一种基于大数据技术的时空数据关联分析方法与流程
本发明涉及一种时空数据关联分析方法,特别是指一种基于特定行业大数据,采用挖掘频繁项集算法对时空轨迹数据关联分析的方法。
背景技术:
随着计算机技术的发展,各种分析方法现在已经很普遍的应用在了数据比较、数据统计、数据挖掘等领域中,然而传统的时空轨迹数据关联分析方法虽然逻辑比较简单但是比对、运行速度比较慢,效率不高,传统分析技术具体描述如下。
第一种比较典型的时空轨迹数据关联分析方法其具体步骤是在数据中提取一类需要关联的数据,循环该类数据列表,而后将需关联的数据分别逐一的与被关联数据进行对比,是否满足关联条件,并逐一反馈对比结果。因此当被比数据的种类多,并且数据量非常庞大的时候,此种分析方法的计算速度以及计算效率是非常低的。
第二种比较典型的数据关联分析方法是通过apriori关联规则算法分析出数据的关联性。具体步骤为,首先分析出所有的频集,并且频繁项集出现的频繁性大于等于预定义的最小支持度;然后根据频集产生强关联规则,关联规则必须满足最小支持度和最小可信度;然后分析出的频集产生期望的规则,产生只包含集合的项的所有规则,其中每一条规则的右部只有一项;一旦这些规则被生成,那么只有那些大于用户给定的最小可信度的规则才会作为结果最终输出。为了生成所有频集,apriori关联规则算法使用了递归的方法。因此apriori算法在产生频繁模式完全集前,需要对数据库进行多次扫描,同时产生大量的候选频繁集,使得apriori算法时间和空间复杂度较大。apriori算法在挖掘额长频繁模式的时候性能往往低下。
在大数据时代来临的背景下,上述传统的时空轨迹数据关联方法已经完全不能够满足人们快速数据关联与数据挖掘的需求,速度问题也是传统技术的主要缺点。
技术实现要素:
本发明提供一种基于大数据挖掘频繁项集算法的时空轨迹数据关联分析方法,其适用在关联分析数据量大,且需要即时反馈出关联分析结果的领域,本发明的时空轨迹数据管理分析方法效率高,运算速度快,能够快速即时反馈出时空轨迹数据关联的结果。
本发明所采用的技术方案为:一种基于大数据技术的时空数据关联分析方法,其包括如下步骤。
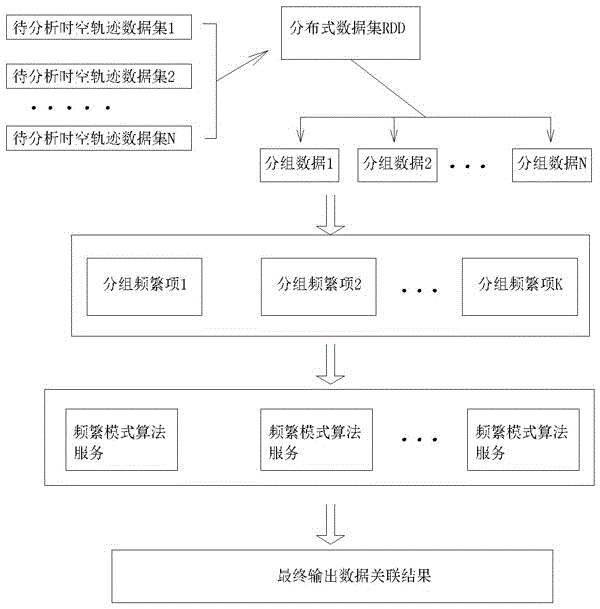
第一步.启动内存分析服务集群,之后启动分析服务容器,再从各类数据源获取各类数据,形成分布式数据集rdd,第二步.对第一步中拉取的分布式数据集rdd,按照不同的数据类型进行分组,并统计各类数据的总数,第三步.根据第二步得出的各类数据总数,计算出集合中某类总数最小的数据类型及其数据集,第四步.依据地理信息系统,确定地理范围内可能的产生关联关系的时间范围,第五步.循环第三步得到的数据总和最小的数据集,对每一条数据,在每一个地理范围内及第四步中所确定的合理时间范围,将其出现的所有类型的数据组成一个新的小集合,称之为n元项集,第六步.按照第五步,每循环一次生成一个新的小集合,最后生成一个大集合,大集合的元素由小集合组成,该大集合为频繁项集,第七步.确定多组数据同时出现会产生关联关系的次数,即最小支持度,至少为3次,第八步.将大集合及第七步确认的次数作为输入参数,输入经过改进后的fp-growth算法方法,修改内容为将输入参数中的频率改为频度,第九步.通过使用基于内存计算集群服务,结合大数据机器学习提供的具体数据挖掘服务,按照第八步的方法,对多元大集合进行挖掘分析,第十步.挖掘分析的过程中,首先扫描频繁项集,过滤掉小于最小支持度的项目,然后将原始数据集中的条目按项目集中降序进行排列,第十一步.扫描第十步中经过排序的数据集,创建项头表,并生成频繁模式树,第十二步.循环项头表的每个项,找到其条件模式基,递归调用树结构,删除小于最小支持度的项,如果最终呈现单一路径的树结构,则直接列举所有组合;非单一路径的则继续调用树结构,直到形成单一路径即可,第十三步.最终输入每个项的单一路径树结构数据集合。
