基于CNN算法和Lasso回归模型的热轧产品质量预测方法与流程
本发明属于轧钢产品质量预测技术领域,尤其涉及一种基于CNN算法和Lasso回归模型的热轧产品质量预测方法。
背景技术:
近年来,钢铁企业虽然已经解决钢铁产品生产不足的情况,但是针对产品质量并没有合适的控制模型,导致生产过程中资源使用量高于平均水平,轧钢生产能耗比过多,与国外的先进技术相比,仍有很大的进步空间。目前,钢铁产品主要用于建造业、航空航天以及汽车制造等各方各面中,这些行业对钢铁质量的要求十分严格,所以建立一个合适、准确的轧钢产品质量预测模型,对于产品质量性能预测,具有重大的意义。
钢铁的生产过程由多个环节组成,并且每一个环节都对产品质量产生影响,为了保障产品质量,需要建立生产变量和产品性能指标之间的联系,在现有的生产条件下,通过改变生产参数,达到控制产品质量的目的。钢铁企业经过多年的生产经验,已经积累了大量的生产数据,这些数据容易受到工厂噪声的污染,所以如何处理这些数据并将其使用在建模中,是产品质量建模前期的准备工作。目前,对产品质量建立预测模型的方法主要有回归算法和神经网络算法这两大类:回归模型结构简单,虽然可以避免过拟合问题的产生,但存在着预测结果与预期相差很大的缺点;全连接神经网络模型节点与节点之间均有连接,导致提取出的参数数量上升,使模型计算复杂度增加。因此,考虑到轧钢产品数据和建模过程存在的上述问题,需要选用合适的建模方法,完成产品质量预测。
技术实现要素:
(一)要解决的技术问题
针对现有存在的技术问题,本发明提供一种能够在一定程度上缓解模型过拟合的问题,提高模型预测精度的基于CNN算法和Lasso回归模型的热轧产品质量预测方法。
(二)技术方案
为了达到上述目的,本发明采用的主要技术方案包括:
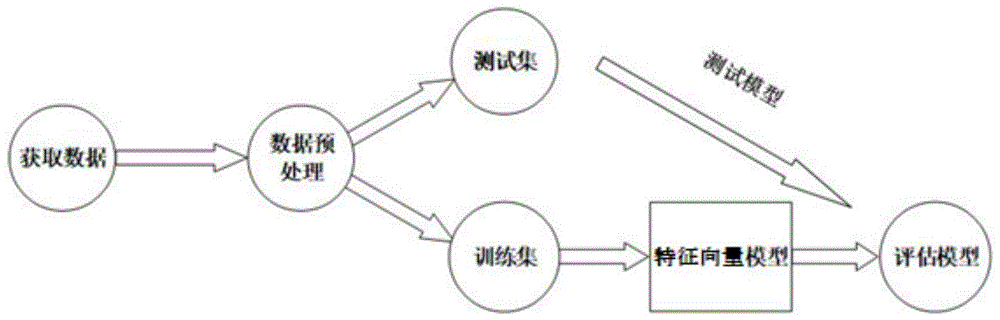
一种基于CNN算法和Lasso回归模型的热轧产品质量预测方法,包括以下步骤,
S1:获取关于热轧产品性能历史数据中用于建模的样本数据,样本数据包括训练数据,并确定关键输入变量;
S2:利用样本数据的关键输入变量对CNN进行训练,得到特征向量模型;
S3:将训练数据的关键输入变量代入特征向量模型,得到用于代入Lasso回归模型的输入变量;
S4:确定Lasso回归模型最优的正则化因子,并利用步骤S3中得到的输入变量对Lasso回归模型进行训练,得到未修正的混合预测模型,将未修正的混合预测模型进行至少一次的修正,得到修正后的用于对未来时间段的生产数据进行预测的混合预测模型;
S5:将未来时间段的生产数据输入所述修正后的混合预测模型,以获取生产数据的预测结果。
具体地,步骤S1中,获取关于热轧产品性能历史数据中用于建模的样本数据,包括,
S11:获取预设时间段内关于热轧产品性能的历史数据,对历史数据进行清洗处理,获取完整的清洗后的第一次数据;
S12:对清洗后的第一次数据进行采样,得到采样后的第二次数据;
S13:对采样后的第二次数据进行降维处理,得到降维后的第三次数据;
S14:对降维后的第三次数据进行归一化处理,最终得到用于建模的样本数据。
具体地,在步骤S14之后,还包括,
S15:确定样本数据中训练数据和测试数据的比例;
S16:选定关键输出变量。
具体地,步骤S4中,对未修正的混合预测模型进行至少一次的修正,包括,
S41:将测试数据的关键输入变量代入特征向量模型,得到用于代入未修正的混合预测模型的输入变量;
