一种类案推荐方法、系统及装置与流程
本发明涉及推荐技术领域,尤其涉及一种类案推荐方法、系统及装置。
背景技术:
现有的类案推荐系统在实践中主要有两种形态:第一种是自动推送,自动推送是技术人员依托网上公布的裁判文书建立数据库,在此基础上对相关案件“贴标签”,将每个具体案例结构化为数十个法律标签。再将起诉书接入系统,与系统中的标签对比,推送标签最相似的案例;第二种是主动搜索,主动搜索是指法官对系统自动推送的类案不满意时,自主选取系统中罗列出的标签,在此基础上输入关键词,通过一整套的标签和自主搜索,在数据库中检索符合条件的类案。但是这两种推荐系统普遍存在推送类案不准确、案情细节不匹配等问题。
技术实现要素:
为了解决上述技术问题,本发明的目的提供一种能提高推荐精准度的类案推荐方法、系统及装置。
本发明所采取的技术方案是:
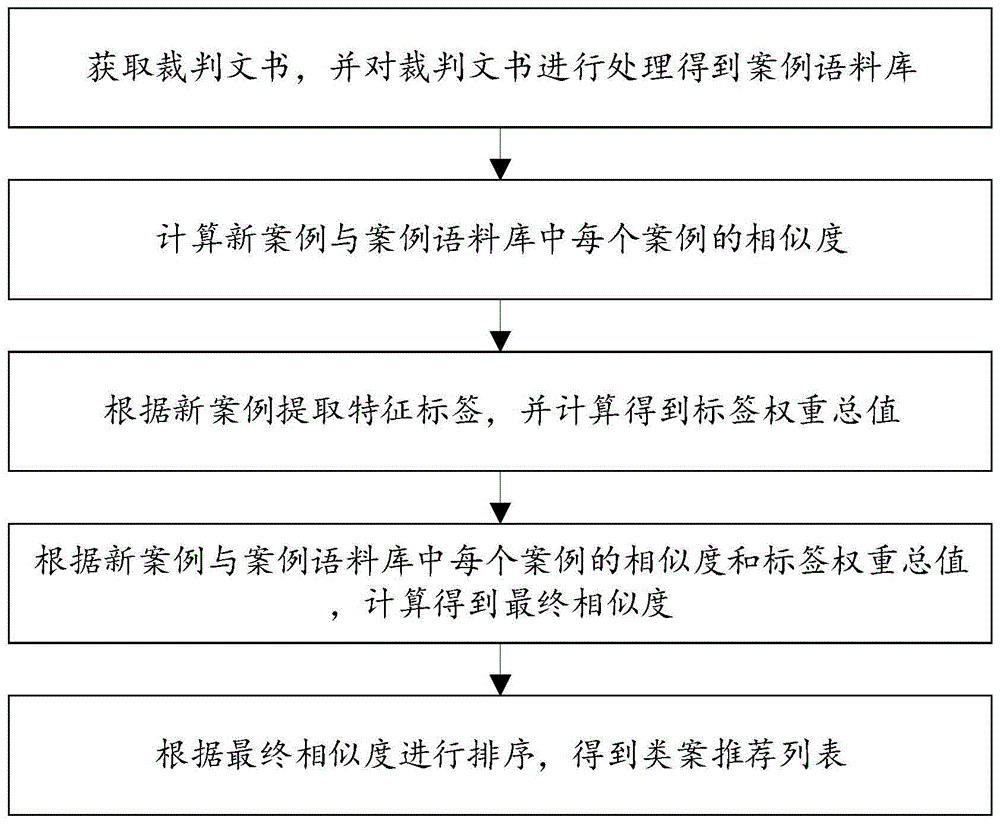
一种类案推荐方法,包括以下步骤:
获取裁判文书,并对裁判文书进行处理得到案例语料库;
计算新案例与案例语料库中每个案例的相似度;
根据新案例提取特征标签,并计算得到标签权重总值;
根据新案例与案例语料库中每个案例的相似度和标签权重总值,计算得到最终相似度;
根据最终相似度进行排序,得到类案推荐列表。
作为所述的一种类案推荐方法的进一步改进,所述的获取裁判文书,并对裁判文书进行处理得到案例语料库,这一步骤具体包括:
获取裁判文书,并从裁判文书中提取得到各案例的诉讼案情信息;
对诉讼案情信息进行分词处理,得到案例文件语料;
调用doc2vec模型对案例文件语料进行训练,得到词向量、softmax参数和文档向量,形成得到案例语料库。
作为所述的一种类案推荐方法的进一步改进,所述的计算新案例与案例语料库中每个案例的相似度,这一步骤具体包括:
根据案例语料库的词向量和softmax参数,计算得出新案例的文档向量;
计算新案例的文档向量与案例语料库中每个案例的文档向量之间的计算欧式距离,得到新案例与案例语料库中每个案例的相似度。
作为所述的一种类案推荐方法的进一步改进,所述的根据新案例提取特征标签,并计算得到标签权重总值,这一步骤具体包括:
根据新案例的诉讼案情信息提取特征标签,并对其标准格式化,得到新案例的标签值;
根据预设的权重定义规则和新案例的标签值,对新案例的标签权重因子进行设定;
根据新案例的标签值和标签权重因子,计算得到标签权重总值。
作为所述的一种类案推荐方法的进一步改进,所述的最终相似度的计算公式为:
wt=0.5*w1+(1-0.5)*(1/(1+lnw2));
其中,wt表示最终相似度,w1表示相似度,w2表示标签权重总值。
本发明所采用的另一个技术方案是:
一种类案推荐系统,包括:
案例语料库生成单元,用于获取裁判文书,并对裁判文书进行处理得到案例语料库;
相似度计算单元,用于计算新案例与案例语料库中每个案例的相似度;
标签单元,用于根据新案例提取特征标签,并计算得到标签权重总值;
最终相似度计算单元,用于根据新案例与案例语料库中每个案例的相似度和标签权重总值,计算得到最终相似度;
列表生成单元,用于根据最终相似度进行排序,得到类案推荐列表。
作为所述的一种类案推荐系统的进一步改进,所述的案例语料库生成单元具体包括:
获取单元,用于获取裁判文书,并从裁判文书中提取得到各案例的诉讼案情信息;
分词单元,用于对诉讼案情信息进行分词处理,得到案例文件语料;
