一种基于伸缩卷积神经网络的引导区域密集人群计数方法与流程
本发明涉及伸缩卷积神经网络,引导区域选取,图像分割,人群计数技术领域,具体涉及一种基于伸缩卷积神经网络的引导区域密集人群计数方法。
背景技术:
目前人群计数随着计算机网络的发展在安防和公共安全方面得到广泛的应用,传统基于滑动窗口的检测和通过回归方法计数只适用稀疏场景,而对于密集场景或者遮挡情况严重场景效果很差,所以目前多采用卷积神经网络来预测人群数量,许多基于卷积神经网络的框架结构可以捕获低分辨率的特征,也会有不错的人群统计效果,但是抗干扰能力较差,还有些方法受限于图片局部尺度不一致,人群分布的差异性较大,背景噪声影响严重、整幅图像透视失真,遮挡严重等问题,直接导致难以生成可靠的密度图或生成的人群密度图分辨率质量下降,由此严重影响密集人群计数的准确性和可靠性。
技术实现要素:
本发明针对现有技术的不足,提出一种基于伸缩卷积神经网络的引导区域密集人群计数方法。
具体包括以下步骤:
步骤一、人群计数数据集等级划分
本方法图像熵被定义为随机量的度量,对人群计数数据集中图片进行熵滤波处理,具体方法如下:从人群计数数据集任意选取一张图片,假定选取的图片尺寸大小为m*n,图片记为a,a所对应的直方图是一种离散的频率分布,直方图中每个矩形框的数值描述为相应灰度值的频率,直方图中所有矩形框代表的数值之和为图片中的像素总数量,即h(j):
e为矩形框的个数,j表示为随机变量的概率分布,归一化直方图p(j)表示为:
则图像熵可表示为:
对人群计数数据集中所有图片都进行图像熵运算,统计得到所有的图片的熵值,按熵值对相应的人群计数数据集图片进行排序,由于图像熵值反映图片内部信息的均匀程度,此处根据先验设置图像熵的阈值,对人群计数数据集进行等级划分,收集人群计数数据集中图像熵大于阈值的图片,生成新的密集人群数据集,即分布极其不均匀、遮挡严重、尺度差异较大的区域图片,也是在人群计数数据集中预测误差比较大的场景。
步骤二、引导区域选取
针对步骤一处理后的密集人群数据集,需获取重要区域信息,抑制干扰信息,得到适用于密集人群数据集的引导区域,这里提出一种算法来提取密集人群数据集中引导区域和保留更多的密集人群数据集上下文结构信息,具体方法如下:
2、1特征提取
针对密集人群数据集中每张训练图片,此处图片尺寸为512*512*3,分别依次通过卷积操作和池化模块,首先,将当前的训练图片输入到两个3*3的卷积核中,通道为64,得到512*512*64的特征图,512*512*64的特征图经过池化得到256*256*64的特征图。
然后,将256*256*64的特征图输入到两个3*3的卷积核中,通道为128,得到256*256*128的特征图,256*256*128的特征图经过池化得到128*128*128的特征图,将128*128*128的特征图c0按通道划分为两个128*128*64的特征图c1、c2。
进一步,对于密集人群数据集中512*512*3的训练图片,缩小一倍为256*256*3训练图片,将当前图片输入到三个3*3的卷积核中,通道为64,得到256*256*64的特征图,256*256*64的特征图经过池化得到128*128*64的特征图c3。
最后,c2与c3结合得到一个新的128*128*128的特征图c4,将c0和c4输入到1*1的卷积核中得到特征图o和引导图i。
上述所有卷积核的步距为1,补丁为1;池化的尺寸为2,步距为2。
2、2构造引导规则
使用1*1*1的卷积核对o和i做线性变换得到o1和i1,对o1和i1进行按像素累加结合,再经过relu激活函数,再输入到1*1*1卷积核中做线性变换,最后通过sigmoid激活函数得到关注图g。则ii是对i进行下采样得到的与o相同尺寸的低分辨率特征图,在特征图o中对每个位置h,构造一个半径为r的窗口wh,窗口系数定义分别为:
这里的λ是正则化系数,gi是位置i的关注图权重,这里
ohi=ahili+bh,i∈wh
计算窗口中所有像素点的差异性,公式为:
由于不同位置i涉及多个窗口wh的系数不同,将不同窗口中所有的ohi取平均值得到o′hi,公式如下:
这里的wi是包含位置i所有窗口的集和区域,然后对al和bl进行上采样得到对ah和bh,得出高分辨率的引导密度图