S42:将步骤S41中得到的输入变量代入未修正的混合预测模型,得到预测值,将预测值和测试数据的关键输出变量进行比较,以多次修正混合预测模型,直至预测值和测试数据中的关键输出变量的误差在预设范围内,得到修正后的用于对当前时间段的生产数据进行预测的混合预测模型。
具体地,步骤S11获取完整的清洗后的第一次数据包括,对于存在异常值和缺失值的数据,采用直接剔除的处理方式,对数据进行清理工作;
步骤S12得到采样后的第二次数据包括,使用系统随机抽样的方法对数据进行采样工作。
具体地,S13中数据降维包括,
用相关分析法确定采样后的第二次数据中输入变量和输出变量之间的关联程度,计算出两者之间的相关系数,并根据变量重要性程度确定模型的关键输入变量,降低模型中生产数据输入变量的维度,相关系数的计算方式为:
其中,n为样本数据组数,xi,yi(i=1,2,…n)为输入变量和输出变量,为输入变量和输出变量的平均值。
具体地,S14中数据归一化处理的具体方法为,
令xi=(xi1,xi2,…,xip),i∈2313,p为输入变量的特征总数,将数据归一化处理的公式为:
其中,为归一化处理后分布在0~1之间的数值,kmin对应生产变量的最小值,kmax对应生产变量的最大值。
具体地S15中确定样本数据中训练数据和测试数据的比例,包括,
分别用回归方法和神经网络方法建模,比较在不同比例下模型预测值和实际值的平均相对误差,得到训练数据和测试数据的比例;
S16中选定断裂延伸率、屈服强度和抗拉强度三个机械性能指标为关键输出变量。
具体地,S2中对CNN进行训练,得到特征向量模型,包括,
建立特征向量模型的过程包括前向传播和反向传播两个方面,
A、前向传播
将一维输入变量整合成6×6二维数据,第一个卷积层使用32个3×3大小的卷积核,第二个卷积层设计中,使用64个同样大小的卷积核,经过两个卷积层的逐层提取,最终得到具有代表性的局部数据特征,卷积输出计算公式为:
其中,表示加入激活函数后卷积层的输出,激活函数选用ReLU函数,Fj表示特征图个数,为前一层卷积特征的输入,为卷积核矩阵,为偏置量;
经过卷积处理以后,再对卷积后的特征采样,即对卷积层提取的全部数据特征进行统计处理,选用最大值池化方式采样,两个池化层窗口均设置成2×2大小,每经过一次池化处理,数据大小都会减小一半,计算公式为:
其中,为池化层作用后的输出,为池化权值,pooling为池化操作;
B、反向传播
反向传播是通过将预测值与实际值进行误差计算,并反向传递进行训练,对权值进行更新的一个过程,定义误差目标函数为:
其中,E代表反向传播误差,n为样本数,yn代表实际输出,代表预测输出。
具体地,S4中确定Lasso回归模型最优的正则化因子,包括,
设Xi(xi1,xi2,…,xip)T为模型的输入值,其中,i=1,2,…,N,N为样本数,p为生产变量特征数;Yi为模型的输出值。则Lasso回归加入L1正则化项以后优化的目标函数为:
式中,j=1,2,…,N,β=(β0,β1,…,βj)为j×1维的未知参数,λ为L1正则化项系数。
(三)有益效果
本发明的有益效果是:本发明提供的基于CNN算法和Lasso回归模型的热轧产品质量预测方法,利用CNN提取数据特征的优点,并用Lasso回归代替CNN的单层感知机预测输出,可以在一定程度上缓解模型过拟合的问题,提高模型的预测精度。
附图说明
图1为基于CNN算法和Lasso回归模型的热轧产品质量预测方法的模型图;
图2为对CNN进行训练的网络结构图;
