基于Transformer和深度强化学习的视频摘要生成网络的制作方法
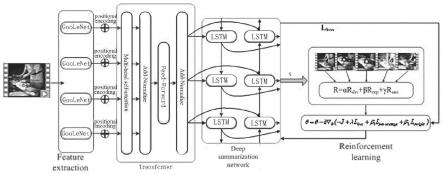
基于transformer和深度强化学习的视频摘要生成网络
技术领域
1.本发明涉及一种基于transformer和深度强化学习的视频摘要生成网络,属于计算机视觉技术领域。
背景技术:
2.随着互联网技术的发展和移动通讯设备的进步,网络视频领域突飞猛进。《中国互联网发展报告(2021)》显示,2020年中国网络视频市场规模达到了2412 亿元,同比增长44%,网络视频活跃用户规模达到10.01亿,同比增长2.14%,带来巨大机遇同时也迎来许多挑战。视频数据不仅数量庞大而且类型繁多,如用户自主拍摄视频,短视频,监控视频及新闻视频等,这使得网络视频内容的审核难度加大,同时用户对视频的快速浏览需求与日俱增。视频摘要技术的目的便是提取不同类型视频的关键信息,提升浏览效率。
3.研究视频摘要技术将有助于解决上述问题,视频摘要是以自动或半自动的方式,通过分析视频的结构和内容存在的时空冗余,从原始视频中提取关键帧或感兴趣的目标的活动信息自动生成视频摘要,使得用户可以通过少量的关键信息快速浏览原始视频的内容。视频摘要分为静态摘要和动态摘要,静态摘要通过提取若干关键帧合成为摘要,动态摘要则是组合关键镜头生成摘要。静态摘要最大的不足是合成的摘要不具有时序连贯性,给人一种快进的感觉,而动态摘要是将镜头进行组合,在不丢失关键内容的同时保留了视觉连贯性。因此发明重点研究动态视频摘要
技术实现要素:
4.为了使生成的摘要能更好的概括主题同时又不丢失视频帧之间的时序信息,本文提出基于编码器-解码器架构的transformer和深度强化学习的视频摘要网络(tdrlsn)。首先通过卷积神经网络将视频帧转换为深度特征,经由 transformer编码部分中的multi-head self-attention,transformer会将编码的位置信息添加到特征中,能较好的保留特征之间的时序关系。解码器部分由长短期记忆网络完成时序建模,进行重要性分值预测,最后通过强化学习来优化模型的参数,强化学习的奖励函数包含三个模块:代表性、多样性、统一性用以评估生成摘要的质量。为了能更好的结合无监督学习和监督学习的优势,本文将监督学习中loss的计算通过变换加入奖励函数,使得模型拥有更强的学习能力,进一步提升预测准确性,生成更符合用户视觉的视频摘要。
5.技术方案如下:
6.基于transformer和深度强化学习的视频摘要生成网络,包括三个部分:编码、解码、优化;
7.编码部分通过goolenet提取视频帧的深度特征,将特征向量输入 transformer编码部分,首先进行位置编码,之后传入self-attention层,计算完成后进行残差连接和层正则化,最后经过前馈神经网络和再一次的残差连接和层正则化;
8.视频帧经由goolenet提取深度特征后,假设共有m帧,则当前视频的特征集合可以
表示为:x=x1,x2,
…
,xm,其中每个x的维度均为1024;首先要对特征进行位置编码,位置编码是transformer重要组成部分,用于弥补attention 无法获取位置信息的不足;
9.位置编码的添加,首先要构造一个与输入特征同维度的矩阵pe(positional encoding),pe矩阵是二维矩阵,行表示当前视频的帧的位置,列表示帧的特征向量,对于pe矩阵的计算通过三角函数来完成,奇数位置用正弦函数,偶数位置用余弦函数,利用三角函数变换,则当前位置的pe可由上一位置的pe线性表示;
10.对于pe矩阵的计算如下:
[0011][0012][0013]
其中,pos表示当前视频帧在视频帧序列中的位置索引,即pos=0,1,2
…
