一种基于文本表示学习的跨领域情感分类系统及方法与流程
本发明涉及情感分析和观点挖掘领域,特别是一种基于文本表示学习的跨领域情感分类系统及方法。
背景技术:
当前,有很多技术方法可用于文本情感分类。传统的文本情感分类方法主要基于有监督的机器学习的方法,主要通过提取文本中的情感特征,使用支持向量机(svms)等分类器进行情感分类。这一类基于特征工程与浅层线性模型的方法虽然取得了一定的成效,但是当训练领域与测试领域的情感特征分布不同时,情感特征的迁移性较差,传统的情感分类方法无法有效地进行跨领域情感分类,需要耗费大量的时间和精力重新设计目标领域的情感特征,并且受限于人工设计的规则和特征的有效性以及模型的学习能力。而且有监督方法准确度较高,但在目标领域没有标注数据时,如何利用领域之间的联系,从而学习一个跨领域的文本特征表示空间,是跨领域情感分类的问题关键。
当前,存在着一些基于特征选择的跨领域情感分类方法。在跨领域情感分类中,在目标领域与源领域中都频繁出现的特征称为枢轴特征,研究者们从两个领域中的原始特征集中挖掘枢轴特征和非枢轴特征,构建领域特征间的映射关系,寻找统一的情感特征空间。这类方法通常利用人工设计的特征或使用n元语法模型提取特征,无法充分高效地对跨领域文本进行表示。
当前,存在着一些基于特征表示学习的跨领域情感分类方法。近年来随着深度学习的快速发展,利用神经网络模型对文本进行表示学习在语义表示和情感分析运用方面更具优势。许多研究者们也将这些模型用于跨领域情感分类中。神经网络模型与特征选择的方法相比,能够自动地从文本数据中学习文本表示,从而避免了大量的特征工程,但需要目标领域的标注数据进行有效训练。有些研究者利用领域对抗的方法同时进行领域分类和情感分类,从而学习一个领域适应的特征表示空间,但未充分考虑文本表示学习中的噪声问题,仍有很大的探索空间
因此人们希望找到一种更加高效的跨领域情感分类方法,进而提高跨领域情感分类的精度和减少人工时间精力的消耗。
技术实现要素:
有鉴于此,本发明的目的是提出一种基于文本表示学习的跨领域情感分类系统及方法,能够自动抽取出目标领域与源领域的潜在通用特征,并对特征进行抽象和组合,最终识别出目标领域文本的情感类别。
本发明采用以下方案实现:一种基于文本表示学习的跨领域情感分类系统,具体包括:
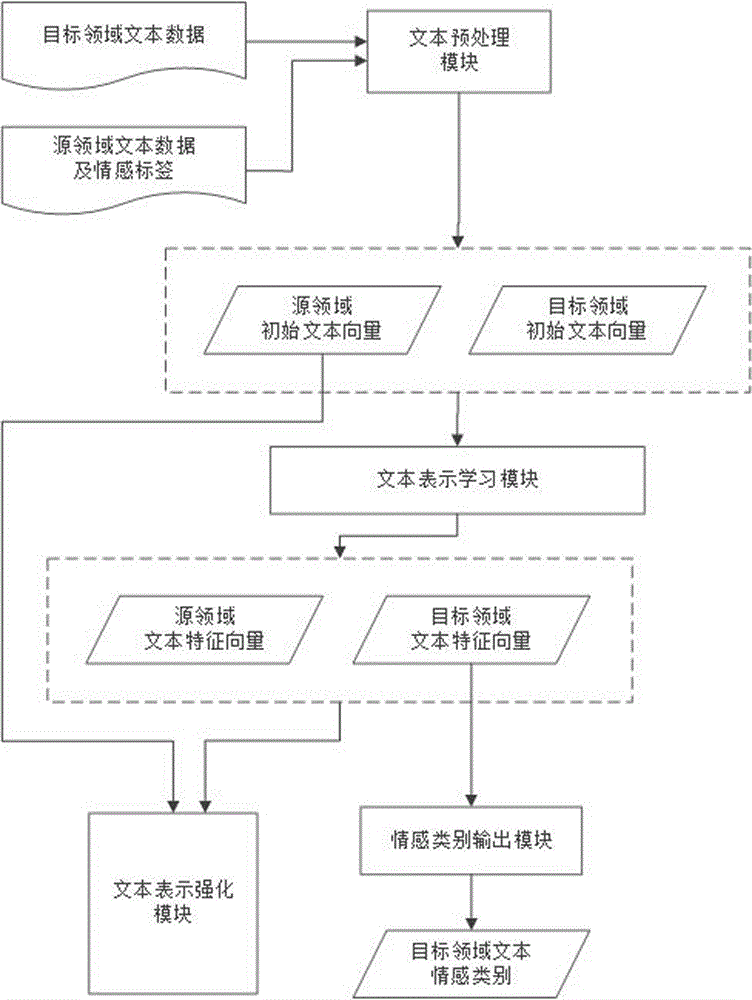
一个文本预处理模块,用于对跨领域文本进行特征化处理,得到源领域与目标领域的初始文本向量;
一个文本表示学习模块,接收文本预处理模块的输出,用于学习领域适应的特征表示空间,挖掘出源领域与目标领域潜在的通用领域特征和情感特征,得到源领域与目标领域的文本特征向量;
一个文本表示强化模块,生成对抗网络模型用于自动生成鲁棒的源领域文本表示并判别其情感类别,根据误差不断更新与优化文本表示学习模块的参数;
一个情感类别输出模块,根据文本表示学习模块输出的目标领域的文本特征向量并利用分类函数得到目标领域的文本情感分类结果。
进一步地,所述文本预处理模块利用n-gram文法提取源领域与目标领域文本的特征,并利用边缘堆叠降噪自编码器学习跨领域文本的特征表示,无需目标领域的情感标签。
较佳的,边缘堆叠降噪自编码器使用更少的计算量和具有对高维特征的扩展性,实现领域特征的抽象化。
进一步地,所述文本表示学习模块利用神经网络对领域适应的特征表示进行学习,同时考虑了不同领域文本中的领域特征和情感特征。
进一步地,所述神经网络对文本特征进行抽象化,从而得到领域适应的特征表示向量,即源领域文本特征向量与目标领域文本特征向量。
进一步地,所述文本表示强化模块中构建生成对抗网络模型,考虑了文本表示学习模块中存在的噪声特征问题。
