一种基于DeepDive技术构建K12教育知识图谱的方法与流程
本发明涉及计算机科学技术领域,具体为一种基于deepdive技术构建k12教育知识图谱的方法。
背景技术:
随着计算机的发展,人们在计算机的使用上越来越丰富,对于计算机的研究也越来越深层次了,并且将计算机运用到对知识点的筛选上,即是通过计算机绘制知识图谱,知识图谱在图书情报界称为知识域可视化或知识领域映射地图,是显示知识发展进程与结构关系的一系列各种不同的图形,用可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互联系。deepdive是一种抽取文本知识之间关系的技术。
现有技术也在使用一些内置的模型,并有自己的api,它们已经完成了产品推荐、工作推荐、工作列表和一些个人细节的搜索以及教育领域的工作。教育领域正在进行更多的研究工作,但它们没有提供良好的准确性。因此,我们提出了使用deepdive技术提取知识点之间的关系,通过大量的文章数据计算他们之间的相关度,来提高精度。
技术实现要素:
本发明的目的在于提供一种基于deepdive技术构建k12教育知识图谱的方法,具有deepdive技术提高获取结构化数据的效率;使用量化的数据计算知识点之间的关系,提高知识图谱的精确度;通过数据库中已有知识点与文章中知识点的对比的方式提取出知识点等优点,用以解决上述背景技术中提出的问题。
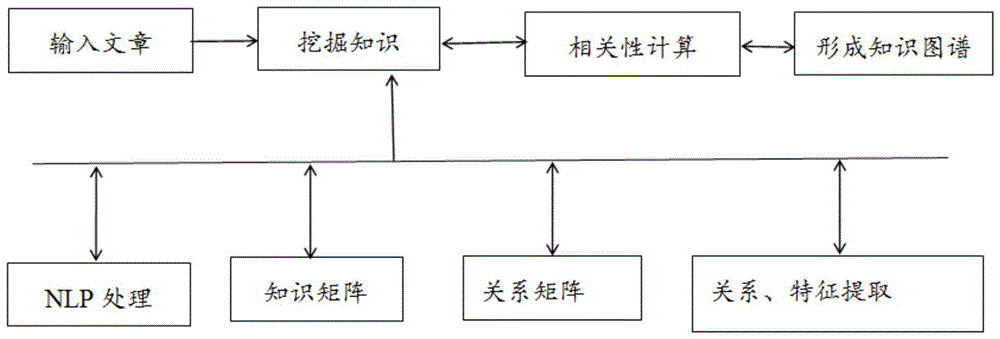
为实现上述目的,本发明提供如下技术方案:一种基于deepdive技术构建k12教育知识图谱的方法,包括如下步骤:
s1、输入文章,首先利用scrapy爬虫技术从网站上抓取文章,然后通过beautifulsoup从html和xml文件中提取数据,再将这些文章输入到deepdive深度学习框架中;
s2、挖掘知识点,deepdive通过执行nlp函数将输入的文章拆分成句子,再进行分词,词性标注、语法依赖,再将知识点与数据库中的已有知识点进行对比,输出相同知识点,并将分解得到的知识点存储到csv文件中;
s3、关系、特征的提取,从csv文件中提取出他们的特征和关系,经过一系列的筛选和整合操作,最终获取到符合要求的知识点;
s4、计算知识相关性,然后通过对不同层级知识点相关性计算和同层级知识点相关性计算的方法,开始计算所得到的知识点之间的相关性;
s5、绘制知识图谱,最后将知识点之间的相关性输入到neo4j工具中,进行构造成知识图谱。
所述步骤s1中beautifulsoup是一个用于从html和xml文件中提取数据的python库,且能够获取单个的url并剪切指定的数据;scrapy是一个用python编写的免费开源的web爬行框架。
所述步骤s2中deepdive从文本文档中的暗数据提取有价值的数据;deepdive将非结构化信息中创建结构化数据sql表,并将这些数据与现有的结构化数据库集成,提取有用的知识点。
所述步骤s2中使用deepdive技术提取出知识点,并作为输入,再根据分离结果,删除所有不必要的数据,将数据转换成键值对的形式,然后转换为所需的规范,即不同的密钥包含相同的值,因此我们将包含相同值的密钥组合在一起,从获得的结果中删除单个字符和特殊符号。
所述关键字的所有单词和字符,即所选关键字中除复数形式外的任何单词与末尾的最后一个字符相同,则该单词将移动到新列表中,将新列表与标记文件(句子)进行比较,如果新列表的单个单词位于标记文件(句子)中,则考虑该句子;且一直重复到所有句子都完成,将所有的句子合并成一个列表,并计算出句子列表中每个单词的出现次数;再次将新列表与句子列表进行比较,通过创建新的列表,将新列表和句子列表中常见的单词分开。
