文本生成方法以及装置与流程
1.本说明书实施例涉及自然语言处理技术领域,特别涉及一种文本生成方法。
背景技术:
2.随着互联网技术的发展,越来越多针对项目场景中需要利用对象描述文本,例如,用于商品销售的商品介绍文章。随着项目场景的多样化、商品数量众多且商品的更新速度快,仅仅通过人工撰写是难以满足其对数量和即时性的要求。
3.目前,利用自然语言处理技术,学习已有人工撰写的对象描述文本的语义特征,高效地生成在文本流畅度、准确性上都符合条件的对象描述文本。
4.然而,这样生成的对象描述文本由于其过多关注于语义层面,而忽视了不同的应用场景中需要不同风格的对象描述文本,例如,当项目场景为直播销售时,口语化风格的商品介绍文章更能增强观众的代入感,当项目场景为电商平台的页面展示时,书面化风格的商品介绍文章更能体现平台和商家的专业度。如何高效地生成适用性更高且流畅又准确的对象描述文本是一个亟需解决的问题,本说明书提供了一种文本生成方法。
技术实现要素:
5.有鉴于此,本说明书实施例提供了一种文本生成方法。本说明书一个或者多个实施例同时涉及一种文本生成装置,一种计算设备,一种计算机可读存储介质以及一种计算机程序,以解决现有技术中存在的技术缺陷。
6.根据本说明书实施例的第一方面,提供了一种文本生成方法,包括:
7.获取对象属性信息和目标风格信息,其中,对象属性信息包括至少一个属性词;
8.根据各属性词,生成各属性词之间的排列顺序;
9.根据各属性词及目标风格信息,计算各属性词的目标词向量,其中,目标词向量融合了目标风格信息的风格特征;
10.根据各属性词的目标词向量,预测各属性词的上下文;
11.按照排列顺序,对各属性词和上下文进行排列,生成具有目标风格的对象描述文本。
12.根据本说明书实施例的第二方面,提供了一种文本生成装置,包括:
13.获取模块,被配置为获取对象属性信息和目标风格信息,其中,对象属性信息包括至少一个属性词;
14.排列顺序生成模块,被配置为根据各属性词,生成各属性词之间的排列顺序;
15.计算模块,被配置为根据各属性词及目标风格信息,计算各属性词的目标词向量,其中,目标词向量融合了目标风格信息的风格特征;
16.预测模块,被配置为根据各属性词的目标词向量,预测各属性词的上下文;
17.生成模块,被配置为按照排列顺序,对各属性词和上下文进行排列,生成具有目标风格的对象描述文本。
18.根据本说明书实施例的第三方面,提供了一种计算设备,包括:
19.存储器和处理器;
20.存储器用于存储计算机可执行指令,处理器用于执行计算机可执行指令,该计算机可执行指令被处理器执行时实现上述文本生成方法的步骤。
21.根据本说明书实施例的第四方面,提供了一种计算机可读存储介质,其存储有计算机可执行指令,该指令被处理器执行时实现上述文本生成方法的步骤。
22.根据本说明书实施例的第五方面,提供了一种计算机程序,其中,当计算机程序在计算机中执行时,令计算机执行上述文本生成方法的步骤。
23.本说明书一个或多个实施例中,获取对象属性信息和目标风格信息,其中,对象属性信息包括至少一个属性词,根据各属性词,生成各属性词之间的排列顺序,根据各属性词及目标风格信息,计算各属性词的目标词向量,其中,目标词向量融合了目标风格信息的风格特征,根据各属性词的目标词向量,预测各属性词的上下文,按照排列顺序,对各属性词和上下文进行排列,生成具有目标风格的对象描述文本。根据各属性词的排列顺序对各属性词和上下文进行排列,保证了生成的文本和属性词之间的对应关系,保证了生成的对象描述文本的语义一致性,提升了生成的对象描述文本的文本流畅度和准确性,根据各属性词及目标风格信息,计算目标词向量,再进一步根据目标词向量预测各属性词的上下文,使得各属性词的上下文可以体现出目标风格的风格特征,增强了对象描述文本的适用性。
