一种实现有效特征抽取的深度子空间聚类方法及系统与流程
本发明涉及机器学习技术领域,尤其涉及一种实现有效特征抽取的深度子空间聚类方法
背景技术:
对于许多实际应用程序来说,聚类是无监督学习中一个重要的任务。
在众多的模型中,子空间学习是最常用的方法之一。在现有技术中,子空间聚类方法包括:低秩表示聚类等传统方法、基于自编码器的深度子空间聚类及自我监督机制。
但是,低秩表示聚类等传统方法特征提取和聚类是分开进行的,首先这样会使模型得不到最优解,其次两个步骤之间没有相互促进的过程。基于自编码器的深度子空间聚类在一定程度上解决了这个问题,但是模型仍然不能保证学习到的中间隐藏层表示对聚类任务是有用的;基于自我监督机制的模型会出现标签不一致的情况,不利于特征学习。
技术实现要素:
本发明的目的在于提供一种实现有效特征抽取的深度子空间聚类方法,能够抽取到对于聚类有用的特征,降低噪声数据的影响,提高聚类效果,也避免了标签不对齐的问题。
为了解决上述技术问题,本发明实施例提供一种实现有效特征抽取的深度子空间聚类方法,包括:
利用自编码器抽取输入样本特征表达,并通过最小化输入与输出样本的误差获得自编码器损失函数;
利用自表达模块实现子空间学习,获取自表达模块损失函数;
通过监督特征学习模块从潜在表示中提取与聚类任务相关的特征,得到监督特征学习模块损失函数;所述监督特征学习模块损失函数为通过kl散度进行优化得到的;其中,通过定义一个均匀分布的标签先验分布函数以及平衡标签类别的分布使监督特征学习模块损失函数通过kl散度进行优化;
根据所述自编码器损失函数、自表达模块损失函数以及监督特征学习模块损失函数得到优化目标函数;
根据得到的相关系数矩阵计算出亲和矩阵,并利用所述亲和矩阵进行谱聚类。
进一步地,所述自编码器损失函数用于优化网络参数,所述自编码器损失函数由以下公式确定:
其中,x={x1,x2,x3,...,xn}为输入样本,
进一步地,所述利用自表达模块实现子空间学习,获取自表达模块损失函数,具体的,
自表达模块通过其他样本的线性组合表示每个样本,实现子空间学习,所述子空间学习由以下公式确定:
z=zc
其中,c∈rn×n代表相关系数矩阵,所述c具有块对角的性质,z={z1,z2,z3,...,zn}代表每个输入样本对应的中间向量表达。
所述自表达模块损失函数由以下公式确定:
λ是用于平衡不同损失项权重的参数,||·||p表示一个合适的矩阵范数。
进一步地,所述监督特征学习模块损失函数由以下公式确定:
,pik为预测标分布中第i个样本属于第k个类的概率qik为目标分布中第i个样本属于第k个类的概率。
进一步地,所述优化目标函数由以下公式确定:
minl1+γ1l2+γ2l3s.t.diag(c)=0
其中,l1为自编码器损失函数,l2为自表达模块损失函数,l3为监督特征学习模块损失函数,γ1,γ2为正则化参数。
进一步地,所述亲和矩阵由以下公式确定:
第二方面,本发明实施例提供一种实现有效特征抽取的深度子空间聚类系统,其特征在于,包括:
自编码器损失函数获取模块,用于利用自编码器抽取输入样本特征表达,并通过最小化输入与输出样本的误差获得自编码器损失函数;
自表达模块损失函数获取模块,用于利用自表达模块实现子空间学习,获取自表达模块损失函数;
监督特征学习模块损失函数获取模块,用于通过监督特征学习模块从潜在表示中提取与聚类任务相关的特征,得到监督特征学习模块损失函数;所述监督特征学习模块损失函数为通过kl散度进行优化得到的;其中,通过定义一个均匀分布的标签先验分布函数以及平衡标签类别的分布使监督特征学习模块损失函数通过kl散度进行优化;
优化目标函数获取模块,用于根据所述自编码器损失函数、自表达模块损失函数以及监督特征学习模块损失函数得到优化目标函数;
