神经网络电路的控制方法与流程
1.本发明涉及神经网络电路的控制方法。本技术基于2020年04月13日在日本技术的特愿2020-071933号主张优先权,在此引用其内容。
背景技术:
2.近年来,卷积神经网络(convolutional neural network:cnn)被用作图像识别等的模型。卷积神经网络为具有卷积层、池化层的多层构造,需要卷积运算等大量运算。已设计了各种使基于卷积神经网络的运算高速化的运算方法(专利文献1等)。
3.现有技术文献
4.专利文献
5.专利文献1:日本特开2018-077829号公报
技术实现要素:
6.发明所要解决的技术课题
7.另一方面,期望在iot(物联网)设备等嵌入式设备中也实现利用卷积神经网络的图像识别等。在嵌入式设备中,难以嵌入专利文献1等记载的大规模专用电路。另外,在cpu、存储器等硬件资源受限的嵌入式设备中,仅利用软件难以充分实现卷积神经网络的运算性能。
8.鉴于上述情况,本发明的目的在于提供能够使可嵌入于iot设备等嵌入式设备的神经网络电路高性能地工作的神经网络电路的控制方法。
9.用于解决技术课题的技术方案
10.为了解决上述技术课题,本发明提出以下方案。
11.关于本发明的第一方案的神经网络电路的控制方法,所述神经网络电路具备:第一存储器,保存输入数据;卷积运算电路,对保存于所述第一存储器的所述输入数据进行卷积运算;第二存储器,保存所述卷积运算电路的卷积运算输出数据;量化运算电路,对保存于所述第二存储器的所述卷积运算输出数据进行量化运算;第二写入信号量(semaphore),限制由所述卷积运算电路对所述第二存储器的写入;第二读取信号量,限制由所述量化运算电路从所述第二存储器的读取;第三写入信号量,限制由所述量化运算电路对所述第一存储器的写入;以及第三读取信号量,限制由所述卷积运算电路从所述第一存储器的读取,在所述神经网络电路的控制方法中,基于所述第三读取信号量及所述第二写入信号量,使所述卷积运算电路实施所述卷积运算。
12.发明效果
13.本发明的神经网络电路的控制方法能够使可嵌入于iot设备等嵌入式设备的神经网络电路高性能地工作。
附图说明
14.图1为示出卷积神经网络的图。
15.图2为说明卷积层进行的卷积运算的图。
16.图3为说明卷积运算的数据的展开的图。
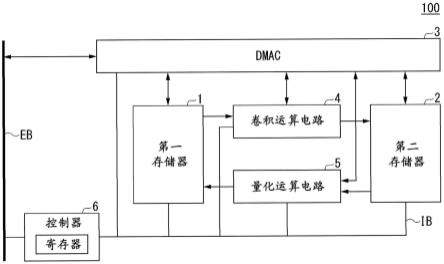
17.图4为示出第一实施方式的神经网络电路的整体结构的图。
18.图5为示出该神经网络电路的工作例的时序图。
19.图6为示出该神经网络电路的其它工作例的时序图。
20.图7为该神经网络电路的dmac的内部框图。
21.图8为该dmac的控制电路的状态转变图。
22.图9为该神经网络电路的卷积运算电路的内部框图。
23.图10为该卷积运算电路的乘法运算器的内部框图。
24.图11为该乘法运算器的积和运算单元的内部框图。
25.图12为该卷积运算电路的累加器电路的内部框图。
26.图13为该累加器电路的累加器单元的内部框图。
27.图14为该神经网络电路的量化运算电路的内部框图。
28.图15为该量化运算电路的矢量运算电路和量化电路的内部框图。
29.图16为运算单元的框图。
30.图17为该量化电路的矢量量化单元的内部框图。
31.图18为说明基于信号量对该神经网络电路的控制的图。
32.图19为第一数据流的时序图。
33.图20为第二数据流的时序图。
34.图21为说明卷积运算实施命令的图。
35.图22为示出卷积运算命令的具体例的图。
36.图23为说明量化运算实施命令的图。
37.图24为说明dma转发实施命令的图。
38.附图标记
39.200:卷积神经网络;100:神经网络电路(nn电路);1:第一存储器;2:第二存储器;3:dma控制器(dmac);4:卷积运算电路;42:乘法运算器;43:累加器电路;5:量化运算电路;52:矢量运算电路;53:量化电路;6:控制器;61:寄存器;s:信号量;f1:第一数据流;f2:第二数据流;f3:第三数据流
具体实施方式
40.(第一实施方式)
41.参照图1至图24对本发明的第一实施方式进行说明。
42.图1为示出卷积神经网络200(以下称为“cnn 200”)的图。第一实施方式的神经网络电路100(以下称为“nn电路100”)进行的运算为推理时使用的学习完毕的cnn 200的至少一部分。
43.[cnn 200]
[0044]
cnn 200为包括进行卷积运算的卷积层210、进行量化运算的量化运算层220和输
出层230的多层构造的网络。在cnn 200的至少一部分中,卷积层210与量化运算层220交替连结。cnn 200为广泛用于图像识别、动态图像识别的模型。cnn 200可以还具有全连接层等具有其它功能的层(layer)。
[0045]
图2为说明卷积层210进行的卷积运算的图。
[0046]
卷积层210对输入数据a进行使用权重w的卷积运算。卷积层210进行以输入数据a和权重w为输入的积和运算。
[0047]
对卷积层210的输入数据a(也称为激活数据、特征图)为图像数据等多维数据。在本实施方式中,输入数据a为由元素(x,y,c)构成的三维张量。cnn 200的卷积层210对低位的输入数据a进行卷积运算。在本实施方式中,输入数据a的元素为2位无符号整数(0,1,2,3)。输入数据a的元素也可以为例如4位或8位无符号整数。
[0048]
在输入至cnn 200的输入数据为例如32位浮点类型等形式与对卷积层210的输入数据a不同的情况下,cnn 200可以还具有输入层,该输入层在卷积层210之前进行类型变换、量化。
[0049]
卷积层210的权重w(也称为滤波器、卷积核)为具有作为能够学习的参数的元素的多维数据。在本实施方式中,权重w为由元素(i,j,c,d)构成的4维张量。权重w具有d个由元素(i,j,c)构成的三维张量(以后称为“权重wo”)。学习完毕的cnn 200中的权重w为学习完毕的数据。cnn 200的卷积层210使用低位的权重w进行卷积运算。在本实施方式中,权重w的元素为1位带符号整数(0,1),值“0”表示+1,值“1”表示-1。
[0050]
卷积层210进行式1所示的卷积运算,将输出数据f输出。在式1中,s表示步幅(stride)。在图2中以虚线所示的区域示出对输入数据a应用权重wo的区域ao(以后称为“应用区域ao”)之一。应用区域ao的元素以(x+i,y+j,c)来表示。
[0051]
[数学式1]
[0052][0053]
量化运算层220对卷积层210输出的卷积运算的输出实施量化等。量化运算层220具有池化层221、批量归一化(batch normalization)层222、激活函数层223和量化层224。
[0054]
池化层221对卷积层210输出的卷积运算的输出数据f实施平均池化(式2)、max池化(式3)等运算,对卷积层210的输出数据f进行压缩。在式2及式3中,u表示输入张量,v表示输出张量,t表示池化区域的大小。在式3中,max为输出u关于t中含有的i与j的组合的最大值的函数。
[0055]
[数学式2]
[0056][0057]
[数学式3]
[0058]
v(x,y,c)=max(u(t
·
x+i,t
·
y+j,c)),i∈t,j∈t......(式3)
[0059]
批量归一化层222利用例如式4所示的运算对量化运算层220、池化层221的输出数据进行数据分布的归一化。在式4中,u表示输入张量,v表示输出张量,α表示尺度(scale),β表示偏置(bias)。在学习完毕的cnn 200中,α及β为学习完毕的常数矢量。
[0060]
[数学式4]
[0061]
v(x,y,c)=α(c)
·