图3为基于CNN算法和Lasso回归模型的热轧产品质量预测方法的流程图。
具体实施方式
为了更好的解释本发明,以便于理解,下面结合附图,通过具体实施方式,对本发明作详细描述。
本发明公开了一种基于CNN算法和Lasso回归模型的热轧产品质量预测方法,包括以下步骤,
S1:获取关于热轧产品性能历史数据中用于建模的样本数据,样本数据包括训练数据,并确定关键输入变量;
S2:利用样本数据的关键输入变量对CNN进行训练,得到特征向量模型;
S3:将训练数据的关键输入变量代入特征向量模型,得到用于代入Lasso回归模型的输入变量;
S4:确定Lasso回归模型最优的正则化因子,并利用步骤S3中得到的输入变量对Lasso回归模型进行训练,得到未修正的混合预测模型,将未修正的混合预测模型进行至少一次的修正,得到修正后的用于对未来时间段的生产数据进行预测的混合预测模型;
S5:将未来时间段的生产数据输入所述修正后的混合预测模型,以获取生产数据的预测结果。
具体地,步骤S1中,获取关于热轧产品性能历史数据中用于建模的样本数据,包括:
S11:获取预设时间段内关于热轧产品性能的历史数据,对历史数据进行清洗处理,获取完整的清洗后的第一次数据;
S12:对清洗后的第一次数据进行采样,得到采样后的第二次数据;
S13:对采样后的第二次数据进行降维处理,得到降维后的第三次数据;
S14:对降维后的第三次数据进行归一化处理,最终得到用于建模的样本数据。
具体地,在步骤S14之后,还包括,
S15:确定样本数据中训练数据和测试数据的比例;
S16:选定关键输出变量。
具体地,步骤S4中,对未修正的混合预测模型进行至少一次的修正,包括:
S41:将测试数据的关键输入变量代入特征向量模型,得到用于代入未修正的混合预测模型的输入变量;
S42:将步骤S41中得到的输入变量代入未修正的混合预测模型,得到预测值,将预测值和测试数据的关键输出变量进行比较,以多次修正混合预测模型,直至预测值和测试数据中的关键输出变量的误差在预设范围内,得到修正后的用于对当前时间段的生产数据进行预测的混合预测模型。
具体地,步骤S11获取完整的清洗后的第一次数据的具体方法是包括:对于存在异常值和缺失值的数据,采用直接剔除的处理方式,对数据进行清理工作;
步骤S12得到采样后的第二次数据包括:使用系统随机抽样的方法对数据进行采样工作。
具体地,S13中数据降维包括:
用相关分析法确定采样后的第二次数据中输入变量和输出变量之间的关联程度,计算出两者之间的相关系数,并根据变量重要性程度确定模型的关键输入变量,降低模型中生产数据输入变量的维度,相关系数的计算方式为:
其中,n为样本数据组数,xi,yi(i=1,2,…n)为输入变量和输出变量,为输入变量和输出变量的平均值。
为了减小样本数据之间数量级的差别,需要将各个变量统一在同一数量级,所以需要对数据进行归一化处理,可以实现生产变量从有量纲到无量纲的转变。具体地,S14中数据归一化处理的具体方法为,
令xi=(xi1,xi2,…,xip),i∈2313,p为输入变量的特征总数,将数据归一化处理的公式为:
其中,为归一化处理后分布在0~1之间的数值,kmin对应生产变量的最小值,kmax对应生产变量的最大值。
具体地,S15中确定样本数据中训练数据和测试数据的比例,包括:
分别用回归方法和神经网络方法建模,比较在不同比例下模型预测值和实际值的平均相对误差,得到训练数据和测试数据的比例应为8:2,所以选取样本数据的1850组作为训练数据,其余的463组作为测试数据。