附图说明
24.图1a是本说明书一个实施例提供的一种文本生成系统的结构示意图;
25.图1b是本说明书一个实施例提供的一种文本生成系统的文本生成指令发送界面的显示示意图;
26.图1c是本说明书一个实施例提供的一种文本生成系统的对象描述文本显示界面的显示示意图;
27.图2是本说明书一个实施例提供的一种文本生成方法的流程图;
28.图3是本说明书一个实施例提供的一种应用于商品摘要文本的文本生成方法的处理过程流程图;
29.图4是本说明书一个实施例提供的一种应用于商品摘要文本的文本生成方法的数据流向示意图;
30.图5是本说明书一个实施例提供的一种文本生成装置的结构示意图;
31.图6是本说明书一个实施例提供的一种计算设备的结构框图。
具体实施方式
32.在下面的描述中阐述了很多具体细节以便于充分理解本说明书。但是本说明书能够以很多不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本说明书内涵的情况下做类似推广,因此本说明书不受下面公开的具体实施的限制。
33.在本说明书一个或多个实施例中使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本说明书一个或多个实施例。在本说明书一个或多个实施例和所附权利要求书中所使用的单数形式的“一种”、
“”
和“该”也旨在包括多数形式,除非上下文清楚地表示
其他含义。还应当理解,本说明书一个或多个实施例中使用的术语“和/或”是指并包含一个或多个相关联的列出项目的任何或所有可能组合。
34.应当理解,尽管在本说明书一个或多个实施例中可能采用术语第一、第二等来描述各种信息,但这些信息不应限于这些术语。这些术语仅用来将同一类型的信息彼此区分开。例如,在不脱离本说明书一个或多个实施例范围的情况下,第一也可以被称为第二,类似地,第二也可以被称为第一。取决于语境,如在此所使用的词语“如果”可以被解释成为“在
……
时”或“当
……
时”或“响应于确定”。
35.首先,对本说明书一个或多个实施例涉及的名词术语进行解释。
36.风格:自然语言文本中词语和句子的内容形式特征。
37.语义:自然语言文本中对现实世界中的事物概念和概念间关系表述的特征。
38.图神经网络模型(gnn,graphic neural network):一种利用深度学习直接对图结构数据进行学习的神经网络模型。可以实现节点分类、边数据输出和图聚类等。
39.transformer模型:一种基于注意力机制的神经网络模型,通过注意力机制可以提取、分析自然语言文本的语义特征,生成目标文本。transformer模型的模型结构包括编码器和解码器,其中,编码器包括嵌入层,可以将输入模型的自然语言文本通过嵌入计算,编码为特征向量,然后基于注意力机制,对特征向量表征的文本上下文进行分析,通过解码层输出得到目标文本。
40.掩码:对向量中部分特征进行遮蔽的向量处理方法,通过对向量中的部分特征进行遮蔽,使得向量只保留需要保留的特征来进行后续的计算。例如,向量为(11121),通过神经网络学习,确定其中的维度2和维度3是表征某特征的维度,则对该向量的维度2和维度3设置掩码,得到(10021),可以认为该设置了掩码的向量为不包含该特征的向量。
41.目前,生成既具有某种风格特征又满足文本流畅度和准确度的对象描述文本,一种方法是根据人工撰写的风格生成预定义的模板,将表征对象属性的属性词填入模板中,生成符合特定风格的对象描述文本,然而,该方法在属性词出现遗漏、乱序等问题后,导致属性词被错误地填入到预定义的模板后引起后续的错误累积,对于属性词的质量有较高要求。