o′=ah*i+bh
将引导密度图进行反卷积操作,得到与密集人群数据集尺寸大小相同密度图的引导区域。
步骤三、调整引导区域尺度一致
针对步骤二中密度图的引导区域进行分割,使其密集人群数据集图片的各部分尺度一致,将密度图的引导区域一级划分为2*2的四块,分别为q1、q2、q3、q4,由于图片远处人头较小,近处较大,再二级划分q1和q2,分别为q11、q12、q13、q14;q21、q22、q23、q24;计算每一块的平均密度,公式为
这里rd表示第d块面积,(d)是第d块的引导像素点数,然后二级分块区域与相应的一级分块区域进行对比,一级分块区域与整张图片进行对比,决定一级分块与二级分块区域放缩程度,放缩系数选取根据分块区域平均密度,然后用每一块乘以相应的系数得到放缩后的每一块引导区域,此时将每一块引导区域拼接,以每一分块级别中尺寸最大的引导区域为基准,若尺寸不一致,则进行补丁操作,获得尺度一致的引导区域密度图,将引导区域密度图和密集人群数据集训练图片进行对应像素点乘,得到新的引导区域人群数据集。
步骤四、伸缩卷积神经网络
在原有的卷积操作上添加了偏移量来适应人头标注带来的误差,每个卷积核的偏移量可以根据当前位置误差自行学习优化,即伸缩卷积核,针对步骤三获取的引导区域人群数据集训练图片,输入到三列伸缩卷积核中,三列卷积核的大小分别为3*3、2个3*3、3个3*3,通道数为256,经过一个过滤器连接,得到特征图s1。
使用伸缩卷积核为1*1,通道为256的卷积对s1进行处理,再输入到三列伸缩卷积核中,三列卷积核的大小分别为3*3、2个3*3、3个3*3,通道数为128,经过一个过滤器连接,得到特征图s2。
使用伸缩卷积核为1*1,通道为128的卷积对s2进行处理,再输入到三列伸缩卷积核中,三列卷积核的大小分别为3*3、2个3*3、3个3*3,通道数为64,经过一个过滤器连接,得到特征图s3。
最后经过一个的伸缩卷积核1*1,通道为1的卷积生成密度图,对生成密度图进行积分求和得到最终的人群数目预测,这里用平均绝对误差(mae)和均方误差(mse)来评估预测性能,具体公式如下:
这里的n1是人群计数数据集测试图片数量,g表示第g张测试数据集图片,zg是地面真实值,
本发明还使用损失函数融合来优化模型,第一种是欧氏距离作为损失函数,也是最常见的一种像素均方误差,公式如下:
这里的n2是引导区域人群数据集图片数量,xk是第k张输入图片,θ是模型的参数,d(xk;θ)是估计的密度图,dk是真实的密度图,该损失函数求和像素的欧几里得距离来测量像素级的估计误差,但是这种损失函数会忽略不同级别的密度对网络训练的影响。
第二种损失函数为自适应分块损失,自适应分块损失可以根据真实的局部人群计数将密度图划分为不均匀的锥形子区域,自适应分块计算出每个局部相对估计损失,然后对其求和得到最终的损失,具体方式如下:
将真实密度图dk划分为2*2的四个一级分块区域,并用bx1表示子区域,1∈{1,2,3,4},如果某个子区域的计数值高于给定的阈值s,则将其划分为2*2的四个二级分块区域,用bx1,x2表示,x2∈{1,2,3,4},将一个区域迭代的划分为2*2的n级分块区域,用bx1,x2…xn表示,xn∈{1,2,3,4},直到所有子区域块计数值都小于阈值s,当所有块分割完成后,会得到一个非均匀非线性的锥形网格,将得到的自适应锥形网格应用于估计的密度图,由此计算出每个子区域的局部损耗,公式如下:
此处
第三种损失是感知损失,加入一个生成图像的高层感知特征图,通过最小化图像的感知差异,生成图像可以在语义上和目标图像上更加相似,感知损失函数公式如下:
这里f(xk;θ)是预测特征,fk是真实特征。最后总的损失函数为
ls=l2+λdl1+λfl3
这里λd和λf是欧式损失和感知损失的权重。
本发明相对于现有技术所具有的效果,本发明有效的提取了人群计数数据集的密集人群区域,提高了图片的抗干扰能力,且对网络模型深度进行了加强,有效的解决了尺度不均匀、遮挡严重等场景,加入了自适应分块损失函数与感知损失、欧式损失融合来优化模型,提高了密度图的分辨率质量,提升密集人群计数的准确性。
