一种引入关键词特征的不均衡文本分类方法与流程
1.本发明涉及一种文本分类方法,特别是一种引入关键词特征的不均衡文本分类方法。
背景技术:
2.类别不均衡是指语料中存在长尾现象,各个类别的数据量相差较大。现有的文本分类模型本质上是对损失函数的优化,最小化某个损失函数。在不均衡文本分类中,因为各个类别的样本规模不一样,会导致大规模出现的样本损失函数占比较高,最终会导致模型偏向于大规模出现的类别。
3.针对普通文本分类问题,现有的解决方法是通过预训练语言模型bert得到文本的向量表示,然后利用交叉熵损失函数进行微调。针对类别不均衡问题,主要是通过两种方式进行改进,数据方面通过数据重采样,模型方面通过修改损失函数中类别权重进行改进。但是这两种方法均无法解决稀疏类别的欠拟合问题,假设某个稀疏类别只有一个样本,但是该样本包含较多个单词,而且这些单词的组合只会出现在这个类别中。无论是重采样还是类别加权均无法解决该洗漱样本的多样性问题。
4.训练语料中类别分布是一种重要的先验信息,对于分类模型来说至关重要,因为这种信息会提示模型某种类别概率上出现的可能性,这种概率与文本内容无关,因此如何将类别分布信息引入模型是本文要解决的关键问题。如何表示类别标签,本文利用归一化点互信息(npmi)和改进信息增益(ig+)筛选类别关键词,作为类标签的先验表示,并在模型训练中将该信息引入文本分类模型。
技术实现要素:
5.发明目的:本发明所要解决的技术问题是针对现有技术的不足,提供一种引入关键词特征的不均衡文本分类方法。
6.为了解决上述技术问题,本发明公开了一种引入关键词特征的不均衡文本分类方法,包括如下步骤:
7.步骤1,构建文本分类模型,定义层级分类体系,构建类别标签,构建训练数据集;
8.步骤2,抽取文本中各类别关键词,得到关键词信息;
9.步骤3,融合关键词信息和文本语义信息进行模型训练。
10.本发明中,步骤1包括:
11.步骤1-1,定义层级分类体系,刻画类别之间的层次化关系,不同层次的标签之间通过符号-隔开,进行文章级分类;
12.步骤1-2,构建训练数据集,包括如下步骤:
13.采集训练语料;所述训练语料包括文章标题、文章内容以及文章的层级分类标签;
14.对训练语料进行预处理;所述预处理包括:将繁体字转换为简体字,全角数字和全角字母转为半角数字和半角字母;
15.将文章标题与正文采用句号拼接起来,判断长度是否超过预设的长度阈值;如果没有超过,将拼接结果作为文章;如果超过预设的长度阈值,对文章进行截断处理,将截断后的内容作为文章。
16.本发明中,步骤2包括:
17.步骤2-1:基于归一化点互信息,进行类别关键词选择;
18.步骤2-2:基于改进信息增益ig+,进行类别关键词选择;
19.步骤2-3:针对每个类别选择关键词集合。
20.本发明中,步骤2-1所述基于归一化点互信息进行类别关键词选择方法包括:
21.对步骤1-2中构建的训练数据集中的文本进行分词,形成单词序列,统计每个单词和文本类别的出现情况,单词w和类别y的归一化点互信息npmi(w,y)计算方法如下:
[0022][0023]
其中,p(w,y)表示单词w和类别y的共现次数除以训练文本总数;p(w)和p(y)分别表示单词和类别出现总数除以训练文本总数。
[0024]
本发明中,步骤2-2所述基于改进信息增益进行类别关键词选择方法包括:
[0025]
信息增益是从信息熵的角度考虑这种度量,分析一个特征项对整个系统的信息量贡献度,其缺点是未分析一个特征在一个类别内部的分布情况以及在所有类别中的分类情况,因此我们引入类内分散程度di和类间集中程度ci,采用改进信息增益ig+方法计算类别的关键词的ig+得分ig+(w,c),方法包括:
[0026]
ig+(w,c)=(di(w,c)-ci(w,c))ig(w,c)
