一种基于生成对抗网络的侧脸图片生成正脸图片的方法
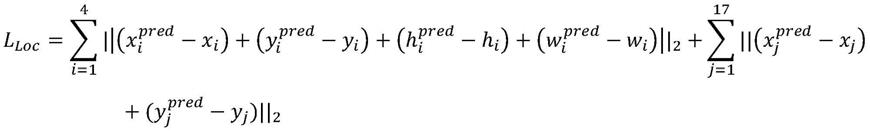
1.本发明涉人脸生成技术领域,尤其涉及一种基于生成对抗网络的侧脸图片生成正脸图片的方法。
背景技术:
2.当前人脸识别系统以及人脸数据库都是以正脸图片作为标准数据,因此经过训练后的人脸识别模型对正脸的识别度有较好的表现,但是对输入为侧脸的数据表现极差。而在现实生活中,摄像头所捕获的数据多数为侧脸数据,无法直接应用于人脸识别系统。特别是对于安防领域或是智能家居领域。对于前者而言,公共场所会部署大量的摄像头用于搜寻、记录犯罪份子,而犯罪份子会刻意的躲避摄像头,使得摄像头无法捕获或者仅仅捕获到他的侧脸,而安防系统中的人脸识别模块可能会忽略掉侧脸数据;同样的,随着智能家居领域的不断发展,越来越多的物联网设备会安装在家居环境中,出于对个人隐私保护考虑,大部分设备都会搭配人脸识别模块,如果每一个设备使用时都需要用户正面设备,这也会给用户带来极大的不便。
3.侧脸问题由于信息的缺失本身就是病态的问题,传统的方法是将侧脸数据和正脸数据同时训练,提取侧脸和正脸的公共特征,但是这一方法无法给出侧脸对应的正脸图像,只能给出侧脸的特征,特征无法输入其他成熟的人脸识别模块;另一种方法是通过侧脸数据生成正脸,这一类方法采用的是全局特征或者局部加全局特征来生成正脸图片,使用全局特征会导致生成图片的细节较差,而采用局部加全局特征训练时很容易导致局部特征无效,从而导致模型生成的图像并不能包含全部的信息。
4.综上,现阶段方法的缺陷主要包括:
5.1.基于特征提取的方法无法应用于成熟的人脸识别模块;
6.2.基于特征生成的方法会造成细节的缺失或是特征的无效。
技术实现要素:
7.针对现有技术中存在的问题,本发明提供了一种基于生成对抗网络的侧脸图片生成正脸图片的方法。
8.为实现上述目的,本发明采用的技术方案是:一种基于生成对抗网络的侧脸图片生成正脸图片的方法,具体包括以下步骤:
9.(1)收集侧脸图片和对应的正脸图片,将每张侧脸图片i
p
划分成侧脸感官图片集将对应的正脸图片i
f
划分成正脸感官图片集并标记出正脸的轮廓特征点k
f
和对应的感官位置l
f
;所述感官包括:左眼、右眼、嘴巴和鼻子;
10.(2)将侧脸图片i
p
和侧脸感官图片集分别输入生成对抗网络中,训练生成对抗网络,当判别器损失函数l
discriminator
和生成器损失函数l
generator
均收敛
时,完成对生成对抗网络的训练;
11.(3)再次收集侧脸图片,输入到训练好的生成对抗网络中,输出正脸图片。
12.进一步地,所述生成对抗网络包括感官生成器、轮廓生成器、融合网络、正脸感官位置预测网络、正脸轮廓特征点预测网络和判别器;所述感官生成器、轮廓生成器均与融合网络连接,所述融合网络与判别器连接,所述轮廓生成器分别与正脸感官位置预测网络、正脸轮廓特征点预测网络连接。
13.进一步地,所述生成对抗网络的训练过程具体包括如下步骤:
14.(2.1)将侧脸图片i
p
输入轮廓生成器中,生成预测正脸轮廓图片将侧脸感官图片集输入感官生成器中,生成预测正脸感官图片集
15.(2.2)将步骤(2.1)生成的预测正脸轮廓图片和预测正脸感官图片集输入融合网络中进行融合,生成预测正脸图片i
pred
,将预测正脸图片i
pred
输入判别器中,以判别器损失函数l
discriminator
来判断预测正脸图片i
pred
与正脸图片i
f
是否属于同一种概率分布下;
16.(2.3)将轮廓生成器中侧脸图片i
p
的高维特征作为正脸感官位置预测网络和正脸轮廓特征点预测网络的输入,输出预测正脸感官位置l
pred
和预测正脸轮廓特征点k
pred
,以生成器损失函数l
generator
来判断预测正脸感官位置l
pred
与正脸感官位置l
f
的相似度以及判断预测正脸轮廓特征点k
pred
与正脸的轮廓特征点k
f
的相似度,并且判断融合生成的正脸图片i
pred
和真实的正脸图片i
f
的相似度;
17.(2.4)将不同的侧脸图片i
