业务化赤潮预警方法及计算机可读存储介质与流程
本发明涉及赤潮预报
技术领域:
,尤其涉及一种业务化赤潮预警方法及计算机可读存储介质。
背景技术:
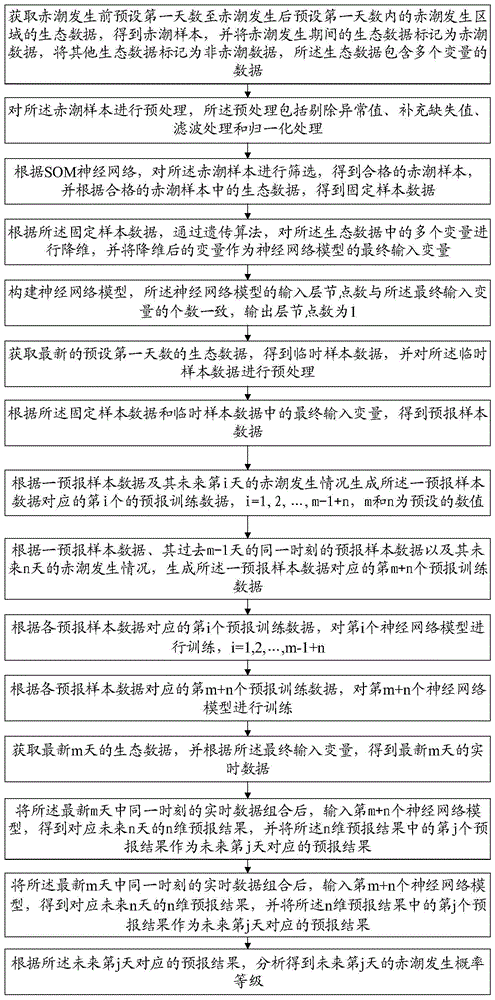
:赤潮是海洋生态系统中的一种异常现象,它是由海藻家族中的赤潮藻在特定环境条件下爆发性地增殖造成的。海藻是一个庞大的家族,除了一些大型海藻外,很多都是非常微小的植物,有的是单细胞植物。根据引发赤潮的生物种类和数量的不同,海水有时也呈现黄、绿、褐色等不同颜色。赤潮不仅给海洋环境、海洋渔业和海水养殖业造成严重危害,对人类健康和生命安全也有一定影响。随着工农业生产的迅速发展、海洋环境污染、流域水体营养化和气候的变暖及少雨等自然变异,赤潮呈现日益严重的趋势,造成的影响也越来越大,已经成为海洋经济发展的一个制约因素。赤潮严重威胁沿岸渔业生产、滨海旅游甚至公众健康,尤以有毒赤潮的危害为甚。面对这一日益突出的海洋生态问题,如何进行有效预测和防灾减灾迫在眉睫。生物与其生活的环境是一个相互依存、相互制约的统一整体。只有当外界环境(海洋)的各种理化条件基本能满足生活于其中的某种赤潮藻生理、生态需求时,该种赤潮藻才有可能形成赤潮。赤潮生物的异常繁殖与周围环境因素有着非常密切的关系。赤潮生物的生长、发育和繁殖都要从环境中索取营养物质和能量。同时,赤潮生物的生长发育和繁殖的各个阶段又都受周围环境条件的制约。因而,在某种程度上,环境因子决定着是否发生赤潮。虽然目前尚不清楚赤潮发生的具体原因,但普遍认为海域的有机污染、富营养化是赤潮发生的物质基础,水温、盐度、do(溶解氧)、cod(化学需氧量)等是赤潮发生的主要条件,气温、降雨、气压是赤潮发生的诱发条件。众多的赤潮预报的方法,都是在以上的理论基础上进行各种预报工作。然而无论是哪种预报方法也只是赤潮预报的一种手段,绝大多数赤潮预报方法无法进行业务化运作,仅有气象条件预报赤潮和遥感方法预报赤潮两种有进行大尺度宏观的预报应用。气象条件仅是赤潮发生的诱发条件,并不是主要条件,由于赤潮灾害本身受诸多条件的限制,所以赤潮气象预报方法的准确率并不高;遥感方法预报赤潮具有快速、同步、大范围监测海洋的能力,但也有其自身的不足,例如不能全天候工作,阴雨天气和晚上就无法监测赤潮,此外对于空间分辨率较低,对小尺度赤潮的监测十分困难。充足的、有时效的、有质量保证的数据支撑才是赤潮预报工作能否业务化实施的根本,即使拟合度非常好的神经网络模型也仅仅是一种统计手段的探讨,在数据的缺失下也无法真正启动赤潮预报工作。技术实现要素:本发明所要解决的技术问题是:提供一种业务化赤潮预警方法及计算机可读存储介质,可实现较为准确的业务化赤潮预警。为了解决上述技术问题,本发明采用的技术方案为:一种业务化赤潮预警方法,包括:获取赤潮发生前预设第一天数至赤潮发生后预设第一天数内的赤潮发生区域的生态数据,得到赤潮样本,并将赤潮发生期间的生态数据标记为赤潮数据,将其他生态数据标记为非赤潮数据,所述生态数据包含多个变量的数据;对所述赤潮样本进行预处理,所述预处理包括剔除异常值、补充缺失值、滤波处理和归一化处理;根据som神经网络,对所述赤潮样本进行筛选,得到合格的赤潮样本,并根据合格的赤潮样本中的生态数据,得到固定样本数据;根据所述固定样本数据,通过遗传算法,对所述生态数据中的多个变量进行降维,并将降维后的变量作为神经网络模型的最终输入变量;构建神经网络模型,所述神经网络模型的输入层节点数与所述最终输入变量的个数一致,输出层节点数为1;获取最新的预设第一天数的生态数据,得到临时样本数据,并对所述临时样本数据进行预处理;根据所述固定样本数据和临时样本数据中的最终输入变量,得到预报样本数据;根据一预报样本数据及其未来第i天的赤潮发生情况,生成所述一预报样本数据对应的第i个的预报训练数据,i=1,2,…,m-1+n,m和n为预设的数值;根据一预报样本数据、其过去m-1天的同一时刻的预报样本数据以及其未来n天的赤潮发生情况,生成所述一预报样本数据对应的第m+n个预报训练数据;根据各预报样本数据对应的第i个预报训练数据,对第i个神经网络模型进行训练,i=1,2,…,m-1+n;根据各预报样本数据对应的第m+n个预报训练数据,对第m+n个神经网络模型进行训练;获取最新m天的生态数据,并根据所述最终输入变量,得到最新m天的实时数据;若要预报未来第j天的赤潮发生情况,则分别从前m-1+n个神经网络模型中确定最新m天中各天对应的神经网络模型,并分别将所述各天的实时数据输入对应的神经网络模型,得到未来第j天对应的预报结果,j=1,2,…,n;将所述最新m天中同一时刻的实时数据组合后,输入第m+n个神经网络模型,得到对应未来n天的n维预报结果,并将所述n维预报结果中的第j个预报结果作为未来第j天对应的预报结果;根据所述未来第j天对应的预报结果,分析得到未来第j天的赤潮发生概率等级。本发明还提出一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现如上所述的方法的步骤。本发明的有益效果在于:通过对样本数据进行预处理,保证样本数据的准确性和完整性,通过归一化处理,减少不同变量之间量级差异带来的干扰;通过赤潮样本进行筛选,可确保赤潮样本的质量;通过对输入变量进行降维,可提高神经网络模型的精度和效率,降低神经网络模型的过拟合现象出现几率,减少模型收敛时长;通过生成各预报样本数据对应的各预报训练数据,并分别用多个神经网络模型进行训练,可得到分别用于预报未来多天的赤潮发生情况的神经网络模型,从而可实现业务化的赤潮预警,且预报准确率较高。