42.另一种方法是针对需要生成的对象描述文本中的词语建立映射关系表,将现有的对象描述文本中的词语转换成具有风格特征的词语,例如,现有的对象描述文本“他今天到a地来
……”
根据映射关系表,将“今天”转换为具有书面化风格的“今日”,将“到”转换为具有书面化风格的“莅临”。然而,该方法生成的对象描述文本的语义流畅度和准确度,取决于映射关系表的质量,同时,由于只关注了零散的词的转换,而忽视了整个文本词语间的顺序和联系,在保证了生成的对象描述文本具有某种风格特征的同时,难以保证语义流畅度和准确度。
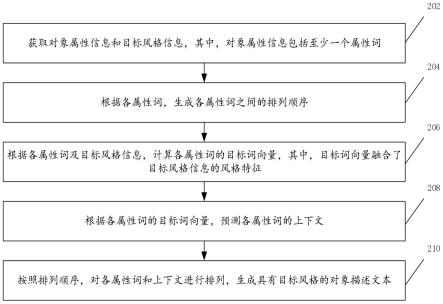
43.针对上述问题,在本说明书中,提供了一种文本生成方法,本说明书同时涉及一种文本生成装置,一种计算设备,以及一种计算机可读存储介质,在下面的实施例中逐一进行详细说明。
44.参见图1a-图1c,图1a示出了本说明书一个实施例提供的一种文本生成系统的结构示意图。
45.如图1a所示,文本生成系统包括客户端和服务端。
46.客户端:向服务端发送文本生成指令,其中,文本生成指令包括对象属性信息和目标风格信息,对象属性信息包括至少一个属性词;
47.服务端:获取对象属性信息和目标风格信息,根据各所述属性词,生成各所述属性词之间的排列顺序,根据各所述属性词及所述目标风格信息,计算各所述属性词的目标词向量,其中,所述目标词向量融合了所述目标风格信息的风格特征,根据各所述属性词的目标词向量,预测各所述属性词的上下文,按照所述排列顺序,对各所述属性词和上下文进行排列,生成具有目标风格的对象描述文本。
48.客户端:接收并显示服务端发送的具有目标风格的对象描述文本,以使用户根据对象描述文本对对象进行介绍。
49.具体地,在对象为商品时,客户端可以为直播平台的主播客户端,也可以为电商平台的服务端。
50.值得说明的是,本说明书实施例中提供的文本生成方法一般由服务端执行,但是,在本说明书的其它实施例中,客户端也可以与服务端具有相似的功能,从而执行本说明书实施例所提供的文本生成方法。在其他实施例中,本说明书实施例所提供的文本生成方法还可以是由客户端与服务端共同执行。
51.图1b示出了本说明书一个实施例提供的一种文本生成系统的文本生成指令发送界面的显示示意图。
52.如图1b所示,在客户端的文本生成指令发送界面中,具有风格信息录入框、对象属性信息录入框和生成确认控件,用户通过在风格信息录入框中录入目标风格信息,用户通过在对象属性信息录入框中录入对象属性信息,在两者都完成录入后,点击生成确认控件,将文本生成指令发送至文本生成系统的服务端来生成对象描述文本。
53.图1c示出了本说明书一个实施例提供的一种文本生成系统的对象描述文本显示界面的显示示意图。
54.如图1c所示,文本生成系统的服务端在生成对象描述文本后,将对象描述文本反馈给客户端,客户端在对象描述文本显示界面中的对象描述文本显示框中显示对象描述文本。
55.本说明书实施例中,获取对象属性信息和目标风格信息,其中,对象属性信息包括至少一个属性词,根据各属性词,生成各属性词之间的排列顺序,根据各属性词及目标风格信息,计算各属性词的目标词向量,其中,目标词向量融合了目标风格信息的风格特征,根据各属性词的目标词向量,预测各属性词的上下文,按照排列顺序,对各属性词和上下文进行排列,生成具有目标风格的对象描述文本。根据各属性词的排列顺序对各属性词和上下文进行排列,保证了生成的文本和属性词之间的对应关系,保证了生成的对象描述文本的语义一致性,提升了生成的对象描述文本的文本流畅度和准确性,根据各属性词及目标风格信息,计算目标词向量,再进一步根据目标词向量预测各属性词的上下文,使得各属性词的上下文可以体现出目标风格的风格特征,增强了对象描述文本的适用性。
