一种卷积神经网络的压缩方法及其实现电路与流程
本发明涉及深度学习加速器设计领域,具体涉及一种卷积神经网络的压缩方法及其实现电路。
背景技术:
随着卷积神经网络在目标检测及识别的快速发展,大幅改善图像识别检测精确度成为可能。然而,为了实现更好的目标检测识别性能,卷积神经网络在不断地加深,带来则是计算量的急速增长和模型大小的膨胀。因此,卷积神经网络需要并行设备来对其进行加速,节省训练时间或者满足实时目标检测的要求,例如大功耗的gpu设备等。为了实现深度卷积神经网络在低功耗的嵌入式设备上的部署,基于fpga的卷积神经网络加速设计已经成为学术界和工业界研究的重点。
膨胀的深度神经网络模型对存储有着很高要求,为了节省存储空间,神经网络模型压缩算法在近几年不断被提出。神经网络剪枝,权重量化等压缩算法由于其对精确度较小的影响,被广泛使用在神经网络模型压缩中。然而大量研究表明,由于剪枝算法造成的模型不规则性,导致神经网络并行计算效率低,对其处理速度造成了严重的影响。因此,需要一种适合硬件加速的压缩策略,使卷积神经网络在模型尺寸被大幅压缩的情况下,仍然保持高性能的处理速度,同时满足实时性检测和小模型尺寸的要求。
技术实现要素:
发明目的:大规模神经网络模型尺寸庞大,存储资源消耗巨大,难以在嵌入式设备上实现。然而压缩后的神经网络由于其模型的不规则性,在并行加速架构上计算效率低,计算速度慢,为了克服这个缺陷,本发明提出一种卷积神经网络的压缩方法及其实现电路。
技术方案:本发明提出的技术方案如下:
一种卷积神经网络的压缩方法,包括依次执行的步骤(1)至(5):
(1)将卷积神经网络分为非剪枝层和剪枝层;
(2)对整个卷积神经网络进行剪枝,然后重新训练,得到一个高精度的稀疏网络;
(3)移除非剪枝层的权重掩膜;
(4)对剪枝层进行渐进量化,具体步骤为:
1)随机选取剪枝层中的一组权重进行量化;
2)重新训练卷积神经网络,更新剪枝层中其他组的权重和非剪枝层的权重,重复训练过程,直至卷积神经网络的精度满足预设要求;
3)随机选取剪枝层中的下一组权重进行量化,然后返回步骤3);
4)重复执行步骤2)至3),直至整个剪枝层量化完成;
(5)保持剪枝层权重不变,对非剪枝层进行线性量化,得到压缩后的卷积神经网络。
进一步的,所述步骤(2)中得到一个高精度的稀疏网络的具体步骤为:
设置剪枝阈值,将卷积神经网络中小于剪枝阈值的权重进行剪枝,然后重训练卷积神经网络,更新没有被剪切的权重,重复训练-剪枝过程,直至卷积神经网络中所有权重都小于剪枝阈值,至此,得到一个高精度的稀疏网络。
本发明还提出一种卷积神经网络的实现电路,用于实现所述的压缩方法压缩后的卷积神经网络,所述电路通过fpga实现,包括:分布式非剪枝层硬件处理电路和基于移位累加器的剪枝层硬件处理电路,分布式非剪枝层硬件处理电路用于实现所述卷积神经网络的非剪枝层功能,剪枝层硬件处理电路用于实现所述卷积神经网络的剪枝层功能;分布式非剪枝层硬件处理电路和剪枝层硬件处理电路以流水线的方式共同实现卷积神经网络:分布式非剪枝层硬件处理电路处理当前输入数据的同时,剪枝层硬件处理电路处理上一次非剪枝层输出的数据。
进一步的,所述分布式非剪枝层硬件处理电路包括:特征图缓存模块、n个特征图存储模块、m个复合卷积处理单元、m个权重存储模块、数据转换模块;
特征图缓存模块用于缓存输入的特征图,并将特征图送入特征图存储模块;