训练单元,用于调用doc2vec模型对案例文件语料进行训练,得到词向量、softmax参数和文档向量,形成得到案例语料库。
作为所述的一种类案推荐系统的进一步改进,所述的相似度计算单元具体包括:
文档向量计算单元,用于根据案例语料库的词向量和softmax参数,计算得出新案例的文档向量;
欧式距离计算单元,用于计算新案例的文档向量与案例语料库中每个案例的文档向量之间的计算欧式距离,得到新案例与案例语料库中每个案例的相似度。
作为所述的一种类案推荐系统的进一步改进,所述的标签单元具体包括:
标准化单元,用于根据新案例的诉讼案情信息提取特征标签,并对其标准格式化,得到新案例的标签值;
标签权重因子设定单元,用于根据预设的权重定义规则和新案例的标签值,对新案例的标签权重因子进行设定;
标签权重总值计算单元,用于根据新案例的标签值和标签权重因子,计算得到标签权重总值。
本发明所采用的再一个技术方案是:
一种类案推荐装置,包括:
至少一个处理器;
至少一个存储器,用于存储至少一个程序;
当所述至少一个程序被所述至少一个处理器执行,使得所述至少一个处理器实现所述一种类案推荐方法。
本发明的有益效果是:
本发明一种类案推荐方法、系统及装置通过提取标签算得标签权重总值,进而计算得到最终相似度,最后根据最终相似度进行排序列表,克服了原来的标签模型没有语义的缺点,大大提高了类案推荐的精准度。
附图说明
图1是本发明一种类案推荐方法的步骤流程图;
图2是本发明一种类案推荐系统的模块方框图。
具体实施方式
下面结合附图对本发明的具体实施方式作进一步说明:
参考图1,本发明一种类案推荐方法,包括以下步骤:
获取裁判文书,并对裁判文书进行处理得到案例语料库;
计算新案例与案例语料库中每个案例的相似度;
根据新案例提取特征标签,并计算得到标签权重总值;
根据新案例与案例语料库中每个案例的相似度和标签权重总值,计算得到最终相似度;
根据最终相似度进行排序,得到类案推荐列表。
进一步作为优选的实施方式,所述的获取裁判文书,并对裁判文书进行处理得到案例语料库,这一步骤具体包括:
获取裁判文书,并从裁判文书中提取得到各案例的诉讼案情信息;
对诉讼案情信息进行分词处理,得到案例文件语料;
调用doc2vec模型对案例文件语料进行训练,得到词向量、softmax参数和文档向量,形成得到案例语料库。
本实施例中,所述裁判文书可从裁判文书网进行下载,从裁判文书中提取得到各案例的诉讼案情信息可采用正则表达式实现,本实施例正则表达式如下:
诉称[,:](?p<ss_sc>.*),请求:
事实.*理由:(?p<ss_sc>.*)。#\$#本院经审理
辩称:(?p<ss_bc>.*)。#
进一步作为优选的实施方式,所述的计算新案例与案例语料库中每个案例的相似度,这一步骤具体包括:
根据案例语料库的词向量和softmax参数,计算得出新案例的文档向量;
计算新案例的文档向量与案例语料库中每个案例的文档向量之间的计算欧式距离,得到新案例与案例语料库中每个案例的相似度。
进一步作为优选的实施方式,所述的根据新案例提取特征标签,并计算得到标签权重总值,这一步骤具体包括:
根据新案例的诉讼案情信息提取特征标签,并对其标准格式化,得到新案例的标签值;
根据预设的权重定义规则和新案例的标签值,对新案例的标签权重因子进行设定;
根据新案例的标签值和标签权重因子,计算得到标签权重总值。
