一种计算板卡的制作方法
本发明实施例涉及计算机领域人工智能运算技术,尤其涉及一种计算板卡。
背景技术:
随着互联网和信息行业的快速发展,各种声音、图像、视频数据均呈井喷式的发展,大数据处理已经逐步取代传统的人工数据处理,而人工智能(简称ai)技术的应用使得大数据分析处理能力得到再一次飞跃。
深度学习技术引发了人工智能应用的高速发展,引领人类由信息时代进入智能时代。深度学习本质是一种机器学习技术,需要强大的硬件计算能力,来完成复杂的数据处理和运算。对于如此庞大的数据处理和运算,现有的人工智能解决方案中,采用专用的ai加速处理芯片执行深度学习运算,但是即使单个超高性能的ai加速处理芯片,其处理能力也远远达不到运算需求。
现有技术中ai计算服务器都是大型设备,一般通过数量较多的gpu组成算力阵列,目前还没有根据需要进行算力板卡数量配置的使用单机箱的功能强大的ai计算服务器。
技术实现要素:
为解决上述问题,本发明提供一种计算板卡,包括转接板卡和算力板卡,
所述转接板卡包括m.2插座、桥接芯片和pcie接口,所述桥接芯片包括第一接口和第二接口,所述第一接口连接所述m.2插座;所述第二接口连接所述pcie接口;
所述算力板卡包括m.2插头和ai芯片,所述ai芯片包括和所述m.2插头连接的第三接口,所述m.2插头和所述m.2插座可拆卸式连接;
其中,所述桥接芯片通过pcie接口从外部设备获取第一数据并传输至所述ai芯片进行计算,然后将基于第一数据的计算结果传输至外部设备;或者所述桥接芯片将从外部设备获取多个第二数据,将所述多个第二数据并行传输至多个ai芯片进行计算,然后将基于第一数据的计算结果传输至外部设备,所述第一数据为预设事件的特征数据,所述计算结果为预设事件的ai判断结果。
进一步地,所述算力板卡为多个,所述多个算力板卡并行连接至所述桥接芯片。
进一步地,所述算力板卡进一步包括控制芯片,每个算力板卡包括的ai芯片为多个,所述多个ai芯片通过所述控制芯片连接至所述m.2插头。
进一步地,所述多个ai芯片串行连接至所述控制芯片。
进一步地,所述pcie接口包括供电端,用于为所述桥接芯片和ai芯片提供工作电源。
进一步地,所述第一数据为图像数据,所述第二数据为物体、人脸、指纹中的一种或多种。
进一步地,所述计算板卡进一步包括电源电路,用于通过所述m.2插座和m.2插头为所述ai芯片供电。
进一步地,所述计算板卡为多个,多个计算板卡包括pcie转接排线,所述多个计算板卡通过所属pcie转接排线与服务器主板电连接。
进一步地,所述计算板卡靠近服务器主机箱侧壁的一端还包括固定卡扣,用于将所述计算板卡固定在服务器主机箱表面。
进一步地,所述计算板卡表面还包括覆盖于所述计算板卡表面的散热装置。
本发明通过使用m.2插座转接桥接芯片,使服务器主机能够方便配置算力。
附图说明
图1是本发明实施例一中的计算板卡的结构示意图。
图2是本发明实施例二中的算力板卡的结构示意图。
图3是本发明实施例三中的服务器主机的结构示意图。
具体实施方式
下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。
实施例中出现的缩写解释如下:
m.2接口:m.2接口是intel推出的一种替代msata新的接口规范。m.2接口分两种类型,分别支持sata通道与nvme通道,其中sata3.0只有6g带宽,而后者是走pcie通道,能提供高达32g的带宽,nvme作为新一代存储规范,由于走pcie通道带宽充足,可提升空间极大,传输速度更快。
ai芯片:在人工智能计算领域用于执行ai算法的芯片,主要用于图像处理、语音处理、人像识别等领域。
fpga:field-programmablegatearray,现场可编程门阵列,是在可编程器件的基础上进一步发展的产物。它是作为专用集成电路领域中的一种半定制电路而出现的,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。
