一种基于序列增强胶囊网络的刑事案件罪名预测方法与流程
本发明涉及智能法律领域,尤其涉及一种基于序列增强胶囊网络的刑事案件罪名预测方法。
背景技术:
近年来,以深度学习和自然语言处理为代表的人工智能技术取得巨大突破,开始在智能法律领域崭露头角,受到了学术界与产业界的广泛关注。智能法律赋予机器理解法律文本、分析案例的能力,能根据案件进行智能办案。
自动罪名预测作为智能法律中最具有表性的子任务之一,在法律助理系统中发挥着重要的作用,在现实生活中也有着广泛的应用。例如,它可以为法律专家(如律师和法官)提供案件被告人的罪名参考,以此辅助法官判案,提高工作效率;同时可以为不熟悉法律术语和复杂程序的普通人提供法律咨询。自动罪名预测是利用机器学习或深度学习技术训练机器法官判断案件被告人的罪名(如盗窃、抢劫、交通肇事等)。以前的研究工作提出了许多实现自动罪名预测的方法。这些方法主要分为三类:(1)传统方法;(2)机器学习方法;(3)深度学习方法。
传统方法常采用数学公式或者定量计算。kort[fredkort.predictingsupremecourtdecisionsmathematically:aquantitativeanalysisofthe“righttocounsel”cases.americanpoliticalsciencereview,1957,51(1):1–12]试图运用定量方法预测通常被认为高度不确定的人类事件,即美国最高法院的判决。该研究旨在证明,至少在司法审查的一个领域,用一些已经决策的案件来确定影响决策的事实因素,用公式求出这些因素的数值,然后在指定的领域中正确地预测剩余案件的决策。nagel[stuartsnagel.applyingcorrelationanalysistocaseprediction.tex.l.rev.,1963,42:1006]认为可以科学地预测诉讼结果,他利用重新分配的例子证明了通过对案例中出现的四个变量分配相关系数,预测是可能的。这一预测将有助于规划诉讼的当事人、理解司法程序的理论家、解释司法反应的立法者以及寻求遵守法律的公众。keown[rkeown.mathematicalmodelsforlegalprediction.computer/lj,1980,2:829]提出了用数学方法预测司法判决的可行性。他利用haar、sawyer和cummings的线性模型法以及mackaay和robillard的最近邻法在1000多个案例中,正确预测了99%的决策。这种成功为在其他特殊领域开发线性模型提供了真正的机会和迫切的需要,这不仅是为了从经验上验证该方法在一般情况下是有效的,而且还为法律行业提供了额外的预测模型。这些传统的方法在某些场景中取得了一些效果,但它们仅限于具有少量标签的小数据集。
由于机器学习在许多领域的成功,研究人员开始使用机器学习方法来处理罪名预测。这类工作通常侧重于从案例事实中提取特征,然后使用机器学习算法进行预测。liu等人[chao-linliu,cheng-tsungchang,jim-howho.caseinstancegenerationandrefinementforcase-basedcriminalsummaryjudgmentsinchinese.2004.,chao-linliu,chwen-darhsieh.exploringphrase-basedclassificationofjudicialdocumentsforcriminalchargesinchinese.in:procofinternationalsymposiumonmethodologiesforintelligentsystems.springer,2006,681–690]提出了一种基于k-nearestneighbor(knn)算法,用于从现实世界的判决文本中自动生成和细化用于刑事简易判决的案件实例。