(u(x,y,c)-β(c))......(式4)
[0062]
激活函数层223对量化运算层220、池化层221、批量归一化层222的输出进行relu(式5)等激活函数的运算。在式5中,u为输入张量,v为输出张量。在式5中,max为输出自变量当中的最大数值的函数。
[0063]
[数学式5]
[0064]
v(x,y,c)=max(0,u(x,y,c))......(式5)
[0065]
量化层224基于量化参数,对池化层221、激活函数层223的输出进行例如式6所示的量化。式6所示的量化将输入张量u减位至2位。在式6中,q(c)为量化参数的矢量。在学习完毕的cnn 200中,q(c)为学习完毕的常数矢量。式6中的不等号“≤”也可以为“<”。
[0066]
[数学式6]
[0067][0068]
输出层230为利用恒等函数、归一化指数函数(softmax函数)等输出cnn 200的结果的层。输出层230的前级的层可以为卷积层210,也可以为量化运算层220。
[0069]
在cnn 200中,量化后的量化层224的输出数据被输入至卷积层210,因此与不进行量化的其它卷积神经网络相比较,卷积层210的卷积运算的负荷小。
[0070]
[卷积运算的分割]
[0071]
nn电路100将卷积层210的卷积运算(式1)的输入数据分割为部分张量来运算。分割成部分张量的分割方法、分割数量没有特别限制。部分张量例如通过将输入数据a(x+i,y+j,c)分割为a(x+i,y+j,co)来形成。此外,nn电路100也能够不对卷积层210的卷积运算(式1)的输入数据进行分割而进行运算。
[0072]
在卷积运算的输入数据分割中,如式7所示,式1中的变量c按照尺寸bc的块来分割。另外,如式8所示,式1中的变量d按照尺寸bd的块来分割。在式7中,co为偏移量,ci为0至(bc-1)的索引。在式8中,do为偏移量,di为0至(bd-1)的索引。此外,可以是尺寸bc与尺寸bd相同。
[0073]
[数学式7]
[0074]
c=co
·
bc+ci......(式7)
[0075]
[数学式8]
[0076]
d=do
·
bd+di......(式8)
[0077]
式1中的输入数据a(x+i,y+j,c)在c轴方向上按照尺寸bc被分割,用分割后的输入数据a(x+i,y+j,co)来表示。在以后的说明中,也将分割后的输入数据a称为“分割输入数据a”。
[0078]
式1中的权重w(i,j,c,d)在c轴方向上按照尺寸bc被分割并且在d轴方向上按照尺寸bd被分割,用分割后的权重w(i,j,co,do)来表示。在以后的说明中,也将分割后的权重w称为“分割权重w”。
[0079]
按照尺寸bd分割后的输出数据f(x,y,do)通过式9来求出。能够通过组合分割后的
输出数据f(x,y,do)来计算最终的输出数据f(x,y,d)。
[0080]
[数学式9]
[0081][0082]
[卷积运算的数据的展开]
[0083]
nn电路100将卷积层210的卷积运算中的输入数据a及权重w展开来进行卷积运算。
[0084]
图3为说明卷积运算的数据的展开的图。
[0085]
分割输入数据a(x+i,y+j,co)被展开为具有bc个元素的矢量数据。分割输入数据a的元素用ci来被索引(0≤ci<bc)。在以后的说明中,针对每个i、j被展开为矢量数据的分割输入数据a也称为“输入矢量a”。关于输入矢量a,以分割输入数据a(x+i,y+j,co
×
bc)至分割输入数据a(x+i,y+j,co
×
bc+(bc-1))作为元素。
[0086]
分割权重w(i,j,co,do)被展开为具有bc
×
bd个元素的矩阵数据。被展开为矩阵数据的分割权重w的元素用ci和di来被索引(0≤di<bd)。在以后的说明中,针对每个i、j被展开为矩阵数据的分割权重w也称为“权重矩阵w”。关于权重矩阵w,以分割权重w(i,j,co
×
bc,do
×
bd)至分割权重w(i,j,co
×
bc+(bc-1),do
×
bd+(bd-1))作为元素。
[0087]
通过将输入矢量a与权重矩阵w相乘来计算矢量数据。通过将针对每个i、j、co计算出的矢量数据整形为三维张量,能够得到输出数据f(x,y,do)。通过进行这样的数据的展开,能够利用矢量数据与矩阵数据的乘法运算来实施卷积层210的卷积运算。
[0088]
[nn电路100]
[0089]
图4为示出本实施方式的nn电路100的整体结构的图。
[0090]
nn电路100具备第一存储器1、第二存储器2、dma控制器3(以下也称为“dmac 3”)、卷积运算电路4、量化运算电路5和控制器6。nn电路100的特征在于,卷积运算电路4和量化运算电路5经由第一存储器1及第二存储器2形成为环状。
[0091]
第一存储器(第一存储器单元)1为例如由sram(static ram,静态随机存取存储器)等构成的易失性存储器等可改写的存储器。在第一存储器1中,经由dmac 3、控制器6进行数据的写入及读取。第一存储器1与卷积运算电路4的输入端口连接,卷积运算电路4能够从第一存储器1读取数据。另外,第一存储器1与量化运算电路5的输出端口连接,量化运算电路5能够将数据写入于第一存储器1。外部主机cpu能够通过对第一存储器1的数据的写入、读取来进行对nn电路100的数据的输入输出。
[0092]
第二存储器(第二存储器单元)2为例如由sram(static ram,静态随机存取存储器)等构成的易失性存储器等可改写的存储器。在第二存储器2中,经由dmac 3、控制器6进行数据的写入及读取。第二存储器2与量化运算电路5的输入端口连接,量化运算电路5能够从第二存储器2读取数据。另外,第二存储器2与卷积运算电路4的输出端口连接,卷积运算电路4能够将数据写入于第二存储器2。外部主机cpu能够通过对第二存储器2的数据的写入、读取来进行对nn电路100的数据的输入输出。
[0093]
dmac 3连接于外部总线eb,进行dram等外部存储器与第一存储器1之间的数据转发。另外,dmac 3进行dram等外部存储器与第二存储器2之间的数据转发。另外,dmac 3进行dram等外部存储器与卷积运算电路4之间的数据转发。另外,dmac 3进行dram等外部存储器与量化运算电路5之间的数据转发。
[0094]
卷积运算电路4为进行学习完毕的cnn 200的卷积层210中的卷积运算的电路。卷积运算电路4读取保存于第一存储器1的输入数据a,对输入数据a实施卷积运算。卷积运算电路4将卷积运算的输出数据f(以后也称为“卷积运算输出数据”)写入于第二存储器2。
[0095]
量化运算电路5为进行学习完毕的cnn 200的量化运算层220中的量化运算的至少一部分的电路。量化运算电路5读取保存于第二存储器2的卷积运算的输出数据f,对卷积运算的输出数据f进行量化运算(包括池化、批量归一化、激活函数及量化当中的至少量化的运算)。量化运算电路5将量化运算的输出数据(以后也称为“量化运算输出数据”)写入于第一存储器1。
[0096]
控制器6连接于外部总线eb,作为外部的主机cpu的从设备而工作。控制器6具有包括参数寄存器、状态寄存器的寄存器61。参数寄存器为对nn电路100的工作进行控制的寄存器。状态寄存器为包括信号量s的表示nn电路100的状态的寄存器。外部主机cpu能够经由控制器6访问寄存器61。
[0097]
控制器6经由内部总线ib与第一存储器1、第二存储器2、dmac3、卷积运算电路4和量化运算电路5连接。外部主机cpu能够经由控制器6对各块进行访问。例如,外部主机cpu能够经由控制器6来指示对dmac 3、卷积运算电路4、量化运算电路5的命令。另外,dmac 3、卷积运算电路4、量化运算电路5能够经由内部总线ib更新控制器6具有的状态寄存器(包括信号量s)。状态寄存器(包括信号量s)可以构成为经由与dmac 3、卷积运算电路4、量化运算电路5连接的专用布线被更新。