附图说明
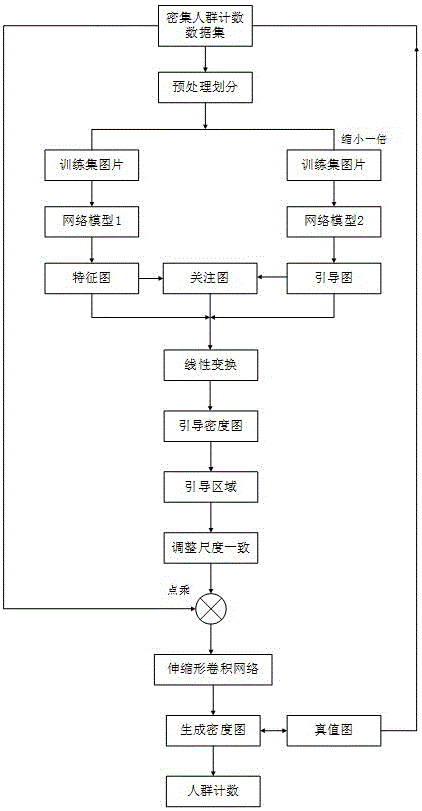
图1为密集人群计数流程图;
图2a和图2b为生成特征图的两种网络模型图;
图3为引导区域提取流程图;
图4为伸缩卷积神经网络模型图。
具体实施方式
以下结合附图对本发明作进一步说明:
如图1所示,本发明包括以下步骤:
步骤一、人群计数数据集等级划分
假设将图像分为背景和前景两个部分,熵是一种统计测量方法,背景与前景的熵值差异较大,用以确定随机数据源中包含的信息数量,图像的信息量越大,对应的熵就越大,信息熵决定图像内部的均匀程度,本方法的熵被定义为随机量的度量,具体方法如下:
给定一个大小为m*n的图像a,对应的直方图是一种离散的频率分布,直方图中每个矩形框的数值描述为相应灰度值的频率,直方图中所有矩形框代表的数值之和为图像中的像素数量,即h(j):
e为矩形框的个数,j表示为随机变量的概率分布,概率分布要满足以下条件:
归一化直方图p(j)表示为:
则熵可表示为:
可以计算得出不同区域的熵值不同,然后再计算整幅图像的熵,最后把不同区域的熵值和整体区域的熵值做一个统计,反映出图像内部的均匀程度,由此得到整幅图像的尺度多样性,上下文信息和遮挡是否严重等信息问题。上述方法对m*n图像进行统计,下面针对具体的人群数据集做处理,根据先验设置图像熵的阈值,对人群计数数据集进行等级划分,收集人群计数数据集中图像熵大于阈值的图片,生成新的密集人群数据集,即分布极其不均匀、遮挡严重、尺度差异较大的区域图片,也是在人群计数数据集中预测误差比较大的场景。
步骤二、引导区域选取
针对上述预处理后的数据集图片,由于密集人群数据集中人群密度等级较高,尺度一致性有较大差别,易受背景噪声的影响,所以这里首先要获取重要区域信息,而抑制干扰信息,得到适用于密集人群计数数据集的引导区域,这里提出一种算法来提取密集人群图片中引导区域以及解决上采样引起的引导区域边界模糊问题,而且本方法可以保存更多的密集人群图片上下文结构信息,同时也能解决遮挡严重和失真严重问题,对最后提高密度图的分辨率有直接影响,具体方法如下:
针对密集人群数据集中每张训练图片,此处图片尺寸为512*512*3,分别依次通过卷积操作和池化模块,首先,将当前的训练图片输入到两个3*3的卷积核中,通道为64,得到512*512*64的特征图,512*512*64的特征图经过池化得到256*256*64的特征图。
然后,将256*256*64的特征图输入到两个3*3的卷积核中,通道为128,得到256*256*128的特征图,256*256*128的特征图经过池化得到128*128*128的特征图,将128*128*128的特征图c0按通道划分为两个128*128*64的特征图c1、c2,见图2a。
进一步,对于密集人群数据集中512*512*3的训练图片,缩小一倍为256*256*3图片,将当前图片输入到三个3*3的卷积核中,通道为64,得到256*256*64的特征图,256*256*64的特征图经过池化得到128*128*64的特征图c3,见图2b。
最后,c2与c3结合得到一个新的128*128*128的特征图c4,将c0和c4输入到1*1的卷积核中得到特征图o和引导图i。
使用1*1*1的卷积核对o和i做线性变换得到o1和i1,对o1和i1进行按像素累加结合,再经过relu激活函数,再输入到1*1*1卷积核中做线性变换,最后通过sigmoid激活函数得到关注图g。则ii是对i进行下采样得到的与o相同尺寸的低分辨率特征图,在特征图o中对每个位置h,构造一个半径为r的窗口wh,窗口系数定义分别为:
这里的λ是正则化系数,gi是位置i的关注图权重,这里
ohi=ahili+bh,i∈wh
计算窗口中所有像素点的差异性,公式为:
由于不同位置i涉及多个窗口wh的系数不同,将不同窗口中所有的ohi取平均值得到o′hi,公式如下:
这里的wi是包含位置i所有窗口的集和区域,然后对ai和bl进行上采样得到对ah和bh,得出高分辨率的引导密度图:
o′=ah*i+bh
将引导密度图进行反卷积操作,得到与密集人群数据集尺寸大小相同密度图的引导区域。