[0027]
其中,di表示类内分散程度,表示单词w在类别为c的文本中的出现次数与该类文本出现总次数的占比,该值越大表明该单词在这类文本中分布越广,该单词更能代表该类别,计算方法为:
[0028][0029]
其中df(w,c)表示类别c中包含单词w的文本数目,df(c)表示类别c中包含的文本数目;
[0030][0031]
其中,ci(w,c)表示类间集中程度,即单词w出现类别数与总类别数的占比,该占比越小表明该单词在越少的类别中出现,越能代表这些类别,其中|c|表示类别总数目,cf(w)表示单词w出现的类别数目;
[0032]
单词w的信息增益ig(w)用来衡量单词w出现与否对于文本分类不确定性的较少程度,其计算方法包括:
[0033]
[0034]
其中,n表示文本类别总数,i表示遍历每个类别的文本;p(w)表示单词w在文本中出现的概率;p(ci|w)表示针对单词的后验概率,即包含单词w的文本属于类比ci的概率;表示文本中不含单词w的概率;表示文本不含单词w时属于类别ci的后验概率。
[0035]
本发明中,步骤2-3所述针对每个类别选择关键词集合方法包括:
[0036]
遍历每个类别,计算每个单词的npmi和ig+得分,并按照降序排列,分别选择得分最高的前10个单词作为该类别的单词表示,每个类别得到20个关键词表示。
[0037]
本发明中,步骤3所述融合关键词信息和文本信息的模型训练过程中,对于每个批处理batch:
[0038]
步骤3-1,计算单个批处理batch内文本交叉熵损失函数;
[0039]
步骤3-2,随机选择nc个类别,遍历每个类别,对于每个类别采样k个关键词,并将关键词拼接组成该类别的关键词文本;
[0040]
步骤3-3,对于关键词文本计算交叉熵损失;
[0041]
步骤3-4,计算联合损失。
[0042]
本发明中,步骤3-1所述计算单个批处理batch内文本分类的交叉熵损失函数,包括:
[0043]
对原始文本经过bert分词后首尾添加特殊标记[cls]和[eos],记为:
[0044]
x
doc
=[cls],t1,t2,...tj,...,t
l
,[eos]
[0045]
其中l为文本长度,t
l
表示bert分词后的词元。对于序列x
doc
,经过bert特征抽取后计算交叉熵损失l
doc
,方法包括:
[0046][0047]
其中,c表示类别个数,y
j,c
是样本真实标签,是文本分类模型输出样本xj属于类别c的概率,j是样本编号;
[0048]
本发明中,步骤3-2中所述随机选择nc个类别,类别数量nc的计算方法包括:
[0049]
nc=max(batch_size,c)
[0050]
其中,c表示总计类别个数,batch_size表示这个批处理内样本个数;对于当前类别c经过关键词选择后的关键词文本x
keyword
表示为:
[0051]
x
keyword
=w1,w2...wk[0052]
其中,wk为步骤2-3经过特征选择后得到的代表类别c的单词。
[0053]
本发明中,步骤3-3中所述对于关键词文本计算交叉熵损失,方法包括:
[0054]
对于关键词文本x
keyword
按照步骤3-1所述方式经过bert分词后得到其语义向量表示h
keyword
,并按照步骤3-1计算关键词后得到的交叉熵损失l
keyword
;
[0055]
步骤3-4基于文本和关键词计算联合损失,计算方法包括:
[0056]
loss=l
doc
+αl
keyword
[0057]
其中,l
doc
表示文本的交叉熵损失,l
keyword
表示关键词的交叉熵损失,α是超参数,取值为0到1。
[0058]
有益效果:
[0059]
针对不均衡文本分类问题,将类标签分布作为一种先验信息引入文本分类模型,