[0098]
nn电路100具有第一存储器1、第二存储器2等,因此在由dmac 3进行的来自dram等外部存储器的数据转发中,能够降低重复的数据的数据转发次数。据此,能够大幅降低由于存储器访问而产生的功耗。
[0099]
[nn电路100的工作例1]
[0100]
图5为示出nn电路100的工作例的时序图。
[0101]
dmac 3将层1的输入数据a保存于第一存储器1。dmac 3可以与卷积运算电路4进行的卷积运算的顺序相配合地分割层1的输入数据a并转发至第一存储器1。
[0102]
卷积运算电路4读取保存于第一存储器1的层1的输入数据a。卷积运算电路4对层1的输入数据a进行图1所示的层1的卷积运算。层1的卷积运算的输出数据f被保存于第二存储器2。
[0103]
量化运算电路5读取保存于第二存储器2的层1的输出数据f。量化运算电路5对层1的输出数据f进行层2的量化运算。层2的量化运算的输出数据被保存于第一存储器1。
[0104]
卷积运算电路4读取保存于第一存储器1的层2的量化运算的输出数据。卷积运算电路4将层2的量化运算的输出数据作为输入数据a来进行层3的卷积运算。层3的卷积运算的输出数据f被保存于第二存储器2。
[0105]
卷积运算电路4读取保存于第一存储器1的层2m-2(m为自然数)的量化运算的输出数据。卷积运算电路4将层2m-2的量化运算的输出数据作为输入数据a进行层2m-1的卷积运算。层2m-1的卷积运算的输出数据f被保存于第二存储器2。
[0106]
量化运算电路5读取保存于第二存储器2的层2m-1的输出数据f。量化运算电路5对2m-1层的输出数据f进行层2m的量化运算。层2m的量化运算的输出数据被保存于第一存储器1。
[0107]
卷积运算电路4读取保存于第一存储器1的层2m的量化运算的输出数据。卷积运算电路4将层2m的量化运算的输出数据作为输入数据a进行层2m+1的卷积运算。层2m+1的卷积运算的输出数据f被保存于第二存储器2。
[0108]
卷积运算电路4和量化运算电路5交替进行运算,推进图1所示的cnn 200的运算。在nn电路100中,卷积运算电路4通过时分方式实施层2m-1和层2m+1的卷积运算。另外,在nn电路100中,量化运算电路5通过时分方式实施层2m-2和层2m的量化运算。因此,与对每层安装各自的卷积运算电路4和量化运算电路5的情况相比较,nn电路100的电路规模小得多。
[0109]
nn电路100通过形成为环状的电路来进行作为多个层的多层构造的cnn 200的运算。nn电路100通过环状电路结构能够高效利用硬件资源。此外,在nn电路100中,为了使电路形成为环状,在各层中变化的卷积运算电路4、量化运算电路5中的参数被适当更新。
[0110]
当在cnn 200的运算中包含无法由nn电路100实施的运算时,nn电路100将中间数据转发至外部主机cpu等外部运算装置。在外部运算装置对中间数据进行运算后,外部运算装置的运算结果被输入至第一存储器1、第二存储器2。nn电路100重新进行针对外部运算装置的运算结果的运算。
[0111]
[nn电路100的工作例2]
[0112]
图6为示出nn电路100的其它工作例的时序图。
[0113]
nn电路100可以将输入数据a分割为部分张量,通过时分方式进行针对部分张量的运算。分割成部分张量的分割方法、分割数量没有特别限制。
[0114]
图6示出将输入数据a分解为两个部分张量时的工作例。将分解出的部分张量设为“第一部分张量a
1”、“第二部分张量a
2”。例如,层2m-1的卷积运算被分解为与第一部分张量a1对应的卷积运算(在图6中记载为“层2m-1(a1)”)和与第二部分张量a2对应的卷积运算(在图6中记载为“层2m-1(a2)”)。
[0115]
如图6所示,与第一部分张量a1对应的卷积运算及量化运算和与第二部分张量a2对应的卷积运算及量化运算能够独立地实施。
[0116]
卷积运算电路4进行与第一部分张量a1对应的层2m-1的卷积运算(在图6中为用层2m-1(a1)表示的运算)。之后,卷积运算电路4进行与第二部分张量a2对应的层2m-1的卷积运算(在图6中为用层2m-1(a2)表示的运算)。另外,量化运算电路5进行与第一部分张量a1对应的层2m的量化运算(在图6中为用层2m(a1)表示的运算)。像这样,nn电路100能够并行地实施与第二部分张量a2对应的层2m-1的卷积运算和与第一部分张量a1对应的层2m的量化运算。
[0117]
接下来,卷积运算电路4进行与第一部分张量a1对应的层2m+1的卷积运算(在图6中为用层2m+1(a1)表示的运算)。另外,量化运算电路5进行与第二部分张量a2对应的层2m的量化运算(在图6中为用层2m(a2)表示的运算)。像这样,nn电路100能够并行地实施与第一部分张量a1对应的层2m+1的卷积运算和与第二部分张量a2对应的层2m的量化运算。
[0118]
与第一部分张量a1对应的卷积运算及量化运算和与第二部分张量a2对应的卷积运算及量化运算能够独立地实施。因此,nn电路100例如可以并行地实施与第一部分张量a1对应的层2m-1的卷积运算和与第二部分张量a2对应的层2m+2的量化运算。即,nn电路100并行地运算的卷积运算和量化运算不限于连续的层的运算。
[0119]
通过将输入数据a分割为部分张量,nn电路100能够使卷积运算电路4和量化运算电路5并行地工作。其结果是,卷积运算电路4和量化运算电路5待机的时间被削减,nn电路100的运算处理效率提高。虽然在图6所示的工作例中分割数量为2,但在分割数量大于2的情况下也是同样地,nn电路100能够使卷积运算电路4和量化运算电路5并行地工作。
[0120]
例如,在输入数据a被分割为“第一部分张量a
1”、“第二部分张量a
2”及“第三部分张量a
3”时,nn电路100可以并行地实施与第二部分张量a2对应的层2m-1的卷积运算和与第三部分张量a3对应的层2m的量化运算。运算的顺序根据第一存储器1及第二存储器2中的输入数据a的保存状况而适当变更。
[0121]
此外,作为对于部分张量的运算方法,示出了如下例子(方法1):在用卷积运算电路4或量化运算电路5进行同一层中的部分张量的运算之后,进行下一层中的部分张量的运算。例如,如图6所示,在卷积运算电路4,在进行与第一部分张量a1及第二部分张量a2对应的层2m-1的卷积运算(在图6中为用层2m-1(a1)及层2m-1(a2)表示的运算)之后,实施与第一部分张量a1及第二部分张量a2对应的层2m+1的卷积运算(在图6中为用层2m+1(a1)及层2m+1(a2)表示的运算)。
[0122]
然而,对于部分张量的运算方法不限于此。对于部分张量的运算方法也可以为如下方法:在进行多个层中的一部分的部分张量的运算之后,实施剩余部分的部分张量的运算(方法2)。例如,在卷积运算电路4,可以在进行与第一部分张量a1对应的层2m-1及与第一部分张量a1对应的层2m+1的卷积运算之后,实施与第二部分张量a2对应的层2m-1及与第二部分张量a2对应的层2m+1的卷积运算。
[0123]
另外,对于部分张量的运算方法可以为组合方法1和方法2对部分张量进行运算的方法。不过在使用方法2时,需要根据与部分张量的运算顺序相关的依存关系来实施运算。
[0124]
接下来对nn电路100的各结构详细进行说明。
[0125]
[dmac 3]
[0126]
图7为dmac 3的内部框图。
[0127]