该算法试图从过去的诉讼文件中提取重要的法律信息来构建案例实例,然后通过合并相似的案例并从案例中删除相对不相关的信息来细化这些案例实例。lin等人[wan-chenlin,tsung-tingkuo,tung-jiachang.exploitingmachinelearningmodelsforchineselegaldocumentslabeling,caseclassification,andsentencingprediction.roclingxxiv(2012),2012.140]针对“强盗罪”与“恐吓取财罪”定义21种法律要素标签,然后利用法律要素资讯来分类来分类“强盗罪”与“恐吓取财罪”以及预测此两种罪的判处刑期。mackaay等人[ejanmackaay,pierrerobillard.predictingjudicialdecisions:thenearestneighborruleandvisualrepresentationofcasepatterns.1974]通过聚类语义相似的n-grams来提取特征。sulea等人[octavia-mariasulea,marcoszampieri,shervinmalmasi,etal.exploringtheuseoftextclassificationinthelegaldomain.corr,2017,abs/1710.09306]利用法国最高法院的案例和裁决,调查了文本分类方法在法律领域的应用,然后提出了一种基于支持向量机的案件描述、时间跨度和判决特征的判决系统,以预测案件的法律领域和判决方面的准确性。然而,这些方法仅提取浅层文本特性或手动标记,很难在大的数据集上收集这些特征。因此,当数据量很大时,它们的性能不会很好。
近年来,随着深度神经网络在自然语言处理(nlp)、计算机视觉(cv)和语音领域的成功,一些工作开始将其应用到自动罪名预测任务中,并显示出巨大的性能提升。luo等人[bingfengluo,yansongfeng,jianboxu,etal.learningtopredictchargesforcriminalcaseswithlegalbasis.arxivpreprintarxiv:1707.09168,2017.]认为相关法律条文在这一任务对罪名预测任务起着非常重要的作用。因此提出了一种基于注意力的神经网络方法,将罪名预测任务和相关条文提取任务在统一的框架下进行联合建模,从而能够有效预测不同表达方式案件的适当罪名。然而,这项工作不能解决低频罪名预测以及多重罪名预测的问题。zhong等人[haoxizhong,guozhipeng,cunchaotu,etal.legaljudgmentpredictionviatopologicallearning.in:procofproceedingsofthe2018conferenceonempiricalmethodsinnaturallanguageprocessing.2018,3540–3549]通过考虑到法律条文中的罪名、法条、罚款、处罚期限这些子任务之间的拓扑依赖关系,提出了一种拓扑多任务学习的框架,将多个子任务的依赖关系结合到罪名判断预测中。