一种基于数据增强和非负矩阵稀疏分解的群组发现方法与流程
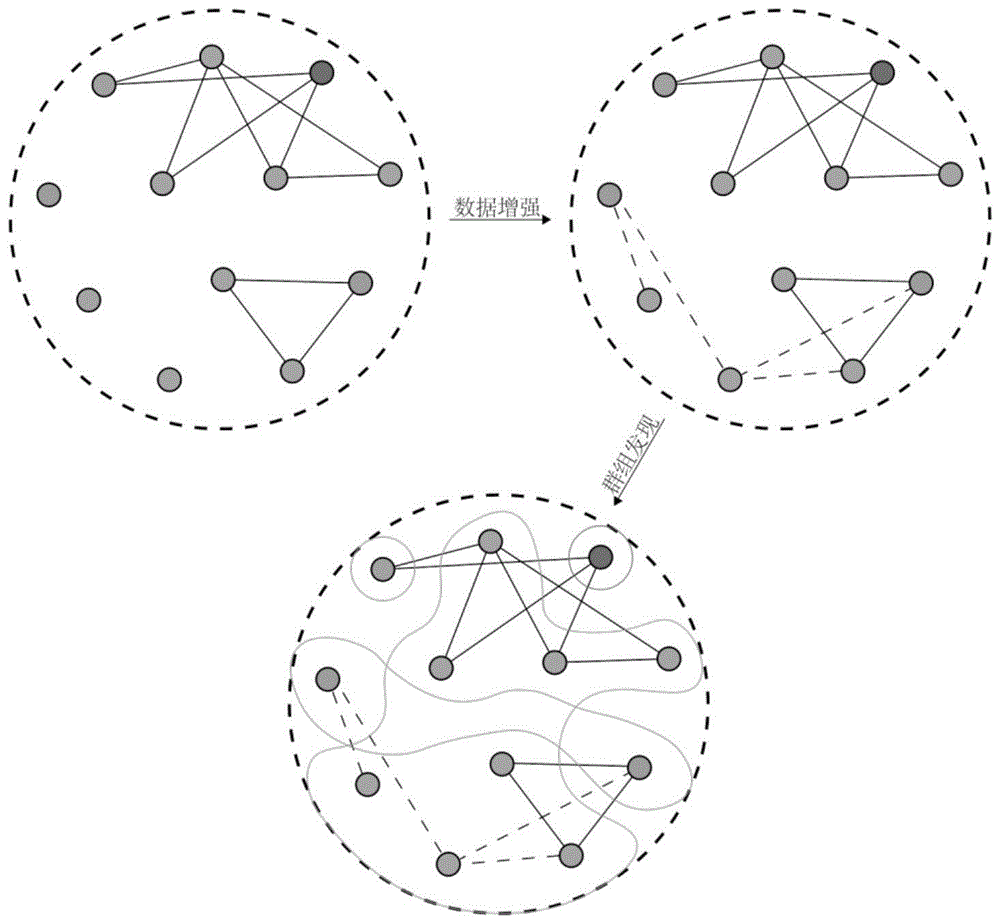
本发明属于大数据技术领域,具体涉及基于深度学习的网络数据增强和非负矩阵稀疏分解的群组发现方法。
背景技术:
现实中,各种各样的对象之间存在着联系与交互,这些对象以及它们之间的联系可以抽象成网络结构,或者称为图结构。联系或交互用网络中的边表示,而这些对象以及它们的属性在网络中则被表示为节点及其节点属性。分析这些网络数据,找出其中相似的点构成的集合,被称为群组发现任务。群组发现是大数据挖掘中的一项重要任务,例如,在社交网络中,网络节点代表了每一个人,而网络中的边则代表了他们之间存在的社交关系,比如同学关系、亲属关系、师生关系等。通过对社交网络的群组发现分析,得到每个人的社交圈,利用这些信息,能够进行好友推荐、商品推荐、社交关系的预测等。根据每个网络节点可以从属的群组数目,群组发现可以分为非重叠的群组发现和重叠的群组发现。非重叠的群组发现只允许每个节点只从属于一个群组;重叠的群组发现允许每个节点属于多于一个群组,比如社交网络中,某个人除了属于同事圈,还能属于社交朋友圈。
传统的基于矩阵分解的群组发现方法通常直接考虑当前给定的网络的拓扑结构,没有考虑在数据采集时可能缺失的边,例如尚未通过互加好友或关注建立的好友关系或同事关系等。另一方面,在非重叠群组发现任务上,矩阵分解的结果中某些节点可能最后计算得到的属于多个群组的概率相近,导致难以区分节点所属的群组;在重叠群组发现任务上,矩阵分解的结果可能每个群组都得到一个非零的概率,这也将导致难以判断节点是否属于该群组。
针对上述问题,本发明提出了一种基于数据增强和非负矩阵稀疏分解(non-negativematrixfactorizationwithsparsenessconstraints,nmfs)的群组发现方法。首先,通过利用循环神经网络(recurrentneuralnetwork,rnn),学习各种不同节点属性的网络节点的邻居分布(称为邻居模式);接着,通过学习到的邻居模式增强在数据采集过程中损失的拓扑结构数据;同时,考虑到节点属性可能有缺失,可以利用邻居节点属性进行补充,我们采用拉普拉斯平滑的方法进行增强;最后,对增强后的数据通过非负矩阵稀疏分解的方法,计算出每个节点所属的群组。该方法与传统方法相比,不仅考虑了网络的拓扑结构,还考虑了网络的节点属性,并且利用这些信息对数据进行了增强,有助于提高准确率;同时,使得矩阵分解时尽量不迭代出全零的行以保证迭代稳定;进一步地,在非负矩阵分解的群组发现算法上应用了吉洪诺夫正则化进行稀疏分解。采用非负矩阵稀疏分解的方法可以用一个模型同时处理非重叠的群组发现和重叠的群组发现任务,同时由于分解得到的从属群组概率矩阵和群组特征矩阵都是稀疏矩阵,在非重叠群组发现任务上,使得每个节点属于某个群组的概率接近于1,而属于其他群组的概率接近于0。不同于非稀疏分解的方法得到某些节点可能属于多个群组的概率相近,导致难以判断节点隶属群组的关系;在重叠的群组发现任务上,稀疏分解方法能够使得每个节点属于不从属的群组的概率接近于0,而非稀疏分解的方法,可能每个群组得到一个非零的概率,导致难以区分节点到底属于其中哪几个群组。总的来说,以非负矩阵稀疏分解的方法得到稀疏的群组表示,稀疏分解使得每个节点远离了属于某个或者多个群组的划分边界,同时避免了产生大量难以解释的非零的概率,因此同时提高了模型的准确性与可解释性。
技术实现要素:
本发明的目的在于为具有图结构的数据及其之间的关系的应用场景中,提供一种高准确性与可解释性的群组发现方法。
