一种面向隐私保护的用户轨迹生成方法及系统与流程
本发明属于数据安全领域,更具体地,涉及一种面向隐私保护的用户轨迹生成方法及系统。
背景技术:
近年来,随着gps移动设备、智能手机、基于位置的社交网络和谷歌地图等交通导航服务的大力普及与发展,产生了大量基于用户的移动轨迹数据。利用第三方服务挖掘这些数据,以实现城市规划、出行模式分析、路线推荐和交通管理等目的。但是,轨迹数据往往蕴含了移动用户在时间、空间维度上的丰富信息,发布轨迹数据引发了合理的隐私担忧。针对轨迹数据的推理攻击,不仅可得出用户在什么时间去过什么位置,还可以分析出目标用户的家庭住址、工作地点等敏感位置信息,甚至可推测出用户的生活习惯、健康状态、宗教信仰等隐私信息。研究发现即使是完全的伪匿名化,通过一个外部数据集或者额外的背景知识足以高精度地重新识别个体。因此,传统的发布轨迹数据集的方法可能会造成隐私泄露,需要探索保护隐私的轨迹数据发布的新途径。
轨迹数据也是流数据的一种,即就是时空环境下,通过对一个或多个移动对象运动过程的采样所获得的数据信息序列,包括采样点位置、采样时间等。这些采样点数据信息根据采样先后顺序构成了轨迹数据流。对于轨迹数据隐私保护处理来说,需要讲求的是隐私性、可用性、高效性三者的动态平衡。由于轨迹流数据自身的高速、海量、不确定性(位置数据在每个单位时间到来的规模以及形式都是不可预知的)等特点,使得在轨迹流数据上做到实时隐私保护处理显得尤为困难。目前,针对轨迹数据信息的隐私保护的方法大致可以分为两类:
基于数据匿名化的隐私保护方法,如基于轨迹数据的k匿名技术,其核心思想为将一条轨迹和其他k-1条相似的轨迹泛化为一个匿名区域,使得每个区域至少覆盖k个用户,从而使得攻击者成功识别特定的轨迹信息的概率最高为1/k,以此满足匿名需求以达到隐私保护的目的。但这种k匿名技术存在一些漏洞和缺点,攻击者可以利用背景知识对数据集进行攻击,这种基于分区的轨迹隐私保护数据发布模型由于其确定性,很难抵抗这种类型的攻击。其可用性较高,而且其算法原理相对简单,但无法在理论上证明其绝对安全,只能对已有的方案进行改进和完善。
基于数据扰动的隐私保护方法,如差分隐私技术,它的原理是对原始数据、对原始数据的转换或者是对统计结果添加噪音来达到隐私保护效果。即使攻击者已经掌握除某一条记录之外的所有记录的信息,该记录的隐私也无法被披露。在攻击者在拥有最大背景知识条件下,系统仍能抵御各种攻击。也就是说,这个机制保证了一个数据集的每个个体的隐私信息都不被泄露,即使在数据集中添加或删除一条记录都不会对输出结果产生影响,但数据集整体的统计学信息比如均值,方差等却可以被外界了解。隐私性和可用性在不同的应用场景中难以做到更好的平衡。
技术实现要素:
针对现有技术的缺陷和改进需求,本发明提供了一种面向隐私保护的用户轨迹生成方法及系统,其目的在于做到用户数据隐私的保密性的同时,保证一定的数据可用性以及流数据处理的高效性。
为实现上述目的,按照本发明的第一方面,提供了一种面向隐私保护的用户轨迹生成方法,该方法包括以下步骤:
s1.将时间段t对应的位置元组数据流s所在区域范围划分为层次网格,采用geohash算法对各个网格进行编码,得到每个位置数据元组的编码字符串;
s2.根据划分后的网格和所有位置数据元组的编码字符串,生成该元组数据流s对应的前缀层次树;
s3.将该元组数据流s划分为k段,根据第一隐私预算值εa对每段数据流进行采样,得到采样后的位置元组数据集{d′i},1≤i≤k;