进一步地,所述生成对抗网络模型包括生成网络和判别网络,在两者对抗学习中强化文本表示空间;所述的生成网络通过在文本表示向量中加入噪声向量合成假样本以迷惑判别网络的判断,判别网络同时进行情感分类和真假样本的判断,进一步优化文本表示学习模块。
进一步地,所述的生成网络利用正态分布产生随机噪声向量,生成的合成向量通过模块的优化更接近源领域样本。
进一步地,所述判别网络同时进行情感分类和真假样本的判断,考虑了领域特征和情感特征对跨领域情感分类的贡献程度,权衡两个因素对结果的影响程度。
进一步地,所述情感类别输出模块采用softmax函数对所得到的文本表示向量进行处理,预测各文本的情感类别。
本发明还提供了一种基于上文所述的基于文本表示学习的跨领域情感分类系统的方法,具体包括以下步骤:
步骤s1:所述文本预处理模块接收源领域文本数据及情感标签、目标领域文本数据,对跨领域文本进行特征化处理,得到源领域与目标领域的初始文本向量;
步骤s2:所述文本表示学习模块将文本预处理模块的输出作为输入,学习领域适应的特征表示空间,挖掘出源领域与目标领域潜在的通用领域特征和情感特征,得到源领域与目标领域的文本特征向量;
步骤s3:所述文本表示强化模块生成对抗网络模型用于自动生成鲁棒的源领域文本表示并判别其情感类别,根据误差不断更新与优化文本表示学习模块的参数;
步骤s4:所述情感类别输出模块接收优化后的文本表示学习模块输出的文本特征向量,并利用分类函数得到目标领域的文本情感分类结果。
特别的,在模型的训练阶段,根据信息的前向传播和误差的后向传播将不断地对他们进行调整,逐步优化目标函数。
与现有技术相比,本发明有以下有益效果:本发明提出的方法能够自动抽取出目标领域与源领域的潜在通用特征,并对特征进行抽象和组合,最终识别出目标领域文本的情感类别。
附图说明
图1为本发明实施例的原理示意图。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
应该指出,以下详细说明都是示例性的,旨在对本申请提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本申请所属技术领域的普通技术人员通常理解的相同含义。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本申请的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
如图1所示,本实施例提供了一种基于文本表示学习的跨领域情感分类系统,具体包括:
一个文本预处理模块,用于对跨领域文本进行特征化处理,得到源领域与目标领域的初始文本向量;
一个文本表示学习模块,接收文本预处理模块的输出,用于学习领域适应的特征表示空间,挖掘出源领域与目标领域潜在的通用领域特征和情感特征,得到源领域与目标领域的文本特征向量;
一个文本表示强化模块,生成对抗网络模型用于自动生成鲁棒的源领域文本表示并判别其情感类别,根据误差不断更新与优化文本表示学习模块的参数;
一个情感类别输出模块,根据文本表示学习模块输出的目标领域的文本特征向量并利用分类函数得到目标领域的文本情感分类结果。
在本实施例中,所述文本预处理模块利用n-gram文法提取源领域与目标领域文本的特征,并利用边缘堆叠降噪自编码器学习跨领域文本的特征表示,无需目标领域的情感标签。
较佳的,在本实施例中,边缘堆叠降噪自编码器使用更少的计算量和具有对高维特征的扩展性,实现领域特征的抽象化。
