一种基于三维重建的人脸特征点实时检测方法和检测系统与流程
本发明属于计算机视觉技术领域,尤其是涉及一种基于三维重建的人脸特征点实时检测方法及检测系统。
背景技术:
随着移动端rgb-d相机的普及,装配在移动设备上的消费级rgb-d相机将直接触及到消费者终端用户,势必给三维视觉带来深刻的进步。而人脸的三维信息建模,是移动安全、移动ar、移动vr等各个领域的基础,为更加丰富的移动应用提供了无限可能。而在人脸的三维信息中,最具表现力和实用价值的就是人脸的几何网格、外观纹理和三维特征点。但是,移动设备的运算能力和存储能力有限,需要在移动设备上设计友好的交互系统、高效的算法进行人脸三维信息的获取。
在三维几何网格重建算法的研究中,有相当一部分的算法兼顾了性能与效果,同时得益于设备运算性能的不断提升,可以对rgb-d帧进行实时重建,取得很好的效果。此外,外观纹理也包含了三维物体的丰富信息。但是,由于相机位姿误差、几何网格误差、复杂光照等因素,恢复三维物体的真实外观纹理非常具有挑战性。目前主流的方法大多针对通用场景,建立复杂的全局非线性优化模型迭代求解,运行非常耗时,而且没有考虑人脸的先验信息,不能很好的适应人脸。
人脸的三维特征点,同样包含人脸的关键信息,是人脸识别、人脸动画、3d打印制造等等更高级应用的前提。现有的人脸特征点定位研究主要集中在二维图像领域。当然,也有一部分学者针对人脸三维模型的特征点定位提出了有效的算法。但是,现有的算法一部分模型过于复杂,运行效率低下,而另一部分模型结果的精度则不能满足要求。三维特征点定位与二维特征点定位相比,两者的区别在于输入数据的格式不同。二维数据的输入得益于图像卷积神经网络的发展,取得了很大的研究进展。因此,很多学者开始探索适用于三维数据存储结构的深度学习方法,这一热门的研究领域被称为三维深度学习。随着通用领域的三维深度学习的不断发展,人脸的三维特征点检测作为一个容易拓展的子问题,将得到更好的解决。
技术实现要素:
本发明的目的是提供一种基于三维重建的人脸特征点实时检测方法及检测系统,可以提高人脸三维特征点检测方法的准确率和实时性。
为实现上述发明目的,本发明提供以下技术方案:
一种基于三维重建的人脸特征点实时检测方法,包括以下步骤:
(1)采集人脸图像帧,利用几何重建算法实时重建人脸几何模型;
(2)对人脸几何模型进行预处理,提取人脸点云数据;
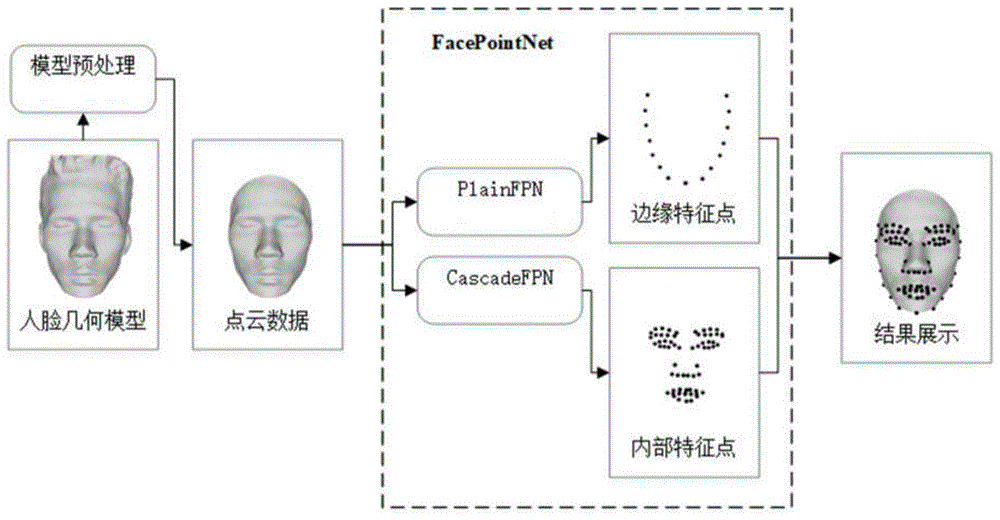
(3)将人脸点云数据输入由粗plainfpn网络和分块级联网络cascadefpn组成的facepointnet进行人脸三维特征点检测,得到人脸三维特征点;
所述粗plainfpn网络用于检测人脸的脸颊边缘特征点和粗精度的内部特征点,所述cascadefpn依据粗精度的内部特征点将人脸点云数据分为若干个分块,并分别检测每个分块细精度的内部特征点。
本发明针对人脸三维特征点检测提出facepointnet。其中,分块级联网络cascadefpn根据分块级联的思路,由粗到精的检测人脸内部的三维特征点。相比目前主流的人脸三维特征点检测方法更准确,而且实时性更高。
作为优选,步骤(1)中,采集的人脸图象帧为人脸姿态对齐的连续图象帧。在采集人脸图像帧时,对输入图片执行二维人脸对齐算法,检测实时的人脸姿态和二维特征点。根据当前的人脸姿态判断人脸是否对齐,当人脸没有初始对齐时,系统会反馈提示用户进行姿态的调整。
步骤(1)中,所述几何重建算法采用kinectfusion算法,具体重建过程为:
(1-1)对人脸图像执行空间区域划分操作,检测人脸图像的二维特征点,结合深度帧,划分出人脸的包围盒立方体;
(1-2)在得到的包围盒立方体里实现kinectfusion算法,进行实时的人脸三维几何重建。
步骤(2)中,所述的预处理包括对齐和切割处理,具体过程为:
首先将待检测的人脸几何模型粗对齐到一个标准的人脸模型的坐标空间;然后,取鼻尖为球心,80~100mm为半径的球面对人脸进行切割,切割后得到人脸点云数据。
