一种基于棒状像素的交通场景障碍检测与识别方法与流程
本发明涉及计算机视觉和深度学习领域,具体涉及一种基于棒状像素的交通场景障碍检测与识别方法。
背景技术:
近几年,汽车行业正在向着智能化的方向发展,智能化要实现的目标是能够使得汽车具备人类感知外界环境的能力,在一定情况下代替或者帮助驾驶员做出决策。障碍物检测作为环境感知的基础,已经广泛应用于智能汽车和汽车辅助驾驶系统等领域。双目立体视觉系统可以提供较为丰富的场景信息,是智能车进行障碍物检测的重要方式。但目前的基于双目立体视觉系统的障碍物检测算法功能比较单一,导致交通场景的可解析性差。
为了提高可解析性,人们在障碍物识别中,加入了支持向量机(svm)或adaboost算法(通过迭代弱分类器而产生最终的强分类器的算法)等浅层的学习方法。但这些方法对大规模训练样本难以实施,同时也不能解决多分类问题。随着高性能计算硬件和大数据的快速发展,卷积神经网络的优势在不断凸显,被广泛的应用于图像识别等领域,但目前未见将卷积神经网络用于障碍物检测识别的相关报道。
技术实现要素:
为了克服上述现有技术的不足,本发明要提出一种既具有较好的交通场景可解析性,又能适应大规模训练样本并解决多分类问题的基于棒状像素的交通场景障碍检测与识别方法。
为实现上述目的,本发明的技术方案如下:一种基于棒状像素的交通场景障碍检测与识别方法,包括以下步骤:
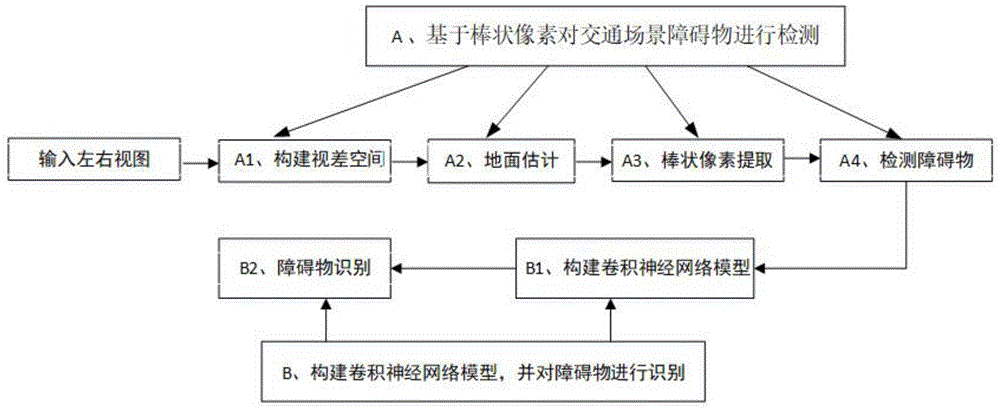
a、基于棒状像素对交通场景障碍物进行检测
a1、构建视差空间
通过车载双目立体视觉系统获取包含交通场景的左右两幅图像,然后采用半全局立体匹配算法(semi-globalstereomatching,sgm)对包含交通场景的左右两幅图像进行立体匹配,得到包含场景三维信息的视差图。所述的双目立体视觉系统包括安装在汽车上的左右两个摄像机。
a2、地面估计
在交通场景中,将所有的交通元素分为两类平面:一类是地面,用水平平面表示;另一类是车辆、树木和行人这类垂直于地面的物体,用垂直平面表示。对步骤a1得到的视差图进行处理,把视差图中每一行的相同视差值累加起来构建v-视差图。由于处于同一距离的地面在水平方向具有相同的视差值,加之视差图中距离人眼视角越近,视差值越大,所以v-视差图中的地面为一条从左上到右下的倾斜直线。利用hough直线变换检测v-视差图中的倾斜直线,并映射到视差图中,进而根据v-视差图中得到的倾斜直线方程滤除地面,完成地面估计。v-视差图中的倾斜直线方程如下:
式中,b是双目立体视觉系统中两个摄像机之间的基线距离,d是视差值,f是摄像机焦距,θ是摄像机主光轴方向与地面夹角,v是图像列坐标,h是世界坐标下的垂直距离。
a3、棒状像素提取
首先通过占位网格法计算出图像每一列的自由区域,进而找出地面与障碍物的交点;然后使用隶属度函数对图像每一列上的每个像素进行划分,当隶属度函数值为正时表示障碍物,为负时为除了障碍物以外的背景,进而将障碍物的高度分割出来。一旦计算出每一列的自由区域和高度,就可以直接提取出棒状像素。隶属度函数的公式如下:
式中,mu,v(d)是视差值d对应的隶属度函数值,u是图像的横坐标,v是图像的列坐标,d是视差值,
式中,
a4、检测障碍物
首先对视差图基于棒状像素表示的交通场景的障碍物所在区域的每一列的相同视差值累加起来,构建表示障碍物区域的u视差图,得到障碍物在u视差图中的左右边界的列坐标。然后根据障碍物的高度,标记出障碍物的位置。
b、构建卷积神经网络模型,并对障碍物进行识别
b1、构建卷积神经网络模型