s4.根据差分隐私的指数机制,将各个采样后的位置元组泛化到对应的划分区域内,得到泛化后的位置元组数据集
s5.通过第二隐私预算εb,对处于相同划分网格内的元组数据
优选地,所述步骤s2中,隐私保护级别越高,所述前缀层次树中的节点个数越多,所述前缀层次树中的每个节点维护一个键值对pair<str,count>,其中,str表示该网格的地理哈希编码字符,count表示访问该网格的人数的计数值。
优选地,隐私保护级别越高,整体隐私预算ε越小,其中,ε=εa+εb;若用户隐私级别高,εb<εa,否则,εb≥εa。
优选地,步骤s3包括以下步骤:
s31.以时间窗口长度t为单位,将用户位置数据流s划分为k个连续的分段<d1,…,di,…,dk>;
s32.根据第一隐私预算εa,计算每个分段di的元组采样隐私预算εa,i,将其分配给对应分段;
s33.根据每段数据流di分配到的隐私预算εa,i值,计算其对应的采样概率
s34.根据采样概率pi,分别对每个分段数据流di中的位置数据进行采样,整理采样后得到的流数据元组,并生成采样后的元组数据集<d′1,…,d′i,…,d′k>;
其中,s为界限常数,满足
优选地,每个分段di的元组采样隐私预算εa,i计算公式如下:
优选地,步骤s4包括以下步骤:
s41.收集元组数据流s所在路网中的每个位置,组成位置域γ;
s42.对于每个分段d′i,计算其每一个元组数据x′iz对于在位置域γ的每个网格rj的权重分数q(x′iz,rj);
s43.使用差分隐私的指数机制,结合元组x′iz与周围网格的权重分数q(x′iz,rj),生成相应的泛化概率
s44.根据该概率将x′iz泛化到对应的网格rj中,得到元组数据集
其中,1≤z≤|d′i|,1≤j≤|γ|,rj表示位置域γ第j个网格。
优选地,每个网格rj的权重分数q(x′iz,rj)计算公式如下:
其中,pt[rj]表示网格节点rj所包含的访问者人数信息,δdisijz表示网格节点rj与d′i中的元组x′iz所在的网格节点之间的距离,a是小于1的常数,由位置域的面积确定。
优选地,步骤s5包括以下步骤:
s51.根据第二隐私预算εb的值,确定对应的元组合并级别level,该合并级别level代表元组要被合并到的网格的父节点的深度;
s52.定义k个空集合lri,对于在每段位置数据集
s53.对于祖先节点集合lri中的每个元素pij,计算键值对字典
s54.根据隐私预算εb和键值对字典
s55.使用差分隐私指数机制,根据概率pijn进行合并网格的选择;
s56.将每段位置数据集
其中,pijn表示pij的第n个子节点,1≤n≤|child(pij)|,child(pij)为pij的子节点集合,
优选地,步骤s1中的时间段t根据用户查询要求确定,步骤s5中,将生成的轨迹返回给查询用户。
为实现上述目的,按照本发明的第二方面,提供了一种面向隐私保护的用户轨迹生成系统,该系统包括以下:
数据预处理模块,用于将时间段t对应的位置元组数据流s所在区域范围划分为层次网格,采用geohash算法对各个网格进行编码,得到每个位置数据元组的编码字符串;
前缀层次树生成模块,用于根据划分后的网格和所有位置数据元组的编码字符串,生成该元组数据流s对应的前缀层次树;
元组采样模块,用于将该元组数据流s划分为k段,根据第一隐私预算值εa对每段数据流进行采样,得到采样后的位置元组数据集{d′i},1≤i≤k;