p
和对应的侧脸感官图片集以及与之对应的正脸图片i
f
,正脸感官和轮廓及感官位置k
f
、l
f
输入生成对抗网络中重复步骤(2.1)
‑
(2.3),训练生成对抗网络,直至判别器损失函数l
discriminator
和生成器损失函数l
generator
均收敛时,完成对生成对抗网络的训练。
18.进一步地,所述判别器损失函数l
discriminator
为:
[0019][0020]
其中,d()为判别器,k2表示为将输入判别器的图片划分为区块的个数,g(i
p
)为生成器生成的正脸图片,为侧脸图像分布期望,为正脸图像分布期望。
[0021]
进一步地,所述生成器损失函数l
generator
为:
[0022]
l
generator
=l
pix
+λ1l
id
+λ2l
loc
+λ3l
adv
[0023]
其中,l
pix
为像素损失函数,l
id
为身份损失函数,λ1为身份损失函数对应的系数,取值为0.3;l
loc
为位置损失函数,λ2为位置损失函数对应的系数,取值为0.01;l
adv
为对抗损失函数,λ3为对抗损失函数对应的系数,取值为0.001。
[0024]
与现有技术相比,本发明具有如下有益效果:本发明的生成对抗网络中采用感官生成器和轮廓生成器,分别利用侧脸感官图片集和侧脸图片生成预测正脸感官图片集和预测正脸轮廓图片,再进一步融合成生成预测正脸图片。本发明生成正脸图片的方法通过双
路径生成器保证了脸部局部细节的存在,并通过预测感官和轮廓的位置,加速轮廓子生成器提取有效特征,通过拼接的方式保证了两种特征都能作用与结果,从而生成高质量、可用于人脸识别的图像。本发明的方法保留了局部特征和全局特征,生成正脸图片具有准确高效的特点。
附图说明
[0025]
图1是本发明基于生成对抗网络的侧脸图片生成正脸图片的方法的流程图;
[0026]
图2是本发明生成对抗网络结构图;
[0027]
图3是本发明的生成正脸图片的结果示意图。
具体实施方式
[0028]
下面结合附图对本发明的技术方案作进一步的解释说明。
[0029]
如图1是本发明基于生成对抗网络的侧脸图片生成正脸图片的方法的流程图,所述方法具体包括如下步骤:
[0030]
(1)收集侧脸图片和对应的正脸图片,将每张侧脸图片i
p
,大小为416
×
416,划分成侧脸感官图片集并且侧脸感官图片集全部缩放至64
×
64;将对应的正脸图片i
f
,大小同样为416
×
416,划分成正脸感官图片集大小同样为64
×
64,并标记正脸的轮廓特征点k
f
,大小为17
×
2,标记对应的感官位置l
f
,大小为4
×
4;每张侧脸图片i
p
对应一张正脸图片i
f
;所述感官包括:左眼、右眼、嘴巴和鼻子;
[0031]
(2)将侧脸图片i
p
、正脸图像i
f
和侧脸感官图片集正脸感官图集分别输入生成对抗网络中,训练生成对抗网络,当判别器损失函数l
discriminator
和生成器损失函数l
generator
均收敛时,完成对生成对抗网络的训练;具体包括如下子步骤:
[0032]
(2.1)构建双生成器的生成对抗网络,所述生成对抗网络如图2所示,包括感官生成器、轮廓生成器、融合网络、正脸感官位置预测网络、正脸轮廓特征点预测网络和判别器;所述感官生成器、轮廓生成器均与融合网络连接,所述融合网络与判别器连接,所述轮廓生成器分别与正脸感官位置预测网络、正脸轮廓特征点预测网络连接。本发明中的感官生成器和轮廓生成器均采用res
‑
unet结构。该方法使用两个生成器,两个生成器分别对应不同的功能,能够更好的提取人脸不同程度的特征,在更好的保留细节的同时也能够提取的人脸的轮廓特征,从而保证生成高质量的图片。
[0033]
(2.2)将侧脸图片i
p
输入轮廓生成器中,生成预测正脸轮廓图片将侧脸感官图片集输入感官生成器中,生成预测正脸感官图片集
[0034]
(2.3)将步骤(2.2)生成的预测正脸轮廓图片和预测正脸感官图片集
输入融合网络中进行融合,生成预测正脸图片i
pred
,将预测正脸图片i
pred
