知识的应用提供了语料基础,为宠物领域问答机器人奠定了基础,具有重要意义。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其它的附图。其中:
图1为本发明提供的宠物知识图谱的半自动化构建方法的构建整体流程示意图;
图2为本发明提供的宠物知识图谱的半自动化构建方法的所述宠物知识图谱schema层的示意图;
图3为本发明提供的宠物知识图谱的半自动化构建方法的抽取数据后的阿司匹林中毒疾病的示意图;
图4为本发明提供的宠物知识图谱的半自动化构建方法的症状命名实体识别关键技术框架的示意图;
图5为本发明提供的宠物知识图谱的半自动化构建方法的属性图实例的示意图;
图6为本发明提供的宠物知识图谱的半自动化构建方法的宠物只是图谱示例图。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合说明书附图对本发明的具体实施方式做详细的说明。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其他不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广,因此本发明不受下面公开的具体实施例的限制。
其次,此处所称的“一个实施例”或“实施例”是指可包含于本发明至少一个实现方式中的特定特征、结构或特性。在本说明书中不同地方出现的“在一个实施例中”并非均指同一个实施例,也不是单独的或选择性的与其他实施例互相排斥的实施例。
本发明宠物知识图谱的半自动化构建方法提供的实施例中包括四个步骤,具体为:
第一步,构建schema层,采用自顶而下的方式构建宠物知识图谱;
第二步,数据的抽取,包括从半结构化数据中抽取和从非结构化数据中抽取,所述从半结构化数据中抽取是从半结构化的数据源中进行实体、关系和属性的抽取,所述从非结构化数据中抽取是从非结构化的数据中进行命名实体识别和抽取;
第三步,知识表示,选择orientdb原生图数据支持的属性图模型来进行知识表示;
第四步,知识存储,将获取的数据通过orientdb图数据库存储。
其中,schema层的构建是对整个宠物知识图谱框架的构建,schema是要对类及类之间的关系进行定义,也就是对知识图谱中的概念和概念之间的语义关系进行定义,因此,将构建schema层定义了基本的四大类,分别为:宠物品种、宠物疾病、疾病症状和宠物食物。
上述四个类的属性定义依次陈述如下:
(1)关于宠物品种的属性定义,其包括中文名、别名、体型、毛长、英文名、智商、原产地、体重、寿命、价格、肩高、毛色和功能。
(2)关于宠物疾病的属性定义,其包括科属、概述、发病原因、诊断标准、治疗方法和防治方法。
(3)关于宠物食物的属性定义,其为可食性。
经过分析宠物品种、宠物疾病和宠物食物的属性(由于疾病症状比较特殊,只有症状名称,不存在属性关系的定义),创建了3种语义关系,分别是:
有疾病(e_hasdisease):宠物品种——宠物疾病,宠物品种与宠物疾病之间存在关系。
有症状(e_hassymptom):宠物疾病——疾病症状,宠物疾病与疾病症状之间存在关系。
吃食物(e_eatfood):宠物品种——宠物食物,宠物品种与宠物食物之间存在关系。
以上就是宠物知识图谱概念与语义关系的创建,具体的宠物知识图谱的schema层如图2所示。
宠物知识图谱是从国内的关于宠物的网站上抽取知识,本申请以从“铃铛宠物”和“有宠”两家宠物网站爬取有用的知识为例,做具体说明。
在铃铛宠物抽取了92种食物的实体,以及食物的属性。有宠网站上面有关于宠物品种和宠物的疾病的百科知识,提供了质量较高的半结构化数据,所以在有宠网站抽取了1367个实体。
从“铃铛宠物”和“有宠”这两个网站的半结构化数据中抽取宠物品种、宠物疾病和宠物食物的实体、实体属性以及语义关系。采用的是网页爬虫和数据解析,通过爬虫采集网页信息。