将密度图的引导区域一级划分为2*2的四块,分别为q1、q2、q3、q4,由于图片远处人头较小,近处较大,再二级划分q1和q2,分别为q11、q12、q13、q14;q21、q22、q23、q24;计算每一块的平均密度,公式为:
这里rd表示第d块面积,v(d)是第d块的引导像素点数,然后二级分块区域与相应的一级分块区域进行对比,一级分块区域与整张图片进行对比,决定一级分块与二级分块区域放缩程度,放缩系数选取根据分块区域平均密度,然后用每一块乘以相应的系数得到放缩后的每一块引导区域,此时将每一块引导区域拼接,以每一分块级别中尺寸最大的引导区域为基准,若尺寸不一致,则进行补丁操作,获得尺度一致的引导区域密度图,将引导区域密度图和密集人群数据集训练图片进行对应像素点乘,得到新的引导区域人群数据集,见图3。
步骤三、伸缩卷积神经网络
目前的方法都是直接对上述的特征图进行反卷积操作得到密度图,这样得到的密度图质量会大大降低和带来极大的预测误差,所以这里采用伸缩卷积神经网络进行优化处理,见图4,当前人群计数数据集上人头标注多是由人工自行标定,这样就使得对于每个人头的标注位置都有很大差异,可能在头顶,面部,额头等位置,这样就会因为人头标注的差异性带来很大的误差,为后续的训练带来极大的麻烦,可能导致网络无法继续学习或学习效果较差,直接影响人群数目的统计。原有的卷积神经网络中卷积核是固定不变的,这样就会使得训练不具有自适应性,这里加入伸缩卷积进行处理,在原有的卷积操作上添加了偏移量来适应人头标注带来的误差,每个卷积核的偏移量是可以根据位置误差自行进行学习优化。从而减少初始人为原因带来误差,增大感受野范围,提高最后生成密度图的分辨率,增强密度图预测可信度。具体流程如下:对上述的一致性特征图经过一个三列的伸缩卷积,卷积核的大小分别为3*3、5*5、7*7,通道数都是256个,再经过一个过滤器连接,再经过一个卷积核为1*1,通道为256的卷积,再通过一个三列的伸缩卷积,卷积核的大小分别为3*3、5*5、7*7,通道数都是128个,再经过一个过滤器连接,再经过一个卷积核为1*1,通道为128的卷积,再通过一个三列的伸缩卷积,卷积核的大小分别为3*3、5*5、7*7,通道数都是64个,再经过一个过滤器连接,最后经过一个的卷积核1*1,通道为1的卷积生成密度图。最后对生成密度图进行积分求和得到最终的人群数目预测,这里用平均绝对误差(mae)和均方误差(mse)来评估测试数据的性能,具体公式如下:
这里的n1是测试数据集的图片数量,g表示第g张测试数据集图片,zg是地面真实值,
步骤四、融合损失函数优化模型
本发明使用损失函数融合来优化模型,第一种是欧氏距离作为损失函数,也是最常见的一种像素均方误差,公式如下:
这里的n2是引导区域人群数据集图片数量,xk是第k张输入图片,θ是模型的参数,d(xk;θ)是估计的密度图,dk是真实的密度图,该损失函数求和像素的欧几里得距离来测量像素级的估计误差,但是这种损失函数会忽略不同级别的密度对网络训练的影响。
第二种损失函数为自适应分块损失,自适应分块损失可以根据真实的局部人群计数将密度图划分为不均匀的锥形子区域,自适应分块计算出每个局部相对估计损失,然后对其求和得到最终的损失,具体方式如下:
将真实密度图dk划分为2*2的四个一级分块区域,并用bx1表示子区域,x1∈{1,2,3,4},如果某个子区域的计数值高于给定的阈值s,则将其划分为2*2的四个二级分块区域,用bx1,x2表示,x2∈{1,2,3,4},将一个区域迭代的划分为2*2的n级的分块区域,用bx1,x2…xn表示,xn∈{1,2,3,4},直到所有子区域块计数值都小于阈值s,当所有块分割完成后,会得到一个非均匀非线性的锥形网格,将得到的自适应锥形网格应用于估计的密度图,由此计算出每个子区域的局部损耗,公式如下:
此处
第三种损失是感知损失,加入一个生成图像的高层感知特征图,通过最小化图像的感知差异,生成图像可以在语义上和目标图像上更加相似,感知损失函数公式如下:
这里f(xk;θ)是预测特征,fk是真实特征。最后总的损失函数为
ls=l2+λdl1+λfl3
这里λd和λf是欧式损失和感知损失的权重。
- 还没有人留言评论。精彩留言会获得点赞!