训练过程同时利用文本内容和类别关键词信息;利用归一化点互信息和改进的信息增益作为类别关键词选择的统计量,进行类别关键词选择;利用关键词信息和文本信息进行联合训练文本分类模型,有效的解决文本分类中的类别不均衡问题。
附图说明
[0060]
下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述和/或其他方面的优点将会变得更加清楚。
[0061]
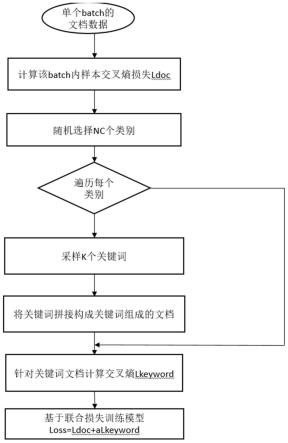
图1为本发明方法流程图。
具体实施方式
[0062]
如图1所示,一种引入关键词特征的不均衡文本分类方法,包括如下步骤:
[0063]
步骤1,构建文本分类模型,定义层级分类体系,构建类别标签,构建训练数据集;
[0064]
步骤1-1,定义层级分类体系,刻画类别之间的层次化关系,不同层次的标签之间通过符号-隔开,进行文章级分类;
[0065]
步骤1-2,构建训练数据集,包括如下步骤:
[0066]
采集训练语料;所述训练语料包括文章标题、文章内容以及文章的层级分类标签;
[0067]
对训练语料进行预处理;所述预处理包括:将繁体字转换为简体字,全角数字和全角字母转为半角数字和半角字母;
[0068]
将文章标题与正文采用句号拼接起来,判断长度是否超过预设的长度阈值;如果没有超过,将拼接结果作为文章;如果超过预设的长度阈值,对文章进行截断处理,将截断后的内容作为文章。
[0069]
步骤2,抽取文本中各类别关键词,得到关键词信息;
[0070]
步骤2-1:基于归一化点互信息,进行类别关键词选择;
[0071]
对步骤1-2中构建的训练数据集中的文本进行分词,形成单词序列,统计每个单词和文本类别的出现情况,单词w和类别y的归一化点互信息npmi(w,y)计算方法如下:
[0072][0073]
其中,p(w,y)表示单词w和类别y的共现次数除以训练文本总数;p(w)和p(y)分别表示单词和类别出现总数除以训练文本总数。
[0074]
步骤2-2:基于改进信息增益ig+,进行类别关键词选择;
[0075]
信息增益是从信息熵的角度考虑这种度量,分析一个特征项对整个系统的信息量贡献度,其缺点是未分析一个特征在一个类别内部的分布情况以及在所有类别中的分类情况,因此我们引入类内分散程度di和类间集中程度ci,采用改进信息增益ig+方法计算类别的关键词的ig+得分ig+(w,c),方法包括:
[0076]
ig+(w,c)=(di(w,c)-ci(w,c))ig(w,c)
[0077]
其中,di表示类内分散程度,表示单词w在类别为c的文本中的出现次数与该类文本出现总次数的占比,该值越大表明该单词在这类文本中分布越广,该单词更能代表该类别,计算方法为:
[0078][0079]
其中df(w,c)表示类别c中包含单词w的文本数目,df(c)表示类别c中包含的文本数目;
[0080][0081]
其中,ci(w,c)表示类间集中程度,即单词w出现类别数与总类别数的占比,该占比越小表明该单词在越少的类别中出现,越能代表这些类别,其中|c|表示类别总数目,cf(w)表示单词w出现的类别数目;
[0082]
单词w的信息增益ig(w)用来衡量单词w出现与否对于文本分类不确定性的较少程度,其计算方法包括:
[0083][0084]
其中,n表示文本类别总数,i表示遍历每个类别的文本;p(w)表示单词w在文本中出现的概率;p(ci|w)表示针对单词的后验概率,即包含单词w的文本属于类比ci的概率;表示文本中不含单词w的概率;表示文本不含单词w时属于类别ci的后验概率。
[0085]
步骤2-3:针对每个类别选择关键词集合。
[0086]
遍历每个类别,计算每个单词的npmi和ig+得分,并按照降序排列,分别选择得分最高的前10个单词作为该类别的单词表示,每个类别得到20个关键词表示。