粗对齐是为了避免输入点云模型旋转对检测结果产生影响,切割是为了提取有效人脸部分,避免无效的几何干扰数据对检测结果产生不良影响。通过上述预处理操作,可以提高整个检测方法的鲁棒性。
步骤(3)中,所述的
plainfpn网络分为两个模块,其中一个模块用来检测人脸的脸颊边缘特征点,另一个模块用来检测粗精度的人脸内部特征点。
每个模块包含5个x-conv层,每层的平均采样点数分别为1024、384、128、128、128个,x-conv层后接着一个平均池化层,提取出各个采样点的平均特征,之后将该特征输入到由三层全连接层组成的多层感知机,最后输出人脸特征点的三维坐标。
其中,x-conv层由一个多层感知机和两个普通卷积层组成,输入的点云数据先进入一个多层感知机中升维,得到的数据再输入到一个卷积层中获得变换矩阵,之后将变换矩阵与升维后的点云数据相乘,输入到另外一个卷积层中,最后输出结果。
所述的分块级联网络cascadefpn包括:用于分割人脸内部特征点的点云分割模块以及与分割后每个分块分别对应的若干个细plainfpn网络。
cascadefpn将粗精度的人脸内部特征点作为输入,利用这些特征点将人脸点云分割为鼻子、眼睛、眉毛和嘴巴四个分块,然后将各个分块的点云数据输入到对应的细plainfpn网络中。每个细plainfpn网络包含4层x-conv层,每层的采样点数各不相同,除此之外网络的其他部分则与粗plainfpn网络结构相同。最后每个细plainfpn网络输出对应部位特征点的三维坐标。
根据人脸每个部位的大小和点云规模,分别设计了四种采样策略,每个分块对应细plainfpn网络的采样策略如下:
鼻子分块每个x-con层的平均采样点数分别为738、384、128、128个,眼睛和眉毛的平均采样点数相同,都为400、256、128、128个,嘴巴的平均采样点数则为512、256、128、128个。
步骤(3)中,获取人脸三维特征点的具体过程为:
(3-1)将点云数据输入到粗plainfpn网络,获得粗对齐的特征点,包括脸颊边缘特征点和内部特征点;
(3-2)将粗对齐的内部特征点输入cascadefpn,对点云数据做分割操作,得到眉毛、眼睛、鼻子和嘴巴四个分块;
(3-3)每个分块的点云数据与对应的内部特征点一起,分别输入cascadefpn网络中每个分块相对应的细plainfpn网络,得到精对齐的内部特征点。
通过本发明设计的粗planefpn网络已经能够输出比较准确的三维特征点,包括脸颊边缘特征点和内部特征点。由于脸颊边缘的特征点的局部特征并不明显,噪声较大,很难对其精度继续改进。但是,对于人脸内部特征点,利用本发明的分块级联网络cascadefpn,对输入点云进行分块可以更好的提取局部几何细节,并由粗到精的继续优化特征点的精度,最终能够得到更加准确的结果,
本发明还公开了一种基于三维重建的人脸特征点实时检测系统,包括带相机的移动终端,所述移动终端还包括:
几何重建模块,利用相机采集的人脸图像帧,实时构建人脸三维几何模型;
预处理模块,对人脸三维几何模型进行对齐和切割,输出人脸点云数据;
三维特征点检测模块,对人脸点云数据进行三维特征点检测,得到人脸三维特征点;
所述三维特征点检测模块包括由粗plainfpn网络和分块级联网络cascadefpn组成的facepointnet;所述粗plainfpn网络用于检测人脸的脸颊边缘特征点和粗精度的内部特征点;所述cascadefpn包括:用于分割人脸内部特征点的点云分割模块以及与分割后每个分块分别对应的若干个细plainfpn网络。
本发明针对人脸三维特征点检测提出了facepointnet,facepointnet由粗plainfpn和分块级联网络cascadefpn组成,分别用来检测人脸的脸颊边缘特征点和人脸的内部特征点。其中,cascadefpn是根据分块级联的思路,设计的级联网络结构,由粗到精的检测人脸内部的三维特征点。与目前主流的人脸三维特征点检测方法相比,准确率更高,而且实时性也较高。
