一种基于HiveMutationAPI进行数据更新的方法与流程
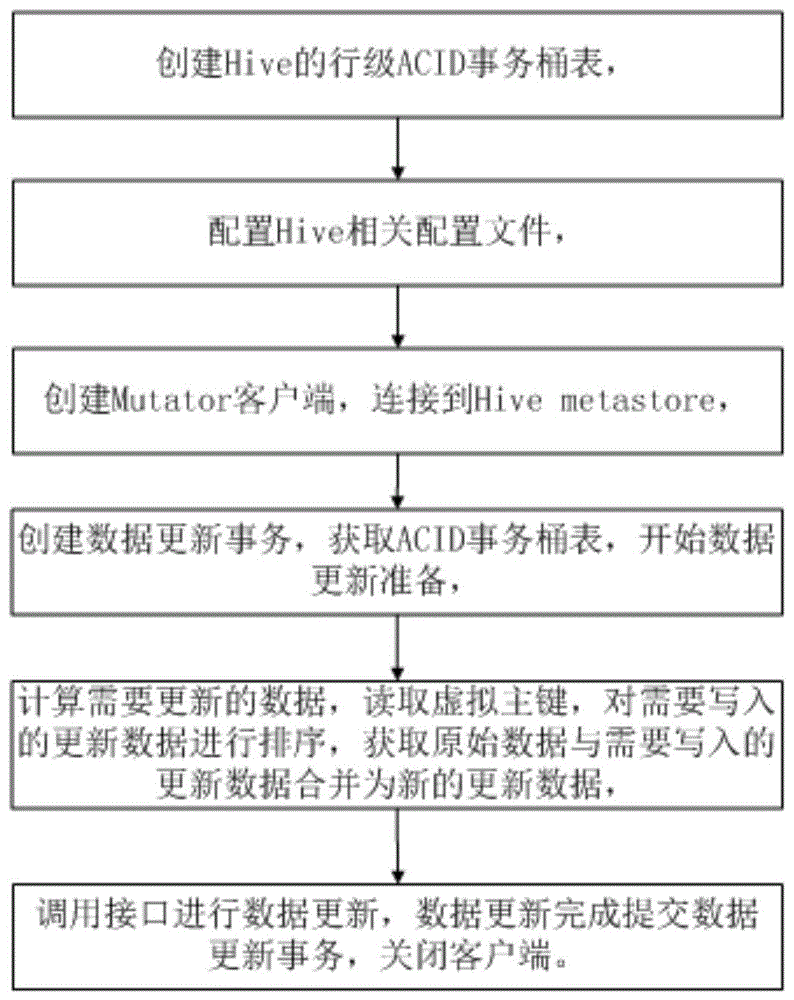
本发明公开一种基于hivemutationapi进行数据更新的方法,涉及数据更新
技术领域:
。
背景技术:
:大数据环境下,数据量日益增长,业务上对数据的备份及数据更新的需求越来越显著。现有的数据存储技术,将源数据从关系型数据库,如oracle、mysql等,抽取到hive数据仓库后,对数据更新的支持并不完善。现有技术针对hive数据仓库需要进行数据更新的情况,一般采取的方案是:将某个分区的数据删除掉,再重新导入。一旦当关系型数据库的原始数据存在数据更新,为了保证数据的一致性,现有技术会将hive数据表的某个分区甚至整张数据表全部删掉,再将关系型数据库的数据重新抽取到数据仓库。如此耗费了较多时间和资源,并且当关系型数据库更新比较频繁时,这种将数据删除重新导入的方法显然不能满足业务需求,数据一致性很难保证。为了解决hive数据更新存在的问题,本发明提供了一种基于hivemutationapi进行数据更新的方法,可以指定hive数据表中的数据进行更新,解决了现有的hive数据更新时,只能删除整个分区再重新写入的问题,提高了数据更新的性能,保证了数据一致性。技术实现要素:本发明针对现有技术的问题,提供一种基于hivemutationapi进行数据更新的方法,利用hivemutationapi,实现了hive进行数据更新,解决hive难以进行数据更新的问题。本发明提出的具体方案是:一种基于hivemutationapi进行数据更新的方法:创建hive的行级acid事务桶表,配置hive相关配置文件,创建mutator客户端,连接到hivemetastore,创建数据更新事务,获取acid事务桶表,开始数据更新准备,计算需要更新的数据,读取虚拟主键,对需要写入的更新数据进行排序,获取原始数据与需要写入的更新数据合并为新的更新数据,调用接口进行数据更新,数据更新完成提交数据更新事务,关闭客户端。所述的方法中虚拟主键包括bucketid和rowid,虚拟主键利用bucketid将需要写入的更新数据进行排序,虚拟主键利用rowid识别acid事务桶表中的记录,获取原始数据与需要写入的更新数据合并为新的更新数据,新的更新数据根据rowid进行排序。所述的方法中创建hive的行级acid事务桶表,通过建表语句clusteredby确定分桶字段,into确定分桶个数,且分桶字段不可更新。所述的方法中配置连接信息,设置metastore连接的uri,数据库名称,数据表名称,数据表所在分区,分区数据,以便mutator客户端连接到hivemetastore。所述的方法中数据更新事务读取分区数据及虚拟主键时,hive设置数据表所在分区的hdfs路径,获取行级acid事务桶表的分桶个数,设置数据表字段名称,字段类型。所述的方法中计算需要更新的数据,将新的更新的数据和虚拟主键组成一条数据更新记录,多条一次性数据更新记录放置在list集合列表里。所述的方法中对list集合列表中的记录根据虚拟主键进行排序和分组。所述的方法中如果计算需要更新的数据时,传参是某几列需要更新的字段,则查询虚拟主键时将一条记录的所有列查询出来,将需要更新的字段替换掉再更新;如果传参为一条记录的所有列,则只将虚拟主键查询出来,与传参构成一条完整的数据更新记录。所述的方法中将list集合列表转换成javabean,利用java反射机制将object对象转换成javabean对象。所述的方法中创建行级acid事务桶表的mutatorcoordinator协调器,调用mutatorcoordinator协调器接口进行数据更新。本发明的有益之处是:本发明提供一种基于hivemutationapi进行数据更新的方法,创建mutator客户端,连接到hivemetastore,创建数据更新事务,计算需要更新的数据,读取虚拟主键,对需要写入的更新数据进行排序,获取原始数据与需要写入的更新数据合并为新的更新数据,调用接口进行数据更新,与现有技术相比,提高了hive数据更新的性能,摆脱了hive更新时需要删除原数据再重新导入的状况。附图说明图1是本发明方法流程示意图;图2是本发明hive更新性能数据对照图。