dmac 3具有数据转发电路31和状态控制器32。dmac 3具有针对数据转发电路31的专用的状态控制器32,当被输入命令指令时,无需外部的控制器而能够实施dma数据转发。
[0128]
数据转发电路31连接于外部总线eb,进行dram等外部存储器与第一存储器1之间的dma数据转发。另外,数据转发电路31进行dram等外部存储器与第二存储器2之间的dma数据转发。另外,数据转发电路31进行dram等外部存储器与卷积运算电路4之间的数据转发。另外,数据转发电路31进行dram等外部存储器与量化运算电路5之间的数据转发。数据转发电路31的dma通道数量不受限制。例如,可以针对第一存储器1和第二存储器2分别具有专用的dma通道。
[0129]
状态控制器32控制数据转发电路31的状态。另外,状态控制器32经由内部总线ib与控制器6连接。状态控制器32具有命令队列33和控制电路34。
[0130]
命令队列33为保存有dmac 3用的命令指令c3的队列,例如由fifo存储器构成。在命令队列33中经由内部总线ib被写入1个以上的命令指令c3。
[0131]
控制电路34为对命令指令c3进行解码并基于命令指令c3依次控制数据转发电路31的状态机。控制电路34可以利用逻辑电路来实现,也可以通过由软件控制的cpu来实现。
[0132]
图8为控制电路34的状态转变图。
[0133]
当命令指令c3被输入至命令队列33时(not empty:非空),控制电路34从空闲状态st1转变到解码状态st2。
[0134]
在解码状态st2下,控制电路34对从命令队列33输出的命令指令c3进行解码。另外,控制电路34读取保存于控制器6的寄存器61的信号量s,判定是否能够执行命令指令c3中指示的数据转发电路31的工作。在无法执行的情况下(not ready:未就绪),控制电路34等待(wait)直到能够执行。在能够执行的情况下(ready:就绪),控制电路34从解码状态st2转变到执行状态st3。
[0135]
在执行状态st3下,控制电路34控制数据转发电路31,使数据转发电路31实施命令指令c3中指示的工作。当数据转发电路31的工作结束时,控制电路34从命令队列33中移除已执行完毕的命令指令c3,并且更新保存于控制器6的寄存器61的信号量s。在命令队列33中存在命令的情况下(not empty:非空),控制电路34从执行状态st3转变到解码状态st2。在命令队列33中没有命令的情况下(empty:空),控制电路34从执行状态st3转变到空闲状态st1。
[0136]
[卷积运算电路4]
[0137]
图9为卷积运算电路4的内部框图。
[0138]
卷积运算电路4具有权重存储器41、乘法运算器42、累加器电路43和状态控制器44。卷积运算电路4具有针对乘法运算器42及累加器电路43的专用的状态控制器44,当被输入命令指令时,无需外部的控制器而能够实施卷积运算。
[0139]
权重存储器41为保存卷积运算中使用的权重w的存储器,例如为由sram(static ram,静态随机存取存储器)等构成的易失性存储器等可改写的存储器。dmac 3利用dma转发来将卷积运算所需的权重w写入于权重存储器41。
[0140]
图10为乘法运算器42的内部框图。
[0141]
乘法运算器42将输入矢量a与权重矩阵w相乘。如上所述,输入矢量a为具有分割输入数据a(x+i,y+j,co)针对每个i、j被展开而得到的bc个元素的矢量数据。另外,权重矩阵w为具有分割权重w(i,j,co,do)针对每个i、j被展开而得到的bc
×
bd个元素的矩阵数据。乘法运算器42具有bc
×
bd个积和运算单元47,能够并行地实施输入矢量a与权重矩阵w的乘法运算。
[0142]
乘法运算器42从第一存储器1及权重存储器41读取乘法运算所需的输入矢量a和权重矩阵w并实施乘法运算。乘法运算器42输出bd个积和运算结果o(di)。
[0143]
图11为积和运算单元47的内部框图。
[0144]
积和运算单元47实施输入矢量a的元素a(ci)与权重矩阵w的元素w(ci,di)的乘法运算。另外,积和运算单元47将乘法运算结果与其它的积和运算单元47的乘法运算结果s(ci,di)相加。积和运算单元47输出加法运算结果s(ci+1,di)。元素a(ci)为2位无符号整数(0,1,2,3)。元素w(ci,di)为1位带符号整数(0,1),值“0”表示+1,值“1”表示-1。
[0145]
积和运算单元47具有反转器(反相器)47a、选择器47b和加法运算器47c。积和运算单元47不使用乘法运算器,而仅使用反转器47a及选择器47b来进行乘法运算。在元素w(ci,di)为“0”时,选择器47b选择元素a(ci)的输入。在元素w(ci,di)为“1”时,选择器47b选择由反转器使元素a(ci)反转得到的补数。元素w(ci,di)也被输入至加法运算器47c的进位输入(carry-in)。当元素w(ci,di)为“0”时,加法运算器47c输出对s(ci,di)加上元素a(ci)得到
的值。当w(ci,di)为“1”时,加法运算器47c输出从s(ci,di)中减去元素a(ci)得到的值。
[0146]
图12为累加器电路43的内部框图。
[0147]
累加器电路43将乘法运算器42的积和运算结果o(di)在第二存储器2中累积。累加器电路43具有bd个累加器单元48,能够在第二存储器2并行地累积bd个积和运算结果o(di)。
[0148]
图13为累加器单元48的内部框图。
[0149]
累加器单元48具有加法运算器48a和屏蔽部48b。加法运算器48a将积和运算结果o的元素o(di)与保存于第二存储器2的式1所示的卷积运算的中间过程即部分和相加。作为加法运算结果,每个元素为16位。加法运算结果不限于每个元素16位,也可以为例如每个元素15位或17位。
[0150]
加法运算器48a将加法运算结果写入于第二存储器2的同一地址。在初始化信号clear(清除)被断言(assert)时,屏蔽部48b屏蔽来自第二存储器2的输出,将对于元素o(di)的加法运算对象设为零。当第二存储器2中未保存有中间过程的部分和时,初始化信号clear被断言。
[0151]
当由乘法运算器42及累加器电路43进行的卷积运算完成时,输出数据f(x,y,do)被保存于第二存储器。
[0152]
状态控制器44控制乘法运算器42及累加器电路43的状态。另外,状态控制器44经由内部总线ib与控制器6连接。状态控制器44具有命令队列45和控制电路46。
[0153]
命令队列45为保存卷积运算电路4用的命令指令c4的队列,例如由fifo存储器构成。在命令队列45中经由内部总线ib被写入命令指令c4。
[0154]
控制电路46为对命令指令c4进行解码并基于命令指令c4控制乘法运算器42及累加器电路43的状态机。控制电路46为与dmac 3的状态控制器32的控制电路34同样的结构。
[0155]
[量化运算电路5]
[0156]
图14为量化运算电路5的内部框图。
[0157]
量化运算电路5具有量化参数存储器51、矢量运算电路52、量化电路53和状态控制器54。量化运算电路5具有针对矢量运算电路52及量化电路53的专用的状态控制器54,当被输入命令指令时,无需外部的控制器而能够实施量化运算。
[0158]
量化参数存储器51为保存量化运算中使用的量化参数q的存储器,例如为由sram(static ram,静态随机存取存储器)等构成的易失性存储器等可改写的存储器。dmac 3利用dma转发来将量化运算所需的量化参数q写入于量化参数存储器51。
[0159]
图15为矢量运算电路52和量化电路53的内部框图。
[0160]