附图说明
图1为本发明一种基于三维重建的人脸特征点实时检测方法的流程示意图;
图2为利用几何重建算法实时重建人脸几何模型的流程示意图;
图3为人脸空间区域划分示意图,其中,(a)为二维特征点,(b)为三维特征点,(c)为包围盒立方体;
图4为本发明facepointnet中的粗plainfpn网络结构示意图;
图5为本发明facepointnet中的cascadefpn网络结构示意图;
图6为cascadefpn中四个分块的对应的细plainfpn网络结构示意图,其中,(a)为鼻子分块的细plainfpn网络,(b)为眼睛分块的细plainfpn网络,(c)为眉毛分块的细plainfpn网络,(d)为嘴巴分块的细plainfpn网络;
图7为人脸内部特征点粗对齐与精对齐的对比图,其中,(a)为粗plainfpn粗对齐结果,(b)为cascadefpn精对齐结果;
图8为特征点在人脸模型中的标注关系示意图。
具体实施方式
下面结合附图和实施例对本发明做进一步详细描述,需要指出的是,以下所述实施例旨在便于对本发明的理解,而对其不起任何限定作用。
如图1所示,为本发明一种基于三维重建的人脸特征点实时检测方法的流程示意图,包括:
步骤(1),采集人脸图像帧,利用几何重建算法实时重建人脸几何模型。
如图2所示,在重建人脸几何模型时,需要先对图片执行二维人脸对齐算法,检测实时的人脸姿态和二维特征点。根据当前的人脸姿态判断人脸是否对齐,当人脸没有初始对齐时,系统会反馈提示用户进行姿态的调整。人脸姿态对齐以后,执行空间区域划分操作,利用检测到二维特征点,结合深度帧,划分出人脸的包围盒立方体,以初始化实时几何重建。然后,执行实时几何重建,输出人脸几何模型数据。具体过程如下:
(1-1)人脸初始对齐
本实施例,利用已有的偏移动态表情(displaceddynamicexpression,简称dde)二维人脸对齐算法做人脸的初始对齐。通过输入连续的rgb视频,dde算法可以实时的计算得到图像中人脸的位置、大小、姿态、特征点等信息,如图3中(a)所示。根据得到的人脸位置、大小、姿态,系统可以实时的提示用户调整相应的姿态,从而完成人脸初始对齐的操作。在移动端,dde算法由faceunity公司提供了商业版的sdk,实现时对其直接进行了调用。
(1-2)空间区域划分
当完成人脸初始对齐后,将流入的第一帧rgb-d帧作为参考帧,用于划分需要重建的包围盒空间区域,以初始化三维重建。记该rgb帧为i0,深度帧为d0,从dde算法可以得到该帧的人脸二维特征点集p2d∈r2,其中的每个二维特征点p2d都是i0上的一个二维图像坐标,如图3中(a)所示。由于p2d只是特征点在二维图像i0上的坐标,需要利用与i0对齐的深度帧d0和相机内参矩阵,计算与p2d相对应的三维特征点集p3d∈r3,用于确定人脸空间区域,如图3中(b)所示。假设一个二维特征点p2d∈p2d,可以计算出对应p3d∈p3d
p3d=d0(p2d)k-1[p2dt,1]t(1)
其中,k是3×3的相机内参矩阵。
但是,多数情况下,消费级相机的深度帧在边缘轮廓处的深度值通常是缺失的。如图3中(b)所示,深度帧中的灰色区域的深度值是缺失的。因此,不能使用整个的p2d点集,只能使用人脸内部的特征点来确定人脸的空间区域。首先,约定水平向右为x轴,竖直向上为y轴,正面朝外是z轴。通过公式(1)的计算,可以得到人脸内部的三维特征点集p3d。然后,计算p3d的包围盒长方体(xmin,xmax,ymin,ymax,zmin,zmax),如图3中(b)所示。最后,根据人脸几何比例的先验约束,划分出人脸所在的包围盒立方体(cx,cy,cz,cw),如图3中(c)所示。其中(cx,cy,cz)表示立方体的中心,cw表示立方体的边长,计算过程如下
cw=2.2(ymax-ymin)(2)
cx=0.5xmin+0.5xmax(3)
cy=0.2ymin+0.8ymax(4)