每个特征图存储模块包括一个特征图存储单元和一个特征图缓存单元;每个特征图存储模块对应地存储特征图中的一个q行的数据块,并按照行顺序输出给对应的特征图缓存单元,特征图缓存单将数据按行存储并按列输出;在每个时钟,n个特征图存储模块向m个复合卷积处理单元分别输出n路特征图数据;
m个权重存储模块一一对应地连接m个复合卷积处理单元,即每个复合卷积处理单元由一个独立的权重存储模块提供权重;每个权重存储模块包括一个权重存储单元和一个权重缓存单元;每个权重存储单元用于存储相应的复合卷积处理单元的权重,并在上一层计算时,将权重输入到相应的权重缓存单元,权重缓存单元在本层计算开始前,将权重送入相应复合卷积处理单元;
每个复合卷积处理单元根据相应权重存储模块提供的权重,以n个不同的卷积核分别处理n个特征图存储模块输出的n路特征图数据;对卷积后的特征图数据累加后缓存,并与下一个时钟的n路特征图数据卷积结果相加,直至本次对特征图的处理结束;累加后的数据通过激活函数处理后,将处理结果的最后一列数据置零,若数据还需要池化,则进行池化后输出,若不需要池化,则直接输出数据。
进一步的,所述基于移位累加器的剪枝层硬件处理电路包括解码器和若干移位累加器,每个移位累加器还配置有一个激活数据缓存模块、一个判断器、一个权重目录缓存模块、一个权重缓存模块,每个移位累加器负载一个权重核;
解码器将压缩后的剪枝层权重解码为±2n形式的权重和权重目录,并输入到对应的移位累加器对应的权重缓存模块和权重目录缓存模块,权重目录即为权重在权重核中的位置;
当所有移位累加器所需负载的权重被解码完,激活数据按顺序被同时输入到每个判断器中,每个判断器根据其对应的权重目录判断该激活数据是否被该移位累加器需要;如果需要,则将激活数据存储于对应激活数据缓存模块中,等待参与计算;
每输入指定数据的激活数据后,激活数据被送入移位累加器参与计算,同时后面的数据被输入激活数据缓存模块,以构成流水线的处理模式。
有益效果:与现有技术相比,本发明具有以下优势:
本发明能够在保证神经网络模型压缩率的情况下对神经网络进行加速。整个方案包括面向硬件加速的卷积神经网络压缩策略和高性能的混合并行硬件架构两个部分。本发明目前能在单片xilinxvcu118上实现主流卷积神经网络vgg-16部署,并能以27.5倍的模型压缩比达到83.0fps的处理速度,且保证在imagenet2012测试数据集上0.5%以内的top-5精度损失。
附图说明
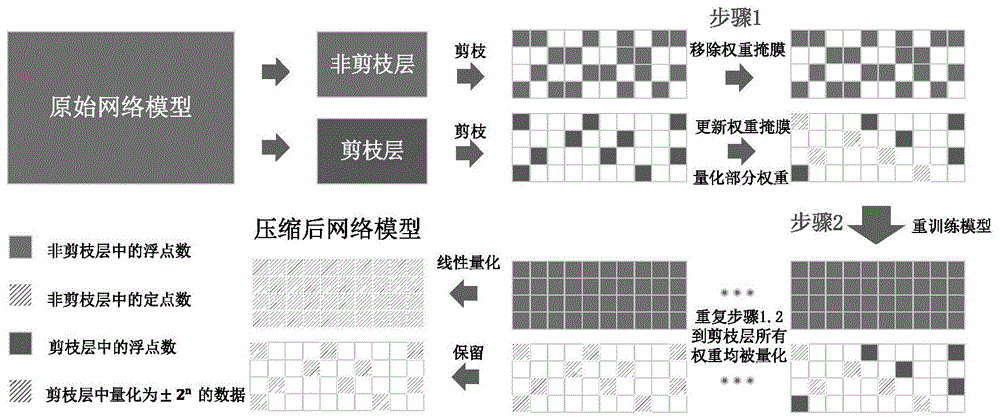
图1为实施例涉及的面向硬件加速的卷积神经网络压缩方法;
图2为实施例涉及的分布式非剪枝层硬件处理电路结构图;
图3为实施例涉及的复合卷积处理单元结构图;
图4为实施例涉及的卷积处理单元结构图;
图5为实施例涉及的f×f乒乓缓存(fppb)结构图;
图6为实施例涉及的基于fir滤波器的高效卷积层数据流示意图;
图7为实施例涉及的基于移位累加器的剪枝层硬件处理电路结构图;
图8为硬件算法协同优化方法的原理图。
具体实施方式
下面结合附图和具体实施例对本发明作更进一步的说明。
在卷积神经网络中,不同的层拥有不同的特点。前面的层需要处理大尺寸的特征图,所需计算量大,但是却拥有较少的权重;后面的层处理的特征图尺寸因为池化层而被减小,所需计算量小,但是拥有大量的权重。
本实施例基于卷积神经网络的特征,提出一种压缩方法,具体步骤为:
(1)将卷积神经网络分为非剪枝层和剪枝层;
(2)设置剪枝阈值,将卷积神经网络中小于剪枝阈值的权重进行剪枝,然后重训练卷积神经网络,更新没有被剪切的权重,重复训练一剪枝过程,直至卷积神经网络中所有权重都小于剪枝阈值,至此,得到一个高精度的稀疏网络;