所述新获得的列表中,采用word2vec技术,查找单词之间的相关性,并用neo4j技术展示知识图谱。
所述知识数据转换成知识矩阵,且将数据键值对整理成知识之间的关系矩阵。
所述步骤s4中的不同层级知识点相关性计算:假设a,b,c,d四个知识点都在同一个知识点n下,那么知识点n出现的次数为包含abcd四个知识点的文章数量,a与n的关系即a出现的次数/n出现的次数;同层级知识点相关性计算:a,b两知识点的计算公式为log2(p(ab)/(p(a)*p(b))),其中p(ab)为ab同时出现的次数,p(a)为a出现的次数,p(b)为b出现的次数。
所述步骤s5中的neo4j是一个高性能的,nosql图形数据库,能够将结构化数据存储在网络上而不是表中;是一个嵌入式的、基于磁盘的、具备完全的事务特性的java持久化引擎,neo4j也可以被看作是一个高性能的图引擎。
与现有技术相比,本发明的有益效果是:
本发明使用deepdive将非结构化数据转换为结构化数据的基础框架,从暗数据中提取有价值的数据,deepdive技术提取出知识点,分离结果,删除所有不必要的数据,将数据转换成键值对的形式,将包含相同值的密钥组合在一起,删除结果中单个字符和特殊符号,进而使得deepdive技术可以提高获取结构化数据的效率;使用量化的数据计算知识点之间的关系,即不同层级知识点相关性计算和同层级知识点相关性计算方法,可以提高知识图谱的精确度;通过数据库中已有知识点与文章中知识点的对比的方式提取出知识点。
附图说明
图1为本发明的方法流程示意框图。
具体实施方式
下面将结合本发明实例中的附图,对本发明实例中的技术方案进行清楚、完整地描述。所描述的实例仅仅是本发明的一部分实例,而不是全部的实例。基于本发明中的实例,本领域其他人员在没有做出创造性改变前提下所获得的所有其他实例,都属于本发明保护的范围。
请参阅图1,本发明提供一种技术方案:一种基于deepdive技术构建k12教育知识图谱的方法,包括如下步骤:
s1、输入文章,首先利用scrapy爬虫技术从网站上抓取文章,然后通过beautifulsoup从html和xml文件中提取数据,再将这些文章输入到deepdive深度学习框架中;
s2、挖掘知识点,deepdive通过执行nlp函数将输入的文章拆分成句子,再进行分词,词性标注、语法依赖,再将知识点与数据库中的已有知识点进行对比,输出相同知识点,并将分解得到的知识点存储到csv文件中;
s3、关系、特征的提取,从csv文件中提取出他们的特征和关系,经过一系列的筛选和整合操作,最终获取到符合要求的知识点;
s4、计算知识相关性,然后通过对不同层级知识点相关性计算和同层级知识点相关性计算的方法,开始计算所得到的知识点之间的相关性;
s5、绘制知识图谱,最后将知识点之间的相关性输入到neo4j工具中,进行构造成知识图谱。
所述步骤s1中beautifulsoup是一个用于从html和xml文件中提取数据的python库,且能够获取单个的url并剪切指定的数据;scrapy是一个用python编写的免费开源的web爬行框架,该处的beautifulsoup能够获取单个的url并剪切指定的数据,scrapy是一个用python编写的免费开源的web爬行框架。它最初是为web抓取而设计的,也可以用于使用api提取数据,或者作为通用的web爬虫程序,通过beautifulsoup和scrapy能够快速的截取文章段落输入到deepdive中。