cz=ymax-0.5cw+δ(5)
其中,δ是一个固定的小偏移量,防止鼻尖部分因为误差而被切割,我们实现时取δ=15mm。通过上述计算进行空间区域划分,对于不同脸型的用户,可以自适应调整几何模型的重建精度。
(1-3)实时几何重建
通过上述公式(2)~(5)的计算,划分好人脸所在的包围盒立方体区域(cx,cy,cz,cw)以后,利用kinectfusion算法进行实时几何重建。首先,对该包围盒立方体做均匀的体素网格划分,以初始化kinectfusion的tsdf体素网格,然后根据传入的深度帧不断更新tsdf值,得到持续更新的人脸三维几何模型。
步骤(2),对人脸几何模型进行预处理,提取人脸点云数据。
首先,需要将待检测的人脸模型粗对齐到一个标准的人脸模型的坐标空间。可以先利用二维人脸对齐算法粗略估计人脸的二维内部特征点,并映射为粗略的三维特征点。将几何重建时的第一帧作为参考帧,可以得到第一帧的二维人脸特征点坐标。而深度图则由已经重建的人脸模型和第一帧的相机位姿渲染得到,然后可以利用步骤(1-2)空间区域划分中的变换方法得到粗略的人脸内部三维特征点。然后,取一个标准的人脸模型,标注相对应的特征点,通过计算两组特征点之间的一个三维空间变换,就可以将待检测的人脸模型粗对齐到标准人脸模型的坐标空间。然后,取鼻尖为球心,80~100mm为半径的球面对人脸进行切割。切割后的数据,将作为本发明提出的facepointnet网络的输入,由粗到精的检测人脸三维特征点。
步骤(3),将人脸点云数据输入facepointnet网络进行人脸三维特征点检测,得到人脸三维特征点。
获取三维特征点的一种直观的方法是将二维人脸特征点映射到三维,得到人脸的三维特征点。但这种基于二维图像的方法的缺点也十分明显,不能充分的利用三维几何信息,而且对光线敏感。因此,为了能充分利用人脸的三维几何信息,我们将人脸模型的点云数据作为输入,在pointcnn的基础上,设计了facepointnet,由粗到精的检测三维特征点。facepointnet由两个网络组成:粗plainfpn和分块级联网络cascadefpn,分别用来检测人脸的脸颊边缘特征点和人脸的内部特征点。
首先,本发明利用x-conv卷积设计了一个粗plainfpn网络,结构如图4所示。粗plainfpn网络的输入是由预处理以后得到的人脸点云数据v∈r3,设输入包含n个顶点,则网络的输入是一个n×3的一维向量。设待检测的特征点集合为vm∈r3,包含m个特征点,则网络的输出是一个m×3的一维向量y={y1,y2,…,y3m}。设yi表示拟合值,yi*表示真值,网络的损失函数为
实际上,利用粗plainfpn网络,既可以检测人脸的脸颊边缘特征点,同时也可以检测人脸的内部特征点。而且,利用粗plainfpn检测的内部特征点,其结果已经比一部分主流的方法得到的结果更好。但是,对于人脸内部特征点,我们希望得到更加准确的结果。从级联回归求解问题的思路出发,可以将粗plainfpn网络的结果当作粗对齐点。我们认为,精对齐的特征点肯定分布在粗对齐点的邻域,并且可以在原始的输入点集中进行邻域搜索得到。另外,对输入点云进行分块可以更好的提取局部几何细节。基于上述观察,本发明设计了cascadefpn网络,由粗到精的继续优化特征点的精度。另外,由于脸颊边缘的特征点的局部特征并不明显,噪声较大,实验表明,很难对其精度继续改进。因此,cascadefpn网络只针对人脸的内部特征点的检测精度进行改进。
如图5所示,虚线框中是本发明设计的cascadefpn网络。首先,将人脸点云数据输入粗plainfpn网络,获得粗对齐的特征点。利用粗对齐的特征点,对输入点云数据做分割操作,得到4个分块:眉毛、眼睛、鼻子、嘴巴。分割点云的操作,实际上是为了更好的提取人脸局部几何细节。每个分块的点云与对应的粗特征点一起,组合构成下一步网络的输入。对这4个分块,分别设计不同参数的细plainfpn网络,进行精对齐操作。
