农业面源污染多源异构大数据关联方法及采用该方法的大数据监管平台与流程
本发明属于大数据处理技术领域,特别涉及一种农业面源污染多源异构大数据关联方法及采用该方法的大数据监管平台。
背景技术:
目前农业面源污染问题突出,在综合治理中,需选择农业环境问题突出、代表性强的小流域,加大源头控制,实施农业面源污染综合治理工程建设。为了保证工程应用中的监测效果和工作效率,急需构建农业面源污染大数据监管平台,实现多源异构数据的规范化和快速关联,服务于农业面源普查、调查、监测、分析决策等功能,为农业面源、农田土壤重金属污染综合防治与修复提供数据支撑。
然而现有技术对农业面源污染多源异构大数据进行关联时存在以下缺点:
1、由于数据量巨大,因而对数据进行标注存在工作量大、耗费多等问题。
2、对标注后数据进行关联处理速度慢,难以实现实时关联。
3、难以解决种类多、内容庞杂、结构松散的定量和定性数据的关联。
4、监测平台数据库过大,检索困难,同时难以实现实时监测。
技术实现要素:
为了克服上述现有技术的缺点,本发明的目的在于提供一种农业面源污染多源异构大数据关联方法及采用该方法的大数据监管平台,一方面解决了大数据标注工作量大、成本高的问题;第二方面解决了大数据关联速度慢的问题;第三方面解决了不同种类、不同内容、结构松散的定量和定性数据的关联问题;第四方面解决了目前大数据监管平台数据不便于检索,不便于实时监测的问题。
为了实现上述目的,本发明采用的技术方案是:
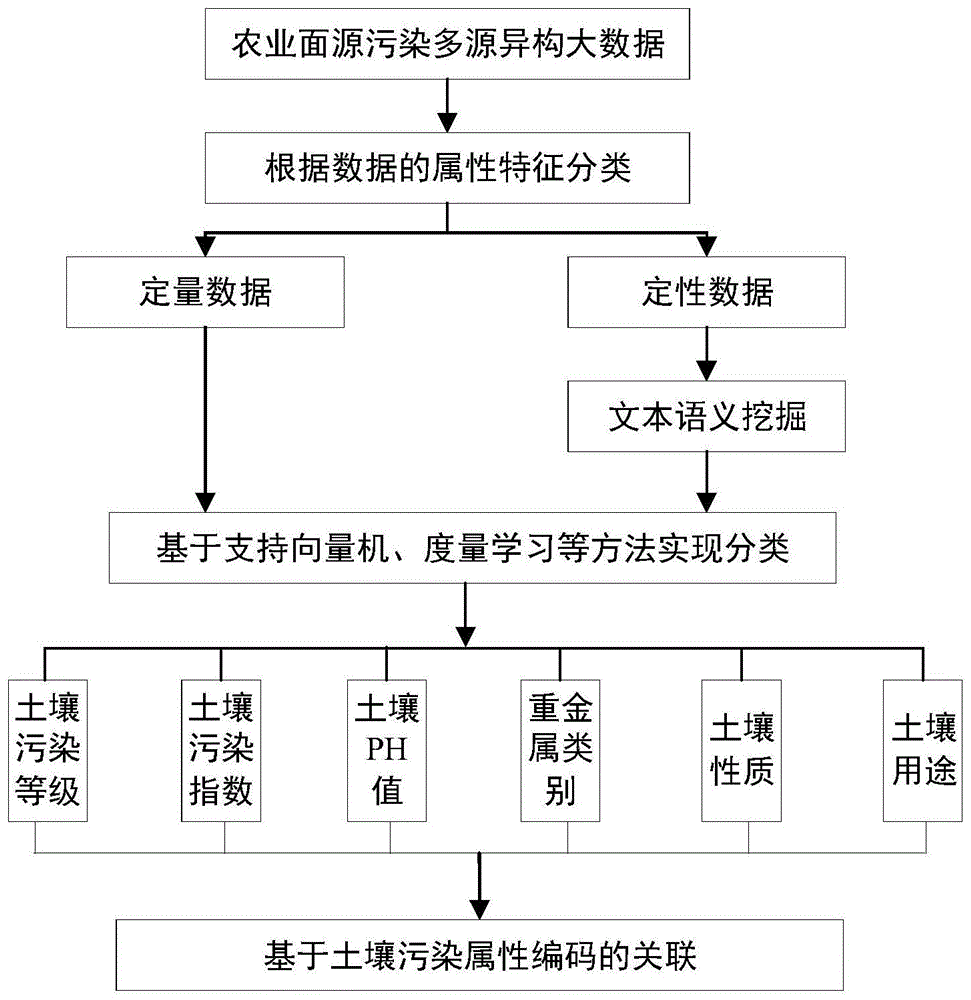
一种基于属性分类的农业面源污染多源异构大数据关联方法,包括如下步骤:
判断农业面源污染多源异构大数据属于定量数据还是定性数据;
对多源异构大数据的定量数据采用支持向量机或度量学习方法实现分类;
对多源异构大数据的定性数据采用文本语义挖掘方法获取量化特征,再采用支持向量机或度量学习方法实现分类;
对分类后的结果进行编码实现多源异构大数据的关联。
所述农业面源污染多源异构大数据的定量数据包括污染监测点数据、遥感栅格数据、线和面矢量基础地理数据以及图像和视频多源异构数据;所述农业面源污染多源异构大数据的定性数据包括统计调查数据和文本数据等数据中不能定量表示的其他数据。
所述多源异构大数据采用最小二乘孪生支持向量机分类方法或基于cayley-klein度量学习的分类方法实现分类。
所述最小二乘孪生支持向量机(lstsvm)分类方法对面源污染多源异构大数据进行分类的具体步骤如下:
以如下两个约束优化问题表示lstsvm模型:
s.t-(k(b,mt)w1+e2b1+y2=e2
s.t-(k(a,mt)w2+e1b2+y1=e1
其中,
把约束条件代入目标函数可以求得:
其中,h=[k(a,mt)e1],q=[k(b,mt)e2]
由此可得超平面方程:
k(xt,mt)w1+b1=0
k(xt,mt)w2+b2=0
上述两个超平面分别对应一类训练样本,判断一个新样本x∈rn为类i的决策函数如下:
基于lstsvm分类方法,采用两两二分类再采用投票法确定最终类别的思想,如果上述函数的值为k=1,则新样本属于第1类,如果该函数的值为k=2,则新样本属于第2类。
所述基于cayley-klein度量学习的分类方法对面源污染多源异构大数据进行分类的具体步骤如下:
cayley-klein度量学习问题可被表述为:给定训练样本数据,寻找一个cayley-klein度量矩阵使得相应的度量在某种学习准则下是最优的,因此,cayley-klein度量学习问题,首先需要根据特定的任务建立cayley-klein度量学习准则,其次是通过求解非线性优化获得最优的cayley-klein度量矩阵,给定一个对称正定矩阵g,其在cayley-klein度量中的双线性形式表示为:
椭圆cayley-klein度量为:
xi表示第i个样本,xj表示第j个样本,k是一个给定的常数。
借鉴ν支持向量机方法,使相同类数据点之间的cayley-klein度量较小而不同类数据点之间的cayley-klein度量较大,给出如下的cayley-klein度量学习的优化模型:
subjectto(a)dck(xi,xl)-dck(xi,xj)≥ρ-ζijl
(b)ζijl≥0,ρ≥0
(c)g>0
式中,符号j→i表示xj和xi是属于相同类别的数据点,目标函数的第一项惩罚输入样本与其相同类样本间的较大距离,第二项中的ν控制误分类样本点的比例,第三项是惩罚异类样本间的较小距离,μ为平衡常数;ζijl表示误差,l表示与i不同类别,ρ表示误差控制量。
为了确保g的对称性,令g=ltl,l∈r(n+1)×(n+1),将约束加到目标函数中,令ζijl(l,ρ)=[ρ+dck(xi,xj)-dck(xi,xl)]+,如果z≥0,[z]+=z;如果z<0,[z]+=0,有:
这里,ε(l,ρ)是相对于l和ρ的函数,r表示实数集合,n是数据的维数。
用记号cij=(xit,1)t(xjt,1),有:
σ(xi,xj)=tr(cijg)=tr(cij(ltl))
得到目标函数第t次迭代的梯度为:
其中
为了提高迭代效率,利用小批量随机梯度下降算法求解上述优化问题,在每次迭代时,只选取其中的b个样本更新梯度值,b远小于样本总数n,收敛后,g由g=ltl得到;小批量随机梯度下降算法求解的步骤如下:
输入:训练样本数据,步长为η
输出:cayley-klein度量矩阵g
(1)初始化:g0=g+;
(2)计算l:g=ltl;
(3)随机选取b个样本,获得该b个样本的的梯度值;
(4)令
(5)重复步骤(3)(4),直到收敛,或达到停止准则;
(6)返回g=ltl,结束;
η表示迭代步长、
本发明可采用基于深度学习的生成式自动文摘方法,抽取定性数据中的属性信息,采用支持向量机或度量学习方法实现定性数据的分类。
本发明还提供了一种农业面源污染大数据监管平台,包括:
数据采集模块,采集农业面源污染多源异构大数据;
数据关联模块,采用所述基于属性分类的农业面源污染多源异构大数据关联方法对数据采集模块采集的数据进行关联;
数据库,存储所述数据关联模块关联的数据
检索模块,根据关联关系检索数据;
监测模块,将检索到的数据与预设阈值进行比较,当不在阈值范围内,则输出报警。
所述农业面源污染大数据监管平台,还可包括:
编码模块,构建树状结构编码,将分类结果进行量化编码。
所述农业面源污染大数据监管平台,还可包括:
数据爬取模块,根据关键词自动爬取数据,并将爬取数据按照编码反馈至监测模块,由监测模块实现实时监控。
与现有技术相比,本发明的有益效果是:
1、本发明基于农业面源污染中的土壤污染属性,利用支持向量机、度量学习等人工智能算法对多源异构定量/定性数据进行分类,可实现农业面源污染多源异构大数据的快速标注。
2、本发明构建土壤污染属性树状结构编码,对分类结果进行量化编码,实现不同种类、不同内容、结构松散的定量和定性数据的高效关联。
