一种基于视觉Transformer的高空坠物检测方法与流程
本发明涉及图像识别技术,尤其是一种基于视觉transformer的高空坠物检测方法。
背景技术:
随着高楼大厦越建越多,高空坠物的危害也日益凸显,新闻报道中发生的高空坠物事件也在呈递增趋势,由于高空坠物存在很大的危害,严重威胁过路行人的生命安全,因此对于高空坠物的及时检测十分重要。目前常规的检测方法通常是先检测画面中的物体,然后对多帧图像中的同一物体进行跟踪,最后通过物体在每一帧里的位置拟合的轨迹来判断是否为抛物,该方法集成了目标检测、目标跟踪和轨迹判断等算法。其中,目标检测算法大概可以分为两类,一类基于传统的图像处理算法,例如帧差法、光流法、背景建模法等,一般通过前景和背景的差异来检测物体;另一类基于深度学习算法,一般通过不同的深度学习检测网络,如yolo、ssd等来快速准确地检出画面中的物体。在检测到运动物体后,结合聚类、特征匹配、匈牙利算法和卡尔曼滤波算法等方法对检测出的物体进行跟踪,最后判断物体运动轨迹是否符合预设的坠物规律。上述两种物体检测算法均存在一定的缺陷,其中基于传统的图像处理算法鲁棒性较低,容易受到外界因素如光照、噪声、清晰度等的干扰,产生较大的漏检和误检,且通常很耗费计算资源,也很难满足实时性的需求;而使用深度检测网络做目标检测,虽然能够较大地提升检测准确率,但是在跟踪和轨迹判断阶段,分步进行的高空抛物检测算法只有在获得完整的物体轨迹后才能判断出是否为坠落物体,使得检测具有一定的滞后性,此外,物体检测和跟踪的误差会直接叠加到轨迹判断中,非常影响算法的准确率。
transformer是google的团队在2017年提出的一种用于自然语言处理(nlp)的经典模型,用于处理nlp中常见的序列信号。与顺序处理序列信号的循环神经网络(rnn)相比,它使用了self-attention机制,使得模型可以对序列信号进行并行化处理,并拥有全局信息,可以快速地对序列进行处理。facebookai在2020年将其引入了视觉领域,提出了一种基于transformer的目标检测网络detr,该网络摒弃了把目标检测问题构建为锚点分类和回归的思路,把目标检测看作是目标集合预测问题,实现了端对端的目标检测方式,同时,论文也验证了transformer在图像分割领域的有效性。其后,transformer又被引入到目标跟踪、图像合成等领域,并且都取得了较好的效果。
鉴于此提出本发明。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种基于视觉transformer的高空坠物检测方法,实现将检测、跟踪与坠物判断在深度神经网络中进行结合,输入视频后,经过网络的一次计算即可得到结果,提高检测速度和精准性。
为了实现该目的,本发明采用如下技术方案:
一种基于视觉transformer的高空坠物检测方法,包括以下步骤:
步骤s1:获取需要监控区域的视频图像;
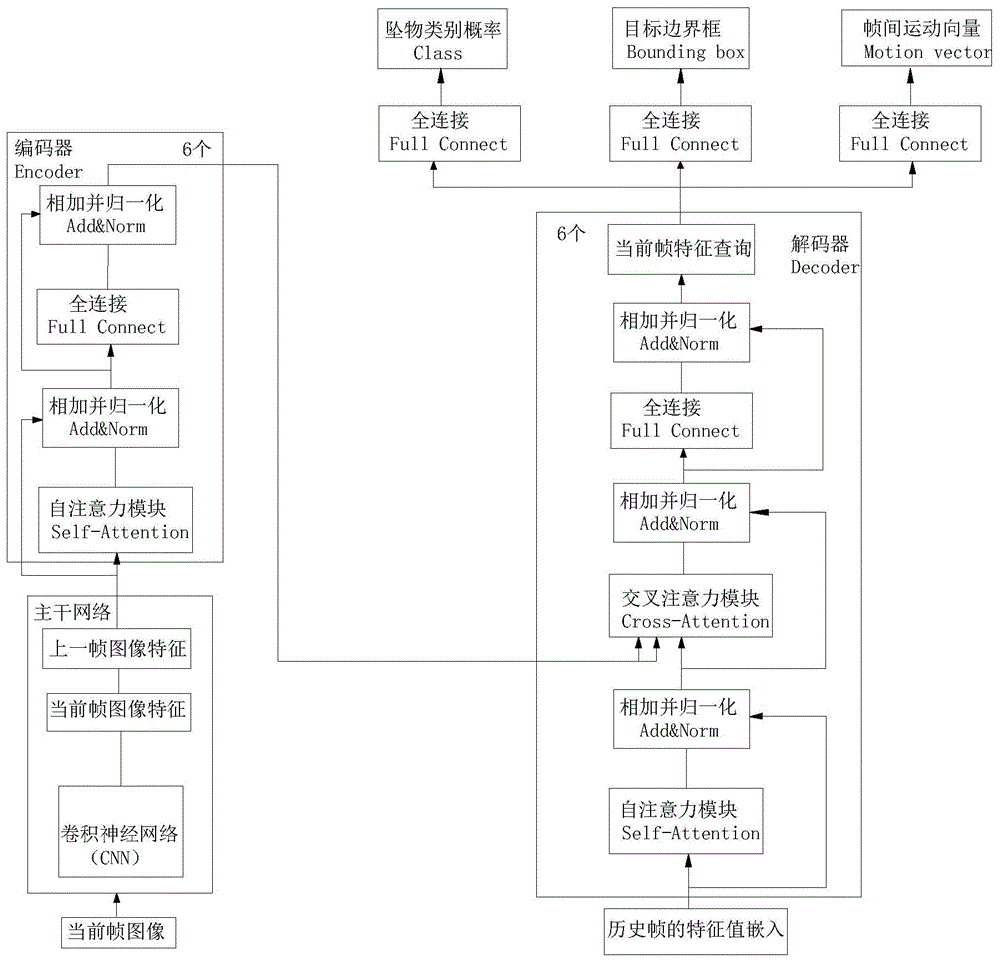
步骤s2:根据获取的视频图像,利用卷积神经网络提取当前帧的特征,并与上一帧提取的特征进行拼接;
步骤s3:将拼接后的特征输入编码器,每个编码器由一个带自注意力模块self-attention的残差结构和带全连接网络的残差结构组成,特征经过多个编码器的计算后,将计算结果分别输入多个解码器中进行后续的运算;