m-1,i 表示特征向量的维度,即i=0,1,2,
…
1/2d
model-1,d
model
是视频帧维度大小,此处 d
model
=1024;
[0014]
位置编码计算完成后,将其与输入特征集合x相加,进入encoder部分;
[0015]
首先进入多头自注意力层,即由多个自注意力层构成,对于输入序列x,经由三个矩阵wq、wk、wv的线性映射,分别得到qj,kj,vj,j∈(1,2,3
…
m),将q1分别与k1,k2,k3…km
进行点积运算,得到注意力分布a
1,1
,a
1,2
,a
1,3
,
…
,a
1,m
,将注意力分布经过softmax函数进行归一化得到0-1之间的注意力权重,得到注意力权重后与对应的v1,v2,v3
…
,vm相乘,相乘结束进行求和运算得到x1对应自注意力的输出h1;
[0016]
对于multi-headed self-attention,则是在self-attention的基础上,将其映射到若干个其他空间运算,多头自注意力计算完成后,通过前馈神经网络层,完成空间变化,增加模型的表征能力;
[0017]
解码部分由双向lstm完成,输出每一帧的重要性分数,通过标注计算出对应的loss,动态摘要是基于镜头的选择,通过算术平均将帧级分数转换成镜头分数;
[0018]
编码端完成编码后,带有注意力权重的特征向量进入解码端;解码端由双向长短期记忆网络组成,bilstm将视频特征集合x作为输入得到对应的隐藏状态 h=h1,h2,h3,
…
hm,h由一个正向遍历和逆向遍历的lstm连接构成,通过这种方式能够获得更多的上下文信息;h计算完成后,经由全连接层和sigmoid函数得到帧级概率p=p1,p2,p3
…
pm,即当前帧是否为关键帧的概率;为了能够生成用于后续评估的摘要,需要对p进行伯努利采样得到动作a=a1,a2,a3
…
am,选取a为1的帧组成摘要s;
[0019]
pm=σ(whm)
ꢀꢀꢀ
(3)
[0020]am
=bernoulli(pm)
ꢀꢀꢀ
(4)
[0021]
s={vm|am=1}
ꢀꢀꢀ
(5)
[0022]
其中m为当前视频对应的帧数,σ为sigmoid函数,am为伯努利采样后对应的动作,am∈(0,1),0代表当前帧不是关键帧,1代表当前帧是关键帧;vm为视频帧,s为摘要集合,即选取am值为1对应的视频帧组成的集合;
[0023]
优化部分由背包算法选出若干关键镜头组成摘要,通过强化学习完成对摘要的奖励值计算;
[0024]
基于编码器-解码器架构的模型生成了摘要,深度网络将获得奖励值r,r由奖励函数r(s)计算得到,奖励值r用于评价生成摘要的质量,深度网络通过生成更符合预期的摘要来最大化奖励值r;生成高质量的摘要是奖励函数的目标,以多样性、代表性和统一性作为奖励函数的计算指标;模型具有较强的学习能力,提升了泛化性,由于视频数据量较少,可能会出现不够准确的情况,因此引入监督学习的信息,帮助模型更好的学习特征,提升准确性;
[0025]
通过深度学习网络lstm得到了摘要s,通过对s中选中的帧进行相似性计算,即帧之间的相似性越低,则整个镜头的多样性就越高,具体来说选取不同的两帧计算它们的cosine距离,重复该过程直至每一帧都完成计算并将结果求和取平均,r
div
计算如下:
[0026][0027]
其中d(x
t
,xi)为差异性计算函数,d(x
t
,xi)函数如下:
[0028][0029]
根据多样性的计算可得,当两帧差异越大,则多样性分值越高;但公式在计算时没有考虑帧之间的时间距离,相距较远的两帧在差异度计算时应当被忽略,因为它们在构建原视频的主要内容时至关重要,所以设定当所选帧超过阈值范围λ则多样性分值记为最大;
[0030]
d(x
t
,xi)=1 if|t-i|>λ
ꢀꢀꢀ
