一种人工智能训练平台的告警预测方法及装置与流程
本发明涉及人工智能训练领域,具体涉及一种人工智能训练平台的告警预测方法及装置。
背景技术:
人工智能训练平台作为一套系统,可以实现用户提交训练任务,并管理计算节点的集群来为多任务分配资源,同时为了维护集群稳定,平台对底层计算资源实时监控,在超出设置的告警阈值时进行告警提示。
深度学习训练中,计算资源多为cpu,gpu(graphicsprocessingunit,图像处理器),内存,磁盘等,人工智能训练平台的监控项设计也是面向这几部分,例如gpu显存、gpu功耗、gpu温度、cpu使用率、内存使用率等等。在深度学习训练平台中,需要为ai的性训练任务提供全生命周期管理,任务的创建也包括镜像加载、数据集加载、模型加载、模型参数计算等过程,这些操作都会实时的对上面提到的监控项数据产生影响,可能导致训练任务中途失败,例如在镜像和数据集加载完成后,模型加载时出现内存溢出情况,而此时加载镜像和数据集的时间已经耗费,影响训练进度与用户体验。更严重者,可能会由于训练模型过深过大,处理的数据与参数量过于庞大,节点连续高强度作业时间过长等极端情况,造成损害硬件设备等后果。
目前的人工智能训练平台的监控告警功能,是通过监控底层资源的实时数据,与告警阈值进行比对,判断是否触发告警功能。但是当真正触发告警时,普通用户已经完成了提交任务操作,花费了部分时间,并且训练任务会有无法暂停,无法继续,无法恢复的情况,此时任务从提交到训练完成得到模型的整个过程的成功与否,对用户的体验是有一定影响的。
技术实现要素:
为解决上述问题,本发明提供一种人工智能训练平台的告警预测方法及装置,在任务训练之前对监控告警情况进行预测,为用户提供预期结果。
本发明的技术方案是:一种人工智能训练平台的告警预测方法,包括以下步骤:
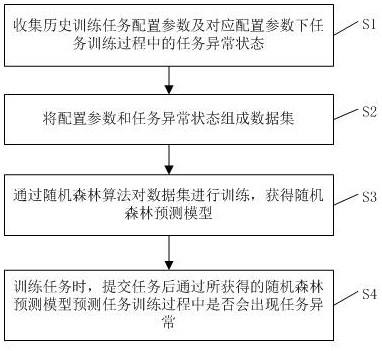
收集历史训练任务配置参数及对应配置参数下任务训练过程中的任务异常状态;
将配置参数和任务异常状态组成数据集;
通过随机森林算法对数据集进行训练,获得随机森林预测模型;
训练任务时,提交任务后通过所获得的随机森林预测模型预测任务训练过程中是否会出现任务异常。
进一步地,配置参数包括镜像大小、训练任务数据集大小、cpu个数、gpu个数、gpu型号、模型的神经网络层数、模型的单次处理图片数、模型的迭代次数。
进一步地,通过随机森林算法对数据集进行训练,获得随机森林预测模型,具体包括:
使用十折交叉验证法将数据集划分为训练集和测试集;
使用训练集通过随机森林算法进行训练,生成原始随机森林预测模型;
使用测试集对原始随机森林预测模型进行优化,获得优化后随机森林预测模型。
进一步地,使用测试集对原始随机森林预测模型进行优化,获得优化后随机森林预测模型,具体为:
使用测试集对原始随机森林预测模型进行测试,计算原始随机森林预测模型各个决策树的auc指标;
将auc指标大于指标阈值的决策树保留,剩余决策树删除;
计算保留决策树中,各个决策树之间的相似度;
将相似度大于相似度阈值的决策树进行聚类,获得优化后随机森林预测模型。
进一步地,两棵决策树之间的相似度为n/m,其中m为决策树预测结果总个数,n为两棵决策树之间相同的预测结果个数。
进一步地,通过随机森林算法对数据集进行训练,获得随机森林预测模型,还包括:
从数据集中提取部分数据作为验证集;使用十折交叉验证法将数据集划分为训练集和测试集是指,使用十折交叉验证法将提取验证集后的剩余数据划分为训练集和测试集;
使用验证集对优化后随机森林预测模型进行验证;
若预测准确率超过准确率阈值,则将该优化后随机森林预测模型作为最终随机森林预测模型;否则继续对原始随机森林预测模型进行优化。
进一步地,从数据集中提取部分数据作为验证集前,将数据集按时间进行分层,从各层中均提取到数据组成验证集。
本发明的技术方案还包括一种人工智能训练平台的告警预测装置,包括,
数据收集模块:收集历史训练任务配置参数及对应配置参数下任务训练过程中的任务异常状态;