附图说明图1为本发明实施例的一种业务化赤潮预警方法的流程图;图2为本发明实施例一的方法流程图;图3为本发明实施例一的神经网络模型的输入输出示意图;图4为本发明实施例二的方法流程图;图5为本发明实施例二中的som神经网络的拓扑结构示意图;图6为本发明实施例二中的som神经网络训练数据分类结果示意图;图7为本发明实施例二中的som神经网络测试数据分类结果示意图;图8为本发明实施例三的方法流程图。具体实施方式为详细说明本发明的技术内容、所实现目的及效果,以下结合实施方式并配合附图详予说明。请参阅图1,一种业务化赤潮预警方法,包括:获取赤潮发生前预设第一天数至赤潮发生后预设第一天数内的赤潮发生区域的生态数据,得到赤潮样本,并将赤潮发生期间的生态数据标记为赤潮数据,将其他生态数据标记为非赤潮数据,所述生态数据包含多个变量的数据;对所述赤潮样本进行预处理,所述预处理包括剔除异常值、补充缺失值、滤波处理和归一化处理;根据som神经网络,对所述赤潮样本进行筛选,得到合格的赤潮样本,并根据合格的赤潮样本中的生态数据,得到固定样本数据;根据所述固定样本数据,通过遗传算法,对所述生态数据中的多个变量进行降维,并将降维后的变量作为神经网络模型的最终输入变量;构建神经网络模型,所述神经网络模型的输入层节点数与所述最终输入变量的个数一致,输出层节点数为1;获取最新的预设第一天数的生态数据,得到临时样本数据,并对所述临时样本数据进行预处理;根据所述固定样本数据和临时样本数据中的最终输入变量,得到预报样本数据;根据一预报样本数据及其未来第i天的赤潮发生情况,生成所述一预报样本数据对应的第i个的预报训练数据,i=1,2,…,m-1+n,m和n为预设的数值;根据一预报样本数据、其过去m-1天的同一时刻的预报样本数据以及其未来n天的赤潮发生情况,生成所述一预报样本数据对应的第m+n个预报训练数据;根据各预报样本数据对应的第i个预报训练数据,对第i个神经网络模型进行训练,i=1,2,…,m-1+n;根据各预报样本数据对应的第m+n个预报训练数据,对第m+n个神经网络模型进行训练;获取最新m天的生态数据,并根据所述最终输入变量,得到最新m天的实时数据;若要预报未来第j天的赤潮发生情况,则分别从前m-1+n个神经网络模型中确定最新m天中各天对应的神经网络模型,并分别将所述各天的实时数据输入对应的神经网络模型,得到未来第j天对应的预报结果,j=1,2,…,n;将所述最新m天中同一时刻的实时数据组合后,输入第m+n个神经网络模型,得到对应未来n天的n维预报结果,并将所述n维预报结果中的第j个预报结果作为未来第j天对应的预报结果;根据所述未来第j天对应的预报结果,分析得到未来第j天的赤潮发生概率等级。从上述描述可知,本发明的有益效果在于:可实现业务化的赤潮预警,且预报准确率较高。进一步地,所述剔除异常值的方法包括基于仪器量程范围剔除异常值、基于与相邻数据的距离剔除异常值、基于均方差检验剔除异常值以及基于数据密度检验剔除异常值中的至少一种;所述基于仪器量程范围剔除异常值具体为:若所述生态数据中一变量的一数据值不处于所述一变量对应的仪器量程范围内,则剔除所述一数据值;所述基于与相邻数据的距离剔除异常值具体为:根据一变量对应的迭代次数,遍历所述一变量的各时刻的数据值;计算一时刻前后预设第一时段内的所述一变量的数据值的平均值,得到所述一时刻对应的相邻数据平均值;若所述一变量的一时刻的数据值与其对应的相邻数据平均值的差值绝对值大于所述一变量对应的第一阈值,则剔除所述一时刻的数据值。所述基于均方差检验剔除异常值具体为:遍历所述生态数据中一变量的各时刻的数据值;计算一时刻前后预设第二时段内的所述一变量的数据值的平均值和均方差值,得到所述一时刻对应的相邻数据平均值和相邻数据均方差值;若所述一变量的一时刻的数据值与其对应的相邻数据平均值的差值绝对值大于预设倍数的所述相邻数据均方差值,则剔除所述一时刻的数据值,所述预设倍数为预设的所述一变量对应的倍数;所述基于数据密度检验剔除异常值具体为:根据生态数据中的一变量的一时刻的数据值以及所述一变量对应的第二阈值,得到所述一变量对应所述一时刻的相关范围;若一变量的一时刻前后预设第三时段内的数据值不处于所述一变量对应所述一时刻的相关范围的个数超过预设个数,则剔除所述一变量的一时刻的数据值。由上述描述可知,通过剔除异常值,保证数据的准确性。进一步地,所述补充缺失值具体为:若生态数据中的一变量的一时刻的数据值缺失,则根据所述一时刻预设第三时段内的所述一变量的数据值,通过三次样条差值补充所述一时刻的数据值。由上述描述可知,通过补充缺失值,保证数据的完整性。进一步地,所述滤波处理具体为:根据预设的第四时段,分别对所述生态数据中各变量的各时刻的数据值进行均值滤波。由上述描述可知,通过滤波处理,去除数据中的噪声。进一步地,所述归一化处理具体为:将一变量的一数据值与所述一变量的最小值的差值除以所述一变量的最大值与最小值的差值,得到归一化后的数据值。由上述描述可知,通过归一化处理,可减少不同变量之间量级差异带来的干扰。