步骤s4:将历史帧的特征值嵌入输入到解码器的self-attention残差结构中,得到的输出会和步骤s3的输出一起输入到解码器的cross-attention残差结构中共同计算,实现编码器的输出与历史帧的特征值之间的关联;所述历史帧的特征值嵌入由解码器的历史输出通过滑动平均的方式计算得到,计算公式为:
et=β·et-1+(1-β)·qt-1
其中:qt-1为上一帧的解码器输出,β为一常数,且小于1;
步骤s5:将编码器运算得到的最后一个序列分别输入到三个全连接网络中,并分别计算出物体为坠物的类别概率、目标边界框以及物体的帧间运动向量;
步骤s6:根据计算出的坠物类别概率识别出坠落物体,并根据帧间运动向量和目标边界框,通过贪心匹配算法,对识别出的坠落物体进行跟踪,生成跟踪轨迹,并发出报警提示。
进一步,在步骤s2中,当首次提取当前帧时,由于不存在上一帧图像,因此,该步骤第一次执行时,只将第一帧图像输入卷积神经网络提取特征后保存,而不执行后续操作,首次提取的第一帧特征在下一循环中将作为上一帧图像特征进行处理。
进一步,在步骤s2中,所述拼接的过程是将两个尺寸为w×h×c的特征图在通道方向上进行拼接,最终获得尺寸为w×h×2c的特征图,所述w代表宽度、h代表高度、c代表通道。
进一步,所述步骤s3还包括,在将拼接后的特征输入编码器前,先将拼接后的特征通过256个1×1大小的卷积核实现通道压缩,之后再输入到编码器中。
进一步,在步骤s4中,所述历史帧的特征值嵌入的维度为100×256,所述编码器和解码器的数量均为6个,经过解码器计算后得到6个100×256的序列;所述类别概率、目标边界框以及物体的帧间运动向量的维度分别为100×2、100×4和100×2。
进一步,还包括模型训练过程,在执行步骤s1之前,先进行模型训练,以提高检测精度,所述模型训练包括以下步骤:
步骤a1:制作训练视频,所述训练视频包括收集的真实坠物视频和可选择性的增加部分合成的高空坠物视频;
步骤a2:采用mot的标注方式对训练视频进行标注,包括一个视频中的物体框和同一物体的编号;
步骤a3:设计损失函数,所述损失函数包含三个部分,一个是用于分类的focalloss,一个是目标框坐标的l1和generalizediou损失,最后一个是跟踪信息的运动向量的l1损失;
损失函数的公式为:l=λcls·lcls+λbbox·lbbox+λgiou·lgiou+λmotion·lmotion
其中,lcls是focalloss分类损失,lbbox是目标框坐标的l1损失,lgiou是目标框坐标的generalizediou损失,lmotion是运动向量的l1损失,λcls、λbbox、λgiou、λmotion分别为不同损失所占的权重。
步骤a4、在开源的深度学习框架pytorch上,导入步骤a2中的视频图片集并使用网络模型进行推理得到相应输出;
步骤a5、使用步骤a3中的损失函数计算a4的网络输出和对应数据集标注内容的损失值;
步骤a6、以最小化损失值为目标,重复步骤a4和a5,使用pytorch框架不断迭代网络模型参数;
步骤a7、当损失值下降不再明显时,停止训练,获得训练后的检测模型。