卷积神经网络模型由四部分组成,前三部分为卷积网络,最后一部分是全连接网络。第一部分由一个卷积层、一个批规范化(bn)层、一个激活函数(relu)层和一个最大池化层组成。卷积层的卷积核的大小为3×3,步长为1×1,卷积后的特征图数量为96。最大池化层的池化核大小为2×2,步长为2×2。输入图像的尺寸大小是224×224×3,经过卷积层之后输出的尺寸大小是224×224×96,经过最大池化层输出的尺寸大小是112×112×96。第二部分由一个卷积层、一个批规范化(bn)层、一个激活函数(relu)层和一个最大池化层组成。经过卷积层和最大池化层输出的尺寸大小是56×56×96。第三部分由三个卷积层、三个批规范化(bn)层、三个激活函数(relu)层和一个最大池化层组成。经过卷积层和最大池化层输出的尺寸大小是28×28×96。最后一部分由三个全连接层、两个激活函数(relu)层、两个丢弃(dropout)层和一个softmax层组成。把第三部分输出的尺寸扁平为长度为75264的一维向量,首先连接含4096个隐含点的第一层全连接层,输出向量为4096的一维向量。然后连接含4096个隐含点的第二层全连接层,输出向量为4096的一维向量。然后连接含10个隐含点的第三层全连接层,输出向量为10的一维向量。第一层和第二层全连接层之后连接激活层和丢弃层,丢弃层中的丢弃率设置为0.5。最后经过softmax层输出类别概率。
b2、障碍物识别
b21、对卷积神经网络模型进行训练,即把步骤a得到的包含车辆或者行人的检测结果裁剪出来,做成训练样本,输入到卷积神经网络模型中;
b22、经过权重初始化过程,初始化网络模型中卷积层的权重和偏置;
b23、采用前向传播算法和反向传播算法,在训练集上迭代,训练出最优的卷积神经网络模型参数;
b24、卷积神经网络模型训练完之后,选取最优的卷积神经网络模型参数用于障碍物识别,最终输出交通场景障碍物的类别。前向传播算法的计算公式如下:
式中,p'x=k是k类的真实概率分布,x为像素点,px=k为第k类的概率,l是损失值,n为小批量图像中的像素总数。反向传播算法的计算公式如下:
wt+1=wt+vt+1(5)
式中,vt+1是当前权重的更新值,vt是先前权重的更新值,μ是动量,α是学习率,wt+1是当前的权重矩阵,wt是先前的权重矩阵,
与现有技术相比,本发明具有以下有益效果:
1、本发明采用基于局部最优的视差求取方法,实现了对交通场景中的障碍物进行棒状像素提取,检测出障碍物的位置,并利用卷积神经网络对交通场景障碍物进行识别,既提高了交通场景的可解析性,同时又适应了大规模训练样本并解决了多分类问题。
2、本发明构造的网络模型,采用批规范化层加快了网络的收敛速度,提高了模型的泛化能力,并一定程度上改善了识别精确率。添加激活函数层减少了网络训练过程中的梯度消失问题。运用丢弃层有效地防止了过拟合,提高网络的性能。同时提高了交通场景障碍物识别的实时性。
附图说明
图1是本发明的流程图。
图2是棒状像素提取之后的结果图。
图3是交通场景障碍物检测结果图。
图4是卷积神经网络结构图。
图5是交通场景障碍物识别结果图。
具体实施方式
以下结合技术方案和附图详细叙述本发明的具体实施方式。
如图1所示,一种基于棒状像素和卷积神经网络的交通场景障碍检测与识别方法,包括以下步骤:
a、基于棒状像素对交通场景障碍物进行检测
a1、构建视差空间
通过车载双目立体视觉系统获取包含交通场景的左右两幅图像,然后采用半全局立体匹配算法(semi-globalstereomatching,sgm)对包含交通场景的左右两幅图像进行立体匹配,构建视差空间;