进一步地,所述根据som神经网络,对所述赤潮样本进行筛选,得到合格的赤潮样本具体为:根据预设的比例,将一赤潮样本划分为训练数据和测试数据;根据所述训练数据对预设的som神经网络进行训练,所述som神经网络的输出层包括a×b个神经元,a和b为预设的数值;分别统计各神经元中赤潮数据和非赤潮数据的个数,并计算各神经元的赤潮数据所占比例;将所述测试数据输入训练后的som神经网络,得到测试数据的分类结果;遍历预设的敏感系数列表,并依次获取一敏感系数作为当前敏感系数;根据所述赤潮数据所占比例以及当前敏感系数,分别将各神经元划分为赤潮神经元和非赤潮神经元;根据测试数据的分类结果,统计当前敏感系数对应的分类结果参数,所述分类结果参数包括第一值、第二值、第三值和第四值,所述第一值表示测试数据中被分到赤潮神经元的赤潮数据的数量,所述第二值表示测试数据中被分到非赤潮神经元的赤潮数据的数量,所述第三值表示测试数据中被分到赤潮神经元的非赤潮数据的数量,所述第四值表示测试数据中被分到非赤潮神经元的非赤潮数据的数量;根据当前敏感系数对应的第一值、第二值、第三值、第四值以及测试数据的总数据量,计算当前敏感系数对应的heidke技巧评分;当遍历完所述敏感系数列表后,获取各敏感系数对应的heidke技巧评分中的最大值对应的敏感系数,得到最优敏感系数;根据所述最优敏感系数对应的第一值、第四值以及测试数据的总数据量,计算所述一赤潮样本的正确预报率;若所述正确预报率大于或等于预设的阈值,则判定所述一赤潮样本合格;若所述正确预报率小于预设的阈值,则判定所述一赤潮样本不合格。由上述描述可知,可对赤潮样本进行精确筛选,确保赤潮样本数据包含赤潮信息,并正确区分赤潮期间数据和非赤潮期间数据,用于机器学习模型的分析和训练。进一步地,所述根据所述固定样本数据,通过遗传算法,对所述生态数据中的多个变量进行降维,并将降维后的变量作为神经网络模型的最终输入变量具体为:根据预设的比例,将所述固定训练数据划分为训练数据和测试数据;随机产生预设数量的初始串结构数据,得到初始的种群,所述初始串结构数据中的每个位分别与样本数据中的各变量一一对应,且每个位的取值为第一字符或第二字符;遍历最新的种群,并依次获取一串结构数据作为当前串结构数据;根据当前串结构数据中取值为第一字符的位对应的变量,确定建模变量;构建当前串结构数据对应的人工神经网络,所述人工神经网络的输入层神经元的个数与所述建模变量的个数一致,输出层神经元的个数为2;根据所述训练数据中的建模变量,对当前串结构数据对应的人工神经网络进行训练;将所述测试数据中的建模变量输入训练后的所述人工神经网络,得到预报结果;根据测试数据的实际结果和预报结果,计算均方根误差,并将所述均方根误差作为当前串结构数据对应的适应度;当遍历完最新的种群后,判断最新的种群中是否存在适应度大于或等于预设目标值的串结构数据;若是,则将适应度大于或等于预设目标值的串结构数据中取值为第一字符的位对应的变量作为最终输入变量;若否,则根据遗传算法的选择操作、交叉操作和变异操作,生成新的串结构数据,得到新的种群;继续执行所述遍历最新的种群,并依次获取一串结构数据作为当前串结构数据的步骤。由上述描述可知,通过遗传算法对神经网络的输入变量进行降维,可提高神经网络模型的精度和效率,降低神经网络模型的过拟合现象出现几率,减少模型收敛时长。进一步地,所述神经网络模型包括bp神经网络模型和rbf神经网络模型;所述构建神经网络模型之后,进一步包括:通过遗传算法优化所述bp神经网络模型的权值和阈值。进一步地,所述预报结果的预报值的取值范围为[0,1];所述根据所述未来第j天对应的预报结果,分析得到未来第j天的赤潮发生概率等级具体为:计算所述未来第j天对应的预报结果的预报值的平均值;若所述平均值大于或等于0.5,则令第一参数为1,否则令第一参数为0;统计所述未来第j天对应的预报结果中预报值大于或等于0.5的预报结果的个数,得到第一个数,并统计预报值小于0.5的预报结果的个数,得到第二个数;计算所述第一个数占所述第一个数与第二个数之和的比值;若所述比值大于预设的第一系数,则令第二参数为1,否则令第二参数为0;若所述第一参数和第二参数均为1,则令第三参数为预设的第一等级值;若所述第一参数和第二参数中有且只有一个为1,则令第三参数为预设的第二等级值;若所述第一参数和第二参数均为0,则令第三参数为预设的第三等级值;若所述比值大于预设的第二系数,则令第四参数为所述第一等级值;若所述比值小于或等于所述第二系数,且大于预设的第三系数,则令第四参数为所述第二等级值;若所述比值小于或等于所述第三系数,则第四参数为所述第三等级值;将所述第三参数和第四参数中的最大等级值作为未来第j天的赤潮发生概率等级。由上述描述可知,基于多种神经网络模型和多种统计方法,避免生态浮标实时监测数据的不稳定波动以及神经网络模型的过拟合带来的偶然误差。本发明还提出一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现如上所述的方法的步骤。实施例一请参照图2-3,本发明的实施例一为:一种业务化赤潮预警方法,可应用于海洋赤潮预警,如图2所示,包括如下步骤:s1:获取赤潮发生前预设第一天数至赤潮发生后预设第一天数内的赤潮发生区域的生态数据,得到赤潮样本,并将赤潮发生期间的生态数据标记为赤潮数据,将其他生态数据标记为非赤潮数据,所述生态数据包含多个变量的数据。其中,赤潮发生区域指的是官方给出的发生赤潮的大致区域,赤潮发生期间指的是官方给出的发生赤潮的大致时间段。