第一步中,通过结合使用spark基于内存计算的技术,将需要分析的时空轨迹数据拉取到spark集群的内存中,形成分布式数据集rdd。若干条时空轨迹数据分别属于数据不同类型的数据。若干条时空轨迹数据分别数据不同的空间和时间维度。第十一步中项头表按降序排列。第十二步中按照从下往上的顺序循环项头表的每个项。
本发明的有益效果为:本发明在时空轨迹数据挖掘时,能够依据数据的空间和时间关系生成频繁项集,并且根据某一数据类型,其数据总量最小的集合循环生成所有频繁项集,将传统的数据挖掘分析算法的时间复杂度从o(n^n)提升至o(n)。通过优化挖掘频繁项集算法的输入参数频率改为频度,提升了数据分析的准确度。并且结合大数据基于内存计算的技术,极大的提升了时空轨迹数据的关联分析速度。本发明尤其适用关联分析数据种类繁多,每类数据量特别大,且需要快速分析出数据关联结果的数据挖掘领域。
附图说明
图1为本发明的原理方框示意图。
具体实施方式
如图1所示,一种基于大数据技术的时空数据关联分析方法,其包括如下步骤。
第一步.启动内存分析服务集群,之后启动分析服务容器,再从各类数据源获取各类数据,形成分布式数据集rdd。
在具体实施的时候,通过结合使用spark基于内存计算的技术,将需要分析的时空轨迹数据拉取到spark集群的内存中,形成分布式数据集rdd。
若干条时空轨迹数据分别属于数据不同类型的数据。
若干条时空轨迹数据分别数据不同的空间和时间维度。
比如根据条件从hbase中获取待分析车牌数据集、imsi数据集、mac数据集。
第二步.对第一步中拉取的分布式数据集rdd,按照不同的数据类型进行分组,并统计各类数据的总数。比如统计车牌数据总量为c1,imsi数据总量为c2,mac数据集总量为c3。
第三步.根据第二步得出的各类数据总数,计算出集合中某类总数最小的数据类型及其数据集。比如c1<c2<c3,则先获取车牌的数据集。
第四步.依据地理信息系统,确定地理范围内可能的产生关联关系的时间范围。比如:用户在某一区域的分析范围为500m,若该区域路段额车速限制为60km/h,则该区域30s范围内采集到的mac、imsi与30s的车牌是具有同时空关联关系的。
第五步.循环第三步得到的数据总和最小的数据集,对每一条数据,在每一个地理范围内及第四步中所确定的合理时间范围,将其出现的所有类型的数据组成一个新的小集合,称之为n元项集。比如,某一车牌,前后30s内的出现的mac和imsi数据,组成一个三元项集。
第六步.按照第五步,每循环一次生成一个新的小集合。最后生成一个大集合,大集合的元素由小集合组成,该大集合为频繁项集。
将时空轨迹数据的频繁项集生成的算法复杂度降低到o(n)。
第七步.确定多组数据同时出现会产生关联关系的次数,即最小支持度。至少为3次,默认也为3次。
第八步.将大集合及第七步确认的次数作为输入参数,输入经过改进后的fp-growth算法方法。主要修改内容为将输入参数中的频率改为频度。
fp-growth算法的改进,适用于时空轨迹分析的应用场景。
第九步.通过使用基于内存计算集群服务,结合大数据机器学习提供的具体数据挖掘服务,按照第八步的方法,对多元大集合进行挖掘分析。