元组泛化模块,用于根据差分隐私的指数机制,将各个采样后的位置元组泛化到对应的划分区域内,得到泛化后的位置元组数据集
元组合并模块,用于通过第二隐私预算εb,对处于相同划分网格内的元组数据
总体而言,通过本发明所构思的以上技术方案,能够取得以下有益效果:
(1)本发明将元组采样后的分段数据作为输入,根据差分隐私的指数机制,将各个采样后的位置元组泛化到对应的划分区域内,通过扰乱和模糊原始位置,在确保数据可用性的同时有效避免了用户位置隐私的泄露,保证了隐私性和数据的高可用性。
(2)本发明的元组合并作用于各个单位时间段内,首先计算出每个候选划分网格,然后对处于同一划分网格内的多个元组的位置点进行位置合并操作,从而保证了生成轨迹数据的隐私性。
(3)本发明通过基于时间窗口的元组采样策略,结合隐私预算εa及采样概率,对各个时间窗口内的元组数据进行采样操作,缩减了数据集大小,提高实时运算处理的高效性。
(4)本发明通过对区域范围进行层次网格划分,并根据位置数据流构建前缀层次树,从而有利于元组泛化针对元组数据划分网格的权重分数的计算,并大大提高了实时运算操作的高效性。
附图说明
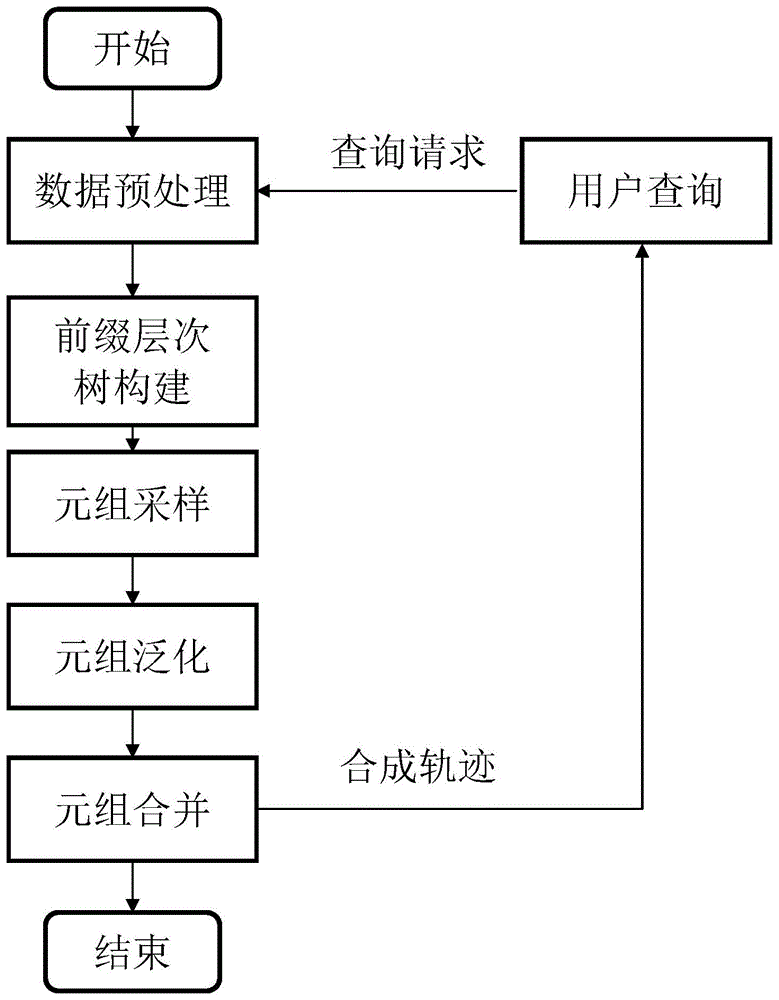
图1为本发明实施例提供的一种面向隐私保护的用户轨迹数据生成方法流程图;
图2(a)为本发明实施例提供的插入操作前的前缀层次树pt示意图;
图2(b)为本发明实施例提供的插入操作后的前缀层次树pt示意图;
图3(a)为本发明实施例提供的porto数据集中的隐私保护轨迹合成示意图;
图3(b)为本发明实施例提供的t-drive数据集中的隐私保护轨迹合成示意图;
图3(c)为本发明实施例提供的nyc数据集中的隐私保护轨迹合成示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
如图1所示,本发明提供了一种面向隐私保护的用户轨迹数据生成方法,该方法包括以下步骤:
(1)数据清洗
以实时采集到的流式位置数据元组为输入,对这些流式位置数据进行数据清洗,清除无关数据、重复数据或原始数据流中的异常值,得到经过数据清洗后的元组数据流s。
具体来说,实时收集当前数据流的位置数据元组,这些数据元组包括用户/车辆id、时间戳、经纬度等信息。对于每一个元组,通过其与前一个相关元组的经纬度与时间戳的组合,进行合理性分析及判断,来确定当前元组数据的合理性,由此保留正确的位置数据元组。
在本发明实例中,优先将输入数据根据其自身特性进行数据清洗处理,剔除失效及错误数据,使得数据的可用性极大提升。
(2)构建前缀层次树
根据用户的隐私需求及位置数据的特点,对位置数据所在的区域范围进行划分。并使用改进后的geohash算法对在元组数据流s中的元组进行位置数据转换,最后输出为前缀层次树pt。在本发明实施例中,有效的元组泛化算法依赖于前缀层次树的构建。前缀层次树的构建可以用于元组泛化中权重分数的计算。具体步骤包括:
(2-1)计算元组数据流s的位置数据的经纬度范围。
(2-2)根据该经纬度范围,使用geohash算法对元组数据流s所在的路网进行层次网格的划分。
(2-3)使用改进后的geohash算法对元组数据流s的所有元组进行计算。对于每个元组t=<u,p,j>,其中,p表示用户u在时间戳j的经纬度位置坐标。geohash算法生成该元组t经转换后的位置字符串p′。