所述步骤s2中deepdive从文本文档中的暗数据提取有价值的数据;deepdive将非结构化信息中创建结构化数据sql表,并将这些数据与现有的结构化数据库集成,提取有用的知识点,该处的暗数据是大量隐藏在文本、表格、图形和图像中的数据,缺乏结构;通过deepdive的创建结构化数据实现对暗数据的曝光,能够快速的提取知识点与已有的知识点数据库对比。
所述步骤s2中使用deepdive技术提取出知识点,并作为输入,再根据分离结果,删除所有不必要的数据,将数据转换成键值对的形式,然后转换为所需的规范,即不同的密钥包含相同的值,因此我们将包含相同值的密钥组合在一起,从获得的结果中删除单个字符和特殊符号,该处的比较所选关键字的所有单词和字符,如果所选关键字中除复数形式外的任何单词与末尾的最后一个字符相同,则该单词将移动到新列表中。将新列表与标记文件或者句子进行比较,如果新列表的单个单词位于标记文件或者句子中,则考虑该句子。这个过程一直重复到所有句子都完成,我们把所有的句子合并成一个列表,并计算出句子列表中每个单词的出现次数。我们再次将新列表与句子列表进行比较,通过创建新的列表,将新列表和句子列表中常见的单词分开。在新获得的列表中,采用word2vec技术,查找单词之间的相关性,并用neo4j技术展示知识图谱。
所述知识数据转换成知识矩阵,且将数据键值对整理成知识之间的关系矩阵,该处的知识矩阵和关系矩阵的建立可以有效快速的提取到关系和特征的相关点,使得知识图谱的搭建十分的方便。
所述步骤s4中的不同层级知识点相关性计算:假设a,b,c,d四个知识点都在同一个知识点n下,那么知识点n出现的次数为包含abcd四个知识点的文章数量,a与n的关系即a出现的次数/n出现的次数;同层级知识点相关性计算:a,b两知识点的计算公式为log2(p(ab)/(p(a)*p(b))),其中p(ab)为ab同时出现的次数,p(a)为a出现的次数,p(b)为b出现的次数,该处的不同层级知识点相关性计算可以计算不同层级知识点之间的关系,同层级知识点相关性计算可以计算同层级知识点之间的关系,提高知识图谱绘制的精确度。
所述步骤s5中的neo4j是一个高性能的,nosql图形数据库,能够将结构化数据存储在网络上而不是表中;是一个嵌入式的、基于磁盘的、具备完全的事务特性的java持久化引擎,neo4j也可以被看作是一个高性能的图引擎,该处通过neo4j快速的对提取出来的知识点进行图谱绘制,且neo4j功能强大,运行速度快,能够有效精确的对知识图谱进行绘制。
工作步骤:
第一步、输入文章,首先利用scrapy爬虫技术从网站上抓取文章,然后通过beautifulsoup从html和xml文件中提取数据,再将这些文章输入到deepdive深度学习框架中;
第二步、挖掘知识点,deepdive通过执行nlp函数将输入的文章拆分成句子,再进行分词,词性标注、语法依赖,deepdive将非结构化信息中创建结构化数据sql表,并将这些数据与现有的结构化数据库集成,提取有用的知识点,再将知识点与数据库中的已有知识点进行对比,输出相同知识点,并将分解得到的知识点存储到csv文件中;
第三步、关系、特征的提取,从csv文件中提取出他们的特征和关系,将知识数据转换成知识矩阵,且将数据键值对整理成知识之间的关系矩阵,该处的知识矩阵和关系矩阵的建立可以有效快速的提取到关系和特征的相关点,使得知识图谱的搭建十分的方便,最终获取到符合要求的知识点;
第四步、计算知识相关性,然后通过对不同层级知识点相关性计算和同层级知识点相关性计算的方法,开始计算所得到的知识点之间的相关性;
第五步、绘制知识图谱,最后将知识点之间的相关性输入到neo4j工具中,进行构造成知识图谱。
尽管已经显示和描述了本发明的实例,对于本领域的其他技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!