一种基于群智能寻优的采煤机在线故障诊断系统的制作方法
本发明涉及故障诊断领域、机器学习领域和群智能优化算法领域,尤其涉及一种基于群智能寻优的采煤机在线故障诊断系统。
背景技术:
我国是个能源消费大国,随着国民经济的发展,对能源的需求越来越大。煤炭作为工业动力燃料的化工产业原材料,是能源的主体,而且煤炭是全世界蕴藏量最丰富的化石燃料,必须充分利用丰富的煤炭资源。但是煤炭产业是一把双刃剑,不走科学发展的道路,就会带来污染、安全等一系列问题。因此,根据我国的能源国情,煤炭资源的合理开采与利用是今后重要的研究课题。
近年来,随着科技的发展,煤炭开采逐步机械化,提高了劳动生产率,增加了煤炭产量,减少了重大恶性事故的发生。其中,采煤机作为煤炭生产中的核心设备,受到人们的普遍关注。但是由于其工作环境复杂恶劣,载荷变化很大,一些关键部位在生产工作中很容易发生过载,出现异常,而且自身的组成结构复杂,因此产生故障的原因也随之复杂。一旦采煤机发生了故障,也就意味着煤矿停产,造成整个煤矿生产系统的瘫痪以及很大的人力、财力浪费。因此,预防和减少采煤机的故障,以及出现故障后准确判断并及时排除故障,对发挥采煤机的效能,增加煤炭产量具有重要意义。
然而,由于在线故障诊断仪表的缺乏和高成本,采煤机故障的在线诊断目前很难做到。因此,利用采煤机运行时的各种特征参数来识别采煤机的运行状态,确定故障发生的部位和严重程度,分析故障发生的原因,从而保证采煤机在一定的工作环境和工作期限内可靠、有效地运行,成为生产中急需解决的一个瓶颈问题。采煤机的在线故障诊断系统及方法研究具有重要的现实意义。
技术实现要素:
为了克服目前已有的采煤机故障诊断精度不高、易受人为因素的影响的不足,本发明的目的在于提供一种基于群智能寻优的采煤机在线故障诊断系统,能够实现采煤机故障的在线诊断、在线参数优化、模型自动更新,以提高采煤机故障诊断的效率和准确率。
本发明的目的是通过以下技术方案实现的:一种基于群智能寻优的采煤机在线故障诊断系统,用于对采煤机运行过程中出现的故障进行诊断,包括数据预处理模块、随机森林模型模块、自适应群智能优化模块以及模型更新模块。
进一步地,所述数据预处理模块以电牵引采煤机运行过程中的故障为对象,分析所有可能发生的故障征兆和导致故障征兆的原因,建立故障征兆集x和原因集y,将从dcs数据库输入的模型输入变量进行预处理,对输入变量中心化,即减去变量的平均值,再进行归一化处理,即除以变量值的变化区间,得到训练样本集。提取故障征兆集x的时域特征向量,将得到的时域特征向量组合成为特征向量w。
进一步地,所述随机森林模型模块采用随机森林分类器进行分类,随机森林分类器采用回归树作为弱学习器,并对基本的决策树进行优化,从而实现对采煤机的故障进行分类:
(1)利用bootstrap重采样方法从原始训练样本集中抽取e个特征向量样本生成一个子样本集;
(2)利用每个子样本集,生长为单棵分类树;
(3)在分类树的每个节点处,从e个特征向量中随机挑选e个特征向量,按照节点不纯度最小的原则,从这e个特征向量中选出一个特征向量γ作为该节点的分类属性;
(4)根据特征向量γ将节点分成2个分支,然后再从剩下的特征向量中寻找分类效果最好的特征向量作为其他节点的分类属性,如此递归构造分类树的分支,使分类树能充分生长,每个节点的不纯度达到最小,而不进行剪枝;直到这棵树能准确地分类训练集,或者所有属性使用完;
(5)所有子样本集生成的分类树组成随机森林,对特征向量w进行判别与分类,按分类器的投票多少,输出故障分类结果。
进一步地,所述自适应群智能优化模块,用于采用引力搜索算法对随机森林模块的参数进行优化,包括:
(1)算法初始化,随机初始化所有粒子,每个粒子代表问题的一个候选解。在一个d维的搜索空间中,假设有np个粒子,定义第i个粒子的位置为:
设定迭代结束条件,即最大迭代次数itermax。
(2)在某t时刻,定义第j个粒子作用在第i个粒子上的引力大小