本实施例中,预设第一天数为15天,即获取赤潮发生前15天至赤潮发生后15天这段时间内的赤潮发生区域的生态数据,得到一个赤潮样本;赤潮样本中赤潮发生期间的数据标记为1,为赤潮数据,其他时间的数据标记为0,为非赤潮数据。s2:对所述赤潮样本进行预处理,所述预处理包括剔除异常值、补充缺失值、滤波处理和归一化处理。其中,所述剔除异常值的方法包括基于仪器量程范围剔除异常值、基于与相邻数据的距离剔除异常值、基于均方差检验剔除异常值以及基于数据密度检验剔除异常值。a)基于仪器量程范围剔除异常值,即判断一变量的各数据值是否处于该变量的仪器量程范围内,若一数据值不处于仪器量程范围内,则认为数据值为异常值,将其剔除。例如,使用仪器ysi(多参数水质测定仪)的量程范围对数据进行初检验,不在量程范围内的数据视为异常值,将其剔除。几种变量的量程范围如表1所示。表1:浮标参数的量程范围测量参数温度盐度溶解氧叶绿素量程范围0-35℃0-40psu0-20mg/l0-400μg/lb)基于与相邻数据的距离剔除异常值,即如果某个数据与其相邻数据之间的距离大于设定的阈值,则视其为异常数据。具体地,遍历所述生态数据中一变量的各时刻的数据值;计算一时刻前后预设第一时段内的所述一变量的数据值的平均值,得到所述一时刻对应的相邻数据平均值;若所述一变量的一时刻的数据值与其对应的相邻数据平均值的差值绝对值大于所述一变量对应的第一阈值,则剔除所述一时刻的数据值。然后根据所述一变量对应的迭代次数,重复上述步骤,即进行多次遍历和剔除。例如,假设某一变量数据为x1,x2,…,xn,某一m时刻的数据值为xm,其前后5小时(m-5,m+5)的数据(10个数据)的平均值为若该时刻的数据值与该平均值的差值的绝对值大于预设的第一阈值时,即若则将该时刻的数据值xm视为异常值,并将其剔除。重复上述流程,迭代t次,得到最后结果。其中,dp和t的取值经多次试验得到,几种变量的dp和t的取值如表2所示。表2:变量对应的第一阈值dp和迭代次数t测量参数温度盐度溶解氧叶绿素dp35430t4441c)基于均方差检验剔除异常值,即如果某个数据与其相邻数据的平均值之差大于α倍的均方差,则视其为异常数据。具体地,遍历所述生态数据中一变量的各时刻的数据值;计算一时刻前后预设第二时段内的所述一变量的数据值的平均值和均方差值,得到所述一时刻对应的相邻数据平均值和相邻数据均方差值;若所述一变量的一时刻的数据值与其对应的相邻数据平均值的差值绝对值大于预设倍数的所述相邻数据均方差值,则剔除所述一时刻的数据值,所述预设倍数为预设的所述一变量对应的倍数。例如,假设某一变量数据为x1,x2,…,xn,某一m时刻的数据值为xm,其前后25小时(m-25,m+25)的数据(50个数据)的平均值为均方差值为s,若该时刻的数据值与该平均值的差值的绝对值大于α倍的均方差,即满足则将该时刻的数据值xm视为异常值,并将其剔除。其中,α的取值经多次试验得到,几种变量的α的取值如表3所示。表3:变量对应的α的取值测量参数温度盐度溶解氧叶绿素α4445d)基于数据密度检验剔除异常值,即通过衡量某一时刻的数据与其相邻数据的无关程度,判断其是否离群,若是,则视其为异常数据。具体地,根据生态数据中的一变量的一时刻的数据值以及所述一变量对应的第二阈值,得到所述一变量对应所述一时刻的相关范围;若一变量的一时刻前后预设第三时段内的数据值不处于所述一变量对应所述一时刻的相关范围的个数超过预设个数,则剔除所述一变量的一时刻的数据值。本实施例中,第二阈值可与第一阈值一致。例如,假设某一变量数据为x1,x2,…,xn,某一m时刻的数据值为xm,其前后10小时(m-10,m+10)的数据为xm-10,xm-9,…,xm+10,如果这20个数据值中超过一半的数据值不在范围(xm-dp,xm+dp)内,则视该时刻的数据值离群,视为异常值,将其剔除。对于补充缺失值,具体为:若生态数据中的一变量的一时刻的数据值缺失,则根据所述一时刻预设第三时段内的所述一变量的数据值,通过三次样条差值补充所述一时刻的数据值。例如,当一变量的数据在某些时间点缺失时,如果在缺失时间点的3小时范围内存在正常值,则采用三次样条插值的方法补充缺失值。对于滤波处理,本实施例采用的是均值滤波方法,具体地,根据预设的第四时段,分别对所述生态数据中各变量的各时刻的数据值进行均值滤波。例如,对所有赤潮样本数据进行3小时平滑,即取一变量某一时刻前后3小时内的所有数据值的平均值,作为该时刻的数据值。对于归一化处理,具体地,根据归一化公式,分别对样本数据中的各变量的变量值进行归一化处理。归一化公式:xnew=(x-xmin)/(xmax-xmin)其中,x表示待归一化的一变量的变量值,xnew表示归一化后的变量值,xmax和xmin分别表示所述一变量的最大值和最小值。通过归一化处理,可减少不同变量之间量级差异带来的干扰。s3:根据som神经网络,对所述赤潮样本进行筛选,得到合格的赤潮样本,并将合格的赤潮样本中的生态数据作为固定样本数据。s4:根据所述固定样本数据,通过遗传算法,对所述生态数据中的多个变量进行降维,并将降维后的变量作为神经网络模型的最终输入变量。s5:构建神经网络模型,所述神经网络模型的输入层节点数与所述最终输入变量的个数一致,输出层节点数为1。本实施例中,构建两种神经网络模型,分别为bp神经网络模型和rbf神经网络模型。