矢量运算电路52对保存于第二存储器2的输出数据f(x,y,do)进行运算。矢量运算电路52具有bd个运算单元57,对输出数据f(x,y,do)并行地进行simd运算。
[0161]
图16为运算单元57的框图。
[0162]
运算单元57例如具有alu 57a、第一选择器57b、第二选择器57c、寄存器57d和移位器57e。运算单元57可以还具有公知的通用simd运算电路具有的其它运算器等。
[0163]
矢量运算电路52通过组合运算单元57具有的运算器等来对输出数据f(x,y,do)进行量化运算层220中的池化层221、批量归一化层222、激活函数层223的运算当中的至少一个运算。
[0164]
运算单元57能够利用alu 57a将保存于寄存器57d的数据与从第二存储器2读取的输出数据f(x,y,do)的元素f(di)相加。运算单元57能够将alu 57a的加法运算结果保存于寄存器57d。运算单元57通过将“0”输入至alu 57a以代替根据第一选择器57b的选择被保存于寄存器57d的数据,从而能够将加法运算结果初始化。例如在池化区域为2
×
2时,移位器57e通过将alu 57a的输出右移位2比特(bit)而能够输出加法运算结果的平均值。矢量运算电路52通过重复进行由bd个运算单元57进行的上述运算等而能够实施式2所示的平均池化的运算。
[0165]
运算单元57能够利用alu 57a来对保存于寄存器57d的数据与从第二存储器2读取的输出数据f(x,y,do)的元素f(di)进行比较。
[0166]
运算单元57能够根据alu 57a的比较结果来控制第二选择器57c,以选择保存于寄存器57d的数据和元素f(di)中的较大者。运算单元57通过根据第一选择器57b的选择将元素f(di)的可取值的最小值输入至alu 57a而能够将比较对象初始化为最小值。在本实施方式中,元素f(di)为16比特(bit)带符号整数,因此元素f(di)的可取值的最小值为“0x8000”。矢量运算电路52通过重复进行由bd个运算单元57进行的上述运算等而能够实施式3的max池化的运算。此外,在max池化的运算中,移位器57e不对第二选择器57c的输出进行移位。
[0167]
运算单元57能够利用alu 57a对保存于寄存器57d的数据和从第二存储器2读取的输出数据f(x,y,do)的元素f(di)进行减法运算。移位器57e能够将alu 57a的输出左移位(即乘法运算)或右移位(即除法运算)。矢量运算电路52通过重复进行由bd个运算单元57进行的上述运算等而能够实施式4的批量归一化的运算。
[0168]
运算单元57能够利用alu 57a对从第二存储器2读取的输出数据f(x,y,do)的元素f(di)与由第一选择器57b选择出的“0”进行比较。运算单元57能够根据alu 57a的比较结果,选择并输出元素f(di)和预先保存于寄存器57d的常数值“0”中的任意值。矢量运算电路52通过重复进行由bd个运算单元57进行的上述运算等而能够实施式5的relu运算。
[0169]
矢量运算电路52能够实施平均池化、max池化、批量归一化、激活函数的运算及这些运算的组合。由于矢量运算电路52能够实施通用simd运算,因此也可以实施量化运算层220中的运算所需的其它运算。另外,矢量运算电路52也可以实施量化运算层220中的运算以外的运算。
[0170]
此外,量化运算电路5可以不具有矢量运算电路52。在量化运算电路5不具有矢量运算电路52时,输出数据f(x,y,do)被输入至量化电路53。
[0171]
量化电路53对矢量运算电路52的输出数据进行量化。如图15所示,量化电路53具有bd个量化单元58,对矢量运算电路52的输出数据并行地进行运算。
[0172]
图17为量化单元58的内部框图。
[0173]
量化单元58对矢量运算电路52的输出数据的元素in(di)进行量化。量化单元58具有比较器58a和编码器58b。量化单元58对矢量运算电路52的输出数据(16位/元素)进行量化运算层220中的量化层224的运算(式6)。量化单元58从量化参数存储器51读取需要的量化参数q(th0,th1,th2),利用比较器58a进行输入in(di)与量化参数q的比较。量化单元58利用编码器58b将比较器58a的比较结果量化为2位/元素。由于式4中的α(c)和β(c)为针对每个变量c而不同的参数,因此反映α(c)和β(c)的量化参数q(th0,th1,th2)为针对每个in
(di)而不同的参数。
[0174]
量化单元58将输入in(di)与3个阈值th0、th1、th2相比较,从而将输入in(di)分类为4个区域(例如in≤th0、th0<in≤th1、th1<in≤th2、th2<in),将分类结果编码为2位并输出。通过量化参数q(th0,th1,th2)的设定,量化单元58还能够将批量归一化、激活函数的运算与量化一并进行。
[0175]
量化单元58通过设定阈值th0作为式4的β(c)、设定阈值之差(th1-th0)及(th2-th1)作为式4的α(c)来进行量化,从而能够将式4所示的批量归一化的运算与量化一并实施。能够通过增大(th1-th0)及(th2-th1)来减小α(c)。能够通过减小(th1-th0)及(th2-th1)来增大α(c)。
[0176]
量化单元58能够将激活函数的relu运算与输入in(di)的量化一并实施。例如,量化单元58在in(di)≤th0及th2<in(di)的区域中使输出值饱和。量化单元58通过以使输出为非线性的方式设定量化参数q,从而能够将激活函数的运算与量化一并实施。
[0177]
状态控制器54控制矢量运算电路52及量化电路53的状态。另外,状态控制器54经由内部总线ib与控制器6连接。状态控制器54具有命令队列55和控制电路56。
[0178]
命令队列55为保存量化运算电路5用的命令指令c5的队列,例如由fifo存储器构成。在命令队列55中经由内部总线ib被写入命令指令c5。
[0179]
控制电路56为对命令指令c5进行解码并基于命令指令c5控制矢量运算电路52及量化电路53的状态机。控制电路56为与dmac 3的状态控制器32的控制电路34同样的结构。
[0180]
量化运算电路5将具有bd个元素的量化运算输出数据写入于第一存储器1。此外,式10中示出bd与bc的优选关系。在式10中n为整数。
[0181]
[数学式10]
[0182]
bd=2n·
bc......式(10)
[0183]
[控制器6]
[0184]
控制器6将从外部主机cpu转发的命令指令转发至dmac 3、卷积运算电路4及量化运算电路5具有的命令队列。控制器6可以具有保存针对各电路的命令指令的命令存储器。
[0185]
控制器6连接于外部总线eb,作为外部主机cpu的从设备而工作。控制器6具有包括参数寄存器、状态寄存器的寄存器61。参数寄存器为对nn电路100的工作进行控制的寄存器。状态寄存器为包括信号量s的表示nn电路100的状态的寄存器。
[0186]
[信号量s]
[0187]
图18为说明基于信号量s对nn电路100的控制的图。
[0188]
信号量s具有第一信号量s1、第二信号量s2和第三信号量s3。信号量s根据p操作而自减(decrement),根据v操作而自增(increment)。由dmac 3、卷积运算电路4及量化运算电路5进行的p操作及v操作经由内部总线ib来更新控制器6具有的信号量s。
[0189]
第一信号量s1被用于第一数据流f1的控制。第一数据流f1为dmac 3(producer,生产者)将输入数据a写入于第一存储器1、卷积运算电路4(consumer,消费者)读取输入数据a的数据流。第一信号量s1具有第一写入信号量s1w和第一读取信号量s1r。