聚类模块,用于根据得到的相关系数矩阵计算出亲和矩阵,并利用所述亲和矩阵进行谱聚类。
进一步地,所述优化目标函数由以下公式确定:
minl1+γ1l2+γ2l3s.t.diag(c)=0
其中,l1为自编码器损失函数,l2为自表达模块损失函数,l3为监督特征学习模块损失函数,γ1,γ2为正则化参数,c∈rn×n代表相关系数矩阵,所述c具有块对角的性质。
进一步地,所述亲和矩阵由以下公式确定:
进一步地,所述自编码器损失函数由以下公式确定:
其中,x={x1,x2,x3,...,xn}为输入样本,
所述自表达模块损失函数由以下公式确定:
,z={z1,z2,z3,...,zn}为每个输入样本对应的中间向量表达,λ是用于平衡不同损失项权重的参数,||·||p为一个合适的矩阵范数
所述监督特征学习模块损失函数由以下公式确定:
pik为预测标分布中第i个样本属于第k个类的概率qik为目标分布中第i个样本属于第k个类的概率。
本发明实施例具有如下有益效果:
(1)本发明实施例加入的监督特征学习模块能够抽取到对于聚类有用的特征,降低噪声数据的影响,提高聚类效果,也避免了标签不对齐的问题。
(2)本发明实施例通过自编码器、自表达模块实现子空间学习以及基于最小化kl散度的监督特征学习模块把特征学习以及用于聚类的相关系数矩阵学习整合到一个网络中,从而获得深度特征提取和子空间学习特征的优点,包括:能够获取数据的非线性特征,以及对于噪音不敏感的优点。
附图说明
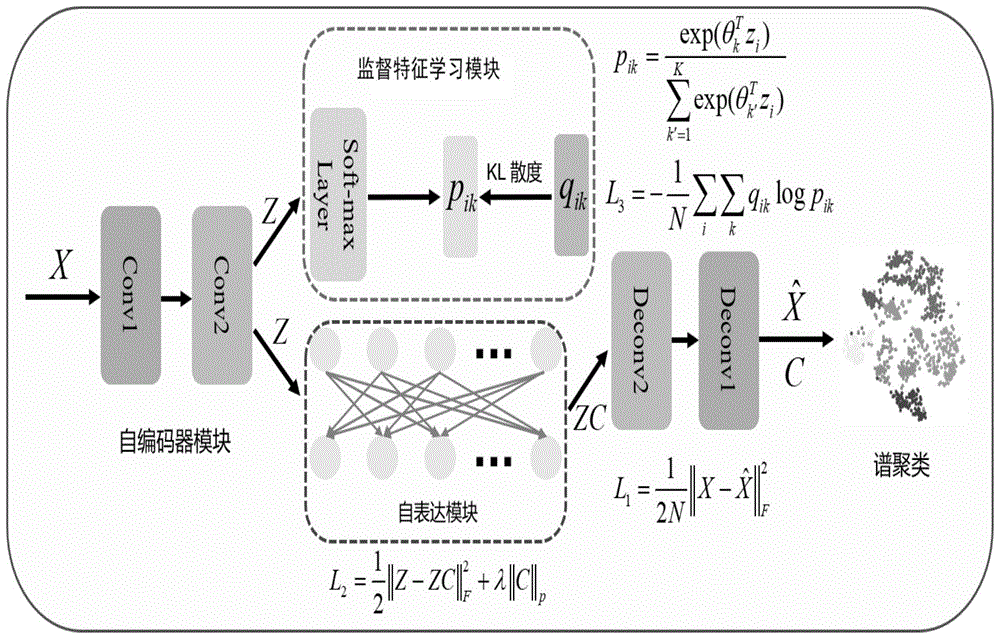
图1为本发明实施例提供的实现有效特征抽取的深度子空间聚类方法的整个网络的总体框架图
图2为本发明实施例提供的实现有效特征抽取的深度子空间聚类方法与现有的11种常用的聚类算法的聚类效果进行比对的示意图
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
术语“包括”和“包含”指示所描述特征、整体、步骤、操作、元素和/或组件的存在,但并不排除一个或多个其它特征、整体、步骤、操作、元素、组件和/或其集合的存在或添加。
术语“和/或”是指相关联列出的项中的一个或多个的任何组合以及所有可能组合,并且包括这些组合。
请参阅图1,本发明实施例提供一种实现有效特征抽取的深度子空间聚类方法,包括:
s1、利用自编码器抽取输入样本特征表达,并通过最小化输入与输出样本的误差获得自编码器损失函数。
在本发明实施例中,利用自编码器抽取输入样本的特征表达,
其中,x={x1,x2,x3,...,xn}代表输入样本,z={z1,z2,z3,...,zn}代表每个输入样本对应的中间向量表达,θe是编码器的参数,θd是解码器的参数,
然后通过最小化输入与输出样本的误差来优化网络参数;其中,以最小化输入样本与输出样本的最小误差作为自编码器损失函数,利用自编码器损失函数来优化网络参数,所述自编码器损失函数由以下公式确定:
其中,x={x1,x2,x3,...,xn}为输入样本,
s2、利用自表达模块实现子空间学习,获取自表达模块损失函数。
在本发明实施例中,自表达模块通过其他样本的线性组合表示每个样本,实现子空间学习,所述子空间学习由以下公式确定:
z=zc(4)
其中,c∈rn×n代表相关系数矩阵,所述c具有块对角的性质,z={z1,z2,z3,...,zn}代表每个输入样本对应的中间向量表达。
此外,为了得到的c具有块对角的性质,需要在c上添加一定的正则项,因此,嵌入网络中的自表达模块损失函数可定义成:
λ为用于平衡不同损失项权重的参数,||·||p表示一个合适的矩阵范数,例如l1,||·||*,||·||f。