(8)
[0031]
代表性奖励能够衡量摘要代表原始视频的程度;为此,将代表性奖励的计算转换为k-medoids问题,即模型选择一组中心帧使得其他帧到中心帧之间的平方误差的平均值最小,通过这种方式使模型选出的帧在整个视频中占比尽可能大,最终生成的摘要越具代表性,因此对r
rep
计算如下:
[0032][0033]
通过多样性与代表性可以得到效果良好的摘要,但为了生成更高质量且符合用户视觉逻辑的摘要,需要减少时间变化带来的片段跳跃,相邻片段巨大的变化会让用户无法理解视频内容,丢失原有故事情节;为了避免该类问题带来的影响,引入统一性奖励,用于平衡片段变化导致的信息缺失,它在形式上与代表性近似:
[0034][0035]
其中和均为平均特征,在用卷积神经网络提取视频帧的特征时,为了提高运算效率采取每15帧选取一帧的策略,因此计算统一性奖励时,将15帧的平均特征作为当前帧的特征;
[0036]
总奖励值由r
div
,r
rep
,r
uni
构成,他们共同指导深度学习模型的学习;具体来说,计算出多样性、代表性、统一性的奖励值后,通过加权求和的方式将他们合并:
[0037]
r(s)=αr
div
+βr
rep
+γr
uni
ꢀꢀꢀ
(11)
[0038]
其中α+β+γ=1,三者均为超参数。
附图说明
[0039]
图1是算法整体流程图;
[0040]
图2是自注意力机制过程;
[0041]
图3是自注意力机制并行过程;
[0042]
图4是多头自注意力;
[0043]
图5是深度摘要网络;
[0044]
图6是分数对比图;
[0045]
图7是镜头片段图;
[0046]
图8是关键镜头分布图。
具体实施方式
[0047]
为了使本领域的技术人员可以更好地理解本发明,下面结合附图和实施例对本发明技术方案进一步说明。
[0048]
如图1所示,基于transformer和深度强化学习的视频摘要生成网络,包括三个部分:编码、解码、优化;
[0049]
编码部分通过goolenet提取视频帧的深度特征,将特征向量输入 transformer编码部分,首先进行位置编码,之后传入self-attention层,计算完成后进行残差连接和层正则化,最后经过前馈神经网络和再一次的残差连接和层正则化;
[0050]
视频帧经由goolenet提取深度特征后,假设共有m帧,则当前视频的特征集合可以表示为:x=x1,x2,
…
,xm,其中每个x的维度均为1024;首先要对特征进行位置编码,位置编码是transformer重要组成部分,用于弥补attention 无法获取位置信息的不足;
[0051]
位置编码的添加,首先要构造一个与输入特征同维度的矩阵pe(positional encoding),pe矩阵是二维矩阵,行表示当前视频的帧的位置,列表示帧的特征向量,对于pe矩阵的计算通过三角函数来完成,奇数位置用正弦函数,偶数位置用余弦函数,利用三角函数变换,则当前位置的pe可由上一位置的pe线性表示;
[0052]
对于pe矩阵的计算如下:
[0053][0054][0055]
其中,pos表示当前视频帧在视频帧序列中的位置索引,即pos=0,1,2
…
m-1,i 表示特征向量的维度,即i=0,1,2,
…
1/2d
model-1,d
model
是视频帧维度大小,此处 d
model
=1024;
[0056]
位置编码计算完成后,将其与输入特征集合x相加,进入encoder部分;
[0057]
首先进入多头自注意力层,即由多个自注意力层构成,以自注意力过程为例,对于输入特征x1的输出结果h1计算如图2所示;对于输入序列x,经由三个矩阵wq、wk、wv的线性映射,分别得到qj,kj,vj,j∈(1,2,3
…
m),将q1分别与 k1,k2,k3…km