hu等人[zikunhu,xiangli,cunchaotu,etal.few-shotchargepredictionwithdiscriminativelegalattributes.in:procofproceedingsofthe27thinternationalconferenceoncomputationallinguistics.2018,487–498]针对低频罪名预测以及容易混淆的罪名,引入罪名的几个判别属性作为案件的事实描述和罪名之间的内部映射,这些属性为低频罪名提供了附加信息以及区分混淆罪名的有效特征,然后提出了一种attribute-attentive罪名预测模型来同时推断属性和罪名。通过对上述学者研究内容的进一步分析可以发现,目前学术界和工业界虽然已经提出了一系列的基于深度学习的自动罪名预测算法,并取得了不小的进步。但已有的方法仍在存在不足:(1)现有的大部分工作[9,10]忽视了自动罪名预测任务的低频罪名场景,仅考虑到高频罪名场景,因此不能很好的解决低频罪名预测问题。(2)hu等人[11]利用人工生成的辅助信息在低频罪名场景中取得了不错的效果,然而,人工标注信息浪费了大量的时间,且不能够实现端到端的深度学习模型。
国家发明专利申请“一种基于记忆神经网络的刑事案件罪名预测方法”(公开日:2019.02.22)以标准的案情描述及其罪名作为训练数据建训练数据集,通过训练数据集对构建出的记忆神经网络模型进行训练,“案情描述特征向量”-“罪名编码”对转换为记忆神经网络模型中存储的键-值对,采用多层感知机分类器对刑事案件罪名进行裁判,该方法提出的模型虽然对低频罪名也能进行预测,但是记忆模块需要对比真实的罪名与预测的罪名的关系,然而低频罪名数据量较少,在部分罪名中甚至仅仅只有几条案件,因此,很难在低频罪名预测场景中取到好的效果。
技术实现要素:
经过对上述国内外众多学者的研究成果深入分析,针对上述现有技术中存在的问题,本发明提出一种基于序列增强胶囊网络的刑事案件罪名预测方法,以缓解刑事案件中低频罪名预测问题。
为了实现上述目的,本发明采用的技术方案为,一种基于序列增强胶囊网络的刑事案件罪名预测方法,包括以下步骤:
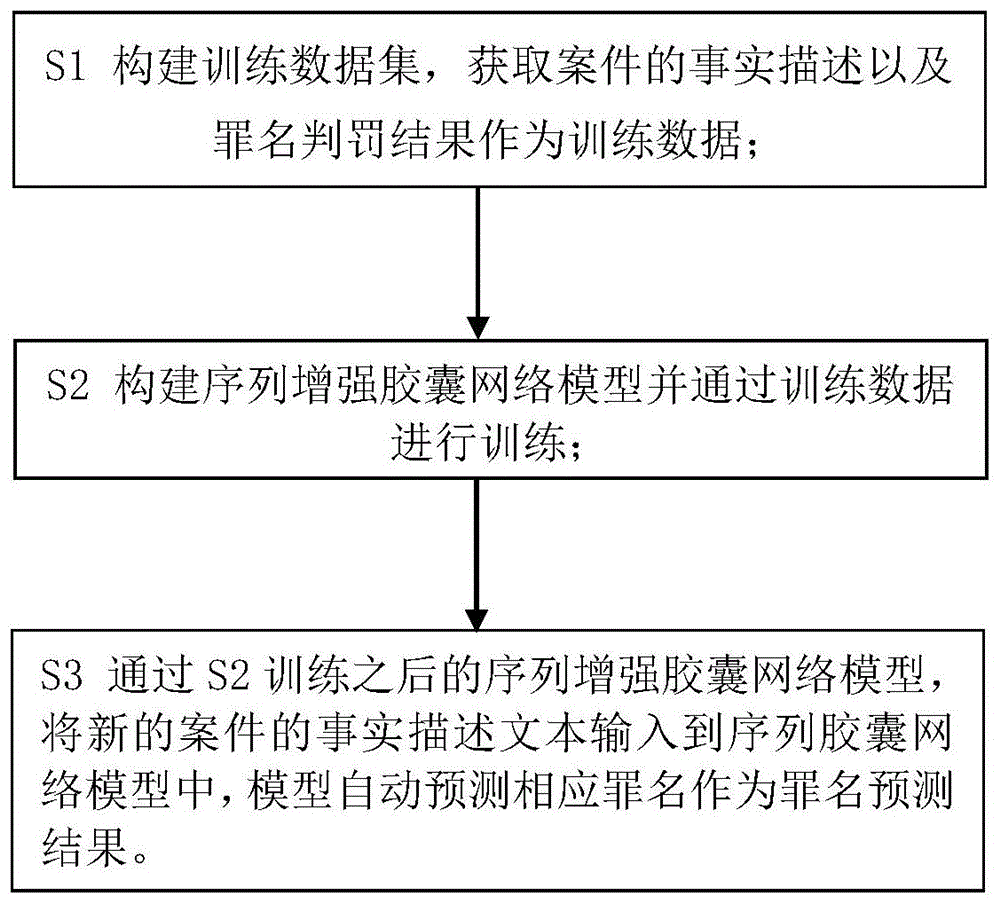
s1构建训练数据集,获取案件的事实描述以及罪名判罚结果作为训练数据;
s2构建序列增强胶囊网络模型并通过训练数据进行训练,包括以下步骤:
s2.1构建序列增强胶囊网络模型,具体步骤如下:
s2.1.1构建初始胶囊层:对案件的事实描述文本进行分词,并映射为词向量序列,将其作为初始胶囊层u={u1,u2,…,un};
s2.1.2构建multipleseq-caps层:通过对s2.1.1得到的初始胶囊层u,利用multipleseq-caps层提取特征,得到案件事实描述文本的主要特征向量,所述multipleseq-caps层由两个seq-caps层组成;
s2.1.3构建基于注意力机制的残差单元层(attention层),对s2.1.1得到的初始胶囊层u使用注意力机制,得到案件事实描述文本的辅助特征向量c:
所述attention层如下:将初始胶囊层u中的n个初始胶囊ui,(i=1,2,…,n)通过权值矩阵w,得到一个经过矩阵变换后的向量ei,然后对向量ei,经过softmax函数,得到每一个初始胶囊ui的重要性权值αi,按照重要性权值将所有初始胶囊相加,最后得到案件事实描述文本的辅助特征向量c;公式如下所示:
ei=tanh(wui+b)
其中w是权值矩阵,b是偏置向量。
s2.1.4构建输出层,将s2.1.2得到的案件事实描述文本的主要特征向量以及s2.1.3得到的案件事实描述文本的辅助特征向量c结合起来,并输送给全连层网络。