具体实施方式本发明提供一种基于hivemutationapi进行数据更新的方法:创建hive的行级acid事务桶表,配置hive相关配置文件,创建mutator客户端,连接到hivemetastore,创建数据更新事务,获取acid事务桶表,开始数据更新准备,计算需要更新的数据,读取虚拟主键,对需要写入的更新数据进行排序,获取原始数据与需要写入的更新数据合并为新的更新数据,调用接口进行数据更新,数据更新完成提交数据更新事务,关闭客户端。下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定。利用本发明方法对1-100列数据表作了性能测试,更新数据量为200万条,具体过程如下:创建hive的行级acid事务桶表,通过建表语句clusteredby确定分桶字段,into确定分桶个数,且分桶字段不可更新,配置hive相关配置文件,hive相关配置文件包括core-site.xml,hdfs-site.xml,hive-site.xml等,配置后,通过连接hive的metastore元数据模块,进行数据更新;创建mutatorclient客户端,用来管理目标acid表的事务,配置连接信息,具体包括设置metastore连接的uri,数据库名称,数据表名称,数据表所在分区,更新的分区数据等,客户端连接到hivemetastore,创建数据更新事务,获取acid事务桶表,设置数据表所在分区的hdfs路径,设置事务桶表的分桶个数,设置数据表字段名称,字段类型等,开始数据更新准备,计算需要更新的数据,读取虚拟主键,虚拟主键除bucketid,rowid外,还可包括transactionid,虚拟主键可利用bucketid将需要写入的更新数据进行排序,虚拟主键利用rowid识别acid事务桶表中的记录,获取原始数据与需要写入的更新数据合并为新的更新数据,新的更新数据与虚拟主键可组成一条完整的数据更新记录,如果一次性更新多条数据更新记录,则将多条数据更新记录放到list集合列表里,这样多条更新记录存放的数据结构为list<object>的集合列表,其中object对象包括数据表的所有列以及该条记录对应的虚拟主键,在计算需要更新的数据时,如果传参是某几列需要更新的字段,则查询虚拟主键时将一条记录的所有列查询出来,将需要更新的字段替换掉再更新;如果传参为一条记录的所有列,则只将虚拟主键查询出来,与传参构成一条完整的数据更新记录,根据虚拟主键的rowid可对list集合列表进行排序,分组,可将list集合列表转换成javabean,利用java反射机制将object转换成javabean对象;创建mutatorcoordinator协调器,调用insert、update接口进行数据写入或更新,写入前给写入的记录增加bucketid,通过bucketidresolver可以得到bucketid,根据bucketid对写入数据排序分组,调用insert接口写入数据,更新数据时,利用虚拟主键查询数据更新记录,调用update接口进行数据更新;完成写入或更新,关闭mutatorcoordinator,将mutator客户端创建的事务提交,关闭客户端连接,数据更新结束。通过实践,验证了该技术完全满足对数据更新的需求,优于以往的处理方案。对1-100列数据表作了性能测试,更新数据量为200万条。通过性能测试得到如图2hive更新性能结果。对于100列以内的数据表,其更新性能达到2万条/秒-20万条/秒。如图2,横轴为hive数据表列的个数,纵轴为每秒更新条数。表1为hive更新时间、数据所占空间大小、更新性能等更细粒度的结果展示。表1hive表列数更新时间(秒)hive表数据大小更新性能(条/秒)111123.6m2000001017255.3m1176472027400.0m740743032548.6m625004043696.9m465115048828.6m416666054973.9m3703770671.1g3125080681.2g2941290891.4g224721001011.5g19608以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本
技术领域:
的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1