进一步,所述步骤a3也可以在步骤a1或步骤a2之前执行,λcls、λbbox、λgiou、λmotion的经验取值分别为0.3,0.3,0.2,0.2。
进一步,所述步骤a4中的网络结构部分,主干网络采用resnet50的imagenet预训练模型提取图片特征,transformer中的dropoutrate为0.1,transformer的权重初始化方式为xavier初始化,空间位置编码采用的是原始transformer中用到的2d模式。
进一步,所述步骤a6中,网络模型中的超参数设计部分,采用adamw优化器,权重损失设为10-4,初始学习率为10-3,训练100个epoch衰减1/10。
采用本发明所述的技术方案后,带来以下有益效果:
本发明基于视觉transformer模型,是一种端对端的实时检测方法,可以关注全局信息,避免了多阶段检测步骤中误差累积的问题,采用自注意力模块可以建立更长距离的依赖关系,因此非常适合挖掘视频帧间信息,而利用长时间的帧间关联信息可以有效提高检测精度,本发明实现了将目标检测、跟踪和坠物判断在同一个网络中实现,具有较高的检测精度,并且检测速度快,可以及时对坠落物体进行识别检测,并发出报警提示。
附图说明
图1:本发明的网络结构图。
具体实施方式
下面结合附图对本发明的具体实施方式作进一步详细的描述。
结合图1所示,一种基于视觉transformer的高空坠物检测方法,主要包括以下步骤:
步骤s1:获取需要监控区域的视频图像;
步骤s2:根据获取的视频图像,利用卷积神经网络(cnn)提取当前帧的特征,并与上一帧提取的特征进行拼接;
步骤s3:将拼接后的特征输入编码器(encoder),并经过多个编码器计算后,将计算结果输入解码器(decoder),每个编码器由带有自注意力模块self-attention的残差结构和带全连接网络的残差结构组成,特征经过多个编码器的计算后,将计算结果分别输入多个解码器中进行后续的运算;
步骤s4:将历史帧的特征值嵌入(historyfeatureembedding)输入到解码器的self-attention残差结构中,得到的输出会和步骤s3的输出一起输入到解码器的cross-attention残差结构中共同计算,实现编码器的输出与历史帧的特征值之间的关联,所述历史帧的特征值嵌入由解码器的历史输出通过滑动平均的方式计算得到,计算公式为:
et=β·et-1+(1-β)·qt-1
其中:qt-1为上一帧的解码器输出,β为一常数,且小于1;
步骤s5:将编码器运算得到的最后一个序列分别输入到三个全连接网络中,并分别计算出物体为坠物的类别概率(class)、目标边界框(boundingbox)以及物体的帧间运动向量(motionvector);
步骤s6:根据计算出的坠物类别概率识别出坠落物体,并根据帧间运动向量和目标边界框,通过贪心匹配算法,对识别出的坠落物体进行跟踪,生成跟踪轨迹,并发出报警提示。
具体地,所述步骤s1中,所述视频图像可以通过布置监控摄像头进行获取,所述摄像头应布置在远离树木和遮挡物的位置,并应使监控画面尽量覆盖整个楼面,所述摄像头优选为广角摄像头。