进一步地,通过遗传算法优化所述bp神经网络模型的权值和阈值。s6:获取最新的预设第一天数的生态数据,得到临时样本数据,并对所述临时样本数据进行预处理;即获取最新15天的生态数据构成临时样本数据。其中,预处理的具体过程可参照步骤s2。s7:根据所述固定样本数据和临时样本数据中的最终输入变量,得到预报样本数据,即对于固定样本数据和临时样本数据中的每个样本数据,仅保留对应最终输入变量的变量数据。s8:根据一预报样本数据及其未来第i天的赤潮发生情况,生成所述一预报样本数据对应的第i个的预报训练数据,i=1,2,…,m-1+n,m和n为预设的数值。步骤s1中对赤潮数据和非赤潮数据的划分是基于生态数据的采集时间是否处于赤潮发生期间,本步骤即重新对预报样本数据进行标记,标记的依据为该预报样本数据的采集时间的未来第i天的赤潮发生情况,若赤潮发生,则记为1,若赤潮未发生,则记为0。此时,一个预报样本数据可生成多个预报训练数据,同一个预报样本数据对应的多个预报训练数据中的变量数据是相同的,但标记分别对应该预报样本数据的采集时间的未来多天的赤潮发生情况。由于固定样本数据和临时样本数据大部分为历史数据,因此其未来多天的赤潮发生情况是可得到的,而对于临时样本数据中最新几天的样本数据,可基于其未来几天中已知的赤潮发生情况生成对应的预报训练数据。例如,假设预报样本数据的采集时间为7月1号至7月31号,当天为8月1号,m=n=4。对于7月1号的预报样本数据,分别根据7月2号至7月8号的赤潮发生情况,生成其对应的7个预报训练数据;对于7月2号的预报样本数据,分别根据7月3号至7月9号的赤潮发生情况,生成其对应的7个预报训练数据;以此类推。由于8月1号及其之后的赤潮发生情况未知,因此,对于7月25号的预报样本数据,分别根据7月26号至7月31号这六天的赤潮发生情况,生成其对应的6个预报训练数据;对于7月26号的预报样本数据,分别根据7月27号至7月31号这五天的赤潮发生情况,生成其对应的5个预报训练数据;以此类推。s9:根据一预报样本数据、其过去m-1天的同一时刻的预报样本数据以及其未来n天的赤潮发生情况,生成所述一预报样本数据对应的第m+n个预报训练数据。即根据过去m天中同一时间点采集的预报样本数据以及未来n天的赤潮发生情况,生成预报训练数据。此时,每个预报训练数据包括m维的预报样本数据和n维的赤潮发生情况的标记。例如,以上述例子继续进行举例说明。对于7月4号至7月27号中的每个预报样本数据,还会根据其过去3天同一时刻的预报样本数据以及其未来4天的赤潮发生情况,生成其对应的第8个预报训练数据。例如,获取7月1号至7月4号中同一时刻(即每天的同一时间点,如每天的1点、2点等)采集的预报样本数据,并根据7月5号至7月8号的赤潮发生情况,生成预报训练数据;获取7月2号至7月5号中同一时刻的预报样本数据,并根据7月6号至7月9号的赤潮发生情况,生成预报训练数据;以此类推。此时,预报训练数据中包括4维的变量数据和4维的赤潮发生情况的标记。s10:根据各预报样本数据对应的第i个预报训练数据,对第i个神经网络模型进行训练,i=1,2,…,m-1+n。具体地,即分别构建m+n个bp神经网络模型和m+n个rbf神经网络模型;然后根据各预报样本数据对应的第i个预报训练数据,分别对第i个bp神经网络模型和第i个rbf神经网络模型进行训练,i=1,2,…,m-1+n。其中,由于预报样本数据对应的第i个预报训练数据是根据该预报样本数据未来第i天的赤潮发生情况生成的,因此,第i个神经网络模型训练完后可用于对输入数据的未来第i天的赤潮发生情况进行预测。s11:根据各预报样本数据对应的第m+n个预报训练数据,对第m+n个神经网络模型进行训练。即分别对第m+n个bp神经网络模型和第m+n个rbf神经网络模型进行训练。由于预报样本数据对应的第m+n个预报训练数据是根据过去m天的数据以及未来n天的赤潮发生情况生成的,因此,第m+n个神经网络模型训练完后,输入m维的数据,即过去连续m天的同一时刻的数据,如pk-(m-1)…pk-1pk,可得到其未来连续n天的赤潮发生情况的n维预报结果,如rk+1rk+2…rk+n;其中,rk+1可作为的pk的未来第一天的预报结果,rk+2可作为的pk的未来第二天的预报结果,以此类推。s12:获取最新m天的生态数据,并根据所述最终输入变量,得到最新m天的实时数据。即对于每组生态数据,仅保留其中最终输入变量的变量数据,得到对应的实时数据。s13:将所述最新m天的实时数据分别输入前m-1+n个神经网络模型,并将所述最新m天中同一时刻的实时数据组合后输入第m+n个神经网络模型,得到对应未来n天的预报结果。例如,假设m=n=4,即根据最新4天的数据,预测未来4天的赤潮发生情况,假设最新4天中对应同一采集时间点的实时数据分别用pk、pk-1、pk-2、pk-3表示,未来4天的预报结果分别用rk+1、rk+2、rk+3、rk+4表示。如图3所示,将pk输入第1个神经网络模型,可得到其未来第一天的预报结果,即rk+1;将pk输入第2个神经网络模型,可得到其未来第二天的预报结果,即rk+2;以此类推。也就是说,将pk分别输入第1个至第4个神经网络模型,可分别得到其未来第一天至第四天的预报结果rk+1、rk+2、rk+3、rk+4。由于k-1与k+1相差两天,因此需要将pk-1输入第2个神经网络模型,才可得到其未来第二天的预报结果,即rk+1。