pcie:peripheralcomponentinterconnectexpress,一种基于数据包、串行、点到点的高性能互连总线协议。其定义了一种分层的体系结构,包括软件层、处理层、数据链路层和物理层。其中软件层是保持与pci总线兼容的关键,pcie采用与pci和pci—x相同的使用模型和读写通信模型。支持各种常见事物,如存储器读写事物,i/o读写事物和配置读写事物。而且由于地址空间模型没有变化,所以现有的操作系统和驱动软件无需进行修改即可在pcie系统上运行。此外pcie还支持一种称为消息事物的新事物类型。这是由于pcie协议在取消了许多边带信号的情况下,需要有替代的方法来通知主机系统对设备中断、电源管理、热插拔支持等进行服务。
实施例一
本发明实施例一提供一种计算板卡,能够拼装于狭小空间,同时为服务器提供足够的算力。
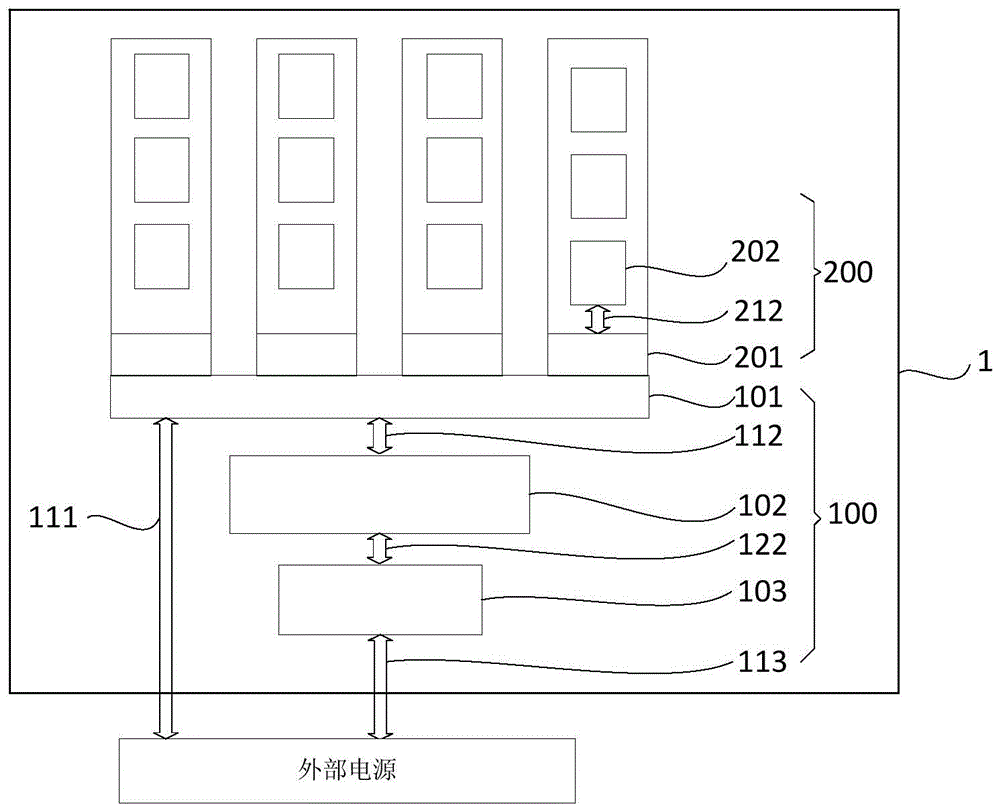
如图1所示,计算板卡1包括转接板卡100和算力板卡200。
其中,转接板卡100包括m.2插座101、桥接芯片102和pcie接口103,桥接芯片102包括第一接口112和第二接口122,第一接口112连接m.2插座101;第二接口122连接pcie接口103。
算力板卡200包括m.2插头201和ai芯片202,ai芯片202包括和m.2插头201连接的第三接口212,m.2插头201和m.2插座101可拆卸式连接。
计算板卡1也被称为ai加速器或计算卡,用于计算输入的数据,执行ai运算加速处理,是专门用于处理人工智能应用中的大量计算任务的模块(其他非计算任务仍由处理器负责)
转接板卡100用于在计算板卡1中提供数据的合并或分路。也可用于调试、检修、引入或引出信号以方便连接测试仪器或提供信号源,本发明中,转接板卡100用于提供数据的合并或分路。
m.2插座101和m.2插头201均采用m.2数据接口。
因此,本实施例通过桥接芯片102将pcie接口103与m.2插座101连接起来,提高数据传输速率。
pcie接口103为一种导电触片式接口,采用了目前业内流行的点对点串行连接,比起pcie以及更早期的计算机总线的共享并行架构,每个设备都有自己的专用连接,不需要向整个总线请求带宽,而且可以把数据传输率提高到一个很高的频率,达到pci所不能提供的高带宽。相对于传统pci总线在单一时间周期内只能实现单向传输,pcie的双单工连接能提供更高的传输速率和质量。由于使用ai芯片进行运算对数据接口的要求较高,因此本发明采用pcie接口,能够使接口负担大量图像处理数据的实时传输需求,保证服务器主机正常运作。服务器可以是1u、2u或4u等规格,根据服务器的规格不同,pcie接口103可以选用若干个pciex4、pciex8或pciex16接口。本实施例优选为pciex16接口。
在具体工作过程中,桥接芯片102通过pcie接口103从外部设备获取第一数据并传输至ai芯片202进行计算,然后将基于第一数据的计算结果传输至外部设备;或者桥接芯片102将从外部设备获取多个第二数据,将多个第二数据并行传输至多个ai芯片202进行计算,然后将基于第二数据的计算结果合并为第一数据的计算结果并传输至外部设备,第一数据为预设事件的特征数据,具体地,在本实施例中,预设时间的特征数据指的是在本实施例中是需要ai芯片进行处理的图像数据及其他ai算法任务,第二数据为待处理图像数据或其他ai算法任务根据桥接芯片102分解得到的数据,具体为物体、人脸、指纹识别中的一种或多种。第一/第二运算结果为预设事件的多个ai芯片202的运算判断结果。
可选地,pcie接口103包括第一供电端113,供电端113用于为桥接芯片102提供工作电源。
可选地,计算板卡1进一步包括第二供电端111,用于通过m.2插座101和m.2插头201为ai芯片202供电。
本实施例一提供的技术方案中,算力板卡通过m.2接口将多个ai芯片和控制芯片构成的算力板卡插接在转接板上,可以根据需求方便地配置服务器的算力。
实施例二
如图2所示,实施例二与实施例一的计算板卡的其他部分相同,区别在于实施例二提供了另一种算力板卡300的结构。