在此,需要说明的是,z和zc不是完全相等,因为所述z=zc只在理想情况下才完全相等,而实际上几乎不会相等,在本发明实施例中,需要最小化z和zc之间的误差才能使自表达模块损失函数具备优化性能。
s3、通过监督特征学习模块从潜在表示中提取与聚类任务相关的特征,得到监督特征学习模块损失函数;所述监督特征学习模块损失函数为通过kl散度进行优化得到的;其中,通过定义一个均匀分布的标签先验分布函数以及平衡标签类别的分布使监督特征学习模块损失函数通过kl散度进行优化。
在本发明实施例中,在聚类中,通过引入监督特征学习模块来从潜在表示中提取与聚类任务相关的特征,具体的,首先利用softmax函数来表示预测分布中第i个样本属于第k个类的概率。
其中,k为聚类样本的类别数,j为第j个神经元,pik表示预测分布中第i个样本属于第k个类的概率,θ=[θ1,...,θk]为softmax函数的参数,zi为第i个样本的中间向量表示,
在本发明实施例中,通过利用一个辅助目标变量q不断优化每一轮产生的pik,并通过定义一个均匀分布的标签先验分布函数u以及平衡标签类别的分布f,以使监督特征学习模块可通过kl散度进行优化,
其中,p为网络输出的样本分布,
通过交替学习的方法对目标函数lkl进行优化,得到:
最后,将监督特征学习模块加入到网络中,得到监督特征学习模块损失函数,所述监督特征学习模块损失函数由以下公式确定:
s4、根据所述自编码器损失函数、自表达模块损失函数以及监督特征学习模块损失函数得到优化目标函数。
所述优化目标函数由以下公式确定:
minl1+γ1l2+γ2l3s.t.diag(c)=0(10)
其中,γ1,γ2是正则化参数,c∈rn×n代表相关系数矩,所述c具有块对角的性质。
由于无监督子空间聚类的数据集较小,对网络进行从头开始训练是困难的。因此,我们首先在没有自表达层和监督特征学习模块的情况下,对网络进行了预训练。也就是说,我们在这一阶段优化损失函数。然后用预训练权重初始化自编码器的参数,这时再训练整个网络,通过最小化总损失迭代更新参数。
s5、根据得到的相关系数矩阵计算出亲和矩阵。
所述亲和矩阵由以下公式确定:
其中,c∈rn×n代表相关系数矩阵。
s6、利用所述亲和矩阵进行谱聚类,得到聚类结果。
为了验证本发明实施例的有效性,我们在五个数据集上进行实验表1数据集描述
在上述五个数据集上进行实验,并与现有的11种常用的聚类算法进行对比,请参阅图2,实验结果充分说明了本发明实施例(图中的ours)的三种指标基本上都达到了当前最优(黑色加粗的代表聚类效果最好结果)。
基于上述实施例,本发明实施例具有如下有益效果:
(1)本发明实施例加入的监督特征学习模块能够抽取到对于聚类有用的特征,降低噪声数据的影响,提高聚类效果,也避免了标签不对齐的问题。
(2)本发明实施例通过自编码器、自表达模块实现子空间学习以及基于最小化kl散度的监督特征学习模块把特征学习以及用于聚类的相关系数矩阵学习整合到一个网络中,从而获得深度特征提取和子空间学习特征的优点,包括:能够获取数据的非线性特征,以及对于噪音不敏感的优点。
(3)本发明实施例的端到端框架联合优化了特征学习和数据自表达的过程。
(4)本发明实施例通过监督特征学习模块来最小化概率聚类分布和目标变量之间的相对熵,进一步保证了学习特征的可靠性。
本发明实施例还提供一种实现有效特征抽取的深度子空间聚类系统,包括:
自编码器损失函数获取模块,用于利用自编码器抽取输入样本特征表达,并通过最小化输入与输出样本的误差获得自编码器损失函数。
在本发明实施例中,利用自编码器抽取输入样本的特征表达,
其中,x={x1,x2,x3,...,xn}代表输入样本,z={z1,z2,z3,...,zn}代表每个输入样本对应的中间向量表达,θe是编码器的参数,θd是解码器的参数,