本申请选用可以从html网页中提取数据的python库—beautifulsoup作为解析器。基于网页页面布局相似的特点,采用基于标签遍历的方法,直接导航到dom树的关键节点,可以避免大量遍历节点,从而提取相关网页正文,通过此方法,可以抽取宠物品种以及属性、宠物疾病以及属性、宠物食物以及食物属性的实体。同时在抽取实体的过程中也实现了语义关系的挖掘,获取了3种语义关系。如图3宠物狗的阿司匹林中毒疾病为例,参照图3,解析网页抽取了宠物疾病实例宠物狗的阿司匹林中毒,也抽取了阿司匹林中毒的科属、概述、发病原因、诊断标准、治疗方法5个属性,根据我们对宠物疾病属性的定义,也就获取了5条“属性-值”关系,用三元组描述为<实体,属性,属性值>,同时这是宠物狗的疾病,也就获取了e_hasdisease(有疾病)这种语义,上图中基本资料里面的症状不全也不正确,还需要从主要症状中抽取,主要症状是一段非结构化文本,本申请将采用条件随机场(crf)与症状词典相结合的症状命名实体识别方法,进行症状实体的抽取,这可以得到e_hassymptom(有症状)这种语义。
本申请需要从非结构文本中进行命名实体识别来抽取症状的实体,优选的,本申请中研究采用了crf与症状词典结合的方法。crf不仅可以使用包括字、词、词性在内的多种上下文特征,还可以结合词典等外部特征。
crf可以看做是一种无向图模型。常用的crf模型是线性链crf。给定输入句子中的单词序列作为观测序列o,s表示对应的输出标记序列,crf定义了s的条件概率分布p(s|o),通过训练求得p(s|o)为最大值时的状态序列s。线性链crf中的输出序列s的条件概率公式入下:
在命名实体识别等任务中取得了较好的效果,得到的症状命名实体识别的关键技术框架如图4所示。
经查阅文献和网上资源后,发现国内外目前没有公开的宠物医疗领域的用于症状命名实体识别的数据集,因此本申请需要自己构造语料库。
本申请共抽取了285条描述症状的文本,其中将100条构建成训练集,30条文本构建成测试集,当准确率达到要求时,将用训练好的模型来从285条无结构化文本中抽取症状的实体。
标记完语料库之后,需要对语料库进行格式转换,按照bieso对语料进行标识。标记为b-signs、i-signs、e-signs、s、o,分别标识症状的首部、症状的中部、症状的尾部、单个症状词和非症状词。表1为使用bieso标记实体的举例。
表1bieso标记实体举例
由于需要从描述症状的非结构化文本中抽取症状实体,因此采用了crf与症状词典相结合命名实体识别方法。主要是通过网上查找分析,构造一个症状的词典,这样就可以利用症状词典获取文本中词语的语义类别信息,并把语义类别信息作为特征传递给crf模型去识别文本中的症状实体。类别信息如表2所示。本申请中将描述症状的文本分为两类:描述症状的术语记为“bs”,其他非症状术语记为“bo”。
表2类别信息
特征集是症状实体识别成功的关键,为了提高命名实体识别的准确率,通过对描述症状的文本分析,本申请中的特征集包括“word”语言符号特征、词性特征以及症状词典特征,如表3所示:
表3症状特征
参照表3,具体解释如下:
(1)“word”语言符号特征。word语言符号特征指的是词的本身,包含丰富的有效信息。词是一种语言符号,本身可以作为一种特征,反映字符信息。与英文不同,中文之间没有明显的空格分隔符,所以在进行症状的实体识别之前,需要将文本进行分词。之后将分词结果作为word特征引入。
(2)“pos”词性特征。在宠物疾病症状的实体识别任务中,文本中的症状实体通常出现在动词后面,所以将词性作为特征,主要包括动词、名词、副词等等。
(3)“dict”词典特征。文本中包含大量专业症状名词,所以需要引入词典特征,通过构造的症状术语词典,用该词典匹配文本单词,结果返回症状的语义类别,词典特征就是症状词典对当前单词的识别结果,分为“bs”和“bo”。
本申请中总共有285条非结构化文本数据,其中使用标注的130条数据集做实验,将100条文本作为训练集,30条作为测试集来进行实验。
为了得到可靠稳定的模型,采用基于训练集的10折交叉验证,从而得到crf模型的最优参数,并于单独的30条测试集上测试。实验采用的是机器学习常用的评价指标precision(准确率)、recall(召回率)以及f值(f-measure),具体定义如下:
进行对比实验的硬件平台为戴尔alienwareaurorar7,cpu3.7ghzintelcorei7,ram32gb,硬盘2t+512gbssd。分为加词典特征和不加词典特征的对比实验,进行两个实验来看识别症状实体的实验效果,实验结果如表4所示。