如图6所示,为每个分块设计的细plainfpn网络,(a)为鼻子分块的细plainfpn网络,(b)为眼睛分块的细plainfpn网络,(c)为眉毛分块的细plainfpn网络,(d)为嘴巴分块的细plainfpn网络。这样做的原因是因为每一个分块的几何特征是不同的,需要用不同的网络来提取相应的特征。其中,图6所示的4个网络的逻辑结构是完全相同的,分别对应的是鼻子、眼睛、眉毛和嘴巴分块。但是网络中各层的参数有所不同。
如图7展示了粗plainfpn粗对齐与cascadefpn精对齐的对比结果,图中(a)为粗plainfpn粗对齐的结果,(b)为cascadefpn精对齐的结果。从对比可以看出,cascadefpn精对齐对每个分块的特征点结果都有明显的提升。对于眉毛和眼睛这种表面几何细节不十分突出的部位,精对齐的特征点构成的拓扑连接比粗对齐更加的自然。对于嘴巴和鼻子这种表面几何细节十分突出的部位,精对齐的特征点倾向于向几何突变的边缘靠拢,得到更精确的结果。其中,鼻子和嘴巴的下边缘改善尤其明显。
为验证本发明方法的有效性,在公开的人脸三维模型数据集bu3dfe上,将本发明提出的facepointnet与目前主流的两种方法进行对比,并对算法的执行效率进行了分析。
bu3dfe数据集包含100个人共2500个扫描模型。每个受试者共采集了1个中性表情和6个设定表情,每个设定表情具有4个强度水平,因此每个受试者采集了25个扫描模型,每个模型约包含35000个顶点。该数据集还带有85个手动标注的特征点,作为真实值。因此,可以在该数据集上测试本发明的特征点检测算法,并与已有的方法进行对比。在实验中,我们发现bu3dfe的85个标注特征点中的其中2个特征点标注并不正确,因此本发明的实验只取其余正确的83个特征点。实验取其中80人共2000个模型的数据作为训练集,其余20人共500个模型的数据作为测试集。
在pc上对facepointnet进行测试,测试的pc硬件配置是xeon3.40ghz四核cpu、16gb内存、nvidiagtx1080gpu。
首先,对训练数据集进行数据增强操作,旋转(rotation)角度采用
表1
各个特征点在人脸模型中的标注关系如图8所示,下表2展示了现有的方法与本发明的facepointnet方法的结果对比。其中,方法1是论文“shape-basedautomaticdetectionofalargenumberof3dfaciallandmarks”中提出的方法;方法2是论文“fullyautomatedandhighlyaccuratedensecorrespondenceforfacialsurfaces”中提出的方法。表中,mean是误差平均值,sd是均方差,单位是mm,数值越小,表示检测的精度越高。
表2
对比的结果显示,本发明设计的粗plainfpn网络得到的粗对齐结果,已经比方法1更准确,并且接近方法2的效果。而本发明提出的cascadefpn网络的结果,精对齐后的三维特征点平均误差只有1.77mm,比方法2和粗plainfpn都提升了很多,分别平均改进了38.54%和50.56%。
而且,方法2在求解特征点时还使用了纹理数据。本发明的facepointnet则只使用了三维几何数据,但结果更好。实验证明了本发明设计的基于分块级联思路的cascadefpn对特征点的精对齐有着显著的效果。本发明提出的facepointnet是一种先进的人脸三维特征点检测算法。
在上述的实验设置下,facepointnet在pc上的单次特征点检测时间约为3.61秒,实时性较高。其中,粗对齐过程粗plainfpn耗时约为1.28秒,精对齐的cascadefpn耗时约为2.33秒,具有较高的效率。
以上所述的实施例对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的具体实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!