(2-4)根据划分后的网格构建前缀层次树pt。该前缀树中的每个节点都维护一个键值对pair<str,count>。其中,str表示该网格的地理哈希编码字符,count表示访问者人数的计数。对于每一个转换后的位置数据p′,将前缀层次树pt中节点的键str为p′的计数count自增加1。最后输出结果为该元组数据流s对应的前缀层次树pt。
geohash是一种地址编码算法,将地球视为二维平面并递归分解为较小的子块,其中每个子块在一定的纬度和经度范围内具有相同的编码。结合geohash算法的特点,可以将位置数据进行层次划分,将其转换为不同长度的字符串表示,而且位置所在网格的范围精度与字符串的长度呈正相关。比如,将一个网格均匀分为10个子网格,而每个子网格又在里面进行划分,继续生成10个更小的子网格,以此类推。改进后的geohash算法将其作用范围从地球平面缩减到当前数据集的经纬度范围,从而提高了位置编码转换的精度。而且,在改进后的geohash算法中,树的子节点个数可以根据用户提供的隐私保护级别自适应地调整。
以每个时间段内的传入的轨迹流s作为输入,基于改进的geohash算法将位置数据进行层次网格划分,然后构建并生成前缀层次树pt。树的子节点个数根据用户提供的隐私保护级别自适应地调整。用户的隐私需求分为多个保护级别,级别越高,要求树的子节点个数越多。该树中的任何节点都包含两条信息:该网格的地理哈希编码字符串及其访问者人数。该树清楚地显示了访问每个网格的人数。树的高度取决于收集的样本数据集的大小。按照原geohash算法的定义,此分层树中的每个非叶节点都固定为拥有32个子节点。而在改进后的geohash算法中,树的子节点个数可以根据用户提供的隐私保护级别自适应地调整。如图2(a)所示,假设当前的前缀树pt。在时间戳i,服务器收集来自两个不同用户的两个位置元组。这两个元组是((39.8209,116.4404),1547817620,u1)和((39.7802,116.4627),1547817620,u2)。算法将这些转换以不同的精度协调到不同的字符串。例如,可以将第一个元组中的位置转换为“j”,“jr”和“jru”。因此,带有这些字符串的节点的数量都增加了一个。同理,第二个元组被转换为“j”、“jg”和“jgh”。经过这些插入操作之后,更新后的前缀树如图2(b)所示。
(3)元组采样
将自适应隐私预算εa、元组数据流s、给定时间窗口长度t为输入。将元组数据流s划分为k段。根据隐私预算值εa对元组数据进行采样。
隐私预算ε根据用户隐私需求设置。用户的隐私需求分多个保护级别,级别越高,隐私预算ε越小。隐私预算ε可分为元组采样和泛化隐私预算εa、元组合并隐私预算εb。其中,保证两者之和为ε的前提下,若用户隐私级别越高,设定εb<εa,若用户隐私级别越低,设定εb≥εa。
在本发明实施例中,有效的元组泛化算法依赖于有效的元组采样策略,这可以通过缩减数据集大小,提高实时运算处理的高效性。具体步骤包括:
(3-1)以时间窗口长度t为单位,将用户位置数据流s划分为k个连续的分段<d1,...,di,...,dk>,1≤i≤k。
其中,时间窗口长度t根据用户隐私需求设置。用户的隐私需求分多个保护级别,级别越高,时间窗口长度t越小,使得段数越多,每个段分配到的隐私预算越小。比如,总时间长度为10min的数据,当t=4min时,分为<0-4>、<4-8>、<8-10>这3段。
(3-2)根据元组采样和泛化隐私预算εa,计算每个分段di的元组采样隐私预算εa,i,将其分配给对应分段。