(3)移除非剪枝层的权重掩膜;
(4)对剪枝层进行渐进量化,具体步骤为:
1)随机选取剪枝层中的一组权重进行量化;
2)重新训练卷积神经网络,更新剪枝层中其他组的权重和非剪枝层的权重,重复训练过程,直至卷积神经网络的精度满足预设要求;
3)随机选取剪枝层中的下一组权重进行量化,然后返回步骤3);
4)重复执行步骤2)至3),直至整个剪枝层量化完成;
(5)保持剪枝层权重不变,对非剪枝层进行线性量化,得到压缩后的卷积神经网络。
在上述压缩方法中,卷积神经网络被划分为前后两个部分:前半部分为非剪枝层,后半部分为剪枝层。非剪枝层模型结构规则,能高效的被并行硬件架构加速。由于其位于网络的前半部分,所拥有权重数量少,即使未被剪枝,对整体模型压缩带来的影响甚微。剪枝层模型结构复杂且不规则,该种模型在计算上会带来一定的困难并影响计算速度。但是由于其位于网络的后半部分,其带来的模型压缩比是巨大的,并且由于后半部分所需求计算量小,其所带来的速度的影响也会被减小。因此,该压缩策略能在保证高处理性能的情况下对模型进行大幅压缩。
此外,本实施例还针对此压缩方法,提出一种实现电路,所述电路通过fpga实现,包括:分布式非剪枝层硬件处理电路和基于移位累加器的剪枝层硬件处理电路,分布式非剪枝层硬件处理电路用于实现所述卷积神经网络的非剪枝层功能,剪枝层硬件处理电路用于实现所述卷积神经网络的剪枝层功能;分布式非剪枝层硬件处理电路和剪枝层硬件处理电路以流水线的方式共同实现卷积神经网络:分布式非剪枝层硬件处理电路处理当前输入数据的同时,剪枝层硬件处理电路处理上一次非剪枝层输出的数据。
所述分布式非剪枝层硬件处理电路包括:特征图缓存模块、n个特征图存储模块、m个复合卷积处理单元、m个权重存储模块、数据转换模块;特征图缓存模块用于缓存输入的特征图,并将特征图送入特征图存储模块;
每个特征图存储模块包括一个特征图存储单元和一个特征图缓存单元;每个特征图存储模块对应地存储特征图中的一个q行的数据块,并按照行顺序输出给对应的特征图缓存单元,特征图缓存单将数据按行存储并按列输出;在每个时钟,n个特征图存储模块向m个复合卷积处理单元分别输出n路特征图数据;
m个权重存储模块一一对应地连接m个复合卷积处理单元,即每个复合卷积处理单元由一个独立的权重存储模块提供权重;每个权重存储模块包括一个权重存储单元和一个权重缓存单元;每个权重存储单元用于存储相应的复合卷积处理单元的权重,并在上一层计算时,将权重输入到相应的权重缓存单元,权重缓存单元在本层计算开始前,将权重送入相应复合卷积处理单元;
每个复合卷积处理单元根据相应权重存储模块提供的权重,以n个不同的卷积核分别处理n个特征图存储模块输出的n路特征图数据;对卷积后的特征图数据累加后缓存,并与下一个时钟的n路特征图数据卷积结果相加,直至本次对特征图的处理结束;累加后的数据通过激活函数处理后,将处理结果的最后一列数据置零,若数据还需要池化,则进行池化后输出,若不需要池化,则直接输出数据。
所述基于移位累加器的剪枝层硬件处理电路包括解码器和若干移位累加器,每个移位累加器还配置有一个激活数据缓存模块、一个判断器、一个权重目录缓存模块、一个权重缓存模块,每个移位累加器负载一个权重核;
解码器将压缩后的剪枝层权重解码为±2n形式的权重和权重目录,并输入到对应的移位累加器对应的权重缓存模块和权重目录缓存模块,权重目录即为权重在权重核中的位置;