进行点积运算,得到注意力分布a
1,1
,a
1,2
,a
1,3
,
…
,a
1,m
,将注意力分布经过softmax函数进行归一化得到0-1之间的注意力权重,得到注意力权重后与对应的v1,v2,v3
…
,vm相乘,相乘结束进行求和运算得到x1对
应自注意力的输出h1;自注意力不同于传统的循环神经网络,它可以并行运算,极大的提高了运算效率,并行计算的过程可以简化为图3所示;
[0058]
对于multi-headed self-attention,则是在self-attention的基础上,将其映射到若干个其他空间运算,计算过程如图4所示;以head=3,x1的计算为例,输入特征x1经由三组不同的映射矩阵,得到三组q,k,v,当前q与k进行点积运算得到一组注意力权重a,经过归一化后与v进行乘积,当前q再与其他输入特征对应的k重复该过程,得到自注意力的输出h1,1,h1,2,h1,3,将h1,1,h1,2, h1,3以首尾相接的方式进行拼接,然后经过单层的全连接神经网络得到最终输出 h1。多头自注意力计算完成后,通过前馈神经网络层,完成空间变化,增加模型的表征能力;
[0059]
解码部分由双向lstm完成,输出每一帧的重要性分数,通过标注计算出对应的loss,动态摘要是基于镜头的选择,通过算术平均将帧级分数转换成镜头分数;
[0060]
编码端完成编码后,带有注意力权重的特征向量进入解码端;如图5所示,解码端由双向长短期记忆网络组成,bilstm将视频特征集合x作为输入得到对应的隐藏状态h=h1,h2,h3,
…
hm,h由一个正向遍历和逆向遍历的lstm连接构成,通过这种方式能够获得更多的上下文信息;h计算完成后,经由全连接层和 sigmoid函数得到帧级概率p=p1,p2,p3
…
pm,即当前帧是否为关键帧的概率;为了能够生成用于后续评估的摘要,需要对p进行伯努利采样得到动作a=a1,a2,a3
…
am,选取a为1的帧组成摘要s;
[0061]
pm=σ(whm)
ꢀꢀꢀ
(3)
[0062]am
=bernoulli(pm)
ꢀꢀꢀ
(4)
[0063]
s={vm|am=1}
ꢀꢀꢀ
(5)
[0064]
其中m为当前视频对应的帧数,σ为sigmoid函数,am为伯努利采样后对应的动作,am∈(0,1),0代表当前帧不是关键帧,1代表当前帧是关键帧;vm为视频帧,s为摘要集合,即选取am值为1对应的视频帧组成的集合;
[0065]
优化部分由背包算法选出若干关键镜头组成摘要,通过强化学习完成对摘要的奖励值计算;
[0066]
基于编码器-解码器架构的模型生成了摘要,深度网络将获得奖励值r,r由奖励函数r(s)计算得到,奖励值r用于评价生成摘要的质量,深度网络通过生成更符合预期的摘要来最大化奖励值r;生成高质量的摘要是奖励函数的目标,以多样性、代表性和统一性作为奖励函数的计算指标;模型具有较强的学习能力,提升了泛化性,由于视频数据量较少,可能会出现不够准确的情况,因此引入监督学习的信息,帮助模型更好的学习特征,提升准确性;
[0067]
通过深度学习网络lstm得到了摘要s,通过对s中选中的帧进行相似性计算,即帧之间的相似性越低,则整个镜头的多样性就越高,具体来说选取不同的两帧计算它们的cosine距离,重复该过程直至每一帧都完成计算并将结果求和取平均,r
div
计算如下:
[0068][0069]
其中d(x
t
,xi)为差异性计算函数,d(x
t
,xi)函数如下:
[0070]
[0071]
根据多样性的计算可得,当两帧差异越大,则多样性分值越高;但公式在计算时没有考虑帧之间的时间距离,相距较远的两帧在差异度计算时应当被忽略,因为它们在构建原视频的主要内容时至关重要,所以设定当所选帧超过阈值范围λ则多样性分值记为最大;
[0072]
