基于随机森林算法训练子宫内膜异位囊肿破裂数据的方法与流程
本发明涉及数据处理技术领域,尤其涉及一种基于随机森林算法来训练子宫内膜异位囊肿破裂数据的方法。
背景技术:
在高速发展的互联网时代,机器学习的出现和应用正深刻改变着医疗行业。在此之前,医学数据的收集分析是一件充满挑战和困难的事。但如今,机器学习通过对数据的分析与处理,能够准确清晰的实现设定的方案并交付结果。
目前,国内外针对子宫内膜异位囊肿破裂数据的相关研究还比较少。数据预测采用的分类模型大多为knn算法、神经网络算法、贝叶斯算法等等,但这些算法的精确度不是很理想,无法处理连续、离散和混合的大数据集,尤其是在缺失数据较多的情况下,准确度会随着数据缺失而快速降低。
因此,亟需一种行之有效的算法对子宫内膜异位囊肿破裂数据进行分析,可以处理连续、离散和混合的大数据集,能够克服数据缺少较多的情况下,准确度快速降低的问题。
技术实现要素:
本发明实施例所要解决的技术问题在于,提供一种基于随机森林算法来训练子宫内膜异位囊肿破裂数据的方法,可以处理连续、离散和混合的子宫内膜异位囊肿破裂数据集,能够克服数据缺少较多的情况下,准确度快速降低的问题。
为了解决上述技术问题,本发明实施例提供了一种基于随机森林算法来训练子宫内膜异位囊肿破裂数据的方法,包括以下步骤:
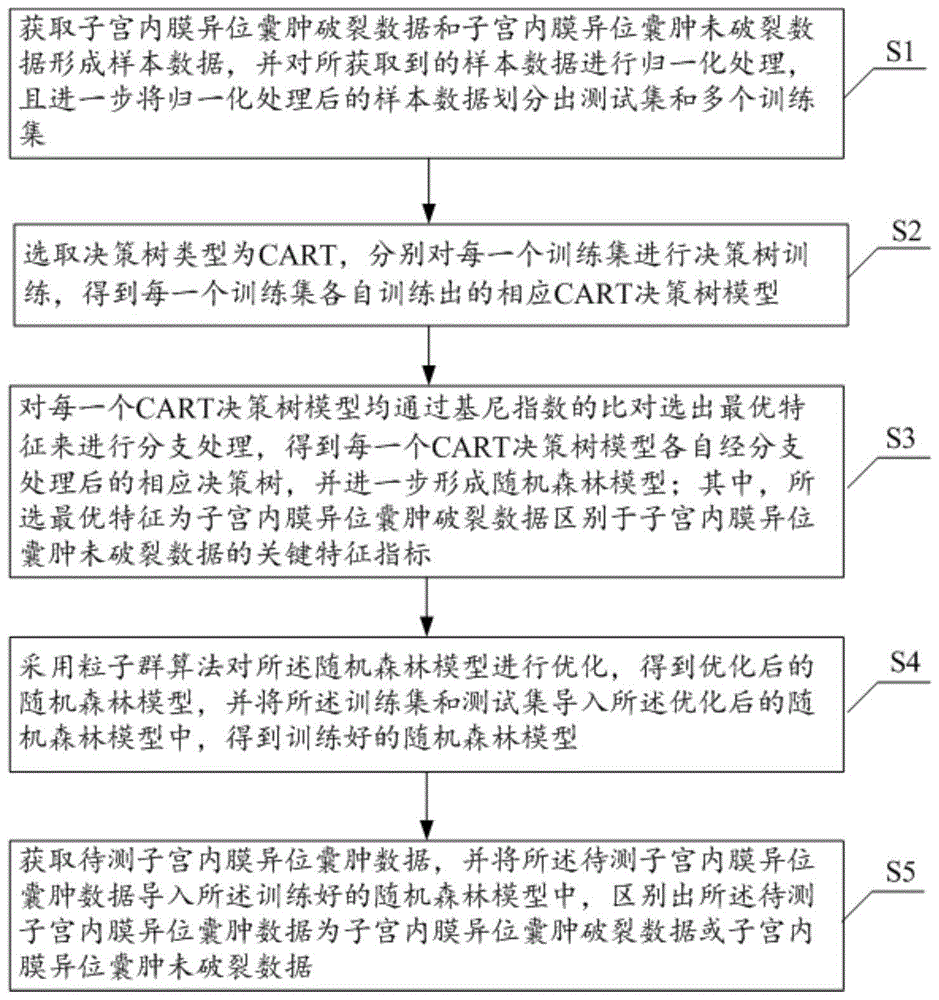
步骤s1、获取子宫内膜异位囊肿破裂数据和子宫内膜异位囊肿未破裂数据形成样本数据,并对所获取到的样本数据进行归一化处理,且进一步将归一化处理后的样本数据划分出测试集和多个训练集;
步骤s2、选取决策树类型为cart分别对每一个训练集进行决策树训练,得到每一个训练集各自训练出的相应cart决策树模型;
步骤s3、对每一个cart决策树模型均通过基尼指数的比对选出最优特征来进行分支处理,得到每一个cart决策树模型各自经分支处理后的相应决策树,并进一步形成随机森林模型;其中,所选最优特征为子宫内膜异位囊肿破裂数据区别于子宫内膜异位囊肿未破裂数据的关键特征指标;
步骤s4、采用粒子群算法对所述随机森林模型进行优化,得到优化后的随机森林模型,并将所述训练集和测试集导入所述优化后的随机森林模型中,得到训练好的随机森林模型;
步骤s5、获取待测子宫内膜异位囊肿数据,并将所述待测子宫内膜异位囊肿数据导入所述训练好的随机森林模型中,区别出所述待测子宫内膜异位囊肿数据为子宫内膜异位囊肿破裂数据或子宫内膜异位囊肿未破裂数据。
其中,在所述步骤s1中,测试集和多个训练集的具体形成步骤为:
以所述归一化处理后的样本数据总量的25%随机组合为一份数据集作为测试集,剩下的75%作为训练数据,且进一步从训练数据中有放回随机采样选出n个样本为一份,占数据总量的50%来形成n个不相同的训练集。
其中,在所述步骤s3中,所述对每一个cart决策树模型均通过基尼指数的比对选出最优特征来进行分支处理的具体步骤包括:
在同一个cart决策树模型中,汇总出对应训练集中训练数据的所有特征,并计算出每个特征的基尼指数评分,且选出最小基尼指数评分的特征为最优特征后,将所选的最优特征及其对应的切分点作为根节点衍生的两个子节点,进一步将剩余的特征分配到上述两个子节点中,实现分支处理;其中,在分支过程中采取预剪枝处理,若当该树杈上的样本小于所设定的参数,则决策树就不再继续生长。
其中,特征xj在某一个cart决策树模型中的基尼指数评分通过公式
其中,特征xj在随机森林模型的基尼指数评分通过公式
其中,在所述步骤s4中,所述采用粒子群算法对所述随机森林模型进行优化的具体步骤包括:
第一步、对粒子群算法进行部分调整,使其适用于离散值的算法优化;
第二步、设置粒子群算法的代价函数或者称之为适应度函数:
prob=fitness(max_depth,n_estimators,min_samples_split)
适应度函数的值等于上述随机森林算法得到的准确率;
第三步:设置最大迭代次数max_iter、目标函数的自变量个数pn、粒子的最大速度x、可行解的搜索空间、学习因子c1和c2、以及种群大小,并进一步构造一个随机群体:
第四步、对于群体中的每一个粒子,将粒子位置代入代价函数求出适应值,寻找个体极值为每个粒子找到的最优解。再根据这些个体极值最优解寻找到一个全局值最优解,最后将本次全局最优解与历史全局最优解比较,如果本次全局最优解结果较好则进行更新,以此寻找种群所经历过的最好位置gbest(g1,g2,g3.....gd);
第五步、更新速度和位置的公式;
第六步、重复执行第四步和第五步。当达到设定迭代次数或者代数之间的差值满足最小界限时终止迭代,将最佳参数代入随机森林算法,优化后的随机森林模型。
实施本发明实施例,具有如下有益效果:
本发明基于随机森林算法来训练子宫内膜异位囊肿破裂数据,可以处理连续、离散和混合的子宫内膜异位囊肿破裂数据集,能够克服数据缺少较多的情况下,准确度快速降低的问题。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,根据这些附图获得其他的附图仍属于本发明的范畴。
图1为本发明实施例提出的一种基于随机森林算法来训练子宫内膜异位囊肿破裂数据的方法的流程图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述。
如图1所示,为本发明实施例中,提出的一种基于随机森林算法来训练子宫内膜异位囊肿破裂数据的方法,包括以下步骤:
步骤s1、获取子宫内膜异位囊肿破裂数据和子宫内膜异位囊肿未破裂数据形成样本数据,并对所获取到的样本数据进行归一化处理,且进一步将归一化处理后的样本数据划分出测试集和多个训练集;
具体过程为,首先收集子宫内膜异位囊肿破裂和子宫内膜异位囊肿未破裂的患者医学数据,上述数据来源于手术过程中发现卵巢子宫内膜异位囊肿破裂的患者。
其次,将子宫内膜异位囊肿破裂数据和子宫内膜异位囊肿未破裂数据形成样本数据,并对所获取到的样本数据进行归一化处理,归一化公式如下:
xk=(xk-xmin)/(xmax-xmin)
最后,将归一化处理后的样本数据划分出测试集和多个训练集;例如,使用bootstraping方法,以归一化处理后的样本数据总量的25%随机组合为一份数据集作为测试集,剩下的75%作为训练数据,且进一步从训练数据中有放回随机采样选出n个样本为一份,占数据总量的50%来形成n个不相同的训练集;其中,n为大于1的正整数。
步骤s2、选取决策树类型为cart分别对每一个训练集进行决策树训练,得到每一个训练集各自训练出的相应cart决策树模型;
具体过程为,决策树类型有id3、c4.5、c5.0和cart这四种,在模型建立过程中,选择的是cart决策树,分别对每一个训练集进行决策树训练,得到每一个训练集各自训练出的相应cart决策树模型,即得到n个cart决策树模型。
步骤s3、对每一个cart决策树模型均通过基尼指数的比对选出最优特征来进行分支处理,得到每一个cart决策树模型各自经分支处理后的相应决策树,并进一步形成随机森林模型;其中,所选最优特征为子宫内膜异位囊肿破裂数据区别于子宫内膜异位囊肿未破裂数据的关键特征指标;
具体过程为,首先,在同一个cart决策树模型中,汇总出对应训练集中训练数据的所有特征,并计算出每个特征的基尼指数评分,且选出最小基尼指数评分的特征为最优特征后,将所选的最优特征及其对应的切分点作为根节点衍生的两个子节点,进一步将剩余的特征分配到上述两个子节点中,实现分支处理来得到每一个cart决策树模型各自经分支处理后的相应决策树;