式中,maj(t)和mpi(t)分别为作用粒子j的惯性质量和被作用粒子i的惯性质量,rij(t)是第i个粒子和第j个粒子之间的欧氏距离,ε是一个很小的常量,g(t)是在t时刻的引力常数:
式中,α是下降系数,g0是初始引力常数,itermax是最大迭代次数。
(3)假设t时刻在第d维作用在第i个粒子上的总作用力
式中,randj是范围在[0,1]的随机数,kbest是一开始具有最佳适应度的前k个粒子的集合。
根据牛顿第二定律,t时刻粒子i在第d维的加速度
式中,mi(t)是第i个粒子的惯性质量。
(4)在下一次迭代中,粒子的新速度为部分当前速度与其加速度的总和。因此,引力搜索算法在每一次迭代运算过程中,粒子都会根据以下公式更新它的速度和位置:
xi(t+1)=xi(t)+vi(t+1)(7)
式中,vi(t)是粒子i在第t次迭代的速度,xi(t)是粒子i在第t次迭代的位置,ai(t)是粒子i在第t次迭代的加速度,randi是范围在[0,1]的随机数。
(5)粒子的惯性质量依据其适应度值的大小来计算,惯性质量越大表明它越接近最优值,同时意味着该粒子的吸引力越大,但其移动速度却越慢。假设引力质量mai与惯性质量mpi相等,粒子的质量mi可以通过适当的运算规则去更新,更新算法如下所示:
mai=mpi=mi,i=1,2,...,np(8)
式中,fiti(t)代表在t时刻第i个粒子的适应度值的大小。对求解最小值问题,best(t)和worst(t)定义如下:
对求解最大值问题,best(t)和worst(t)定义如下:
(6)重复以上步骤直至达到最大迭代次数,选取适应度值最优的解作为算法的最优解,结束算法并返回。
进一步地,所述模型更新模块用于模型的在线更新,定期将离线化验数据输入到训练集中,更新随机森林模型。
本发明的有益效果主要表现在:能在线诊断采煤机运行过程的故障类别,克服已有的采煤机故障诊断仪表测量精度不高、易受人为因素的影响的不足,引入群智能优化模块对随机森林参数和结构进行自动优化,不需要人为经验或多次测试来调整随机森林模型,提高了采煤机故障诊断的效率和准确率。
附图说明
图1一种基于群智能寻优的采煤机在线故障诊断系统的整体架构图;
图2一种基于群智能寻优的采煤机在线故障诊断系统的功能结构图。
具体实施方式
下面结合附图对本发明做进一步描述。本发明实施例用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明作出的任何修改和改变,都落入本发明的保护范围。
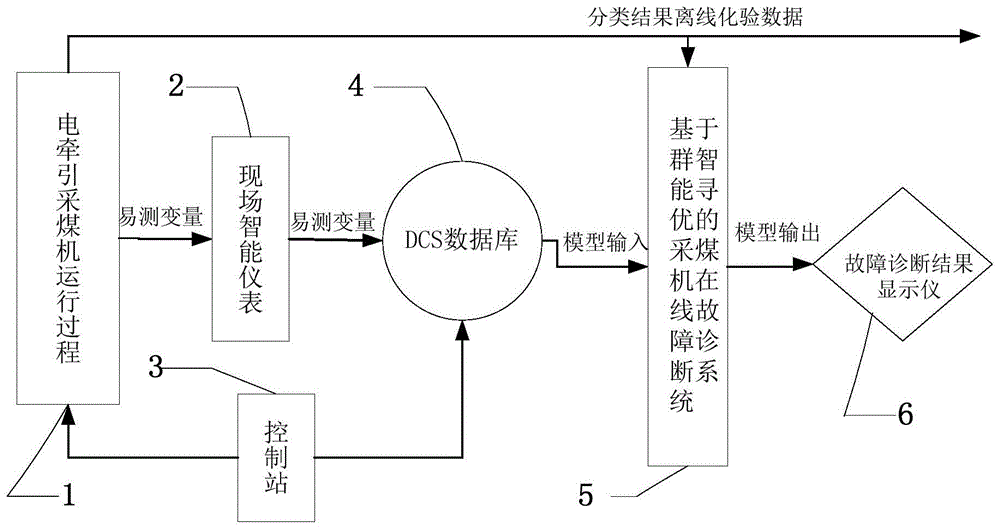
参照图1和图2,一种基于群智能寻优的采煤机在线故障诊断系统5,用于对电牵引采煤机运行过程1中出现的故障进行诊断,包括数据预处理模块7、随机森林模型模块8、自适应群智能优化模块9以及模型更新模块10。
进一步地,所述数据预处理模块7,以电牵引采煤机运行过程1为诊断对象,分析所有可能发生的故障征兆和导致故障征兆的原因,建立故障征兆集x和原因集y,根据搜集的资料、实际调查、维修工程师和专家经验得出故障征兆集x={x1,x2,…,x9}和原因集y={y1,y2,…,y7},如表1所示。dcs数据库4存储由现场智能仪表2测量的数据,将从dcs数据库4输入的模型输入变量进行预处理,对输入变量中心化,即减去变量的平均值,使变量为零均值的变量,再进行归一化处理,即除以变量值的变化区间,使变量的值落到-0.5~0.5之内。提取故障征兆集x的时域特征向量,将得到的时域特征向量组合成为特征向量w。
表1
进一步地,所述随机森林模型8采用随机森林分类器进行分类,随机森林分类器采用回归树作为弱学习器,并对基本的决策树进行优化,从而实现对采煤机的故障进行分类:
(1)随机森林每次利用bootstrap重采样方法从原始训练样本集中抽取63.2%的样本生成一个子样本集,每一个子样本对应着一棵分类树;
(2)利用每个子样本集,生长为单棵分类树;