s2.2训练序列增强胶囊网络模型;
s3通过s2训练之后的序列增强胶囊网络模型,将新的案件的事实描述文本输入到序列胶囊网络模型中,模型自动预测相应罪名作为罪名预测结果。
进一步的,s1中的数据集来自于中国裁判文书网公开的真实刑事案件,每件案件包括两个部分:案件的事实描述和罪名判罚结果,将其作为训练数据。
进一步的,s2.1.1中分词采用的是北京大学开源工具pkuseg,并利用embedding技术将word2vec训练的词向量映射为词向量序列。
进一步的,s2.2中采用focalloss损失函数训练序列增强胶囊网络模型。
与现有技术相比:
(1)本发明提出了一种序列增强胶囊网络模型,该模型不仅能较好地捕捉到法律文本的显著特征和语义信息,而且在低频罪名预测问题上具有较好的竞争力。
(2)引入了focalloss损失函数,作为序列增强胶囊网络模型的损失函数,进一步缓解了低频罪名预测任务的罪名高度不平衡问题。
(3)通过比较目前最先进的方法,本发明提出的序列增加胶囊网络模型在真实数据集criminal-s和criminal-l中分别实现了4.5%和6.4%的f1提升。实验结果一致证明了序列增强胶囊网络模型在解决低频罪名场景中的优越性和竞争力。
附图说明
图1是本发明所述方法的流程图;
图2是本发明序列胶囊网络模型的示意图;
图3是本发明的seq-caps层的示意图;
图4是本发明的attention层的示意图。
具体实施方式
下面结合说明书附图和具体实施例对本发明做进一步阐述。
本发明的简要流程框图如图1所示,本发明基于序列胶囊网络模型的刑事案件罪名预测方法包括以下步骤:
s1构建训练数据集,获取案件的事实描述以及罪名判罚结果作为训练数据;
本发明在公开的三个真实数据集上进行实验,这些数据集均来自于中国裁判文书网中公开的三个刑事案件,获取案件的事实描述以及罪名判罚结果作为训练数据;由于公开的数据集中仅保留了案件的主罪名,因此,只需要将每个罪名映射为一个唯一的整数进行编码。
s2构建序列增强胶囊网络模型并通过训练数据进行训练,包括以下步骤:
s2.1构建序列增强胶囊网络模型,本发明的序列增强胶囊网络模型如图2所示。构建该模型包括以下步骤:
s2.1.1构建初始胶囊层:对案件的事实描述文本进行分词,并利用embedding技术将word2vec训练的词向量映射为词向量序列,将其作为初始胶囊层u={u1,u2,…,un}。
s2.1.2构建multipleseq-caps层,通过对s2.1.1得到的初始胶囊层u,利用multipleseq-caps层得到案件事实描述文本的主要特征向量。
所述multipleseq-caps层由两个seq-caps层组成,对于每一个seq-caps层,如图3所示,由一个序列信息编码器(sequenceinformationencode)和一个动态路由转化器(dynamicrouting)组成。本发明使用长短期记忆网络(lstm)作为序列信息编码器。以第一个seq-caps层为例,将初始胶囊层u={u1,u2,…,un}传入到seq-caps层中,长短期记忆网络的公式如下:
ft=σ(wfut+ufht-1+bf),
it=σ(wiut+uiht-1+bi),
ot=σ(wout+uoht-1+bo),
ht=ototanh(ct)
通过上述公式求解第ht时刻的序列信息,其中ft、it、ot分别是lstm的遗忘门、输入门、输出门,