然后通过最小化输入与输出样本的误差来优化网络参数;其中,以最小化输入样本与输出样本的最小误差作为自编码器损失函数,利用自编码器损失函数来优化网络参数,所述自编码器损失函数由以下公式确定:
其中,x={x1,x2,x3,...,xn}为输入样本,
自表达模块损失函数获取模块,用于利用自表达模块实现子空间学习,获取自表达模块损失函数。
在本发明实施例中,自表达模块通过其他样本的线性组合表示每个样本,实现子空间学习,所述子空间学习由以下公式确定:
z=zc(4)
其中,c∈rn×n代表相关系数矩阵,所述c具有块对角的性质,z={z1,z2,z3,...,zn}代表每个输入样本对应的中间向量表达。
此外,为了得到的c具有块对角的性质,需要在c上添加一定的正则项,因此,嵌入网络中的自表达模块损失函数可定义成:
λ为用于平衡不同损失项权重的参数,||·||p表示一个合适的矩阵范数,例如l1,||·||*,||·||f。
在此,需要说明的是,z和zc不是完全相等,因为所述z=zc只在理想情况下才完全相等,而实际上几乎不会相等,在本发明实施例中,需要最小化z和zc之间的误差才能使自表达模块损失函数具备优化性能。
监督特征学习模块损失函数获取模块,用于通过监督特征学习模块从潜在表示中提取与聚类任务相关的特征,得到监督特征学习模块损失函数;所述监督特征学习模块损失函数为通过kl散度进行优化得到的;其中,通过定义一个均匀分布的标签先验分布函数以及平衡标签类别的分布使监督特征学习模块损失函数通过kl散度进行优化。
在本发明实施例中,在聚类中,通过引入监督特征学习模块来从潜在表示中提取与聚类任务相关的特征,具体的,首先利用softmax函数来表示预测分布中第i个样本属于第k个类的概率。
其中,pik表示预测分布中第i个样本属于第k个类的概率,θ=[θ1,...,θk]为softmax函数的参数,zi为第i个样本的中间向量表示。
在本发明实施例中,通过利用一个辅助目标变量q不断优化每一轮产生的pik,并通过定义一个均匀分布的标签先验分布函数u以及平衡标签类别的分布f,以使监督特征学习模块可通过kl散度进行优化。
其中,
通过交替学习的方法对目标函数lkl进行优化,得到:
最后,将监督特征学习模块加入到网络中,得到监督特征学习模块损失函数,所述监督特征学习模块损失函数由以下公式确定:
优化目标函数获取模块,用于根据所述自编码器损失函数、自表达模块损失函数以及监督特征学习模块损失函数得到优化目标函数。
所述优化目标函数由以下公式确定:
minl1+γ1l2+γ2l3s.t.diag(c)=0(10)
其中,γ1,γ2是正则化参数,c∈rn×n代表相关系数矩,所述c具有块对角的性质。
由于无监督子空间聚类的数据集较小,对网络进行从头开始训练是困难的。因此,我们首先在没有自表达层和监督特征学习模块的情况下,对网络进行了预训练。也就是说,我们在这一阶段优化损失函数。然后用预训练权重初始化自编码器的参数,这时再训练整个网络,通过最小化总损失迭代更新参数。
聚类模块,用于根据得到的相关系数矩阵计算出亲和矩阵,并利用所述亲和矩阵进行谱聚类,得到聚类结果。
所述亲和矩阵由以下公式确定:
其中,c∈rn×n代表相关系数矩阵,所述c具有块对角的性质。
为了验证本发明实施例的有效性,我们在五个数据集上进行实验表1数据集描述
在上述五个数据集上进行实验,并与现有的11种常用的聚类算法进行对比,请参阅图2,实验结果充分说明了本发明实施例(图中的ours)的三种指标基本上都达到了当前最优(黑色加粗的代表最好结果)。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!