也就是说,将pk-1分别输入第2个至第5个神经网络模型,才可分别得到其未来第二天至第五天的预报结果rk+1、rk+2、rk+3、rk+4。同理推知,将pk-2分别输入第3个至第6个神经网络模型,分别得到其未来第三天至第六天的预报结果rk+1、rk+2、rk+3、rk+4。将pk-3分别输入第4个至第7个神经网络模型,分别得到其未来第四天至第七天的预报结果rk+1、rk+2、rk+3、rk+4。进一步地,将最新四天的实时数据进行组合,即pk-3pk-2pk-1pk,输入第8个神经网络模型,得到未来四天的预报结果,即rk+1rk+2rk+3rk+4,并且其中的rk+1、rk+2、rk+3、rk+4可分别作为未来第一天、第二天、第三天、第四天的预报结果。那么,可以推知,若要预报未来第j天的赤潮发生情况,j=1,2,…,n,则分别从前m-1+n个神经网络模型中确定最新m天中各天对应的神经网络模型,使得各天的实时数据输入其对应的神经网络模型均可得到对应同一天(未来第j天,此处的未来第j天是相对最新一天的未来第j天)的预报结果;然后分别将所述各天的实时数据输入对应的神经网络模型,得到未来第j天对应的预报结果。同时将所述最新m天中同一时刻的实时数据组合后,输入第m+n个神经网络模型,得到对应未来n天的n维预报结果,并将所述n维预报结果中的第j个预报结果作为未来第j天对应的预报结果。例如,若要预报未来第一天的赤潮发生情况,则将pk输入第1个神经网络模型,得到pk对应的rk+1,将pk-1输入第2个神经网络模型,得到pk-1对应的rk+1,将pk-2输入第3个神经网络模型,得到pk-2对应的rk+1,将pk-3输入第4个神经网络模型,得到pk-3对应的rk+1,将pk-3pk-2pk-1pk输入第8个神经网络模型,并将得到的rk+1rk+2rk+3rk+4中的rk+1作为pk-3pk-2pk-1pk对应的rk+1。此时即可获取未来第一天对应的所有预报结果。假设数据采集频率为每半小时采集一次,则每天可得到48个实时数据,那么对于最新4天的实时数据,且对应一种神经网络模型,可得到48×5=240个的rk+1,同理,rk+2、rk+3和rk+4的个数也为240个。由于本实施例构建了两种神经网络模型,那么即可分别得到240×2=480个的rk+1、rk+2、rk+3和rk+4。s14:根据未来同一天对应的预报结果,分析得到所述未来同一天赤潮发生概率等级。即根据所述未来第j天对应的预报结果,分析得到未来第j天的赤潮发生概率等级,j=1,2,…,n。本实施例中,预报结果的预报值一般为0-1之间的数值,越接近于0,表示该预报结果越倾向于赤潮不发生,越接近于1,表示该预报结果越倾向于赤潮发生。为避免极端输出结果的干扰,将小于0的预报值定义为0,将大于1的预报值定义为1。例如,假设要对未来第一天(即24h时效)的赤潮发生概率等级进行分析,此时获取了480个预报结果,则进行下述步骤:计算这480个预报结果的预报值的平均值,若平均值大于或等于0.5,则令g1=1判断为赤潮发生,否则g1=0,判断为赤潮不发生。将这480个预报结果的预报值分别与0.5进行比较,统计大于或等于0.5的预报结果的个数n1,小于0.5的预报结果的个数n2;若n1/(n1+n2)>0.35,则令g2=1,判断为赤潮发生,否则g2=0,判断为赤潮不发生。当g1和g2都等于1时,令h1=3,表示赤潮发生概率较大;当g1和g2有且只有1个等于1时,令h1=2,表示赤潮发生概率较小;当g1和g2都等于0时,令h1=1,表示赤潮不会发生。当n1/(n1+n2)≥0.65,令h2=3,表示赤潮发生概率较大;当0.3≤n1/(n1+n2)<0.65时,令h2=2,表示赤潮发生概率较小;当n1/(n1+n2)<0.3时,令h2=1,表示赤潮不会发生。最后取h1和h2中的最大值作为未来第一天的赤潮发生概率等级。对于未来第二天(即48h时效)、第三天(即72h时效)和第四天(即96h时效)的赤潮发生概率等级,也通过上述步骤得到。由于生态浮标实时监测数据常常会出现不稳定波动,人工神经网络模型偶尔也会出现过拟合导致预报不准确,本实施例的基于生态浮标高频采样、多个神经网络模型和多种统计方法获得的最终预报结果,有效避免了上述情况带来的偶然误差。实施例二请参照图4-7,本实施例是实施例一中步骤s3的进一步拓展,如图4所示,步骤s3具体包括如下步骤:s301:根据预设的比例,将一赤潮样本划分为训练数据和测试数据。例如,将一个赤潮样本的80%数据作为训练数据,20%数据作为测试数据。当一个赤潮样本共计2148组数据时,随机选取样本中的1718组数据作为训练数据,剩余430组数据作为测试数据。s302:根据所述训练数据对预设的som神经网络进行训练,所述som神经网络的输出层包括a×b个神经元,a和b为预设的数值。例如,在该步骤之前,预先构建som神经网络,将som神经网络的输出设置成7*7网格,共包含49个神经元,如图5所示。然后用训练数据训练该som神经网络,训练完成后,根据数据之间的差异性,训练数据被分配到49个神经元中,如图6所示。每个神经元分得的数据中有赤潮数据和非赤潮数据。s303:分别统计各神经元中赤潮数据和非赤潮数据的个数,并计算各神经元中赤潮数据所占比例。例如,对于一神经元,假设其分得的数据中有s1个赤潮数据和s2个非赤潮数据,则该神经元中赤潮数据的占比为s1/(s1+s2)。