第十步.挖掘分析的过程中,首先扫描频繁项集,过滤掉小于最小支持度的项目,然后将原始数据集中的条目按项目集中降序进行排列。比如:某一个车牌在频繁项集中仅出现两次,但最小支持度为3次,则会过滤掉该车牌出现的项集。
第十一步.扫描第十步中经过排序的数据集,创建项头表(按降序排列),并生成频繁模式树。
第十二步.循环项头表(按照从下往上的顺序)的每个项,找到其条件模式基,递归调用树结构,删除小于最小支持度的项。如果最终呈现单一路径的树结构,则直接列举所有组合;非单一路径的则继续调用树结构,直到形成单一路径即可。
第十三步.最终输入每个项的单一路径树结构数据集合。
每一个单一路径就是满足操作者关联关系要求的数据集合。
如下,结合具体应用方法对本发明的技术内容进行具体说明。
在公安业务具体案件的侦破过程中,通过卡口抓拍获取到了涉案的车牌信息,但是无法获取其手机信息。此时需要从海量数据中分析出其关联的手机mac信息。比如开车人分别经过卡口a、b、c、d…时,其手机信息也被采集,我们要做的就是从海量数据中,分析出卡口抓拍车牌时,同时采集到的手机信息。由于设备之间有一定的距离差,因此无法根据车牌的采集时间来定位手机采集的信息,根据距离差,预计采集时间相差10秒至1分钟不等。而这个时间段内,采集到的mac可能非常多,此时我们就需要使用到关联分析方法,从海量数据中,根据时空关联分析方法(本专利中提到的时空关联分析方法是指多条数据在多个时空,多次同时出现时,则表示这些数据是具有关联关系的),找到与车牌1关联的mac1及其他数据。具体分析步骤如下。
1.启动大数据内存计算集群,根据分析需求,拉取车牌数据集,mac数据集。
2.循环车牌数据,根据车牌采集时间,将其前后30秒出现的mac数据形成一个集合n1,最终所有的集合形成一个大的数据集n。
3.根据数据集n,扫描所有数据,把每个数据出现的次数记录下来,数据与数据出现的次数组成项头表x,接下来根据需求定义必须同时出现n次方可满足关联条件,过滤表x中,不满足n次的数据,得到项头表x1。
4.再次循环数据集n={n1,n2,n3…nm},首先将n1中未出现项头表x1中的数据删除,然后将n1的数据按照项头表x的升序进行排序,再循环子数据集n1={n1,n2,n3…nx}中的数据,并生成频繁模式树t,树节点为车牌或者mac数据,节点的值为车牌或者mac出现的次数。
5.按照降序循环项头表x1={a1,a2,a3…an}中的项,在频繁模式树t中找到项a1,以及项a1的叶子节点,删除不满足次数n的叶子节点,最终形成单一路径的树结构数据集y1。此时的数据集y1就是一组相关联的数据,表示的是该组数据内车牌与macn次及以上次数一起出现过。循环表x1结束后,最终每个项都会形成一个单一路径的树结构。
6.输出所有的单一路径的树结构数据集y={y1,y2,y3…yn},则构成最终结果集。
本发明在时空轨迹数据挖掘时,能够依据数据的空间和时间关系生成频繁项集,并且根据某一数据类型,其数据总量最小的集合循环生成所有频繁项集,将传统的数据挖掘分析算法的时间复杂度从o(n^n)提升至o(n)。通过优化fp-growth算法的输入参数频率改为频度,提升了数据分析的准确度。并且结合大数据基于内存计算的技术,极大的提升了时空轨迹数据的关联分析速度。本发明尤其适用于关联分析数据种类繁多,每类数据量特别大,且需要快速分析出数据关联结果的数据挖掘领域。
- 还没有人留言评论。精彩留言会获得点赞!