其中,特征标签的提取根据诉讼案情。不同案由的标签,以判决结果关联的特征为主。
举例:民间借贷纠纷,提取的特征标签包括:借款金额、借款利率、借款利息、借款周期、连带关系、借款用途、还款日期、延迟履行利息等。如借款金额<=1w,取值1;借款金额>1w且<=5w取值2;借款金额>5w并且<=20w取值3;借款金额>20w且小于100w取值4;借款金额>100w<=500w取值5,大于500w取值6;
标权重因子的定义,根据各个标签的在所有同案由案例中出现频率和对判决结论的重要性定义标签的权重因子。举例:借款金额:2;借款利率:2。
进一步作为优选的实施方式,所述的最终相似度的计算公式为:
wt=0.5*w1+(1-0.5)*(1/(1+lnw2));
其中,wt表示最终相似度,w1表示相似度,w2表示标签权重总值。
参考图2,本发明一种类案推荐系统,包括:
案例语料库生成单元,用于获取裁判文书,并对裁判文书进行处理得到案例语料库;
相似度计算单元,用于计算新案例与案例语料库中每个案例的相似度;
标签单元,用于根据新案例提取特征标签,并计算得到标签权重总值;
最终相似度计算单元,用于根据新案例与案例语料库中每个案例的相似度和标签权重总值,计算得到最终相似度;
列表生成单元,用于根据最终相似度进行排序,得到类案推荐列表。
进一步作为优选的实施方式,所述的案例语料库生成单元具体包括:
获取单元,用于获取裁判文书,并从裁判文书中提取得到各案例的诉讼案情信息;
分词单元,用于对诉讼案情信息进行分词处理,得到案例文件语料;
训练单元,用于调用doc2vec模型对案例文件语料进行训练,得到词向量、softmax参数和文档向量,形成得到案例语料库。
进一步作为优选的实施方式,所述的相似度计算单元具体包括:
文档向量计算单元,用于根据案例语料库的词向量和softmax参数,计算得出新案例的文档向量;
欧式距离计算单元,用于计算新案例的文档向量与案例语料库中每个案例的文档向量之间的计算欧式距离,得到新案例与案例语料库中每个案例的相似度。
进一步作为优选的实施方式,所述的标签单元具体包括:
标准化单元,用于根据新案例的诉讼案情信息提取特征标签,并对其标准格式化,得到新案例的标签值;
标签权重因子设定单元,用于根据预设的权重定义规则和新案例的标签值,对新案例的标签权重因子进行设定;
标签权重总值计算单元,用于根据新案例的标签值和标签权重因子,计算得到标签权重总值。
本发明一种类案推荐装置,包括:
至少一个处理器;
至少一个存储器,用于存储至少一个程序;
当所述至少一个程序被所述至少一个处理器执行,使得所述至少一个处理器实现所述一种类案推荐方法。
本发明通过提取标签算得标签权重总值,进而计算得到最终相似度,最后根据最终相似度进行排序列表,克服了原来的标签模型没有语义的缺点,大大提高了类案推荐的精准度。原来使用的按标签推荐的相似案例,能达到65%的准确率,跟行业60%-70%的准确率接近。引入doc2vec的文档向量表达模型后,包含了语义的影响,推荐类案准确率普遍超过80%。
以上是对本发明的较佳实施进行了具体说明,但本发明创造并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做作出种种的等同变形或替换,这些等同的变形或替换均包含在本申请权利要求所限定的范围内。
- 还没有人留言评论。精彩留言会获得点赞!