3、本发明构建农业面源污染大数据监管平台,基于所述的关联方法实现数据关联,大大优化了检索,便于利用爬取模块实时监测数据。
附图说明
图1是本发明数据关联方法的流程图。
图2是本发明土壤污染属性编码示意图。
具体实施方式
下面结合附图和实施例详细说明本发明的实施方式。
通过分析引起农业面源污染的主要类型,对农业面源污染监测工程应用中采集的点位数据(比如:带有经纬度坐标的zn、fe、cu、mn、cd、cr土壤等重金属数据;有机质、水解氮、有效磷、缓效钾、速效钾等土壤养分数据,数据格式为*.xls或*.txt)、遥感栅格数据(比如:国产hj-1a/b/c、gf-1/2、美国landsat系列卫星和无人机拍摄的多源遥感影像,数据格式为带地理坐标的*.giff格式)、点/线/面地理信息矢量数据(比如:省、市、县等行政区划数据,数据格式为*.shp格式)、图像(农业物联网拍摄的高清图像,数据格式为*.jpg)、视频(农业物联网拍摄的视频,数据格式为*.avi)等多源异构定量数据采用lstsvm支持向量机、cayley-klein度量学习等方法实现分类,将其归为土壤污染等级、土壤污染指数、土壤ph值、重金属类别、土壤性质、土壤用途。
对农业面源污染工程应用中获取的种植业地块调查、畜禽养殖业调查、水产养殖业调查、农村生活污染源调查等定性调查数据(数据格式为*.doc或者*.pdf),采用文本语义挖掘方法获取量化特征,再采用lstsvm支持向量机、cayley-klein度量学习等方法实现分类,将其归为土壤污染等级、土壤污染指数、土壤ph值、重金属类别、土壤性质、土壤用途。
如图1所示,一种基于属性分类的农业面源污染多源异构大数据关联方法,包括如下步骤:
(1)最小二乘孪生支持向量机分类方法
支持向量机是一种基于统计学习理论的机器学习方法,和神经网络相比,其解决了高维问题和局部最小值问题,具有更好的泛化能力。jayadeva等提出孪生支持向量机(twinsupportvectormachine,twsvm),它通过求解两个规模较小的二次规划问题,对大规模不均衡数据具有很好的处理能力,并且可以获得具有更强鲁棒性的最优超平面,有效提高分类精度。利用最小二乘孪生支持向量机(leastsquarestwinsupportvectormachine,lstsvm)算法对农业面源污染多源异构大数据进行分类。
lstsvm的模型可表示为下面两个约束优化问题:
s.t-(k(b,mt)w1+e2b1+y2=e2
s.t-(k(a,mt)w2+e1b2+y1=e1
其中,
把约束条件带入目标函数可以求得
其中,h=[k(a,mt)e1],q=[k(b,mt)e2]
由此可得超平面方程:
k(xt,mt)w1+b1=0
k(xt,mt)w2+b2=0
上述两个超平面分别对应一类训练样本,判断一个新样本x∈rn为类i的决策函数如下:
根据决策函数得到的计算结果归为土壤污染等级、土壤污染指数、土壤ph值、重金属类别、土壤性质、土壤用途等类型。
(2)基于cayley-klein度量学习的分类方法
凯莱-克莱因度量学习问题可被表述为:给定训练样本数据,寻找一个凯莱-克莱因度量矩阵使得相应的度量在某种学习准则下是最优的。因此,凯莱-克莱因度量学习问题。首先需要根据农业面源污染多源异构数据与土壤污染等级、土壤污染指数、土壤ph值、重金属类别、土壤性质、土壤用途等类型建立凯莱-克莱因度量学习准则,其次是通过求解非线性优化获得最优的凯莱-克莱因度量矩阵。
给定一个对称正定矩阵g,其在凯莱克莱因度量中的双线性形式可以表示为:
椭圆凯莱克莱因度量为:
借鉴ν支持向量机方法,使相同类数据点之间的cayley-klein度量较小而不同类数据点之间的cayley-klein度量较大,给出如下的cayley-klein度量学习的优化模型:
subjectto(a)dck(xi,xl)-dck(xi,xj)≥ρ-ζijl
(b)ζijl≥0,ρ≥0
(c)g>0
式中,符号j→i表示xj和xi是属于相同类别的数据点,目标函数的第一项惩罚输入样本与其相同类样本间的较大距离,第二项中的ν控制误分类样本点的比例,第三项是惩罚异类样本间的较小距离,μ为平衡常数。
为了确保g的对称性,令g=ltl,,这里l∈r(n+1)×(n+1)。将约束加到目标函数中,令ζijl(l,ρ)=[ρ+dck(xi,xj)-dck(xi,xl)]+,这里如果z≥0,[z]+=z;如果z<0,[z]+=0有:
这里,ε(l,ρ)是相对于l和ρ的函数,
用记号cij=(xit,1)t(xjt,1),有:
σ(xi,xj)=tr(cijg)=tr(cij(ltl))
可以得到目标函数第t次迭代的梯度为:
这里
为了提高迭代效率,利用小批量随机梯度下降算法求解上述优化问题。假设样本总数为n,在每次迭代时,只选取其中的b个样本更新梯度值,这里的b远小于样本总数n。收敛后,g可以由g=ltl得到。
小批量随机梯度下降算法求解的步骤如下:
输入:训练样本数据,步长为η
输出:cayley-klein度量矩阵g
(1)初始化:g0=g+;
(2)计算l:g=ltl;
(3)随机选取b个样本,获得该b个样本的的梯度值;
(4)令
(5)重复步骤(3)(4),直到收敛,或达到停止准则;
(6)返回g=ltl,结束。
构建图2所示的土壤污染属性树状结构编码,对分类结果添加具体的量化编码实现农业面源污染多源异构大数据与土壤污染属性的快速关联。
本发明在实现关联之后,可服务于农业面源污染多源异构大数据的高效管理,尤其对于定性数据的分类和关联,可解决当前农业面源污染数据库管理系统的数据管理低效、共享性差和系统服务能力弱等问题,最终为农业面源污染时空大数据平台研发提供高效的数据关联方法。例如,可应用于构建农业面源污染大数据监管平台,本发明中,该平台包括:
数据采集模块,采集农业面源污染多源异构大数据,实际应用中,可在服务器直接接入各数据采集设备的数据输出端,获取数据;
数据关联模块,采用所述基于属性分类的农业面源污染多源异构大数据关联方法对数据采集模块采集的数据进行关联,实际应用中,该模块是设置在服务器中的虚拟模块,从服务器的数据输入端获取各类数据,然后应用所述的关联方法,对数据分类关联;
数据库,存储所述数据关联模块关联的数据,实际应用中,数据库在服务器的存储区;
检索模块,根据关联关系检索数据,实际应用中,检索模块一般采取主动检索,即,设置检索项,由用户根据类别在不同的检索项中进行检索;当然也可采用被动检索,即,设置关键检索项,由系统不间断获取数据库中新存入的数据;
监测模块,将检索到的数据与预设阈值进行比较,当不在阈值范围内,则输出报警。
当在平台中设置编码模块,编码模块基于图2的形式,构建树状结构编码,将分类结果进行量化编码,该特征下,将利于被动检索的实现。
当在平台中设置数据爬取模块,数据爬取模块根据关键词自动爬取数据,并将爬取数据按照编码反馈至监测模块,由监测模块实现实时监控。该特征实质上是被动检索的一种。
- 还没有人留言评论。精彩留言会获得点赞!