表4实验结果对比
通过对比实验,结果显示结合了动物症状术语词典的crf模型比没有结合词典特征的crf模型识别效果有了不错的提升,准确率、召回率和f值都提高了不少,分别提升了6.71%、9.08%和7.90%,其中召回率提升幅度最大。分析实验结果发现,症状识别效果的提升原因是因为在症状的描述训练集中很少出现的,不具有明显特征的症状被结合症状词典的crf模型准确的识别了出来,比如“多饮多尿”,在本申请的训练集中没有这样描述症状的术语,但是动物症状术语词典识别了出来,因此结合动物症状词典的crf模型,因为有了语义类别信息,识别效果比未结合动物症状术语的crf模型好。
因为识别出来的准确率达到了91.63%,召回率达到了90.32%,准确率和召回率都达到了比较高的数值,所以本申请采用了这个训练好的结合症状词典的crf模型从285条非结构化文本中抽取症状实体,共抽取出了624个宠物疾病的症状实体。
知识图谱也可以看做是一种图的网络结构,网络图中的节点表示实体,边代表关系。知识图谱图模型可以使用w3c提出的资源描述框架(rdf,resourcedescriptionframe)或者属性图(propertygraph)来表示[。本申请因为使用orientdb图数据库来存储获取到的宠物领域的数据,因此使用属性图模型来进行知识的表示。
属性图包含实体(节点)和链接实体的关系(边),实体可以包含任何数量的属性(键值对形式),属性图中的元素如下:
一组节点。每个节点有唯一的标识符@rid,每个顶点有一组出边和入边,每个顶点都有个实体类型@class,表示实体所对应的概念类,每个顶点有键值对来定义属性集合。
一组边。每条边都有一个唯一标识符@rid,每条边有一个头结点和尾节点,每条边有个实体类型@class,表示两个节点之间的关系,每条边有键值对来定义属性结合。
图5描述了一个orientdb的属性图模型,疾病“犬瘟热”实体和症状“发热”之间的关系是e_hassymptom(有症状)。其中@rid是唯一标识符,@class是实体类型,也就是对应的概念类,out对应的是头结点也就是疾病节点,in对应的是尾节点也就是症状节点,name和keshu等键值对是对对应节点属性的描述。
本申请使用的是图数据库orientdb,orientdb是一个用java实现的开源nosql数据库管理系统。它是一个多模式的库,支持图形、文档、键值对、对象模型和关系,也可以为图数据的管理和记录之间提供连接。支持的查询语言最常用的是gremlin和sql,用来操作属性图,支持以sql的方式来查询数据,但是在标准的sql上面扩展一些功能用来方便图的操作,是一种类sql语句。
将获取到的宠物领域的实例层数据通过orientdb原生数据库进行知识的整合和存储,存储语言使用类sql。首先需要创建模式,根据schema层的定义,创建概念类包括宠物品种(v_breed)、宠物疾病(v_disease)、食物(v_food)、疾病症状(v_symptom)、有疾病(e_hasdisease)、吃食物(e_eatfood)和有症状(e_hassymptom)
在创建好模式之后,需要载入对应标签中的所有节点信息以及节点之间的关系,在导入数据信息的时候为了防止重复的节点信息和重复的关系,需要用类sql查询语句进行判断,判断症状重复和载入症状信息的类sql查询语句如表5:
表5类sql查询语句
类sql语句首先在图数据库中查询该症状实体,然后用到了if语句来判断症状实体是否已经存在,如果symptom.size()小于1的话则表示该症状实体未在图数据库中出现,则要创建表示该症状的新的实体。
表6整合后的知识库数据统计
表6为全部数据存储到图数据库之后得到的相关详细信息。因为orientdb内置集成了可视化工具,因此我们通过可视化可以看到“犬瘟热”这个疾病的所有症状的可视化结果如图6所示。蓝色节点表示疾病犬瘟热,橙色节点表示犬瘟热的9个症状,边e_hassymptom表示有症状。
应说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!