s304:将所述测试数据输入训练后的som神经网络,得到测试数据的分类结果。将测试数据输入训练后的som神经网络后,som神经网络将测试数据分类到49个神经元中,例如图7所示。每个测试数据都会被分到一个神经元中,此时即记录每个测试数据被分到哪个神经元。s305:遍历预设的敏感系数列表,并依次获取一敏感系数作为当前敏感系数。本实施例中,敏感系数列表为{0,0.01,0.02,…,1},即敏感系数a从0开始取值,下一值递增0.01,直到1。s306:根据各神经元的赤潮数据所占比例以及当前敏感系数的取值,分别将各神经元划分为赤潮神经元和非赤潮神经元。具体地,若一神经元中赤潮数据所占比例超过当前敏感系数a,则将所述一神经元作为赤潮神经元,否则将所述一神经元作为非赤潮神经元。s307:根据测试数据的分类结果,统计当前敏感系数对应的分类结果参数。其中,所述分类结果参数包括第一值、第二值、第三值和第四值,所述第一值表示测试数据中被分到赤潮神经元的赤潮数据的数量,所述第二值表示测试数据中被分到非赤潮神经元的赤潮数据的数量,所述第三值表示测试数据中被分到赤潮神经元的非赤潮数据的数量,所述第四值表示测试数据中被分到非赤潮神经元的非赤潮数据的数量。具体地,所述第一值t1、第二值f1、第三值f2和第四值t2的初始值均为0,即首先令t1=f1=f2=t2=0。然后遍历测试数据,若当前遍历到的测试数据为赤潮数据,且其输入训练后的som神经网络后被分到的神经元为赤潮神经元,则认为分类正确,令t1=t1+1;若当前遍历到的测试数据为赤潮数据,且其输入训练后的som神经网络后被分到的神经元为非赤潮神经元,则认为分类错误,令f1=f1+1;若当前遍历到的测试数据为非赤潮数据,且其输入训练后的som神经网络后被分到的神经元为赤潮神经元,则认为分类错误,令f2=f2+1;若当前遍历到的测试数据为非赤潮数据,且其输入训练后的som神经网络后被分到的神经元为非赤潮神经元,则认为分类正确,令t2=t2+1。当遍历完所有测试数据后,即可得到当前敏感系数对应的第一值t1、第二值f1、第三值f2和第四值t2,并且t1+f1+f2+t2=n,n为测试数据的总数据量。s308:根据当前敏感系数对应的第一值、第二值、第三值、第四值以及测试数据的总数据量,计算当前敏感系数对应的heidke(海德克)技巧评分(hss,theheidkeskillscore)。具体地,根据下述公式计算当前敏感系数对应的heidke技巧评分。hss=[(t1+t2)-(expectedcorrect)random]/[n-(expectedcorrect)random](expectedcorrect)random=[(t1+f1)×(t1+f2)+(t2+f1)×(t2+f2)]/n其中,t1为当前敏感系数对应的第一值,f1为当前敏感系数对应的第二值,f2为当前敏感系数对应的第三值,t2为当前敏感系数对应的第四值,n为测试数据的总数据量。s309:判断是否遍历完所述敏感系数列表,若是,则执行步骤s310,若否,则继续获取下一敏感系数作为当前敏感系数,即执行步骤s305。s310:获取各敏感系数对应的heidke技巧评分中的最大值对应的敏感系数,得到最优敏感系数。执行到本步骤时,已经计算得到了各敏感系数对应的heidke技巧评分,对这些heidke技巧评分进行比较,然后将最大值对应的敏感系数作为最优敏感系数,即最优敏感系数对应的heidke技巧评分为最大值,也即此时som神经网络对测试数据的分类结果最优。进一步地,若存在多个敏感系数对应的heidke技巧评分均为最大值,则将所述多个敏感系数中的最小值作为最优敏感系数。s311:根据所述最优敏感系数对应的第一值、第四值以及测试数据的总数据量,计算所述一赤潮样本的正确预报率。具体地,根据下述公式计算所述一赤潮样本的正确预报率。pocr=(t1+t2)/n其中,t1为最优敏感系数对应的第一值,t2为最优敏感系数对应的第四值,n为测试数据的总数据量。s312:判断所述正确预报率是否大于或等于预设的阈值,若是,则执行步骤s313,若否,则执行步骤s314。本实施例中,所述预设的阈值为0.85。s313:判定所述一赤潮样本合格。当正确预报率大于或等于预设的阈值,则说明该赤潮样本数据包含赤潮信息,赤潮期间数据和非赤潮期间数据存在明显差异,可用于机器学习模型的分析和训练。s314:判定所述一赤潮样本不合格,并剔除所述一赤潮样本。通过本实施例所述的方法,对各赤潮样本进行筛选,即可得到合格的赤潮样本,可确保赤潮样本数据包含赤潮信息。实施例三请参照图8,本实施例是实施例一中步骤s4的进一步拓展,步骤s4具体包括如下步骤:s401:根据预设的比例,将固定训练数据划分为训练数据和测试数据。例如,将一个赤潮样本的80%数据作为训练数据,20%数据作为测试数据。s402:随机产生预设数量的初始串结构数据,得到初始的种群。其中,所述初始串结构数据中的每个位分别与固定训练数据中的各变量一一对应,因此初始串结构数据的长度与生态数据中的变量个数相同,且每个位的取值为第一字符或第二字符。其中,取值为第一字符的位对应的变量参与建模,即参与人工神经网络的训练与预报,取值为第二字符的位对应的变量不参与建模。本实施例中,预设数量为20,第一字符为1,第二字符为0。