具体地,所述步骤s2中,当首次提取当前帧时,由于不存在上一帧图像,因此,该步骤第一次执行时,只将第一帧图像输入卷积网络提取特征后保存,而不执行后续的操作,首次提取的第一帧特征在下一循环中将作为上一帧图像进行处理。所述拼接的过程是将两个尺寸为w×h×c的特征图(featuremap)在通道(channel)方向上进行拼接,最终获得尺寸为w×h×2c的特征图,进行拼接的目的是同步提取视频前后两帧之间的时域特征信息,便于对运动物体进行跟踪。所述w代表宽度、h代表高度、c代表通道,优选w取值25,h取值38,c取值1024。
具体地,所述步骤s3中,还包括在将拼接后的特征输入编码器前,先将拼接后的特征通过256个1×1大小的卷积核实现通道压缩,压缩后的特征通道变为256,用以减小计算的数据量。之后再输入到编码器中进行计算,所述编码器的功能是利用带自注意力模块self-attention的残差结构,可以模拟对此前提取的相邻帧特征的重点区域进行处理,使得重点区域所占的权重更大,更有利于提取目标信息。
具体地,在步骤s4中,所述历史帧的特征值嵌入的维度为100×256,由于历史帧中包含有大量信息,在解码器运算中,通过挖掘当前帧与历史帧之间的关联信息,可以为后续步骤中实现坠落目标的检测、跟踪和判断提供依据,在该步骤中,通过滑动平均的计算公式,可以体现出在时间轴上,越靠近当前帧的历史输出,与当前帧的关系越紧密,所以占的权重也越大,该历史帧的特征值嵌入的初始值e0通过训练得到,所述β的取值优选为0.7。
具体地,所述步骤s5中,经过多个编码器运算后,将获得多个序列,将最后一个序列分别输入到三个全连接网络中,每个全连接网络的结构和参数不同,以根据输入获得相应物体为坠物的类别概率、目标边界框以及物体的帧间运动向量,所述坠物类别概率用于判断是否为坠落物,当概率值大于设定阈值0.5时,则判断物体为坠物,所述目标边界框用于标注坠落物的坐标,所述帧间运动向量用于标注坠落物的运动方向。
优选地,所述编码器和解码器的数量均为6个,经过解码器计算后得到6个100×256的序列,所述坠物类别概率、目标边界框以及物体的帧间运动向量的维度分别为100×2、100×4和100×2,重复叠加编码器是为了加大处理力度。
具体地,所述步骤s6中生成的轨迹可以用于对坠落物进行溯源,所述贪心匹配算法用于将目标边界框和帧间运动向量进行关联,假设前后帧提取到的坠物目标边界框的个数分别为m和n个,那么根据物体中心坐标点一共可以组合成m×n个向量,分别计算这些向量与步骤s5中求出的k个帧间运动向量之间的欧氏距离,即可筛选出k对同一物体在前后帧上的体现,实现物体的跟踪。
为提高本发明方法的检测精度,所述基于视觉transformer的高空坠物检测方法,还包括模型训练过程,在执行步骤s1之前,先进行模型训练,以提高检测精度,所述模型训练包括以下步骤:
步骤a1:制作训练视频,所述训练视频包括收集的真实坠物视频和可选择性的增加部分合成的高空坠物视频;
步骤a2:采用mot的标注方式对训练视频进行标注,包括一个视频中的物体框和同一物体的编号;
步骤a3:设计损失函数,所述损失函数包含三个部分,一个是用于分类的focalloss,一个是目标框坐标的l1和generalizediou损失,最后一个是跟踪信息的运动向量的l1损失;
损失函数的公式为:l=λcls·lcls+λbbox·lbbox+λgiou·lgiou+λmotion·lmotion
其中,lcls是focalloss分类损失,lbbox是目标框坐标的l1损失,lgiou是目标框坐标的generalizediou损失,lmotion是运动向量的l1损失,λcls、λbbox、λgiou、λmotion分别为不同损失所占的权重。