本发明提供的群组发现方法,是基于数据增强和非负矩阵稀疏分解的,具体是利用循环神经网络从网络的拓扑结构和节点属性学习到不同属性的节点的邻居分布,抽取邻居模式;通过学习到的邻居模式恢复在数据采集过程中造成的拓扑信息缺失;并且,利用拉普拉斯平滑对节点属性进行修复,同时对拓扑结构与节点属性进行数据增强;然后,在非负矩阵分解中加入吉洪诺夫正则化(tikhonovregularization),使得矩阵能够被稀疏分解,从而使得每个节点远离了属于某个或者多个群组的划分边界,同时避免产生大量难以解释的非零小概率,提高模型的准确性与可解释性,其过程如图1所示,该具体步骤为:
(1)数据准备:给定一个网络(或称为图)g=(a,x),包含邻接矩阵a=(a1,…,an)t及其节点属性矩阵x=(x1,…,xn)t,其中,a∈rn×n,x∈rn×r,n是节点数,r是节点属性的维数;
(2)拓扑结构数据增强:通过学习不同属性的节点的邻居分布,抽取邻居模式,来补充拓扑结构信息,具体流程为:
(2.1)学习邻居模式,即学习得到不同节点属性的网络节点的邻居分布,并得到不同邻居模式下的节点链接概率分布(流程如图2):首先,从图g中计算连通子图,并去除那些只有一个或者两个节点的连通分量gspa,得到连通子图集合g=(g0,g1,…,gm),根据均匀分布概率随机抽取一个连通子图g~p(g),然后通过随机选择起点,得到该连通子图的广度优先遍历序列π(g)~p(π),根据这个排序重排该连通子图,得到在该排序下的邻居矩阵aπ(g)和节点属性矩阵xπ(g),其中,fa和fn是对应的映射函数,即把子图映射到按某个广度优先遍历序列π(g)排序的邻接矩阵aπ(g),以及按该广度优先遍历序列π(g)排序的节点属性矩阵xπ(g);
每个节点的邻居模式用一个邻居节点属性向量表示,这个向量是通过自身节点属性以及其邻居的邻居节点属性向量的一些运算得到的,这些运算可以是线性的加和,也可以是非线性的取自身节点属性以及其邻居的邻居节点属性向量的列最大值,因此所有节点的邻居节点属性向量可以用一个邻居节点属性矩阵hπ(g)表示,这个邻居节点属性向量可以用一个任意的有关每个节点的节点属性及其邻居的节点属性的函数farb(·)进行提取;由于是无向图,邻接矩阵可以进一步压缩,第i个节点的邻接向量可以用bfs(breath-firstsearch,广度优先搜索)序列
假设每种邻居模式相互独立,把总的邻居模式概率转化成每个邻居模式的概率的乘积,用于下一步神经网络建模;拓扑结构数据增强步骤的学习模型可以用下式表示,其本质就是学习在不同邻居节点属性矩阵
其中,
我们用两个循环神经网络学习该模型,第一个模型用来学习邻居节点属性矩阵hπ(g),第二个模型用来学习不同邻居模式下的节点连接概率θπ~p(sπ|hπ),这两个循环神经网络分别用finh和fcon表示:
hπ=finh(xπ)(6)
θπ=fcon(hπ)(7)
其中,连接概率θπ∈[0,1]n×s,n是节点数量,s=min{i,l},l是最大前向邻居数目;
(2.2)拓扑结构生成:对每个连通子图抽取得到对应的广度优先遍历序列π0(g0),…,πm(gm),以及稀疏子图的节点的随机排序πs(nspa),把这些排序进行连接,得到原图的总排序π(g);通过训练好的神经网络finh和fcon得到原图的邻居模式hπ(g)和对应邻居模式下的节点连接概率θπ(g):
hπ(g)=finh(xπ(g))(8)
θπ(g)=fcon(hπ(g))(9)
根据节点连接概率θπ(g),采样生成边,得到生成的bfs序列sπ(g)~θπ(g),根据以下更新规则,得到数据增强后的邻接矩阵aπ(g):
(3)节点属性数据增强:通过对每个节点属性与其邻居求和,即拉普拉斯平滑来增强节点属性数据,其中d∈rn×n是度矩阵,i∈rn×n是单位矩阵,t是平滑次数:
