一种复杂地形遥感土壤水分产品降尺度方法与流程
本发明属于遥感土壤水分数据分析领域,具体涉及提高土壤水分数据的空间分辨率。
背景技术:
目前的遥感土壤水分产品的空间分辨率较低(25-50km),存在很大的空间异质性,大的混合像元影响数据精确度,在地形复杂的区域,只有通过遥感观测才能实现土壤水分的大范围有效的动态监测,现有的复杂地形区域的降尺度技术缺乏对地形的考虑,而且影响遥感土壤水分(sm)的因素是多维复杂非线性的,现有的线性模型无法有效模拟,使得降尺度反演精度不高,并且某一模型只适用于某一小范围区域,难以有效扩展。因此,急需探索如何采用空间降尺度技术来提高土壤水分数据的空间分辨率,使地面细节清晰呈现。
技术实现要素:
本发明目的:针对现在复杂地形区域土壤水分产品降尺度技术精度较低的问题,本发明将多种变量,纳入地形因子,耦合光学遥感和微波遥感建模,采用随机森林算法对遥感土壤水分产品进行降尺度反演,构建土壤水分与影响变量间的多维复杂非线性关系模型,得到精细空间尺度的土壤水分数据,实现多源遥感优势互补,取长补短,提高反演精度。
本发明详细技术方案如下:
一种复杂地形遥感土壤水分产品降尺度方法,包括以下步骤:
步骤1、获取多种产品数据,纳入地形因子;
步骤2:多种产品数据预处理,包括:
步骤2.1:利用软件将研究区内包含的多个分片存储的文件拼接至同一个栅格文件;
步骤2.2:将所有数据的投影坐标系及数据的坐标系统一;
步骤2.3:从所述产品数据中生成坡度、坡向,增加至随机森林算法的特征种类中;
步骤2.4:对所有数据裁剪,得到研究区内部的数据,通过高分辨率数据对低分辨率数据进行研究区剪裁,使其只保留研究区范围内的数据;
步骤2.5:进行独热变量设置,所述独热变量设置为:特征中同时存在连续型数据与分类型的数据,当数据为分类型的数据时,将分类型的数据做独热编码,修改为哑变量;
步骤2.6:时空匹配,通过快速的空间匹配方法进行时空匹配,所述时空匹配包括:经纬度都保留相同位数,数据表排列规律为:纬度递减,相同纬度时,经度递增;使用双层比较;第一层比较纬度数据,在纬度数据匹配成功的情况下进入第二层,比较经度数据,如果经纬度数据均相等,则完成一个数据点的匹配;
步骤3:采用距离最短法选择最优数据,并将距离,经度,纬度,是否当天以及上午/下午作为新的特征,进行随机森林建模,在数据集中随机抽取样本以保证用于训练的样本抽取的随机性,数据划分完毕后,输入训练数据到随机森林回归模块完成机器学习,从而得到一个最优模型;
步骤4:应用所述步骤3中得到的最优模型,把所有自变量数据预处理后输入模型进行预测,得到降尺度数据。
进一步的所述步骤1、获取所述多种产品数据包括dem数据、modislyc产品数据、modisndvi、evi和lst产品数据以及smapsm产品数据。
进一步的所述步骤2:多种产品数据预处理,包括:当所述产品数据为dem数据时,利用软件将研究区内包含的多个分片存储的文件拼接至同一个栅格文件;将空间高分辨率的数字高程dem采用最近邻域法重采样至1km,将dem数据的投影坐标系和smapsm数据的坐标系(wgs84ease-grid2.0)统一,从dem数据生成坡度、坡向,增加至随机森林算法的特征种类中;当产品数据为modislyc产品数据时:利用软件将研究区内包含的多个分片存储的文件拼接至同一个栅格文件;将modislyc产品数据采用最近邻域法重采样至1km,将modislyc产品数据的投影坐标系和smapsm数据的坐标系(wgs84ease-grid2.0)统一;当产品数据为modisndvi、evi和lst产品数据时:利用软件将研究区内包含的多个分片存储的文件拼接至同一个栅格文件;modisndvi、evi和lst产品数据坐标系和smapsm数据的坐标系(wgs84ease-grid2.0)统一,将坐标系统一后的dem数据、modislyc产品数据、modisndvi、evi和lst产品数据通过软件进行裁剪,对于smap数据的裁剪,首先利用软件剪裁出研究区范围内的dem数据,所述dem数据的分辨率重采样为1km,且在研究区范围内没有数据缺失,smap土壤水分数据的分辨率为36km,smap数据在经纬度精确到0.01时,不出现重复位置,利用1km分辨率的dem数据所对应的经纬度信息,与smap数据土壤水分数据所对应的经纬度信息对比,完成裁剪。
进一步的在所述裁剪过程中假设矩形为原始的smap全球范围数据,六边形部分为dem部分所覆盖的研究区域,将smap数据的经纬度与所述产品数据的经纬度相比较,如果一组smap经纬度在所述dem中也存在,则说明这组经纬度所对应的地点在研究区覆盖范围内,保留此点,否则淘汰。