每个初始串结构数据即为一个个体,也即一个染色体,20个个体构成了一个种群,遗传算法以这20个串结构数据作为初始点开始迭代。s403:分别计算最新的种群中各串结构数据对应的适应度。具体地,本步骤包括如下步骤:s4031:遍历种群,并依次获取一串结构数据作为当前串结构数据。s4032:根据当前串结构数据中取值为第一字符的位对应的变量,确定建模变量。s4033:构建当前串结构数据对应的人工神经网络,所述人工神经网络的输入层神经元的个数与所述建模变量的个数一致,输出层神经元的个数为2;即构建二元神经网络预报模型。s4034:根据所述训练数据中的建模变量,对当前串结构数据对应的人工神经网络进行训练。s4035:将所述测试数据中的建模变量输入训练后的所述人工神经网络,得到预报结果,所述预报结果为赤潮发生或赤潮未发生。s4036:根据测试数据的实际结果和预报结果,计算均方根误差,并作为当前串结构数据对应的适应度。其中,均方根误差是预测值与真实值偏差的平方与观测次数n比值的平方根。s404:判断最新的种群中是否存在适应度大于或等于预设目标值的串结构数据,若是,则执行步骤s405,若否,则执行步骤s406。s405:将适应度大于或等于预设目标值的串结构数据中取值为第一字符的位对应的变量作为最终建模变量,即将满足条件的串结构数据中取值为1的位对应的变量作为降维后的模型输入变量。进一步地,若存在多个串结构数据的适应度均大于预设目标值,则将适应度最大值对应的串结构数据中取值为第一字符的位对应的参量作为最终输入变量。s406:根据遗传算法的选择操作、交叉操作和变异操作,生成新的串结构数据,得到新的种群;然后继续计算新的种群中各串结构数据对应的适应度,即继续执行步骤s403。其中,选择操作是指从旧的群体中以一定的概率选择个体到新的群体中,个体被选中的概率跟适应度值有关,个体适应度值越好,被选中的概率越大。本实施例中,根据当前种群中各串结构数据的适应度,计算各串结构数据的相对适应度,并作为各串结构数据被选中并遗传到下一代种群中的概率,相对适应度即一串结构数据的适应度占该种群所有串结构数据的适应度之和的比例,具体计算公式为:其中,f(xk)为第k个个体(串结构数据)的适应度,m为当前种群中个体的总数量。然后采用模拟轮盘赌操作,产生(0,1)之间的随机数,来确定各个个体被选中的次数。即将当前种群中各个体的放到0-1之间的数轴上,根据各个个体的相对适应度确定各个个体在这段数轴区间上的范围,所有个体占满这段数轴区间且相互之间不重叠,也就是说,某个个体的相对适应度越大,则占据数轴上的范围越大,那么产生的随机数落在其范围内的概率也就越大,即该个体被选择的概率也就越大。显然,适应度大的个体,相对适应度也大,其被选择概率也大,能被多次选中,其遗传基因就会在种群中扩大。交叉操作是指从种群中选择两个个体,通过两个染色体的交换组合,来产生新的优秀个体。交叉过程为从群体中任选两个染色体,随机选择一点或多点染色体位置进行交换。例如,假设交叉前的两个个体的染色体分别为:a:110001011111b:111101010000将后四位进行交叉,则交叉后的两个个体的染色体分别为:a:110001010000b:111101011111本实施例的交叉操作采用最简单的单点交叉算子,具体地,包括如下步骤:a)对当前种群中的个体进行两两配对,则共有n/2对相互配对的个体组;b)对每一对相互配对的个体组,随机选取某一基因座之后的位置作为交叉点;c)对每一对相互配对的个体组,根据b中所确定的交叉点位置,相互交互两个个体的部分染色体,生成两个新个体。变异操作是指从群体中任选一个个体,选择染色体中的一点进行变异以产生更优秀的个体。例如,假设变异前的一个个体的染色体为:110001011111;对倒数第二位进行变异,则变异后的该个体的染色体为:110001011101。本实施例的变异操作采用最简单的单点变异算子,具体地,包括如下步骤:a)随机产生变异点;b)根据a中的变异点位置,改变其对应的基因座上的基因值,即变异操作的结果为1变为0或0变为1。其中,每个个体的变异点都是随机产生的,因此每个个体的变异点不一定相同。本实施例用遗传算法对神经网络的输入变量进行降维,可提高神经网络模型的精度和效率,降低神经网络模型的过拟合现象出现几率,减少模型收敛时长。实施例四本实施例是对应上述实施例的一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现如上述实施例所述的步骤。综上所述,本发明提供的一种业务化赤潮预警方法及计算机可读存储介质,通过对样本数据进行预处理,保证样本数据的准确性和完整性,通过归一化处理,减少不同变量之间量级差异带来的干扰;通过赤潮样本进行筛选,可确保赤潮样本的质量;通过对输入变量进行降维,可提高神经网络模型的精度和效率,降低神经网络模型的过拟合现象出现几率,减少模型收敛时长;通过生成各预报样本数据对应的各预报训练数据,并分别用多个神经网络模型进行训练,可得到分别用于预报未来多天的赤潮发生情况的神经网络模型,从而可实现业务化的赤潮预警,且预报准确率较高。以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等同变换,或直接或间接运用在相关的
技术领域:
,均同理包括在本发明的专利保护范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1