当所有移位累加器所需负载的权重被解码完,激活数据按顺序被同时输入到每个判断器中,每个判断器根据其对应的权重目录判断该激活数据是否被该移位累加器需要;如果需要,则将激活数据存储于对应激活数据缓存模块中,等待参与计算;
每输入指定数据的激活数据后,激活数据被送入移位累加器参与计算,同时后面的数据被输入激活数据缓存模块,以构成流水线的处理模式。
下面以vgg-16为例,进一步阐述本发明的具体实现过程。
如图1所示,vgg-16的卷积层初始被设为非剪枝层,全连接层被设为剪枝层。将整个神经网络剪枝并重新训练,得到高精度的稀疏网络模型(可直接使用已训练好的稀疏网络模型)。对全连接层的权重进行分组,选取其中一组量化为±2n的形式,然后重训练对其他组和卷积层的权重进行更新,当精确度达到需求后再重复以上步骤直至所有全连接层权重被量化完成。完成上述步骤后对卷积层权重进行均匀量化获得最终的压缩模型,压缩后的卷积神经网络模型分为稀疏的全连接层和规则的卷积层两个部分,分别被送入不同的处理单元去处理图片。最后得到的模型的数据类型为:卷积层中权重为8-bit的定点数;全连接层中权重数据位宽为9-bit,其中5-bit作为剪枝后权重的索引,4-bit作为数据存储(其中1-bit表示移位的方向,3-bit表示移位的距离)。特征图数据量化为16-bit的定点数。
本发明的处理架构由分布式非剪枝层硬件处理电路和基于移位累加器的剪枝层硬件处理电路两个部分组成,它们以流水线的方式共同处理卷积神经网络:分布式非剪枝层硬件处理电路处理数据的同时,剪枝层硬件电路处理上一次的非剪枝层输出的数据。
分布式非剪枝层硬件处理电路如图2所示,以架构尺寸pm=32和pn=32为例。
对于处理一个224×225×64(宽×高×通道数)大小的特征图(最后一列由于上层计算已被填充零),卷积核尺寸为3×3×64×64。权重存储ram(wr)在上一层计算时,将权重输入到权重缓存(wb)。在该层计算开始前,wb将权重送入每个复合卷积处理单元,等待与输入特征图的计算。每个wr对应一个wb,每个wb对应一个复合卷积处理单元。32个并行的特征图存储ram(fmr)输出32个通道的输入特征图整合数据,每个整合数据包含3个按行顺序排列的特征图数据。输出的整合数据将被输入到32个f×f乒乓缓存(fppb),每个fppb对应一个fmr。32个fppb一个时钟输出32个通道的特征图数据(每个通道3个按列并行的特征图数据)到每个复合卷积处理单元,复合卷积单元每次处理32个通道的输入特征图数据。每个复合卷积处理单元接收相同的特征图数据,但是以不同的权重进行处理。因此,32个复合卷积处理单元并行输出32个通道的输出特征图数据,输出特征图数据按行排列。32个复合卷积处理单元输出的32个通道的特征图数据将被输入数据转换模块。数据转换模块将接收的三个时钟的串行数据整合变为并行,输出到特征图缓存模块。特征图缓存模块将在fmr中的特征图不再需要被处理的时候,输出特征图数据进fmr等待下一层的计算。下面对上述过程中的模块做进一步的详细说明:
如图3所示,复合卷积处理单元中有32个卷积处理单元,每次并行处理32个不同通道的特征图,并将其输出累加。每次32个通道的特征图累加后的数据被送入缓存,并和下次32个通道的特征图数据相加,直至所有的通道的特征图被累加完毕。累加后的数据经过激活函数后,其中最后一列数据被置零,之后被送入池化模块,可选择是否对特征图进行池化,最后输出数据。