(4)非负矩阵的稀疏分解:首先,设定分解的目标函数,同时对邻接矩阵a和节点属性矩阵x进行非负矩阵分解,a分解为从属群组概率矩阵u与其转置矩阵ut的点积,其中u∈rn×c,c是群组数量,uij代表第i个节点属于第j个群组的概率;x分解为从属群组概率矩阵u与群组潜在属性矩阵c的点积,其中c∈rc×r,r是节点属性的数量;对于矩阵u和c同时加入吉洪诺夫正则化,目标函数如下:
其中,α,β是权重,取值为大于0,例如通常为0<α,β≤2,具体根据实际情况确定;运用交替最小二乘(alternatingleastsquares,als),可以同时对邻接矩阵a和节点属性矩阵x进行非负矩阵分解,得到矩阵u和c,其更新法则如下:
(5)推测所属群组:根据每个节点允许从属单个还是多个群组,可以进行非重叠的群组发现和重叠的群组发现:
(5.1)非重叠的群组发现:对于从属群组概率矩阵u,得到第i个节点所属的群组communityi=argmax(ui);
(5.2)重叠的群组发现:对于从属群组概率矩阵u,得到第i个节点所属的群组集合communityi=find(ui≥thres),其中,thres是设定的阈值,用于剔除数据噪声的影响(虽然稀疏分解使得结果0值变多了,但是依旧不能认为非0值就代表此节点属于某个群组,因为还是会有一些噪声影响,因此要设置阈值),通常取0.1,find(condition)表示找出符合条件condition的值的下标的函数。
本发明方法可以通过学习邻居模式和拉普拉斯平滑修复数据采集中造成的缺失以增强数据,同时在群组发现算法中加入吉洪诺夫正则化,对矩阵进行了稀疏分解,提高了群组发现模型的准确性、稳定性和可解释性。
附图说明
图1为基于数据增强和非负矩阵稀疏分解的群组发现方法图示。
图2为邻居模式学习的流程图示。
图3为由三个节点构成的一个样例网络图示。
具体实施方式
下面将给出基于数据增强和非负矩阵分解的群组发现方法的具体实施方式。
(1)数据准备:选取一个来源于加州大学圣克鲁兹分校公开的网站数据集cornell(https://linqs-data.soe.ucsc.edu/public/lbc/webkb.tgz),数据集中包含邻接矩阵a和节点属性矩阵x。数据集给出了节点对应的群组(课程、教务、学生、工程和职员群组),邻接矩阵a代表这五种群组之间的链接关系。节点属性矩阵x代表网站的属性,这里用0-1取值的词向量表示,比如字典共1703个单词,排序为:“homework”,“student”,“submit”,…,如果网站中出现了字典中的单词就在对应位置用1表示,反之,用0表示。比如某个网站出现了“homework”,“student”,但是没有其他单词,则表示为[1,1,0,…]。
(2)拓扑结构数据增强:首先从图g中计算连通子图,为便于描述,选取其中三个点构成的网络(如图3),此图邻接矩阵为[[0,1,0],[1,0,0],[0,0,0]]t,则其有两个连通分量,这两个连通分量的邻接矩阵可以表示为[[0,1,0],[1,0,0]]t和[[0,0,0]]t,去除那些只有一个或者两个节点的连通分量gspa,为举例方便,这里仅删除一个节点的连通分量,即邻接矩阵为[[0,0,0]]t的分量,得到连通子图集合g=(g0,g1,…,gm),其邻接矩阵的集合可以表示为{[[0,1,0],[1,0,0]]t},根据均匀分布概率随机抽取一个连通子图g~p(g),可以抽取出邻接矩阵为[[0,1,0],[1,0,0]]t的子图,然后通过随机选择起点,得到该连通子图的广度优先遍历序列π(g)~p(π),根据这个排序重排该连通子图,得到在该排序下的邻居矩阵aπ(g)和节点属性矩阵xπ(g)(方便起见,下面用a和x代替aπ(g)和xπ(g))。神经网络输入为邻接矩阵a和节点属性矩阵x,首先对邻接矩阵a进行压缩,比如邻接矩阵为[[0,1,0],[1,0,0]]t,则压缩为bfs序列后为[[1,1],[1,1]]t。