最后,基于基尼指数,将所有决策树形成随机森林模型。
以单个cart决策树模型为例,将训练数据的所有特征的数量记为m,每次决策树分支时就可根据基尼指数选择特征进行分支,基尼指数越低,代表特征的相关性越大,因此通过基尼指数的比对可以选出最优特征。
用vim来表示特征重要性评分(即基尼指数评分),用gi来表示基尼指数,假设现在有m个特征,目标是将每个特征xj的基尼指数评分
此时,特征xj在某一个cart决策树模型中的基尼指数评分的计算公式如下:
其中,
如果特征xj在cart决策树模型i中出现的节点包含在集合m中,且随机森林总共n棵决策树,则特征xj在随机森林模型的基尼指数评分的计算公式如下:
其中,
最后,还可以对上述的基尼指数评分进行归一化处理,具体如下:
从基尼指数评分中,可以证实ca-125和ca19-9的特征重要性系数占比大,因此选取ca-125和ca19-9作为子宫内膜异位囊肿破裂数据分析的关键指标。
应当说明的是,每棵树都已知这样分裂下去,知道该节点的所有训练样例都属于同一类,在决策树的分裂过程中不需要后剪枝。
步骤s4、采用粒子群算法对所述随机森林模型进行优化,得到优化后的随机森林模型,并将所述训练集和测试集导入所述优化后的随机森林模型中,得到训练好的随机森林模型;
具体过程为,首先采用粒子群算法对随机森林模型进行优化,具体如下:
第一步、对粒子群算法进行部分调整,使其适用于离散值的算法优化;
第二步、设置粒子群算法的代价函数或者称之为适应度函数:
prob=fitness(max_depth,n_estimators,min_samples_split)
第三步:设置最大迭代次数max_iter、目标函数的自变量个数pn、粒子的最大速度x、可行解的搜索空间、学习因子c1和c2、以及种群大小;并构造一个随机群体。
第四步、对于群体中的每一个粒子,将粒子位置代入代价函数求出适应值,寻找个体极值为每个粒子找到的最优解。再根据这些个体极值最优解寻找到一个全局值最优解,最后将本次全局最优解与历史全局最优解比较,如果本次全局最优解结果较好则进行更新,以此寻找种群所经历过的最好位置gbest(g1,g2,g3.....gd);
第五步、更新速度和位置的公式;
第六步、重复执行第四步和第五步。当达到设定迭代次数或者代数之间的差值满足最小界限时终止迭代,将最佳参数代入随机森林算法,优化后的随机森林模型。
其次,将步骤s1中的训练集和测试集导入优化后的随机森林模型中,就能得到训练好的随机森林模型。
步骤s5、获取待测子宫内膜异位囊肿数据,并将所述待测子宫内膜异位囊肿数据导入所述训练好的随机森林模型中,区别出所述待测子宫内膜异位囊肿数据为子宫内膜异位囊肿破裂数据或子宫内膜异位囊肿未破裂数据。
具体过程为,获取待测子宫内膜异位囊肿数据并导入所述训练好的随机森林模型中,输出的类别若是最优特征(如ca-125和ca19-9),则说明待测子宫内膜异位囊肿数据为子宫内膜异位囊肿破裂数据;反之,则认为待测子宫内膜异位囊肿数据为子宫内膜异位囊肿未破裂数据。
实施本发明实施例,具有如下有益效果:
本发明基于随机森林算法来训练子宫内膜异位囊肿破裂数据,可以处理连续、离散和混合的子宫内膜异位囊肿破裂数据集,能够克服数据缺少较多的情况下,准确度快速降低的问题。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,所述的程序可以存储于一计算机可读取存储介质中,所述的存储介质,如rom/ram、磁盘、光盘等。
以上所揭露的仅为本发明一种较佳实施例而已,当然不能以此来限定本发明之权利范围,因此依本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。
- 还没有人留言评论。精彩留言会获得点赞!