其中,s为界限常数,满足
di的下标i越大,表示距当前时间越远。由其距当前时间的远近,自适应地计算欲添加的隐私预算εa,i值。
(3-3)根据每段数据流di分配到的隐私预算εa,i值,计算其对应的采样概率pi。
(3-4)根据采样概率pi分别对每个分段数据流di中的位置数据进行采样,整理采样后得到的流数据元组,并生成采样后的元组数据集<d′1,...,d′i,...,d′k>,1≤i≤k。
采样后得到的d′i目对于原始数据流分段di来说,元组数量大大减少,极大保证了实时运算处理的高效性。
(4)元组泛化
将采样后的元组数据集<d′1,...,d′i,...,d′k>,1≤i≤k,以及前缀层次树pt作为输入。使用差分隐私指数机制的思想,将这些坐标元组泛化到它们各自对应的划分网格内。这些操作在模糊了每个元组的位置信息的同时,也确保了数据可用性。结合计算出来的权重分数,将采样后得到的各个元组泛化到其周围的候选划分网格内。最后的输出数据为元组数据集
在本发明实施例中,元组泛化步骤通过扰乱和模糊原始位置,在确保数据可用性的同时有效避免了用户位置隐私的泄露,保证了隐私性。具体步骤包括:
(4-1)收集元组数据流s所在路网中的每个位置,组成一个位置域γ。
(4-2)对于每个分段d′i,计算其每一个元组数据x′iz对于在位置域γ的每个网格rj的权重分数,其中,1≤i≤k,1≤z≤|d′i|,1≤j≤|γ|。
其中,rj表示位置域γ第j个网格,pt[rj]表示网格节点rj所包含的访问者人数信息,δdisijz表示网格节点rj与d′i中的元组x′iz所在的网格节点之间的距离。通常,a是小于1的常数,该常数由位置域的面积确定。a值越小,权重因距离而减小的速率就越慢。接下来,元组泛化步骤使用差分隐私的指数机制按照概率选择一个候选网格,然后将该网格作为我们期望的新位置并返回。
(4-3)使用差分隐私的指数机制,结合元组x′iz与周围网格的权重分数q(x′iz,rj),生成相应的泛化概率pijz。并根据该概率将x′iz泛化到对应的网格rj中。
对所有k个段的元组数据进行计算及网格划分后,完成对位置数据集的元组泛化操作。最后的输出结果为元组数据集
(5)元组合并
以隐私预算εb及位置数据集
在本发明实施例中,元组合并步骤作用于各个单位时间段内,对处于同一划分网格内的多个元组的位置点进行位置合并,从而保证了生成轨迹数据的隐私性。具体步骤包括:
(5-1)跟据隐私预算εb的值确定对应的元组合并级别level。该合并级别level代表元组要被合并到的网格的父节点的深度。
(5-2)定义k个空集合lri,1≤i≤k。对于在每段位置数据集
(5-3)设child(pij)为pij的子节点集合;
(5-4)给定的隐私预算εb,以及键值对字典
(5-5)将每段位置数据集
图3(a)、图3(b)、图3(c)分别表示了在porto、t-drive、nyc三个不同数据集中的轨迹数据隐私保护发布示例。通过各种轨迹路径直观地比较了原始轨迹和合成轨迹之间的偏离程度。算法将时间窗口大小t设置为5分钟,并在三个数据集中分别选择两个典型轨迹作为示例。经过差分隐私预算处理后。可以看到,随着隐私预算的增加,合成轨迹与原始轨迹的形状更加一致。由于如果隐私预算ε变大,则添加到每个位置的噪声变小,因此原始轨迹与合成轨迹之间的偏差减小。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!