[0087]
步骤3,融合关键词信息和文本语义信息进行模型训练。
[0088]
步骤3-1,计算单个批处理batch内文本交叉熵损失函数;
[0089]
对原始文本经过bert分词后首尾添加特殊标记[cls]和[eos],记为:
[0090]
x
doc
=[cls],t1,t2,...tj,...,t
l
,[eos]
[0091]
其中l为文本长度,t
l
表示bert分词后的词元。对于序列x
doc
,经过bert特征抽取后计算交叉熵损失l
doc
,方法包括:
[0092][0093]
其中,c表示类别个数,y
j,c
是样本真实标签,是文本分类模型输出样本xj属于类别c的概率,j是样本编号;
[0094]
步骤3-2,随机选择nc个类别,遍历每个类别,对于每个类别采样k个关键词,并将关键词拼接组成该类别的关键词文本;
[0095]
类别数量nc的计算方法包括:
[0096]
nc=max(batch_size,c)
[0097]
其中,c表示总计类别个数,batch_size表示这个批处理内样本个数;对于当前类别c经过关键词选择后的关键词文本x
keyword
表示为:
[0098]
x
keyword
=w1,w2...wk[0099]
其中,wk为步骤2-3经过特征选择后得到的代表类别c的单词。
[0100]
步骤3-3,对于关键词文本计算交叉熵损失;
[0101]
对于关键词文本计算交叉熵损失,方法包括:
[0102]
对于关键词文本x
keyword
按照步骤3-1所述方式经过bert分词后得到其语义向量表示h
keyword
,并按照步骤3-1计算关键词后得到的交叉熵损失l
keyword
;
[0103]
步骤3-4,基于文本和关键词计算联合损失,计算方法包括:
[0104]
loss=l
doc
+αl
keyword
[0105]
其中,l
doc
表示文本的交叉熵损失,l
keyword
表示关键词的交叉熵损失,α是超参数,取值为0到1。
[0106]
实施例:
[0107]
本发明提供了一种引入关键词特征的不均衡文本分类方法,首先针对军事新闻领域定义层级分类体系,包括32个叶子类别;利用归一化点互信息和改进信息增益抽取每个类别的关键词;融合关键词特征和神经网络语义特征进行训练。经过以上步骤,本发明能够有效解决类别不均衡情况下的文本分类问题。如图1所示,具体包括如下步骤:
[0108]
步骤1包括:
[0109]
步骤1-1:定义层级分类体系,刻画类别之间的层次化关系,如“协作-口头-表达意愿-实质合作”,不同层次的标签之间通过
“‑”
隔开,通过定义该标签希望为政治、军事、外交等领域的新闻提供文本级的分类功能;
[0110]
步骤:1-2:构建训练数据集,包括如下步骤:
[0111]
采集训练语料,所述训练语料包括文章标题、文章内容、文章的层级分类标签;
[0112]
对训练语料进行预处理,所述预处理包括:将繁体字转换为简体字,全角数字和全角字母转为半角数字和半角字母;
[0113]
将文章标题与正文采用句号拼接起来,判断长度是否超过预设的长度阈值;如果没有超过,将拼接结果作为文章;如果超过预设的长度阈值,对文章进行截断处理,将截断后的内容作为文章;
[0114]
步骤2-1:基于归一化点互信息(npmi)的类别关键词选择
[0115]
首先对于文本利用分词工具jieba进行分词,形成单词序列,统计每个单词和文本类别的出现情况,单词w和类别y的npmi计算公式如下:
[0116][0117]
其中p(w,y)表示单词w和类别y的共现次数除以训练文本总数;p(w)和p(y)分别表示单词或者类别出现总数除以训练文本总数。
[0118]
步骤2-2:基于改进信息增益(ig+)的类别关键词选择