数据集组成模块:将配置参数和任务异常状态组成数据集;
模型训练模块:通过随机森林算法对数据集进行训练,获得随机森林预测模型;
结果预测模块:训练任务时,提交任务后通过所获得的随机森林预测模型预测任务训练过程中是否会出现任务异常。
进一步地,配置参数包括镜像大小、训练任务数据集大小、cpu个数、gpu个数、gpu型号、模型的神经网络层数、模型的单次处理图片数、模型的迭代次数。
进一步地,模型训练模块包括,
数据划分单元:从数据集提取出部分数据作为验证集,剩余数据通过十折交叉验证法将剩余数据划分为训练集和测试集;
模型训练单元:使用训练集通过随机森林算法进行训练,生成原始随机森林预测模型;
模型优化单元:使用测试集对原始随机森林预测模型进行优化,获得优化后随机森林预测模型;
模型确定单元:使用验证集对优化后随机森林预测模型进行验证,获得最终随机森林预测模型。
本发明提供的一种人工智能训练平台的告警预测方法及装置,使用随机森林算法对人工智能训练平台的深度学习训练任务进行预测,提示用户所提交的任务是否会发生异常(例如能否完整无中断的完成训练得到模型和是否会触发训练平台的告警机制),减少用户不必要的任务运行等待时间,提前给出用户训练成功预期结果,便于维护训练平台的计算资源,提高人工智能训练平台的竞争力。
附图说明
图1是本发明具体实施例一方法流程示意图;
图2是获得随机森林预测模型方法流程示意图;
图3是本发明具体实施例二结构示意框图。
具体实施方式
下面结合附图并通过具体实施例对本发明进行详细阐述,以下实施例是对本发明的解释,而本发明并不局限于以下实施方式。
以下对本发明涉及的英文词汇进行解释:
auc:areaunderroccurve,即roc曲线下面积,为衡量预测模型优劣的一种标准。其中,roc曲线((receiveroperatingcharacteristiccurve,简称roc曲线)指接受者操作特性曲线。
实施例一
如图1所示,本实施例提供一种人工智能训练平台的告警预测方法,包括以下步骤:
s1,收集历史训练任务配置参数及对应配置参数下任务训练过程中的任务异常状态;
s2,将配置参数和任务异常状态组成数据集;
s3,通过随机森林算法对数据集进行训练,获得随机森林预测模型;
s4,训练任务时,提交任务后通过所获得的随机森林预测模型预测任务训练过程中是否会出现任务异常。
本方法在训练任务前生成预测模型,提交任务后即可首先利用预测模型预测在任务训练过程中是否会出现异常,例如触发告警或者中断造成任务失败等情况,为用户提供预期结果,便于维护训练平台的计算资源,提高人工智能训练平台的竞争力。
本实施例中,所收集的历史训练任务配置参数应包含与cpu、gpu、内存等监控项相关的参数,包括镜像大小、训练任务数据集大小(该数据集与上述步骤s2中的数据集不同,该数据集为深度学习训练任务的数据集,步骤s2中的数据集为本方法随机森林算法的数据集)、cpu个数、gpu个数、gpu型号、模型的神经网络层数、模型的单次处理图片数、模型的迭代次数。本实施例采用这八个特征进行随机森林算法预算,当然,所提取的配置参数可能会包含其他特征,但与监控项无关,为噪音项,为提高预测结果的准确性,在收集到配置参数之后可对数据进行特征提取,提取出上述八个特征。
对应配置参数下任务训练过程中的任务异常状态是指对应训练任务在运行过程中是否遇到触发告警或者中断造成任务失败等情况,任务异常状态作为标签保存在数据集中。
获得数据集即可通过森林算法进行训练,将数据集划分出训练集和测试集,优选地,还划分出验证集,首先使用训练集进行训练获得原始随机森林预测模型,再基于测试集进行相关计算对原始随机森林预测模型优化获得优化后随机森林预测模型,最后优选地通过验证集对优化后随机森林预测模型的预测结果进行验证,根据验证结果确定最终的随机森林预测模型,训练任务时,提交任务后即使用最终确定的随机森林预测模型进行预测。
如图2所示,上述步骤s3通过随机森林算法对数据集进行训练,获得随机森林预测模型,具体包括以下步骤。
s301,从数据集中提取部分数据作为验证集;