(3)在树的每个节点处,从e个特征向量中随机挑选e个特征向量,根据经验公式,通常取
(4)根据特征向量γ将节点分成2个分支,然后再从剩下的特征向量中寻找分类效果最好的特征向量作为其他节点的分类属性,如此递归构造分类树的分支,使分类树能充分生长,每个节点的不纯度达到最小,而不进行剪枝;直到这棵树能准确地分类训练集,或者所有属性使用完;
(5)在分类阶段,分类标签cp是由所有分类树的结果综合而成。随机森林使用的是投票原则,即
其中,n是森林中决策树的数目,i(*)是示性函数,nhi,c是第i棵树hi对类c的分类结果,nhi是第i棵树hi的叶子节点数;
(6)将生成的多棵分类树组成随机森林,用随机森林分类器对新的数据进行判别与分类,分类结果按树分类器的投票多少而定,输出故障分类结果。
进一步地,所述自适应群智能优化模块9,采用引力搜索算法对随机森林模块8的参数进行优化,包括:
(1)算法初始化,随机初始化所有粒子,每个粒子代表问题的一个候选解。在一个d维的搜索空间中,假设有np个粒子,定义第i个粒子的位置为:
设定迭代结束条件,即最大迭代次数itermax。
(2)在某t时刻,定义第j个粒子作用在第i个粒子上的引力大小
式中,maj(t)和mpi(t)分别为作用粒子j的惯性质量和被作用粒子i的惯性质量,rij(t)是第i个粒子和第j个粒子之间的欧氏距离,ε是一个很小的常量,g(t)是在t时刻的引力常数:
式中,α是下降系数,g0是初始引力常数,itermax是最大迭代次数。
(3)假设t时刻在第d维作用在第i个粒子上的总作用力
式中,randj是范围在[0,1]的随机数,kbest是一开始具有最佳适应度的前k个粒子的集合。
根据牛顿第二定律,t时刻粒子i在第d维的加速度
式中,mi(t)是第i个粒子的惯性质量。
(4)在下一次迭代中,粒子的新速度为部分当前速度与其加速度的总和。因此,引力搜索算法在每一次迭代运算过程中,粒子都会根据以下公式更新它的速度和位置:
xi(t+1)=xi(t)+vi(t+1)(7)
式中,vi(t)是粒子i在第t次迭代的速度,xi(t)是粒子i在第t次迭代的位置,ai(t)是粒子i在第t次迭代的加速度,randi是范围在[0,1]的随机数。
(5)粒子的惯性质量依据其适应度值的大小来计算,惯性质量越大表明它越接近最优值,同时意味着该粒子的吸引力越大,但其移动速度却越慢。假设引力质量mai与惯性质量mpi相等,粒子的质量mi可以通过适当的运算规则去更新,更新算法如下所示:
mai=mpi=mi,i=1,2,...,np(8)
式中,fiti(t)代表在t时刻第i个粒子的适应度值的大小。对求解最小值问题,best(t)和worst(t)定义如下:
对求解最大值问题,best(t)和worst(t)定义如下:
(6)重复以上步骤直至达到最大迭代次数,选取适应度值最优的解作为算法的最优解,结束算法并返回。
进一步地,所述模型更新模块10用于模型的在线更新,定期将离线化验数据输入到训练集中,更新随机森林模型8。
本实施例的方法具体实施步骤如下:
步骤1:对电牵引采煤机运行过程1,根据工艺分析和操作分析,选择操作变量和易测变量作为模型的输入;
步骤2:对样本数据进行预处理,由数据预处理模块7完成;
步骤3:基于模型输入、输出建立初始随机森林模型8。输入数据如步骤1所述获得,输出数据由离线化验获得;
步骤5:由自适应群智能优化模块9优化初始随机森林模型8的输入和模型结构;
步骤6:模型更新模块10定期将离线化验数据输入到训练集中,更新随机森林模型8,一种基于群智能寻优的采煤机在线故障诊断系统5建立完成;
步骤7:建立好的一种基于群智能寻优的采煤机在线故障诊断系统5基于dcs数据库4传来的实时模型输入变量数据对电牵引采煤机运行过程1的故障进行基于群智能寻优的最优诊断;
步骤8:故障诊断结果显示仪6显示基于群智能寻优的采煤机在线故障诊断系统5的输出,完成对电牵引采煤机运行过程的最优故障诊断的显示。
- 还没有人留言评论。精彩留言会获得点赞!