如图4所示,卷积处理单元由3个3抽头的fir滤波器a,b,c串联组成,滤波器a,b和b,c之间的连接处被插入选择器以控制b和c是接收外部数据还是上级fir滤波器输出数据。该卷积处理单元可选择在两种模式下运行:(1)对于尺寸小于3×3的卷积核,该卷积处理单元工作在并行模式:mux1选择第二行特征图数据x1,mux2选择0,mux3选择第三行特征图数据x2,mux4选择0,mux5选择三输入加法器的输出数据,mux6选择mux5的输出数据作为模块输出y。特别地,对于1×1的卷积核,mux6选择位拼接后的输出数据作为模块输出。(2)对于尺寸大于3×3的卷积核,该卷积处理单元工作在串行模式:mux1,mux2,mux3和mux4选择上一级fir滤波器输出数据,mux5选择二输入加法器输出数据,mux6选择mux5输出数据作为模块输出。
fmr中每个3个16-bit的特征图数据按行整合为一个位宽为48-bit(等于按行排列的三个特征图数据)的数据,位深由卷积过程中最大的特征图决定(在vgg16中为ceil(224×225×64/3/16)),基于fir滤波器的高效卷积层数据流如图6所示。
如图5所示,fppb中有两个缓存块,每个缓存块可容纳一个3×3的矩阵。接收数据时,一个整合特征图数据刚好可填充缓存块中的一行。等到一个缓存块被填满,这个缓存块将按列输出数据,每个时钟输出一列3个特征图数据;同时,另一个缓存块接收输入的整合数据。两个缓存块如此交替的轮流接收和输出数据。
wr中权重数据位宽为72-bit(等于9个按顺序排列的权重数据),位深由模型大小决定。
wb在上一次卷积计算时被写入权重数据,当要进行该次卷积计算时,权重被输入至复合卷积单元进行计算。
剪枝层硬件处理电路如图7所示,以移位累加器数目为64和每个移位累加器中移位器数目为1为例。
解码器将存储于ram中的压缩权重解码为4-bit权重和5-bit权重目录,并输入到对应的移位累加器对应的权重缓存和权重目录缓存。每个移位累加器负载一个权重核(在卷积层中,权重核即为卷积核;在全连接层中,权重核为连接到一个输出神经元的所有权重)。当所有移位累加器所需负载的权重被解码完,激活数据按顺序从ram中被同时输入到每个判断器中,每个判断器根据其对应的权重目录判断该激活数据是否被该移位累加器需要。如果匹配,则将其存储于对应激活数据缓存中,等待参与计算。每输入128个激活数据后,激活数据被送入移位累加器参与计算,同时后面数据被输入缓存,以构成流水线的处理模式。输出数据被激活后暂存于激活数据缓存,直到输入激活数据不再需要,则输出激活数据被载入激活数据ram等待下一次计算。
本实施例另外还提出一种硬件算法协同优化方法,如图8所示,按以下步骤实施:(1)根据上述硬件架构尺寸,对当前压缩模型的处理时间进行评估。(2)若非剪枝层的处理时间小于剪枝层的处理时间,则分配更多资源到剪枝层;若非剪枝层的处理时间大于剪枝层的处理时间,则向前移动分割器指针,减少非剪枝层的数量,增加剪枝层数量。(3)重新根据新的架构尺寸和压缩模型评估计算时间,并再次进行步骤(2),直到非剪枝层和剪枝层处理时间之差的绝对值达到最小,从而使系统性能达到最优。
以上只是对本发明的优选实施方式进行了描述。对该技术领域的普通技术人员来说,根据以上的实施方式可以很容易地联想到其他的有点和变形。因此,本发明并不局限于上述实施方式,其仅仅作为例子对本发明的一种形态进行详细,示范性的说明。在不违背本发明宗旨的范围内,本领域的普通技术人员在本发明的方案内进行通常变化和替换,都应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!