[0190]
第二信号量s2被用于第二数据流f2的控制。第二数据流f2为卷积运算电路4(生产者)将输出数据f写入于第二存储器2、量化运算电路5(消费者)读取输出数据f的数据流。第二信号量s2具有第二写入信号量s2w和第二读取信号量s2r。
[0191]
第三信号量s3被用于第三数据流f3的控制。第三数据流f3为量化运算电路5(生产者)将量化运算输出数据写入于第一存储器1、卷积运算电路4(消费者)读取量化运算电路5的量化运算输出数据的数据流。第三信号量s3具有第三写入信号量s3w和第三读取信号量s3r。
[0192]
[第一数据流f1]
[0193]
图19为第一数据流f1的时序图。
[0194]
第一写入信号量s1w为限制在第一数据流f1中由dmac 3对第一存储器1的写入的信号量。第一写入信号量s1w表示在第一存储器1中能够保存例如输入矢量a等预定尺寸的数据的存储器区域当中的、数据读取完毕而能够写入其它数据的存储器区域的数量。在第一写入信号量s1w为“0”时,dmac 3无法对第一存储器1进行第一数据流f1中的写入,而要等到第一写入信号量s1w变为“1”以上。
[0195]
第一读取信号量s1r为限制在第一数据流f1中由卷积运算电路4从第一存储器1的读取的信号量。第一读取信号量s1r表示在第一存储器1中能够保存例如输入矢量a等预定尺寸的数据的存储器区域当中的、数据写入完毕而能够读取的存储器区域的数量。在第一读取信号量s1r为“0”时,卷积运算电路4无法从第一存储器1进行第一数据流f1中的读取,而要等到第一读取信号量s1r变为“1”以上。
[0196]
命令指令c3被保存于命令队列33,由此dmac 3开始dma转发。如图19所示,由于第一写入信号量s1w不为“0”,因此dmac 3开始dma转发(dma转发1)。dmac 3在开始dma转发时,对第一写入信号量s1w进行p操作。dmac 3在dma转发完成后,对第一读取信号量s1r进行v操作。
[0197]
命令指令c4被保存于命令队列45,由此卷积运算电路4开始卷积运算。如图19所示,由于第一读取信号量s1r为“0”,因此卷积运算电路4等待直到第一读取信号量s1r变为“1”以上(解码状态st2下的等待)。当由于dmac 3的v操作而第一读取信号量s1r变为“1”时,卷积运算电路4开始卷积运算(卷积运算1)。卷积运算电路4在开始卷积运算时,对第一读取信号量s1r进行p操作。卷积运算电路4在卷积运算完成后,对第一写入信号量s1w进行v操作。
[0198]
在dmac 3开始图19中记载为“dma转发3”的dma转发时,第一写入信号量s1w为“0”,因此dmac 3等待直到第一写入信号量s1w变为“1”以上(解码状态st2下的等待)。当由于卷积运算电路4的v操作而第一写入信号量s1w变为“1”以上时,dmac 3开始dma转发。
[0199]
dmac 3和卷积运算电路4通过使用信号量s1,能够防止在第一数据流f1中对第一存储器1的访问冲突。另外,dmac 3和卷积运算电路4通过使用信号量s1,能够在使第一数据流f1中的数据转发同步的同时独立且并行地工作。
[0200]
[第二数据流f2]
[0201]
图20为第二数据流f2的时序图。
[0202]
第二写入信号量s2w为限制在第二数据流f2中由卷积运算电路4对第二存储器2的写入的信号量。第二写入信号量s2w表示在第二存储器2中能够保存例如输出数据f等预定尺寸的数据的存储器区域当中的、数据读取完毕而能够写入其它数据的存储器区域的数量。在第二写入信号量s2w为“0”时,卷积运算电路4无法对第二存储器2进行第二数据流f2中的写入,而要等到第二写入信号量s2w变为“1”以上。
[0203]
第二读取信号量s2r为限制在第二数据流f2中由量化运算电路5从第二存储器2的读取的信号量。第二读取信号量s2r表示在第二存储器2中能够保存例如输出数据f等预定尺寸的数据的存储器区域当中的、数据写入完毕而能够读取的存储器区域的数量。在第二读取信号量s2r为“0”时,量化运算电路5无法从第二存储器2进行第二数据流f2中的读取,而要等到第二读取信号量s2r变为“1”以上。
[0204]
如图20所示,卷积运算电路4在开始卷积运算时,对第二写入信号量s2w进行p操作。卷积运算电路4在卷积运算完成后,对第二读取信号量s2r进行v操作。
[0205]
命令指令c5被保存于命令队列55,由此量化运算电路5开始量化运算。如图20所示,由于第二读取信号量s2r为“0”,因此量化运算电路5等待直到第二读取信号量s2r变为“1”以上(解码状态st2下的等待)。当由于卷积运算电路4的v操作而第二读取信号量s2r变为“1”时,量化运算电路5开始量化运算(量化运算1)。量化运算电路5在开始量化运算时,对第二读取信号量s2r进行p操作。量化运算电路5在量化运算完成后,对第二写入信号量s2w进行v操作。
[0206]
在量化运算电路5开始图20中记载为“量化运算2”的量化运算时,第二读取信号量s2r为“0”,因此量化运算电路5等待直到第二读取信号量s2r变为“1”以上(解码状态st2下的等待)。当由于卷积运算电路4的v操作而第二读取信号量s2r变为“1”以上时,量化运算电路5开始量化运算。
[0207]
卷积运算电路4和量化运算电路5通过使用信号量s2,能够防止在第二数据流f2中对第二存储器2的访问冲突。另外,卷积运算电路4和量化运算电路5通过使用信号量s2,能够在使第二数据流f2中的数据转发同步的同时独立且并行地工作。
[0208]
[第三数据流f3]
[0209]
第三写入信号量s3w为限制在第三数据流f3中由量化运算电路5对第一存储器1的写入的信号量。第三写入信号量s3w表示在第一存储器1中能够保存例如量化运算电路5的量化运算输出数据等预定尺寸的数据的存储器区域当中的、数据读取完毕而能够写入其它数据的存储器区域的数量。在第三写入信号量s3w为“0”时,量化运算电路5无法对第一存储器1进行第三数据流f3中的写入,而要等到第三写入信号量s3w变为“1”以上。
[0210]
第三读取信号量s3r为限制在第三数据流f3中由卷积运算电路4从第一存储器1的读取的信号量。第三读取信号量s3r表示在第一存储器1中能够保存例如量化运算电路5的量化运算输出数据等预定尺寸的数据的存储器区域当中的、数据写入完毕而能够读取的存储器区域的数量。在第三读取信号量s3r为“0”时,卷积运算电路4无法进行第三数据流f3中的从第一存储器1的读取,而要等到第三读取信号量s3r变为“1”以上。
[0211]
量化运算电路5和卷积运算电路4通过使用信号量s3,能够防止在第三数据流f3中对第一存储器1的访问冲突。另外,量化运算电路5和卷积运算电路4通过使用信号量s3,能够在使第三数据流f3中的数据转发同步的同时独立且并行地工作。
[0212]
第一存储器1在第一数据流f1及第三数据流f3中被共享。nn电路100通过另行设置第一信号量s1和第三信号量s3,能够区分第一数据流f1和第三数据流f3而使数据转发同步。
[0213]
[卷积运算电路4的工作(1)]
[0214]
卷积运算电路4在进行卷积运算时,从第一存储器1进行读取,对第二存储器2进行
写入。即,卷积运算电路4在第一数据流f1中为消费者,在第二数据流f2中为生产者。因此,卷积运算电路4在开始卷积运算时,对第一读取信号量s1r进行p操作(参照图19),对第二写入信号量s2w进行p操作(参照图20)。卷积运算电路4在卷积运算完成后,对第一写入信号量s1w进行v操作(参照图19),对第二读取信号量s2r进行v操作(参照图20)。
[0215]
卷积运算电路4在开始卷积运算时,等待直到第一读取信号量s1r变为“1”以上且第二写入信号量s2w变为“1”以上(解码状态st2下的等待)。