具体的,在文本预处理模块中,由于神经网络的输入数据一般为向量,以便模型的端到端训练,因此需要对文本数据进行向量化表示。为了便于数据的处理和分析,在文本预处理模块,本实施例首先对源领域和目标领域的文本进行分词并过滤停用词;接着,提取文本的unigram/bigram特征将文本数据从文本形式转换成向量形式;最后为了得到更鲁棒的特征表示,训练边缘堆叠降噪自编码器以得到源领域和目标领域的初始文本向量。
在本实施例中,所述文本表示学习模块利用神经网络对领域适应的特征表示进行学习,同时考虑了不同领域文本中的领域特征和情感特征。
在本实施例中,所述神经网络对文本特征进行抽象化,从而得到领域适应的特征表示向量,即源领域文本特征向量与目标领域文本特征向量。
具体的,所述文本表示学习模块是一个多层感知器,通过优化网络的权重矩阵,从而捕获文本的抽象化向量表示。
在本实施例中,所述文本表示强化模块中构建生成对抗网络模型,考虑了文本表示学习模块中存在的噪声特征问题。
在本实施例中,所述生成对抗网络模型包括生成网络和判别网络,在两者对抗学习中强化文本表示空间;所述的生成网络通过在文本表示向量中加入噪声向量合成假样本以迷惑判别网络的判断,判别网络同时进行情感分类和真假样本的判断,进一步优化文本表示学习模块。
在本实施例中,所述的生成网络利用正态分布产生随机噪声向量,生成的合成向量通过模块的优化更接近源领域样本。
在本实施例中,所述判别网络同时进行情感分类和真假样本的判断,考虑了领域特征和情感特征对跨领域情感分类的贡献程度,权衡两个因素对结果的影响程度。
具体的,所述文本表示强化模块是一个生成对抗网络模型,由生成网络和判别网络两个部分组成。生成网络的核心是利用正态分布随机生成的噪声向量与文本表示向量进行拼接,经过特征抽取后得到抽象化的假样本文本向量,判别网络对生成网络生成的假样本与源领域真实样本进行真假判断,并且对源领域样本的情感类别进行预测并计算其与实际情感标签的误差,利用随机梯度和后向传播对文本表示学习模块的参数进行优化更新,在生成网络与判别网络的生成与对抗学习中,从而达到强化文本表示的目的,使文本表示学习模块的领域适应的特征表示空间更具鲁棒性。
在本实施例中,所述情感类别输出模块采用softmax函数对所得到的文本表示向量进行处理,预测各文本的情感类别。
具体的,文本表示学习模块学习了目标领域和源领域的文本表示,情感类别输出模块利用softmax分类函数对所得向量逐一计算,根据设定的阈值得到该文本表示的情感类别预测值。在训练阶段,利用源领域的文本表示进行情感类别的预测并计算其与实际情感标签的误差,利用随机梯度下降法和后向传播对整个系统的参数进行迭代更新;否则,对目标领域的文本表示进行情感类别的预测,并输出预测值。
本实施例还提供了一种基于上文所述的基于文本表示学习的跨领域情感分类系统的方法,具体包括以下步骤:
步骤s1:所述文本预处理模块接收源领域文本数据及情感标签、目标领域文本数据,对跨领域文本进行特征化处理,得到源领域与目标领域的初始文本向量;
步骤s2:所述文本表示学习模块将文本预处理模块的输出作为输入,学习领域适应的特征表示空间,挖掘出源领域与目标领域潜在的通用领域特征和情感特征,得到源领域与目标领域的文本特征向量;
步骤s3:所述文本表示强化模块生成对抗网络模型用于自动生成鲁棒的源领域文本表示并判别其情感类别,根据误差不断更新与优化文本表示学习模块的参数;
步骤s4:所述情感类别输出模块接收优化后的文本表示学习模块输出的文本特征向量,并利用分类函数得到目标领域的文本情感分类结果。
特别的,在本实施例中,在模型的训练阶段,根据信息的前向传播和误差的后向传播将不断地对他们进行调整,逐步优化目标函数。
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!