然后通过循环神经网络finh提取邻居模式,比如节点属性矩阵x(如图3)属性为1703维[[1,0,0,…],[1,1,0,…],[0,0,1,…]]t,此时的循环神经网络finh的权重向量是[0.1,0.2,0.3,…]和[1,2],则邻居模式矩阵h为[2×[0.1×1,0.2×0,0.3×0,…],1×[0.1×1,0.2×0,0.3×0,…]+2×[0.1×1,0.2×1,0.3×0,…],1×(1×[0.1×1,0.2×0,0.3×0,…]+2×[0.1×1,0.2×1,0.3×0,…])+2×[0.1×0,0.2×1,0.3×0,…]]t=[[0.2,0,0,…],[0.6,0.4,0,…],[0.6,0.6,0,…]]t。之后通过循环神经网络fcon计算节点连接概率,比如此时的之后通过循环神经网络fcon权重为[0.4,0.5,0.6,…],则输出的连接概率是[0.4×0.2+0.5×0+0.6×0+…,0.4×0.6+0.5×0.4+0.6×0+…,0.4×0.6+0.5×0.6+0.6×0+…]t=[0.08,0.44,0.54]t。然后通过连接概率与真实值计算出损失值为1×in(0.08)+1×in(0.44)+0×in(0.54)=-3.3467,通过梯度下降更新循环神经网络finh和fcon的参数。生成图的过程和计算与训练时类似,只不过输入节点数不同,顺序不同,不在此赘述。假设生成的图的邻接矩阵为[[0,1,0],[1,0,1],[0,1,0]]t,原图为[[0,1,0],[1,0,0],[0,0,0]]t,根据更新算法,得到数据增强后的图的邻接矩阵a为[[0,1,0],[1,0,0],[0,0,0]]t+[[0,0,0],[0,0,1],[0,1,0]]t=[[0,1,0],[1,0,1],[0,1,0]]t。
(3)节点属性数据增强:输入为增强后的邻接矩阵a和节点属性矩阵x,首先计算出度矩阵d,比如邻接矩阵a为[[0,1,0],[1,0,1],[0,1,0]]t,则度矩阵d为[[0+1+0,0,0],[0,1+0+1,0],[0,0,0+1+0]]t=[[1,0,0],[0,2,0],[0,0,1]]t。计算标准化后的邻接矩阵
[[1.7071,0.7071,0,…],[1.2071,0.5,0.7071,…],[0.7071,0.7071,1,…]]t。
(4)非负矩阵的稀疏分解:首先,设置群组数量c为5,随机初始化u与c,得到比如:
根据公式(13)、(14),设置α=1,β=0.5迭代计算后,得到更新后的u和c矩阵,如下:
(5)推测所属群组:如果是非重叠的群组发现,根据communityi=argmax(ui),其每行的最大值分别为0.2533、0.2855、0.2517,其对应的下标是0、2、2,因此可以得到节点对应从属的群组为[0,2,2]t,说明第1个、第2个、第3个节点分别属于第0种、第2种、第2种群组。如果是重叠的群组发现,根据communityi=find(ui≥0.1),可以求出从属的群组为[[0,2,3],[2,4],[1,2,4]]t,说明第1个节点同时属于第0种、第2种、第3种群组;第2个节点同时属于第2种、第4种群组;第3个节点同时属于第1种、第2种、第4种群组。
通过本发明方法,对于数据采集过程中造成的损失进行了修复,同时引入加上了吉洪诺夫正则化的非负矩阵分解,对于群组发现任务进行了有效的建模,使得每个节点远离了属于某个或者多个群组的划分边界,同时避免了产生许多难以解释的非零小概率,在提高了模型的准确性的同时提高了模型的可解释性,本方法相较于传统方法准确率提高了近10%-25%。
- 还没有人留言评论。精彩留言会获得点赞!