然后将序列信息编码器的输出传到动态路由转化器中,首先将低层胶囊uj|i通过矩阵wj映射到低层胶囊副本。接着,低层胶囊副本利用动态路由机制将uj|i聚合成高层胶囊层,在这一步,得到了动态路由转化器的输出v={v1,v2,…,vn},v表示案件事实描述文本的主要特征向量。
s2.1.3构建基于注意力机制的残差单元层(attention层),对初始胶囊层u={u1,u2,…,un}使用注意力机制,得到案件事实描述文本的辅助特征向量c。
所述attention层如图4所示:
将初始胶囊层u中的n个初始胶囊ui,(i=1,2,…,n)通过权值矩阵w,得到一个经过矩阵变换后的向量ei,然后对向量ei,经过softmax函数,得到每一个初始胶囊ui的重要性权值αi,按照重要性权值将所有初始胶囊向量相加,最后得到案件事实描述文本的辅助特征向量c;公式如下所示:
ei=tanh(wui+b)
其中w是权值矩阵,b是偏置向量。
s2.1.4构建输出层,将s2.1.2得到的案件事实描述文本的主要特征向量以及s2.1.3得到的案件事实描述文本的辅助特征向量c结合起来,并输送给全连层网络。
s2.2训练序列增强胶囊网络模型:利用focalloss损失函数训练s2.1得到的序列增强胶囊网络模型。所述focalloss损失函数公式如下式所示:
其中,
s3通过s2训练之后的序列增强胶囊网络模型,将新的案件的事实描述文本输入到序列胶囊网络模型中,模型自动预测相应罪名作为罪名预测结果。
为了说明本发明提出的基于序列胶囊网络的刑事案件罪名预测方法的有效性,本发明将其与几个经典的文本分类方法以及现有的两个最先进的罪名预测方法在三个数据集中进行比较。此外,为了证明本发明的模型在处理低频罪名预测方面的有效性,我们进行了一组不同频率的罪名预测实验。
表1显示了基于三个数据集的基线模型的结果。总的来说,本发明提出的基于序列胶囊网络的刑事案件罪名预测方法在三个数据集上的性能优于所有的基线,具有显著的优势。具体地,与之前最先进的罪名预测方法相比,本发明的模型利用f1评价指标,在三个数据集上分别获得了4.5%、2.5%和6.4%绝对可观的改进,说明了本发明提出的基于序列胶囊网络的刑事案件罪名预测方法对罪名预测任务的有效性。这一趋势表明本发明提出的基于序列胶囊网络的刑事案件罪名预测方法能够捕获对罪名预测至关重要的法律文本的高级语义表示。
表1:真实数据集下的罪名预测结果比较,其中mp表示macroprecision,mr表示macrorecall,f1表示macrof1。
低频罪名比较
表2:真实数据集下的低频罪名比较
为了进一步说明本发明提出的基于序列胶囊网络的刑事案件罪名预测方法在处理低频罪名方面的有效性,我们进行了一组不同频率的罪名分割实验。我们将罪名按频率分为三部分(低频、中频和高频)。低频定义为所有数据集中出现的罪名小于10次(含10次),高频定义为所有数据集中出现的罪名大于100次(除100次外),其他则属于中频。
表2显示了本发明提出的基于序列胶囊网络的刑事案件罪名预测方法在criminal-s数据集上不同频率下的性能,我们比较了本发明的模型与最先进的罪名预测模型以及最先进的文本分类模型在macro-f1的低频、中频和高频结果。从表中可以看出,低频的macro-f1为53.8%,比lstm-200模型提高了65%以上,比最先进的罪名预测模型提高了4.1%。在secaps模型的帮助下,不仅缓解了低频罪名预测问题,而且提出了一种端到端的模型,减少了人工数据标记。其中secaps模型具有较强的向量表示能力和序列表示能力,focalloss在处理分类不平衡和分类困难的问题上有较好的表现,可以缓解低频罪名预测的不足。
- 还没有人留言评论。精彩留言会获得点赞!