输入判别器中,以判别器损失函数l
discriminator
来判断预测正脸图片i
pred
与正脸图片i
f
是否属于同一种概率分布下,即p(i
pred
)和p(i
f
)是否近似,此处p表示为概率,所述判别器损失函数l
discriminator
为:
[0035][0036]
其中,d()为判别器,k2表示为将输入判别器的图片划分为区块的个数,g(i
p
)为生成器生成的正脸图片,为侧脸图像分布期望,为正脸图像分布期望
[0037]
(2.4)将轮廓生成器中侧脸图片i
p
的高维特征作为正脸感官位置预测网络和正脸轮廓特征点预测网络的输入,输出预测正脸感官位置l
pred
和预测正脸轮廓特征点k
pred
,以生成器损失函数l
generator
来判断预测正脸感官位置l
pred
与正脸感官位置l
f
的相似度以及判断预测正脸轮廓特征点k
pred
与正脸的轮廓特征点k
f
的相似度;所述生成器损失函数l
generator
为:
[0038]
l
generator
=l
pix
+λ1l
id
+λ2l
loc
+λ3l
adv
[0039]
其中,l
pix
为像素损失函数,l
id
为身份损失函数,λ1为身份损失函数对应的系数,取值为0.3;l
loc
为位置损失函数,λ2为位置损失函数对应的系数,取值为0.01;l
adv
为对抗损失函数,λ
v
为对抗损失函数对应的系数,取值为0.001。
[0040][0041][0042][0043][0044]
其中,w表示输入图像的宽,h表示输入图像的高,n为一个batch的图像对大小,为输入的侧脸图像,为生成器生成的正脸图像,为预测感官右上角坐标,(x
i3
,y
i
)为感官右上角真实坐标,为预测高宽,(h
i
,w
i
)为真实高宽,为轮廓特征点坐标,(x
j
,y
j
)为轮廓特征点真实坐标,为预测人脸身份特征,为真实人脸身份特征,为预测人脸像素点值,为真实人脸像素点值。输入输出人脸图片的大小为416
×
416
×
3。
[0045]
(2.5)将不同的侧脸图片i
p
和对应的侧脸感官图片集输入生成对抗网络中重复步骤(2.2)
‑
(2.4),训练生成对抗网络,直至判别器损失函数l
discriminator
和生成器损失函数l
generator
均收敛时,完成对生成对抗网络的训练。通过判别器损失函数,保证了生成的人脸图像和真实的人脸图像处于同一种分布下,通过生成器损失函数保证了生成预测正脸图像与真实的正脸图像尽可能的相似。
[0046]
(3)再次收集侧脸图片,输入到训练好的生成对抗网络中,输出正脸图片。
[0047]
本发明将生成的预测正脸感官图片集和预测正脸轮廓图片直接进行融合生成预测正脸图片,而不是使用感官特征和轮廓特征,这避免了某一特征失效,从而生成高质量的预测正脸图片。通过预测感官的位置来帮助融合网络将感官和正脸轮廓进行拼接,这也能更好的生成预测正脸图片。通过预测感官损失和正脸轮廓特征点的位置加速子生成器更快的找到侧脸和正脸的公共特征子空间,从而更好的提取有用的特征。
[0048]
因此,本发明通过设计侧脸生成正脸的生成对抗网络,充分挖掘侧脸和正脸之间的相关特征,并且生成预测正脸图片,极大的提高了侧脸识别的准确率,并且生成的预测正脸图片能够直接接入现有的人脸识别模块,极大的扩展了人脸识别应用的可用范围。
[0049]
如图3,给出了不同角度下的侧脸图片生成正脸图片的效果图,通过本发明的方法将侧脸图片生成正脸图片,生成的正脸图片与真实的正脸图片基本相同,说明该方法具有鲁棒性,在不同角度的情况下都能够生成真实正脸相似的正脸图像;同时图3给出了用不同用户的侧脸图片生成正脸图片的效果图,生成的正脸图片与真实的正脸图片一致,说明本发明的方法具有普遍适用性。
[0050]
上述实施方式并非是对本发明的限制,本发明也并不仅限于上述举例,本技术领域的技术人员在本发明的技术方案范围内所做出的变化、改型、添加或替换,也均属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1