[0216]
[量化运算电路5的工作]
[0217]
量化运算电路5在进行量化运算时,从第二存储器2进行读取,对第一存储器1进行写入。即,量化运算电路5在第二数据流f2中为消费者,在第三数据流f3中为生产者。因此,量化运算电路5在开始量化运算时,对第二读取信号量s2r进行p操作,对第三写入信号量s3w进行p操作。量化运算电路5在量化运算完成后,对第二写入信号量s2w进行v操作,对第三读取信号量s3r进行v操作。
[0218]
量化运算电路5在开始量化运算时,等待直到第二读取信号量s2r变为“1”以上且第三写入信号量s3w变为“1”以上(解码状态st2下的等待)。
[0219]
[卷积运算电路4的工作(2)]
[0220]
卷积运算电路4从第一存储器1读取的输入数据有时也是在第三数据流中量化运算电路5写入的数据。在该情况下,卷积运算电路4在第三数据流f3中为消费者,在第二数据流f2中为生产者。因此,卷积运算电路4在开始卷积运算时,对第三读取信号量s3r进行p操作,对第二写入信号量s2w进行p操作。卷积运算电路4在卷积运算完成后,对第三写入信号量s3w进行v操作,对第二读取信号量s2r进行v操作。
[0221]
卷积运算电路4在开始卷积运算时,等待直到第三读取信号量s3r变为“1”以上且第二写入信号量s2w变为“1”以上(解码状态st2下的等待)。
[0222]
[卷积运算实施命令]
[0223]
图21为说明卷积运算实施命令的图。
[0224]
卷积运算实施命令为针对卷积运算电路4的命令指令c4之一。卷积运算实施命令有保存有针对卷积运算电路4的命令的命令字段if和保存有针对信号量s的操作等的信号量操作字段sf。命令字段if和信号量操作字段sf作为卷积运算实施命令被收存于一个命令。
[0225]
卷积运算实施命令的命令字段if为保存针对卷积运算电路4的命令的字段。命令字段if中例如保存有使乘法运算器42及累加器电路43实施卷积运算的指令、累加器电路43的clear(清除)信号的控制指令、输入矢量a和权重矩阵w的尺寸和存储器地址等。
[0226]
卷积运算实施命令的信号量操作字段sf保存针对与保存于命令字段if的命令关联的信号量s的操作等。卷积运算电路4在第一数据流f1及第三数据流f3中为从对方接收数据并消费的消费者,在第二数据流f2中为向对方发送生产出的数据的生产者。因而,关联的信号量s为第一信号量s1、第二信号量s2和第三信号量s3。因此,如图21所示,卷积运算实施命令的信号量操作字段sf中包含针对第一信号量s1、第二信号量s2和第三信号量s3的操作字段。
[0227]
在信号量操作字段sf中针对每个信号量设置有p操作字段和v操作字段。如图21所示,卷积运算实施命令的信号量操作字段sf中包含6个操作字段。信号量操作字段sf的各操
作字段为1位。信号量操作字段sf的各操作字段可以为多位。
[0228]
对于针对卷积运算电路4为消费者的第一数据流f1及第三数据流f3的第一信号量s1及第三信号量s3,设置有针对读取信号量(s1r、s3r)的p操作字段和针对写入信号量(s1w、s3w)的v操作字段。
[0229]
对于针对卷积运算电路4为生产者的第二数据流f2的第二信号量s2,设置有针对写入信号量(s2w)的p操作字段和针对读取信号量(s2r)的v操作字段。
[0230]
图22为示出卷积运算命令的具体例的图。
[0231]
图22所示的具体例由4个卷积运算命令(以后称为“命令1”至“命令4”)构成,4个卷积运算命令将保存于第一存储器1的输入数据a(x+i,y+j,co)分割为4次来使卷积运算电路4实施卷积运算。
[0232]
卷积运算电路4的状态控制器44转变到解码状态st2,对保存于命令队列45的4个命令(命令1至命令4)当中的最先保存的命令1进行解码。
[0233]
在p操作字段被设定为“1”时,状态控制器44经由内部总线ib从控制器6读取与被设定为“1”的p操作字段对应的信号量s,判定是否满足实施条件。实施条件是指,与被设定为“1”的p操作字段对应的信号量s全部为“1”以上。在命令1中,针对第一读取信号量s1r的p操作字段和针对第二写入信号量s2w的p操作字段被设定为“1”。因此,状态控制器44读取第一读取信号量s1r及第二写入信号量s2w,判定是否满足实施条件。
[0234]
在p操作字段被设定为“1”时,状态控制器44等待直到与被设定为“1”的p操作字段对应的信号量s被更新而满足实施条件。在命令1的情况下,如果不是第一读取信号量s1r为“1”以上且第二写入信号量s2w为“1”以上(not ready:未就绪),则状态控制器44等待直到信号量s被更新而满足实施条件(wait:等待)。
[0235]
在p操作字段被设定为“1”时,如果满足实施条件,则状态控制器44转变到执行状态st3,实施基于命令字段if的卷积运算。在命令1的情况下,如果第一读取信号量s1r为“1”以上且第二写入信号量s2w为“1”以上(ready:就绪),则状态控制器44转变到执行状态st3,实施基于命令字段if的卷积运算。
[0236]
在p操作字段被设定为“1”时,在实施卷积运算前,状态控制器44对与被设定为“1”的p操作字段对应的信号量s进行p操作。在命令1的情况下,在实施卷积运算前,状态控制器44对第一读取信号量s1r及第二写入信号量s2w进行p操作。
[0237]
在执行命令1后,状态控制器44转变到解码状态st2,对命令2进行解码。在命令2中,所有信号量操作字段sf都未被设定为“1”。因此,状态控制器44不进行信号量s的确认、更新而转变到执行状态st3,实施基于命令字段if的卷积运算。
[0238]
在执行命令2后,状态控制器44转变到解码状态st2,对命令3进行解码。在命令3中,所有信号量操作字段sf都未被设定为“1”。因此,状态控制器44不进行信号量s的确认、更新而转变到执行状态st3,实施基于命令字段if的卷积运算。
[0239]
在执行命令3后,状态控制器44转变到解码状态st2,对命令4进行解码。在命令4中,所有p操作字段都未被设定为“1”。因此,状态控制器44不进行信号量s的确认、更新而转变到执行状态st3,实施基于命令字段if的卷积运算。
[0240]
在v操作字段被设定为“1”时,状态控制器44在命令4的卷积运算完成后,对与被设定为“1”的v操作字段对应的信号量s进行v操作。在命令4中,针对第一写入信号量s1w的v操
作字段和针对第二读取信号量s2r的v操作字段被设定为“1”。因此,状态控制器44在命令4的卷积运算完成后,对第一写入信号量s1w及第二读取信号量s2r进行v操作。
[0241]
在执行命令4后,状态控制器44转变到空闲状态st1,结束由4个命令构成的一系列卷积运算命令的执行。
[0242]
在卷积运算电路4使用由量化运算电路5写入于第一存储器1的量化运算输出数据作为输入数据时,与第三信号量s3对应的操作字段被使用。
[0243]
卷积运算实施命令指示基于命令字段if的卷积运算,并且基于信号量操作字段sf实施关联的信号量s的确认及更新。由于命令字段if和信号量操作字段sf作为卷积运算实施命令被收存于一个命令,因此能够降低用于实施卷积运算的命令指令c4的数量。另外,能够缩短解码等命令执行所花费的处理时间。
[0244]
[量化运算实施命令]
[0245]
图23为说明量化运算实施命令的图。
[0246]
量化运算实施命令为针对量化运算电路5的命令指令c5之一。量化运算实施命令具有保存有针对量化运算电路5的命令的命令字段if和保存有针对信号量s的操作等的信号量操作字段sf。命令字段if和信号量操作字段sf作为量化运算实施命令被收存于一个命令。