[0119]
信息增益是从信息熵的角度考虑这种度量,分析一个特征项对整个系统的信息量贡献度,其缺点是未分析一个特征在一个类别内部的分布情况以及在所有类别中的分类情况,因此我们引入类内分散程度(di)和类间集中程度(ci),提出了一种改进信息增益(ig+)方法计算类别的关键词
[0120]
ig+(w,c)=(di(w,c)-ci(w,c))ig(w,c)
[0121]
其中di表示类内分散程度,表示单词w在类别为c的文本中的出现次数与该类文本出现总次数的占比,该值越大表明该单词在这类文本中分布越广,该单词更能代表该类别,其中df(w,c)表示类别c中包含单词w的文本数目,df(c)表示类别c中包含文本数目;
[0122][0123]
其中ci(w,c)表示类间集中程度,单词w出现类别数与总类别数的占比,该占比越小表明该单词在越少的类别中出现,越能代表这些类别,其中|c|表示类别总数目,cf(w)表示单词w出现的类别数目:
[0124][0125]
其中ig(w,c)表示单词w对于类别c的信息增益,c取值二分类,属于类别c和不属于类别c两种,其中p(ci)表示类别ci出现的概率,p(w)表示包含单词w的出现概率,p(ci|w)表示单词w出现时类别ci出现概率;表示单词w不出现的概率,表示单词w不出现时候类别ci出现概率
[0126][0127]
步骤2-3:每个类别选择关键词集合
[0128]
遍历每个类别,计算每个单词的npmi和ig+得分,并按照降序排列,分别选择得分最高的前10个单词作为该类别的单词表示,每个类别得到20个关键词表示。
[0129]
步骤3融合关键词信息和文本信息的模型训练过程,对于每个batch的处理:
[0130]
步骤3-1:计算单个batch的文本
[0131]
对于原始文本经过bert分词后首位添加两个特殊标记[cls]和[eos],标记为
[0132]
x
doc
=[cls],t1,t2,...,t
l
,[eos]
[0133]
其中l为文本长度,对于该序列x
doc
经过bert特征抽取后的向量标记为h
doc
,计算交叉熵损失
[0134][0135]
其中c表示类别个数,y
i,c
是样本真实标签,是模型输出样本i属于类别c的概率;
[0136]
步骤3-2:随机选择nc个类别,并且遍历每个类别,对于每个类别采样k个关键词,并将关键词拼接组成该类别的关键词文本;其中nc取值为max(batch_size,c),c表示总计类别个数,对于当前类别c经过关键词选择后的文本表示为x
keyword
=w1,w2...wk[0137]
步骤3-3:对于关键词文本计算交叉熵损失:
[0138]
对于关键词文本x
keyword
按照步骤3-1的方式经过bert得到其语义向量表示h
keyword
,
同样的方式计算关键词文本损失l
keyword
[0139]
步骤3-4:联合损失计算
[0140]
loss=ldoc+αl
keyword
[0141]
本实施例针对开源军事领域,搜集了20124篇文档,涵盖45个类别。针对其中一篇文档内容:“正在挪威访问的韩国总统xxx12日表示,希望能在美国总统xxx本月底访问韩国之前实现韩朝领导人再次会晤”,其标注类别是:协作-口头-表达意愿;利用步骤2中基于改进信息增益利用语料对该类做关键词抽取,得到该类别的关键词集合“会晤、谈判、构想、强调、希望、担忧、分享、表示、愿、开展合作、不满意、重申、遵守”;针对步骤3的训练过程,同时将原始文档内容和其类别抽取的关键词集合作为训练样本,联合训练网络模型。
[0142]
本发明提供了一种引入关键词特征的不均衡文本分类方法的思路及方法,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1