56.参见图2,图2示出了本说明书一个实施例提供的一种文本生成方法的流程图,具体包括以下步骤:
57.步骤202:获取对象属性信息和目标风格信息,其中,对象属性信息包括至少一个属性词;
3078;塑料-2408;地面清洁-3306;2000w-2109)。根据目标风格信息对应的风格特征为:书面化风格,根据书面化风格,得到风格特征向量(书面化风格-002)。计算得到各属性词的目标词向量为:(0021027,0021065,0023078,0022408,0023306,0022109)。
72.根据各属性词及目标风格信息,计算各属性词的目标词向量,为后续预测各属性词的上下文奠定了数据基础。
73.步骤208:根据各属性词的目标词向量,预测各属性词的上下文;
74.各属性词的上下文为目标风格的对象描述文本中各属性词间的填充文本。
75.根据各属性词的目标词向量,预测各属性词的上下文,具体方式为,根据各属性词的目标词向量,预测在目标风格下的各属性词的上下文。
76.示例性地,各属性词的目标词向量为:(0021027,0021065,0023078,0022408,0023306,0022109),预测在书面化风格下的各属性词的上下文:
……
的吸尘器,外观颜色为
……
,尺寸为
……
,材质为
……
,具有
……
的功能,功率为
……
。
77.根据各属性词的目标词向量,预测各属性词的上下文,使得各属性词的上下文可以体现出目标风格的风格特征,为后续生成具有目标风格的对象描述文本提供了文本基础。
78.步骤210:按照排列顺序,对各属性词和上下文进行排列,生成具有目标风格的对象描述文本。
79.按照排列顺序,对各属性词和上下文进行排列,生成具有目标风格的对象描述文本,具体方式为,按照排列顺序,对各属性词和上下文进行排列并进行拼接,生成具有目标风格的对象描述文本。
80.示例性地,排列顺序为a牌-2000w-地面清洁-黑色-中号-塑料,按照排列顺序对各属性词和上下文进行排列,得到a牌
‑……
的吸尘器-功率为
……‑
2000w-具有
……
的功能-地面清洁-外观颜色为
……‑
黑色-尺寸为
……‑
中号-材质为
……‑
塑料,并进行拼接,生成具有书面化风格的对象描述文本“a牌的吸尘器,功率为2000w,具有地面清洁的功能,外观颜色为黑色,尺寸为中号,材质为塑料”。
81.本说明书实施例中,获取对象属性信息和目标风格信息,其中,对象属性信息包括至少一个属性词,根据各属性词,生成各属性词之间的排列顺序,根据各属性词及目标风格信息,计算各属性词的目标词向量,其中,目标词向量融合了目标风格信息的风格特征,根据各属性词的目标词向量,预测各属性词的上下文,按照排列顺序,对各属性词和上下文进行排列,生成具有目标风格的对象描述文本。根据各属性词的排列顺序对各属性词和上下文进行排列,保证了生成的文本和属性词之间的对应关系,保证了生成的对象描述文本的语义一致性,提升了生成的对象描述文本的文本流畅度和准确性,根据各属性词及目标风格信息,计算目标词向量,再进一步根据目标词向量预测各属性词的上下文,使得各属性词的上下文可以体现出目标风格的风格特征,增强了对象描述文本的适用性。
82.可选地,步骤204包括如下具体步骤:
83.识别各属性词的属性类型;
84.根据各属性词的属性类型,利用预先训练的排列顺序生成模型,生成各属性词之间的排列顺序。