算力板卡300包括m.2插头301和ai芯片302,还包括管理多个ai芯片302的控制芯片303。
ai芯片302包括和控制芯片303连接的第四接口313,控制芯片303包括和m.2插头301连接的第五接口314。在本实施例中,每个算力板卡300包括的ai芯片302为多个,多个ai芯片302通过控制芯片303连接至m.2插头301。具体地,多个ai芯片302串行连接至控制芯片303。
ai芯片302与控制芯片303之间通过第四接口313连接,具体地,第四接口313用于在ai芯片302与控制芯片303之间传输大量数据,由于ai芯片302与控制芯片303之间有大量的数据交换,所以第四接口313采用特殊的数据接口,本实施例优选为fip数据接口。
本实施例的控制芯片303可以是用于人工智能计算的现场可编程门阵列(fieldprogrammablegatearray,缩写为fpga)芯片、用于人工智能计算的专用集成电路(applicationspecificintegratedcircuit,缩写为asic)芯片或者图形处理器(graphicsprocessingunit,缩写为gpu)芯片等等,本实施例采用fpga控制芯片。需要说明的是,控制芯片303可以与ai芯片302采用各种合适的互连方式,可选地,本实施例中多个ai芯片302串行连接至控制芯片303。
算力板卡300还包括电源管理芯片304,用于对控制芯片303和多个ai芯片302进行电能的变换、分配及管理。电源管理芯片304(powermanagementintegratedcircuits)是在电子设备系统中担负起对电能的变换、分配、检测及其他电能管理的职责的芯片,主要负责推动后级电路进行功率输出,其性能的优劣对服务器主机的性能有直接影响。常用电源管理芯片有hip6301、is6537、rt9237、adp3168、ka7500、tl494或slg46722cpld等,本实施例中,电源管理芯片304的型号优选为slg46722cpld。
本实施例二通过在计算板卡中增加控制芯片和电源电路,使计算板卡能够合理分配计算数据任务及电能。
实施例三
本实施例三在实施例一、二的基础上对计算板卡1在服务器主机中的结构做了进一步细化。
如图3所示,具体地,多个计算板卡1包括pcie转接排线400、固定插板500和散热装置600。
服务器主机2包括pcie插槽3、服务器主板4、电源5、存储器6、处理器7、磁盘阵列8、固定卡座9,pcie插槽3设置于服务器主板4表面,电源5与服务器主板4电连接,存储器6和处理器7设置于服务器主板4表面,磁盘阵列8与存储器6和处理器7电连接,固定卡座9设置于服务器主机2的侧壁。
计算板卡1为多个,层叠设置于服务器主机2中。
pcie转接排线400通过pcie插槽3将多个计算板卡1与服务器主板4电连接。pcie转接排线400一端连接计算板卡1,另一端插入pcie插槽3,使计算板卡1能够与服务器主机2电连接。
计算板卡1靠近服务器主机2侧壁的一端还包括层叠设置的固定插板500,固定插板500位于计算板卡1靠近服务器主机2侧壁的一端,能够与固定卡座9连接,用于将计算板卡1通过机械结构固定在服务器主机侧面,防止计算板卡1在服务器主机2内移动或损坏元器件。同时由于服务器主机内部比较狭小,将计算板卡1层叠设置能够减少在服务器主机2内的空间占用,通过固定插板500可以根据需要在服务器主机2内配置多个计算板卡1,增强算力。
散热装置600为固定覆盖在计算板卡1表面的散热盖,用于促进计算板卡1的散热,同时保护计算板卡1表面的元器件。由于计算板卡1在执行计算任务时会产生热量,有可能超出警戒温度,导致元器件电路运行不稳,使用寿命缩短,甚至损坏计算板卡上的元器件,因此需要使用散热装置吸收热量,保证各部件的温度正常。散热装置600可以是散热风扇和/或水冷散热器,散热风扇通过加快空气对流加快散热;水冷散热器使用液体在泵的带动下强制循环带走散热器的热量,具有降温稳定、对环境依赖小等优点。水冷散热器由于热容量大,热波动相对小,稳定性更好。因此在本实施例中,散热装置600优选为覆盖在计算板卡上的水冷散热器。同时,在计算板卡1表面加装散热盖,能够起到隔离灰尘的作用,防止灰尘落入计算板卡1表面造成短路等问题,保持计算板卡1的正常工作状态。