[0247]
量化运算实施命令的命令字段if为保存针对量化运算电路5的命令的字段。在命令字段if中例如保存有使矢量运算电路52和量化电路53实施运算的指令、输出数据f和量化参数p的尺寸和存储器地址等。
[0248]
量化运算实施命令的信号量操作字段sf保存针对与保存于命令字段if的命令关联的信号量s的操作等。量化运算电路5在第二数据流f2中为消费者,在第三数据流f3中为生产者。因而,关联的信号量s为第二信号量s2和第三信号量s3。因此,如图23所示,在量化运算实施命令的信号量操作字段sf中包含针对第二信号量s2和第三信号量s3的操作字段。
[0249]
对于针对量化运算电路5为消费者的第二数据流f2的第二信号量s2,设置有针对读取信号量(s2r)的p操作字段和针对写入信号量(s2w)的v操作字段。
[0250]
对于针对量化运算电路5为生产者的第三数据流f3的第三信号量s3,设置有针对写入信号量(s3w)的p操作字段和针对读取信号量(s3r)的v操作字段。
[0251]
与状态控制器44对于卷积运算实施命令的工作同样地,量化运算电路5的状态控制器54对p操作字段、v操作字段被设定为“1”的量化运算实施命令进行信号量s的确认、更新。
[0252]
[dma转发实施命令]
[0253]
图24为说明dma转发实施命令的图。
[0254]
dma转发实施命令为针对dmac 3的命令指令c3之一。dma转发实施命令具有保存有针对dmac 3的命令的命令字段if和保存有针对信号量s的操作等的信号量操作字段sf。命令字段if和信号量操作字段sf作为dma转发实施命令被收存于一个命令。
[0255]
dma转发实施命令的命令字段if为保存针对dmac 3的命令的字段。在命令字段if中例如保存有存储器转发源、存储器转发目的地的存储器地址、转发数据尺寸等。
[0256]
在dma转发实施命令的信号量操作字段sf中,保存有针对与保存于命令字段if的命令关联的信号量s的操作等。dmac 3在第一数据流f1中为生产者。因而,关联的信号量s为
第一信号量s1。因此,如图24所示,dma转发实施命令的信号量操作字段sf中包含针对第一信号量s1的操作字段。
[0257]
对于针对dmac 3为生产者的第一数据流f1的第一信号量s1,设置有针对写入信号量(s1w)的p操作字段和针对读取信号量(s1r)的v操作字段。
[0258]
与状态控制器44对于卷积运算实施命令的工作同样地,dmac 3的状态控制器32针对p操作字段、v操作字段被设定为“1”的dma转发实施命令,进行信号量s的确认、更新。
[0259]
根据本实施方式的神经网络电路的控制方法,能够使可嵌入于iot设备等嵌入式设备的nn电路100高性能地工作。在卷积运算实施命令、量化运算实施命令及dma转发实施命令中,命令字段if和信号量操作字段sf被收存于一个命令。因此,能够降低用于实施卷积运算等的命令指令的数量。另外,能够缩短解码等命令执行所花费的处理时间。
[0260]
以上参照附图对本发明的第一实施方式进行了详细说明,而具体结构不限于该实施方式,还包含不脱离本发明主旨的范围内的设计变更等。另外,在上述实施方式及变形例中示出的构成要素能够适当组合来构成。
[0261]
(变形例1)
[0262]
在上述实施方式中,示出了针对一个命令字段if将多个信号量操作字段sf收存于一个命令的命令的例子,而命令的形态不限于此。命令可以为将多个命令字段if和针对每个命令字段if对应关联的多个信号量操作字段sf收存于一个命令的形态。另外,作为将命令字段if和信号量操作字段sf收存于一个命令的方法,不限于上述实施方式的结构。进而,命令字段if和信号量操作字段sf可以被分割为多个命令来收存。如果在命令中命令字段if与对应的信号量操作字段sf对应关联,则能够达到同样的效果。
[0263]
(变形例2)
[0264]
在上述实施方式中,第一存储器1和第二存储器2为分开的存储器,而第一存储器1和第二存储器2的形态不限于此。第一存储器1和第二存储器2例如可以为同一存储器中的第一存储器区域和第二存储器区域。
[0265]
(变形例3)
[0266]
在上述实施方式中,信号量s为针对第一数据流f1、第二数据流f2及第三数据流f3而设置的,而信号量s的形态不限于此。信号量s例如可以针对dmac 3将权重w写入权重存储器41、乘法运算器42读取权重w的数据流来设置。信号量s例如也可以针对dmac3将量化参数q写入量化参数存储器51、量化电路53读取量化参数q的数据流来设置。
[0267]
(变形例4)
[0268]
例如,被输入至上述实施方式记载的nn电路100的数据不限于单一形式,而能够以静止图像、视频图像、语音、文字、数值及它们的组合来构成。此外,被输入至nn电路100的数据不限于可被搭载于设置有nn电路100的边缘设备的光传感器、温度计、全球定位系统(global positioning system,gps)测量仪、角速度测量仪、风速计等物理量测量器的测量结果。也可以将从周边设备经由有线或无线通信而接收的基站信息、车辆/船舶等的信息、天气信息、与拥堵状况有关的信息等周边信息、金融信息、个人信息等不同的信息进行组合。
[0269]
(变形例5)
[0270]
假设设置有nn电路100的边缘设备是由电池等驱动的移动电话等通信设备、个人
计算机等智能装置、数码相机、游戏设备、机器人产品等移动设备,但不限于此。即使在对用以太网供电(power on ethernet,poe)等能够供给的峰值功率限制、降低产品发热或长时间驱动的要求高的产品中利用,也能够得到其它现有例子没有的效果。例如,通过应用于在车辆、船舶等搭载的车载相机、在公共设施、街道上等设置的监视相机等,不仅能够实现长时间的拍摄,还有助于轻量化、高耐用化。另外,对电视、显示器等显示装置、医疗相机、手术机器人等医疗设备、制造现场、建筑现场中使用的作业机器人等,也能够通过应用来达到同样的效果。
[0271]
(变形例6)
[0272]
在nn电路100中,可以使用一个以上处理器来实现nn电路100的一部分或全部。例如,在nn电路100中,可以利用由处理器进行的软件处理来实现输入层或输出层的一部分或全部。利用软件处理实现的输入层或输出层的一部分例如为数据的归一化、变换。据此,能够应对各种形式的输入形式或输出形式。此外,作为由处理器执行的软件,可以使用通信单元、外部介质而以可改写的方式构成。
[0273]
(变形例7)
[0274]
作为nn电路100,可以通过组合云上的图形处理单元(graphics processing unit,gpu)等来实现cnn 200中的处理的一部分。作为nn电路100,通过除了用设置有nn电路100的边缘设备进行的处理之外还在云上进行处理,或是除了在云上的处理之外还在边缘设备上进行处理,能够用少的资源实现更复杂的处理。根据这样的结构,nn电路100能够通过处理的分散来降低边缘设备与云之间的通信量。
[0275]
(变形例8)
[0276]
nn电路100进行的运算为学习完毕的cnn 200的至少一部分,而nn电路100进行的运算的对象不限于此。nn电路100进行的运算可以为例如重复像卷积运算和量化运算这样两类运算的学习完毕的神经网络的至少一部分。
[0277]
另外,本说明书记载的效果仅为说明性或例示性的,而非限定性的。也就是说,本公开的技术可以与上述效果一起、或者代替上述效果而达到本领域技术人员根据本说明书的记载显而易见的其它效果。
[0278]
工业适用性
[0279]
本发明能够应用于神经网络的运算。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1