85.排列顺序模型为一种根据属性类型之间的关联关系构建的模型。属性类型之间的
关联关系为表征属性类型之间逻辑顺序的关系,例如,对象为产品,则品牌这一属性类型是型号这一属性类型的前置条件,只有知道品牌后才能确定品牌下产品的型号,品牌和型号的逻辑顺序为品牌-型号,而不为型号-品牌。
86.排列顺序生成模型可以为一种图神经网络模型(gnn,graphic neural network),其中,各属性词的属性类型为节点,属性类型之间的关联关系为边,构建得到样本拓扑图,通过该样本拓扑图对图神经网络模型进行训练,得到可以根据各属性词的属性类型生成各属性词之间的排列顺序的生成模型。排列顺序生成模型还可以为一种树结构存储模型,其中,各属性词的属性类型为节点,属性类型之间的关联关系为边,按照树结构的层级进行存储。根据各属性词的属性类型,对排列顺序生成模型进行遍历查询,得到各属性词之间的排列顺序。
87.识别各属性的属性类型,具体方式为,根据各属性词和对应的属性类型之间的映射关系,识别各属性词的属性类型。更进一步地,利用预先训练的文本分类模型,根据各属性词和对应的属性类型之间的映射关系,识别各属性词的属性类型。或者,遍历查询预先建立的各属性词和对应的属性类型之间的映射关系表,确定各属性词的属性类型。在此不作限定。
88.示例性地,属性词为“红色,大容量,金属”,根据属性词和对应的属性类型之间的映射关系,识别各属性词的属性类型:红色-颜色,大容量-尺寸,金属-材质。根据各属性词的属性类型,利用预先训练的排列顺序生成模型,生成各属性词之间的排列顺序:红色-金属-大容量。
89.识别各属性词的属性类型,根据各属性词的属性类型,利用预先训练的排列顺序生成模型,生成各属性词之间的排列顺序。使得生成的排列顺序更加准确,更进一步地保证了生成的对象描述文本的语义一致性,更进一步地提升了生成的对象描述文本的文本流畅度和准确性。
90.可选地,在根据各属性词的属性类型,利用预先训练的排列顺序生成模型,生成各属性词之间的排列顺序之前,还包括如下具体步骤:
91.获取第一样本集,其中,第一样本集包括多个样本文本;
92.提取第一样本文本中样本对象的各样本属性词,其中,第一样本文本为第一样本集中的任一样本文本;
93.根据各样本属性词在第一样本文本中的相对位置关系,构建第一样本文本对应的属性词拓扑图;
94.利用多个样本文本及各样本文本对应的属性词拓扑图,对预设学习模型进行训练,得到排列顺序生成模型。
95.第一样本集中的多个样本文本为针对至少一个样本对象的对象描述文本,其来源可以为开源文本数据库,也可以为利用样本文本生成模型生成得到的,在此不作限定。
96.样本属性词为表征样本对象属性的属性类型下数值或者性质的词语。各样本属性词在第一样本文本中的相对位置关系为各样本属性词在第一样本文本中的前后排列顺序。
97.属性词拓扑图为以样本属性词的属性类型为节点,样本属性词之间的相对位置关系为边,构建的拓扑图,节点上存储有样本属性词。
98.预设学习模型为图神经网络模型。
99.提取第一样本文本中样本对象的各样本属性词,可以为利用预先构建的样本属性次索引表,对第一样本文本进行遍历查询,得到各样本属性词,也可以为利用预先训练的文本识别模型,将第一样本文本输入该文本识别模型后,识别得到各样本属性词。
100.根据各样本属性词在第一样本文本中的相对位置关系,构建第一样本文本对应的属性词拓扑图,具体方式为,将各样本属性词的属性类型确定为拓扑图的节点,将各样本属性词在第一样本文本中的相对位置关系确定为拓扑图中的边,得到属性词拓扑图。