pcie插槽3用于固定pcie转接排线400,pcie插槽3具体为具有多个插槽的阵列,每个pcie插槽3均可通过插接pcie转接排线400固定安装一个计算板卡1。当安装有多个计算板卡1时,服务器可以形成关于ai计算的资源池。需要说明的是,通过pcie插槽3,计算板卡1能够以热插拔方式安装在服务器主板4上,可以根据需要调节计算板卡1的安装数量,使服务器主机2能够方便地调节ai计算的资源池的规模,根据需要进行计算板卡1的数量配置,提升服务器主机算力。
电源5分别与计算板卡1、服务器主板4、存储器6和处理器7、磁盘阵列8电连接,用于为上述元器件供电。电源5同时也用于为上述实施例一、二中的控制芯片203、多个ai芯片202供电。
存储器6与处理器7电连接;存储器6可用于存储服务器程序和/或模块,处理器7通过运行或执行存储在存储器6内的服务器程序和/或模块,实现服务器装置的各种功能。存储器6可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序等;存储数据区可存储根据终端的使用所创建的数据等。此外,存储器6可以包括高速随机存取存储器,还可以包括非易失性存储器,例如硬盘、内存、插接式硬盘,智能存储卡(smartmediacard,smc),安全数字(securedigital,sd)卡,闪存卡(flashcard)、至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件等。
处理器7与计算板卡1电连接,用于协调控制各个ai芯片202的接口。处理器7可以是中央处理单元(centralprocessingunit,cpu),还可以是其他通用处理器、数字信号处理器(digitalsignalprocessor,dsp)、专用集成电路(applicationspecificintegratedcircuit,asic)、现成可编程门阵列(field-programmablegatearray,fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等,处理器7是服务器的控制中心,利用各种接口和线路连接整个计算机装置的各个部分。
由于上述实施例一、二中的计算板卡不包括存储单元,本实施例三服务器主机还提供磁盘阵列8,磁盘阵列8是由多块独立的磁盘组合形成的容量巨大的磁盘组,利用个别磁盘提供数据所产生加成效果提升整个磁盘系统效能,如图所示,本实施例中在服务器主机2内设置内接式磁盘阵列卡,用于对计算板卡2计算完成后的数据进行存储。
在计算板卡1工作过程中,处理器调用存储器内的服务器程序和/或模块,获取磁盘阵列内的第一数据,控制芯片203从处理器接收第一数据,根据ai芯片202的数量分解为多个第二数据,通过第一接口112从控制芯片203向ai芯片202分发第二数据运算任务进行计算,ai芯片202将第二数据运算结果返回至控制芯片203。控制芯片203将第二数据运算结果合并为第一数据运算结果,pcie接口103将接收到的第一数据运算结果传输至外部设备,即磁盘阵列。在计算板卡1工作过程中,第一数据指的是预设事件的特征数据,具体地,在本实施例中是需要ai芯片202进行处理的图像数据及其他ai算法任务,第二数据为待处理图像数据或其他ai算法任务根据控制芯片203分解得到的数据,具体为物体、人脸、指纹识别中的一种或多种。第一/第二运算结果为预设事件的多个ai芯片202的运算判断结果。
本实施例三通过在计算板卡1表面加装固定卡扣和散热装置,使计算板卡1能在服务器主机箱内占用更小的空间,及时散热,保证计算板卡1正常工作。
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
- 还没有人留言评论。精彩留言会获得点赞!