a2、地面估计
在交通场景中,将所有的交通元素分为两类平面:一类是地面,用水平平面表示;另一类是车辆、树木和行人这类垂直于地面的物体,用垂直平面表示。对步骤a1得到的视差图进行处理,把视差图中每一行的相同视差值累加起来构建v-视差图。由于处于同一距离的地面在水平方向具有相同的视差值,加之视差图中距离人眼视角越近,视差值越大,所以v-视差图中的地面为一条从左上到右下的倾斜直线。利用hough直线变换检测v-视差图中的倾斜直线,并映射到视差图中,进而根据v-视差图中得到的倾斜直线方程滤除地面,完成地面估计,得到视差图。v-视差图中的倾斜直线公式如下:
式中,b是双目立体视觉系统中两个摄像机之间的基线距离,d是视差值,f是摄像机焦距,θ是摄像机主光轴方向与地面夹角,v是图像列坐标,h是世界坐标下的垂直距离。
a3、棒状像素提取
首先通过占位网格法计算出图像每一列的自由区域,进而找出地面与障碍物的交点;然后使用隶属度函数对图像每一列上的每个像素进行划分,当隶属度函数值为正时表示障碍物,为负时表示除了障碍物以外的背景,进而将障碍物的高度分割出来。一旦计算出每一列的自由区域和高度,就可以直接提取出如图2所示棒状像素。隶属度函数的公式如下:
式中,mu,v(d)是视差值d对应的隶属度函数值,u是图像的横坐标,v是图像的列坐标,d是视差值,
式中,
a4、检测障碍物
首先对视差图基于棒状像素表示的交通场景的障碍物所在区域的每一列的相同视差值累加起来,构建表示障碍物区域的u视差图,得到障碍物在u视差图中的左右边界的列坐标。然后根据障碍物的高度,标记出障碍物的位置。得到的结果如图3所示;
b、构建卷积神经网络模型,并对障碍物进行识别
b1、构建如图4所示的卷积神经网络模型
卷积神经网络模型从上往下,分别是卷积神经网络模型的输入和卷积神经网络模型的结构。卷积神经网络模型的输入尺寸大小是224×224×3,卷积神经网络模型网络模型的结构由四部分组成,前三部分卷积网络,最后一部分是全连接网络。第一部分由一个卷积层、一个批规范化(bn)层、一个激活函数(relu)层和一个最大池化层组成。第二部分也是由一个卷积层、一个批规范化(bn)层、一个激活函数(relu)层和一个最大池化层组成。第三部分由三个卷积层、三个批规范化(bn)层、三个激活函数(relu)层和一个最大池化层组成。最后一部分由三个全连接层、两个激活函数(relu)层、两个dropout层和一个softmax层组成。
b2、障碍物识别
b21、对卷积神经网络模型进行训练,即把步骤a得到的包含车辆或者行人的检测结果裁剪出来,做成训练样本,输入到卷积神经网络模型中;
b22、经过权重初始化过程,初始化网络模型中卷积层的权重和偏置;
b23、采用前向传播算法和反向传播算法,在训练集上迭代,训练出最优的卷积神经网络模型参数;
b24、卷积神经网络模型训练完之后,选取最优的卷积神经网络模型参数用于障碍物识别,最终输出的结果如图5所示。前向传播算法的计算公式如下:
式中,p'x=k是k类的真实概率分布,x为像素点,px=k为第k类的概率,l是损失值,n为小批量图像中的像素总数。反向传播算法的计算公式如下:
wt+1=wt+vt+1(5)
式中,vt+1是当前权重的更新值,vt是先前权重的更新值,μ是动量,α是学习率,wt+1是当前的权重矩阵,wt是先前的权重矩阵,
本发明不局限于本实施例,任何在本发明披露的技术范围内的等同构思或者改变,均列为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!