验证集用于验证随机森林预测模型的预测准确率,在提取数据作为验证集之前,首先将数据集按照时间进行分层,因为同一时间段可能会由于一些原因,例如并行任务量大、同一时刻进行的其他操作多、系统维护等特殊情况,导致这一时间段内的训练任务提交失败几率高,随机取样会不准确。因此,本实施例对数据集按时间分层,从各层中均提取到数据组成验证集。具体可提取20%的数据作为验证集。
s302,使用十折交叉验证法将剩余数据划分为训练集和测试集;
已提取出20%的数据作为验证集,该步骤将剩余80%的数据划分为训练集和测试集。
十折交叉验证法是一种将数据集通过分层采样划分为十个大小相似的互斥子集,将九个子集的并集作为训练集,余下的作为测试集,可获得十组训练/测试集,最终返回十个测试结果均值的方法,能够尽量保证评估结果的稳定性与保真性。
s303,使用训练集通过随机森林算法进行训练,生成原始随机森林预测模型;
通过随机森林算法进行训练生成预测模型为现有技术,在此不再赘述。
s304,使用测试集对原始随机森林预测模型进行优化,获得优化后随机森林预测模型;
该步骤通过auc指标评价原始随机森林预测模型各个决策树的分类性能好坏,将性能好的决策树保留,其他决策树删除,再通过决策树之间的相似度对决策树进行聚类,降低树的规模,获得优化后随机森林预测模型。
具体地,该步骤包括以下过程:
1)使用测试集对原始随机森林预测模型进行测试,计算原始随机森林预测模型各个决策树的auc指标;
2)将auc指标大于指标阈值的决策树保留,剩余决策树删除;
3)计算保留决策树中,各个决策树之间的相似度;
4)将相似度大于相似度阈值的决策树进行聚类,获得优化后随机森林预测模型。
假设测试集中包括m组数据,决策树将会得到m个预测结果,将决策树预测结果两两对比得到n个相同的预测结果,定义两棵树的相似度为n/m,如果相似度超过指定阈值,则两棵决策树相似,将相似的决策树使用聚类方法划分为一类,降低树的规模,既保证准确率又保证不会过拟合。
s305,使用验证集对优化后随机森林预测模型进行验证,获得最终随机森林预测模型;
该步骤通过验证集验证优化后随机森林预测模型的预测准确率,若预测准确率超过准确率阈值,则将该优化后随机森林预测模型作为最终随机森林预测模型;否则继续对原始随机森林预测模型进行优化。
通过上述步骤s301-305确定出最终的随机森林预测模型,且该模型经验证准确率较高,在深度学习训练任务时,在提交任务后将相关参数输入最终随机森林预测模型,进行是否触发告警的预测。
实施例二
如图3所示,基于实施例一,本实施例提供一种人工智能训练平台的告警预测装置,包括以下功能模块。
数据收集模块101:收集历史训练任务配置参数及对应配置参数下任务训练过程中的任务异常状态;
数据集组成模块102:将配置参数和任务异常状态组成数据集;
模型训练模块103:通过随机森林算法对数据集进行训练,获得随机森林预测模型;
结果预测模块104:训练任务时,提交任务后通过所获得的随机森林预测模型预测任务训练过程中是否会出现任务异常。
其中,数据收集模块101所收集配置参数包括镜像大小、训练任务数据集大小、cpu个数、gpu个数、gpu型号、模型的神经网络层数、模型的单次处理图片数、模型的迭代次数。
模型训练模块103包括以下功能单元以获得较优的随机森林预测模型。
数据划分单元:从数据集提取出部分数据作为验证集,剩余数据通过十折交叉验证法将剩余数据划分为训练集和测试集;
模型训练单元:使用训练集通过随机森林算法进行训练,生成原始随机森林预测模型;
模型优化单元:使用测试集对原始随机森林预测模型进行优化,获得优化后随机森林预测模型;
模型确定单元:使用验证集对优化后随机森林预测模型进行验证,获得最终随机森林预测模型。
以上公开的仅为本发明的优选实施方式,但本发明并非局限于此,任何本领域的技术人员能思之的没有创造性的变化,以及在不脱离本发明原理前提下所作的若干改进和润饰,都应落在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!