d(x
t
,xi)=1 if|t-i|>λ
ꢀꢀꢀ
(8)
[0073]
代表性奖励能够衡量摘要代表原始视频的程度;为此,将代表性奖励的计算转换为k-medoids问题,即模型选择一组中心帧使得其他帧到中心帧之间的平方误差的平均值最小,通过这种方式使模型选出的帧在整个视频中占比尽可能大,最终生成的摘要越具代表性,因此对r
rep
计算如下:
[0074][0075]
通过多样性与代表性可以得到效果良好的摘要,但为了生成更高质量且符合用户视觉逻辑的摘要,需要减少时间变化带来的片段跳跃,相邻片段巨大的变化会让用户无法理解视频内容,丢失原有故事情节;为了避免该类问题带来的影响,引入统一性奖励,用于平衡片段变化导致的信息缺失,它在形式上与代表性近似:
[0076][0077]
其中和均为平均特征,在用卷积神经网络提取视频帧的特征时,为了提高运算效率采取每15帧选取一帧的策略,因此计算统一性奖励时,将15帧的平均特征作为当前帧的特征;
[0078]
总奖励值由r
div
,r
rep
,r
uni
构成,他们共同指导深度学习模型的学习;具体来说,计算出多样性、代表性、统一性的奖励值后,通过加权求和的方式将他们合并:
[0079]
r(s)=αr
div
+βr
rep
+γr
uni
ꢀꢀꢀ
(11)
[0080]
其中α+β+γ=1,三者均为超参数。
[0081]
通过强化学习完成对agent的训练。基于策略梯度训练agent使得目标期望最大化,即在策略π
θ
下,agent做出action a
t
(a
t
决定着当前帧是否被选择);根据当前环境下的状态得到下一状态,agent通过当前获得的奖励去执行下一步at;
[0082]
训练时,通过策略函数π
θ
不断更新参数θ完成对网络的策略梯度训练,因此可以计算目标函数j(θ)的导数:
[0083][0084]
其中,pθ(a1:t)为时间序列下动作的概率分布,h
t
为深度网络中的隐藏状态。
[0085]
根据公式,无法直接计算高纬度序列下的期望,因此采用近似估计的方法计算,即对当前视频进行n次episodes然后计算平均梯度。得到了梯度的近似估计,但是由于在进行n次episodes时每次的策略都不尽相同,可能会出现较大的方差不利于模型的训练,根据文献使用奖励值减去一个基线值b来减小梯度:
[0086][0087]
其中基线b为从开始到现在的移动平均奖励;
[0088]
通过奖励值能够很好的指导模型自主学习生成效果较好的摘要,但数据集数据量较小有时会出现波动导致生成的摘要不够准确,同时考虑到生成的摘要不仅需要符合用户观感还应当准确展示视频内容。因此,在原有基础上,引入监督学习的信息,帮助模型生成更具关键信息的视频摘要。
[0089]
给定当前视频的帧序列f={f1,f2,
…
,fn},用binary crossentropy计算损失,设模型的输出x={x1,x2,
…
,xi,
…
xn},对应的标签y={y1,y2,
…
,yi,
…
yn},则binary crossentropy loss计算如下:
[0090][0091]
对于参数θ,使用随机梯度进行优化,其中l
percentage
为正则化项,用于控制摘要中帧数量的百分比,l
weight
同为正则化项,使用l2正则化调整参数θ的权重,避免过拟合出现,最终参数θ的更新如下:
[0092][0093]
基于动态摘要进行研究,测试时摘要的生成由镜头组成,模型的输出结果为帧级重要性分数,需要将其转化为镜头分数。完成转化,首先需要对视频进行镜头划分,使用kts算法得到视频跳跃点进而划分出镜头,通过对镜头中每一帧分数加和求均值得到镜头分数。按照建议,摘要的长度不宜超过原视频的15%同时还要最大化摘要分数。分数最大化问题可视为np难问题,采用0/1背包问题中的动态规划算法来完成镜头的选择:
[0094][0095][0096]
其中i表示镜头编号,j表示帧编号,k表示镜头个数,l表示视频包含的帧数,li表示第i个镜头包含帧的个数,yij表示第i个镜头中第j帧的分数, ui∈{0,1},当ui=1时表示第i个镜头被选中。
[0097]
在实验时选取其中80%作为训练集,剩余20%作为测试集。同时考虑到选取的数据不同带来的误差波动和模型复杂导致的过拟合,对两个数据集使用5 折交叉验证。对于tvsum数据集,其中的视频多为用户自主拍摄,存在着较多的边界变化,因此20个人的标注得分差异较大;对于summe数据集,其中视频多为经过编辑的结构化视频,边界变化小,标注得分差异小,根据文献中的研究,在计算f1-score时,对tvsum数据集取平均值,对summe数据集取最大值。
[0098]
为了验证统一性奖励和有监督信息对模型的影响,在两个数据集上进行了消融实验。首先对不同的方法命名,如表1所示。tl-ren为基于transformer和 lstm的深度摘要网络,其中强化学习的奖励函数使用代表性奖励(rep)和多样性奖励(div);tl-ren
l
在前者的基础上引入了有监督的信息;tl-ren
uni
为奖励函数联合使用代表性奖励、多样性奖励和统一性奖励(uni)的方法;tl-ren
ul
则是同时引入统一性奖励和有监督信息的方法。
[0099]
表1不同模块对应名称
[0100][0101]
表2展示了不同方法在两个数据集上的结果对比,从表中可以看出 tl-ren
ul
(使用了统一性和监督信息)方法在两个数据集上都取得了最好的效果,这表明该方法可以指导模型生成质量更高的视频摘要通过联合使用rep、div和 uni作为奖励函数以及引入有监督信息。此外,对比tl-ren和tl-ren
uni
可以看出统一性奖励的加入在两个数据集上的性能分别提高了0.6%和0.4%。实验结果表明,奖励函数中统一性的引入能提高升镜头的平稳性;同时,tvsum数据集存在较多的镜头变化,镜头的平稳性有助于性能的提升,因此在tvsum数据集上的表现优于summe。
[0102]
表2不同模块对应结果
[0103][0104]
为了更好的展示生成摘要的效果,以部分视频为例定性展示结果。在图6 中将展示模型预测的帧级重要性分数,以tvsum数据集中视频16为例。图中红色虚线表示人工标注的真实分数,蓝色实线代表模型预测的帧级分数。可以看到蓝色实线在总体趋势上基本能与红线保持一致,对于一些高分点和低分点的模型也能保持对应的变化,在代表性、多样性和监督信息的指导下,模型预测了更高的分数,这有利于区分低分片段和高分片段。此外,得益于统一性的引入,对于分数突变的边界,模型预测的结果也能相对保持一致,没有发生较大的错误预测。总的来说,方法预测的分数在时间轴上基本能与人工标注保持一定的关联性。证明了方法的有效性。
[0105]
根据帧级重要性分数可得到每个镜头的分数,然后通过3.1节中的算法得到关键镜头。视频16主要讲述了“在家中制作汉堡包”的故事,图7展示了该视频的部分镜头片段,
图中可以看出主人公在家展示了使用哪些原料并最终成功制作出汉堡包。下面将展示关键镜头在原视频中的分布情况。如图8所示,横轴代表时间轴,纵轴代表重要性分数,其中灰色柱状条表示人工标注的摘要,紫色柱状条表示被选为关键镜头在人工标注中的分布,实线指示了镜头对应的位置。可以看出关键镜头基本包含了视频的开头、中间和结尾部分,关键镜头的分布大多为当前区域的高分镜头且总时长不超过原视频的15%,能够概括原视频的基本内容同时符合用户观看需求。
[0106]
上述实施例仅示例性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1