步骤a4、在开源的深度学习框架pytorch上,导入步骤a2中的视频图片集并使用网络模型进行推理得到相应输出;
步骤a5、使用步骤a3中的损失函数计算a4的网络输出和对应数据集标注内容的损失值;
步骤a6、以最小化损失值为目标,重复步骤a4和a5,使用pytorch框架不断迭代网络模型参数;
步骤a7、当损失值下降不再明显时,停止训练,获得训练后的检测模型。
具体地,所述步骤a3中,l1损失通过计算模型预测值和数据集真实值的l1范数求得,generalizediou损失通过计算模型的预测框和数据集真实框的面积交并比求得.
在其他实施例中,所述步骤a3也可以在步骤a1或步骤a2之前执行。
由于深度学习方法需要使用特定的数据集来训练网络参数,而高空坠物的真实数据集又难以采集,因此在步骤a1中,本发明通过合成的方式来生成高空坠物视频,并结合一部分自己采集的普通高度下的真实坠物视频来构造训练数据集。合成的训练视频需要考虑的变量主要有:坠物轨迹、光照、不同背景、树叶飞鸟等干扰、物体类型和大小等,结合这些变量,采集不同角度仰拍的楼栋图片作为背景,通过加噪、改变亮度来模拟不同的视频质量,根据随机生成的坠物轨迹,从物体图片底库中随机选择一个并粘贴到轨迹位置来合成训练集,并适当加入一些非坠物的物体作为干扰。生成的视频占训练集数量的70%左右。剩下的30%视频是在普通高度,日常背景下拍摄的一些坠物视频。训练视频采用mot的标注方式,训练集数量为60个,每个视频包含300帧图片。
具体地,所述步骤a4中的网络结构部分,主干网络采用resnet50的imagenet预训练模型提取图片特征,transformer中的dropoutrste为0.1,transformer的权重初始化方式为xavier初始化,空间位置编码采用的是原始transformer中用到的2d模式。
具体地,所述步骤a6中,网络模型中的超参数设计部分,采用adamw优化器,权重损失设为10-4,初始学习率为10-3,训练100个epoch衰减1/10。
综上所述,本发明的一种基于视觉transformer的高空坠物检测方法,首先利用卷积神经网络(cnn)提取视频的图像空域特征,然后引入nlp领域中的transformer网络结构用于提取时域特征,用编码器提取相邻帧之间的运动信息,再结合解码器和滑动平均融合连续多帧之间的轨迹信息,将检测、跟踪和坠物判断融入到一个网络中,实现端对端的检测物体位置、运动向量和是否为坠物,并进一步利用物体位置信息和运动向量,结合贪心算法,可以实现坠落物体的跟踪。在监控终端或后台部署该检测模型,可以实时对监控视频进行检测,在出现坠物情况时及时发出预警。
本发明将transformer技术应用到坠物检测中,能够深入挖掘视频的帧间信息,解决传统多阶段坠物检测方法中存在的滞后性和误检率高的问题,并且采用合成数据的方式训练模型,解决了坠物检测问题中数据稀缺的问题。
以上所述为本发明的实施方式,应当指出,对于本领域的普通技术人员而言,在不脱离本发明原理前提下,还可以做出多种变形和改进,这也应该视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!