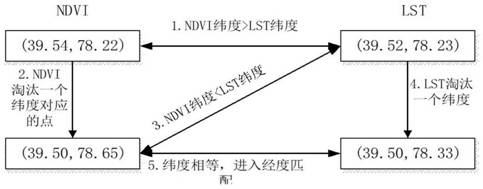
进一步的所述步骤2.6:时空匹配进一步包括:经纬度都保留相同位数且保留到小数点后面两位;当时数据为ndvi与lst数据时,首先判断两组数据的纬度是否相等,若不相等,则纬度大的一方向下移动一位,即淘汰这一个纬度所对应的所有点,纬度小的一方保持不变,直到双方纬度相等,再进入双方的经度匹配;与纬度匹配相反,由于经度是按递增的顺序排列,所以当两组数据经度不相等时,则经度小的一方向下移动一位,即淘汰这个经度所对应的点,经度大的一方保持不变,直到双方经度相等。
进一步的所述步骤3:进行随机森林建模时,设置因变量为土壤水分,并在模型变量中纳入lst、lct、ndvi、evi、dem,坡度,坡向,经度,纬度,匹配点距离,是否当天,上午/下午变量。
进一步的所述步骤3进一步包括:在数据集中随机抽取样本,训练集样本数量与测试集样本数量之比为7:3,数据划分完毕后,输入训练数据到随机森林回归模块完成机器学习,通过调整参数使得测试得分与袋外测试得分同时达到高于第一预设值水平且二者差异小于第二预设值时,得到一个最优模型。
进一步的所述第一预设值为0.7,第二预设值为0.05。
进一步的所述步骤2.1:进一步包括:利用arcgis软件将研究区内包含的多个分片存储的文件拼接至同一个栅格文件。
进一步的所述步骤4得到降尺度数据为1km的降尺度数据。
与现有技术相比本发明的有点在于:
(1)相对于基于tvdi的土壤湿度降尺方法,本发明的降尺度因子更加丰富中纳入了多种因子包括归一化植被指数ndvi、增强植被指数evi、地表温度lst、数据高程dem、匹配点距离distance、坡度slope、坡向aspect、地表覆盖类型lct、上下午、是否当天,并利用随机森林算法能够对多变量非线性拟合,且训练速度快,模型泛化能力强,防止过拟合的优势,采用随机森林算法建模,有利于综合多种土壤水分影响变量,提高降尺度反演精度。
(2)本发明在降尺度因子中纳入了地形因子数据高程dem、坡度slope、坡向aspect,有利于提高该方法在复杂地形区域的适用性。
(3)最短距离法进行经纬度匹配,经纬度保留相同位数,固定数据表排列规律并使用双层比较的地理信息数据空间匹配方法快速,精度高无错误匹配,能扩展应用于地理信息大数据预处理的空间匹配。
(4)在降尺度因子中将最短距离法的匹配点距离,有利于降低匹配点距离差异带来的影响;同时纳入是否当天,上\下午变量,同样有利于降低这些变量差异带来的影响。
(5)采用高分辨率数据对低分辨率数据进行研究区剪裁的方法快速,完整,不会遗漏有效数据。
附图说明
图1为本发明复杂地形遥感土壤水分产品降尺度流程图。
图2为研究区dem数据裁剪smap示意图。
图3纬度匹配流程图。
图4经度匹配流程图。
具体实施方式
下面将结合本发明实施例及附图,对本申请进行清楚、完整地描述。
结合图1本发明复杂地形遥感土壤水分产品降尺度流程图,具体的该方法利用arcgis软件将研究区内包含的多个分片存储的文件拼接至同一个栅格文件,将其中空间高分辨率的数字高程dem和陆表覆盖类型lct采用最近邻域法重采样至1km,为了保证空间对准,将所有数据的投影坐标系和smap(soilmoistureactiveandpassive)sm数据的坐标系wgs84ease-grid2.0统一,从dem数据生成坡度、坡向,增加至随机森林算法的特征种类中,对所有数据裁剪,得到研究区内部的数据,并进行独热变量设置,其中,研究区剪裁、独热变量设置、时空匹配方法具体描述如下:
其中,研究区剪裁法是由于smap数据下载后是全球范围内的土壤水分数据,为减少无效运算量,需要对smap进行裁剪,使其只保留研究区范围内的数据;本发明首先利用arcgis剪裁出研究区范围内的dem,由于dem中的高程数据分辨率已重采样为1km,且在研究区范围内没有数据缺失;而smap土壤水分数据的分辨率为36km,所以smap数据在经纬度精确到0.01时,不会出现重复位置;故利用1km分辨率的dem数据所对应的经纬度信息,与smap数据土壤水分数据所对应的经纬度信息对比,完成裁剪;裁剪思路如图2所示,假设矩形为原始的smap全球范围数据,六边形部分为dem部分所覆盖的研究区域,将smap数据的经纬度与dem的经纬度相比较,如果一组smap经纬度在dem中也存在,则说明这组经纬度所对应的地点在研究区覆盖范围内,保留此点,否则淘汰。
其中,独热变量设置是完成特征与标签之间的一一对应后,特征中同时存在连续型数据(ndvi、evi、lst、dem、distance、slope和aspect)与分类型的数据(lct、上下午、是否当天),对于分类型的数据,存在不可计算的特性,为避免在机器学习时计算机将认为连续变量,需将其做“独热编码”,修改为哑变量。