确定生产中影响热轧产品机械性能的因素为32个关键输入变量,选定断裂延伸率、屈服强度)和抗拉强度三个机械性能指标为关键输出变量。
具体地,S2中对CNN进行训练,得到特征向量模型,包括,
建立特征向量模型的过程包括前向传播和反向传播两个方面,
A、前向传播
将一维输入变量整合成6×6二维数据,第一个卷积层使用32个3×3大小的卷积核,第二个卷积层设计中,使用64个同样大小的卷积核,经过两个卷积层的逐层提取,最终得到具有代表性的局部数据特征,卷积输出计算公式为:
其中,表示加入激活函数后卷积层的输出,激活函数选用ReLU函数,Fj表示特征图个数,为前一层卷积特征的输入,为卷积核矩阵,为偏置量;
经过卷积处理以后,再对卷积后的特征采样,即对卷积层提取的全部数据特征进行统计处理,选用最大值池化方式采样,两个池化层窗口均设置成2×2大小,每经过一次池化处理,数据大小都会减小一半,计算公式为:
其中,为池化层作用后的输出,为池化权值,pooling为池化操作;
B、反向传播
反向传播是通过将预测值与实际值进行误差计算,并反向传递进行训练,对权值进行更新的一个过程,定义误差目标函数为:
其中,E代表反向传播误差,n为样本数,yn代表实际输出,代表预测输出。
对CNN进行训练得到的特征向量模型最后用单层感知机作为输入,通过全连接层输出预测值,这种输出方式会导致过拟合问题,进而影响预测精度,而Lasso回归方法通过改变正则化系数,可以缓解过拟合问题,因此,可以使用Lasso回归代替CNN的单层感知机输出层进行预测,实现对CNN进行训练得到的特征向量模型的改进。Lasso回归,即最小绝对值收缩和选择算子,通过加入L1正则化,缓解模型出现过拟合的问题。
具体地,S4中确定Lasso回归模型最优的正则化因子,包括,
设Xi(xi1,xi2,…,xip)T为模型的输入值,其中,i=1,2,…,N,N为样本数,p为生产变量特征数;Yi为模型的输出值。则Lasso回归加入L1正则化项以后优化的目标函数为:
式中,j=1,2,…,N,β=(β0,β1,…,βj)为j×1维的未知参数,λ为L1正则化项系数。
随着正则化项系数λ的增加,可以在保留数据特征的情况下,使一些模型系数减小甚至为0,达到降维和变量选择的作用,从而有效的缓解模型过拟合问题。
CNN作为一种特殊的人工神经网络,具有自主学习的能力,优点在于局部连接和权值共享两大功能。通过神经元与前一层的神经元局部连接,实现部分特征代替整体特征的功能;权值共享意味着同一层面神经元的权值相同,可以减少模型处理的参数数量。另外,Lasso回归可以通过增加正则化系数,将估计参数较小的变量压缩为零,从而降低预测模型的复杂度和不稳定性,避免过拟合问题的产生。本发明引入了CNN代替全连接神经网络对轧钢产品质量预测进行建模,考虑到CNN利用单层感知机输出预测值的方式容易产生过度拟合,使测试集预测精度降低,所以提出了基于CNN算法和Lasso回归模型的热轧产品质量预测方法,既保持了CNN提取数据特征的优点,又可以利用Lasso回归模型缓解过拟合问题的优点,使模型复杂度和不稳定性降低。
以上结合具体实施例描述了本发明的技术原理,这些描述只是为了解释本发明的原理,不能以任何方式解释为对本发明保护范围的限制。基于此处解释,本领域的技术人员不需要付出创造性的劳动即可联想到本发明的其它具体实施方式,这些方式都将落入本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!