其中,时空匹配方法是实施例中使用的modis数据一共包含ndvi、evi、lst(地表温度)和lct(地表覆盖类型)这四种,由于产品种类不同,经纬度无法完全重合,因此本发明采用最短距离法进行空间匹配。由于研究区范围广,采用逐点计算距离的空间匹配方法消耗的时间过长而影响整个方法的可行性,如果将来要采用长时间序列的数据消耗的时间更长,因此本发明提出一套快速的空间匹配方法,该方法主要包括:
(1)经纬度都保留相同位数,本发明保留到小数点后面两位。
(2)数据表排列规律为:纬度递减,相同纬度时,经度递增。
(3)使用双层比较。
详细说来,数据匹配的主要思路如图3,4所示,在1km分辨率的情况下,只需保留十进制度的小数点后两位即可,由于数据排列规律为:纬度递减,相同纬度时,经度递增,所以可以使用双层比较,第一层比较纬度数据,在纬度数据匹配成功的情况下进入第二层,比较经度数据,如果经纬度数据均相等,则完成一个数据点的匹配,以ndvi与lst数据对准为例,首先判断两组数据的纬度是否相等,若不相等,则纬度大的一方向下移动一位,即淘汰这一个纬度所对应的所有点,纬度小的一方保持不变,直到双方纬度相等,再进入双方的经度匹配。
与纬度匹配相反,由于经度是按递增的顺序排列,所以当两组数据经度不相等时,则经度小的一方向下移动一位,即淘汰这个经度所对应的点,经度大的一方保持不变,直到双方经度相等,如图4所示,此时双方经纬度均已相等,完成了一组数据的匹配。则此组数据的经纬度、ndvi、lst数值记入新csv文件,ndvi、lst均下移一位,进行下一组数据的匹配。
模型生成及降尺度的过程:由于标签(smap数据)分辨率为36*36km,而特征数据的分辨率为1*1km,因此对于同一个标签,有36*36组特征数据与之匹配,需要在多组数据中选择最优,为解决以上问题,采用距离最短法选择,并将距离作为一种新的特征,smap每天有上午和下午两次数据,所以在特征中加入“上下午”这一特征,为区别18日和19日smap数据,新增一个特征——“是否当天”,19日是实验日,单日smap不能完全覆盖研究区,用相邻时间且云覆盖少18日数据来填补。
经过上述处理,训练样本都已准备齐全,便可进行随机森林建模,为保证用于训练的样本抽取的随机性,在数据集中随机抽取样本,训练集样本数量与测试集样本数量之比为7:3,数据划分完毕后,输入训练数据到随机森林回归模块完成机器学习,调整参数使得测试得分与袋外测试得分同时达到一个较高水平且二者差异较小时,得到一个最优模型,应用此模型,把所有自变量数据预处理后输入模型进行预测,得到1km降尺度数据。
裁剪验证数据中国气象局陆面数据同化系统cldasv2.0和全球陆面数据同化系统gldassm到研究区,并与1km降尺度结果进行时空匹配,从空间分布、差异分析、站点验证等角度验证,验证结果表明1km降尺度结果相对于原始数据在精确度方面的提高。
青藏高原1km降尺度结果与原始smap、cldas、gldas的空间分布在整体上呈现一致性,验证了降尺度结果的准确性以及方法的可行性,相对于原始smap数据,降尺度结果更精细,局地差异表现更明显,因此它能够获得精细尺度的土壤水分值。
采用2017.10.19日下午18:00一些气象台站的土壤水分观测数据对青藏高原1km降尺度结果、smap、cldas和gldas进行对比验证,将4个数据集与站点数据进行时空匹配得到它们在对应位置土壤水分值,降尺度结果与站点的一致性优于原始smap及cldas、gldas,降尺度结果与站点的差值最小,这得益于高分辨率导致的空间匹配精度提高,以及在降尺度算法中综合考虑了植被、地形、海拔、地表温度、经纬度等诸多因素使得降尺度数据的准确度提高,证明了该降尺度方法的有效性。
综上所述,本发明与传统的识算法相比,本方法考虑的自变量较多,包括了地形的影响,精度较高,突破复杂地形区域土壤水分数据稀缺且精度较差的局面;将特征与标签匹配点之间的距离作为降尺度模型的一个特征变量,有利于降低匹配点距离差异带来的影响;同时纳入是否当天,上\下午变量,同样有利于降低这些变量差异带来的影响,采用高分辨率数据对低分辨率数据进行研究区剪裁的方法快速,完整,不会遗漏有效数据;经纬度保留相同位数,固定数据表排列规律并使用双层比较的地理信息数据空间匹配方法快速,精度高无错误匹配,能应用于地理信息大数据预处理的空间匹配。本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的范围。
- 还没有人留言评论。精彩留言会获得点赞!