101.示例性地,获取第一样本集,其中任意一个的第一样本文本为“家人们,看过来,这个红色的榨汁机,精致美观,它的榨汁桶是大容量的,一次榨汁就可以满足一家人,它的内壁还是金属的,很方便清洗”。利用预先训练的文本识别模型,提取得到样本属性词“红色,大容量,金属”,将各样本属性词的属性类型确定为拓扑图的节点,将各样本属性词在第一样本文本中的相对位置关系确定为拓扑图中的边,得到属性词拓扑图:颜色(节点1)-尺寸(节点2)-材质(节点3),利用多个样本文本及各样本文本对应的属性词拓扑图,对预设学习模型进行训练,得到排列顺序生成模型。
102.提取第一样本文本中样本对象的各样本属性词,根据各样本属性词在第一样本文本中的相对位置关系,构建第一样本文本对应的属性词拓扑图,利用多个样本文本及各样本文本对应的属性词拓扑图,对预设学习模型进行训练,得到排列顺序生成模型。根据相对位置关系构建属性词拓扑图,提升了拓扑图对于属性词间逻辑关系的表征能力,进一步利用多个样本对应的属性词拓扑图对预设学习模型进行训练,得到排列顺序生成模型,提升了排列顺序生成模型的准确度,提升了后续得到的排列顺序的准确度,提升了后续生成的对象描述文本的文本流畅性和准确度。
103.可选地,步骤206包括如下具体步骤:
104.对各属性词分别进行嵌入计算,得到各属性词对应的初始词向量;
105.对目标风格信息进行嵌入计算,得到风格向量;
106.将风格向量分别与各属性词对应的初始词向量进行融合,得到各属性词的目标词向量。
107.嵌入计算为一种对词语进行编码的方式,通过嵌入计算将自然语言文本编码成可以被神经网络模型识别的特征向量。嵌入计算具体是根据各词语间的语义特征,利用神经网络模型中的全连接层进行编码的方法。其中神经网络模型可以为transformer模型和其相关的衍生模型,对应的全连接层可以为transformer模型中的嵌入层。
108.融合为一种根据至少两个向量的指定特征,将至少两个向量合并为一个向量,使得合并后的向量具有至少两个向量的指定特征。融合可以为对向量中的元素逐个进行相加,也可以为直接进行向量拼接。具体的融合方式在此不作限定。
109.对各属性词分别进行嵌入计算,得到各属性词对应的初始词向量,具体方式为,利用transformer模型的嵌入层,对各属性词进行嵌入计算,得到各属性词对应的初始词向量。
110.对目标风格信息进行嵌入计算,得到风格向量,具体方式为,利用transformer模型的嵌入层,对目标风格信息进行嵌入计算,得到风格向量。可选地,对目标风格信息进行嵌入计算后,利用掩码机制屏蔽掉其中的语义特征,再利用池化层进行降维处理,得到风格向量。
111.示例性地,利用transformer模型的嵌入层,对各属性词“红色,大容量,金属”进行嵌入计算,得到各属性词对应的初始词向量“红色-1060,大容量-3080,金属-2416”,利用transformer模型的嵌入层,对目标风格信息“书面化风格”进行嵌入计算,利用掩码机制屏蔽掉其中的语义特征,再利用池化层进行降维处理,得到风格向量“书面化风格-002”。将风格向量分别与各属性词对应的初始词向量中的元素逐个进行相加,得到各属性词的目标词向量:(1000620,3000820,2040126)。
112.对各属性词分别进行嵌入计算,得到各属性词对应的初始词向量,对目标风格信息进行嵌入计算,得到风格向量,将风格向量分别与各属性词对应的初始词向量进行融合,得到各属性词的目标词向量。使得目标词向量融合了各属性词的语义特征和风格特征,为后续准确预测得到目标风格下的各属性词的上下文奠定了数据基础。
113.可选地,步骤208包括如下具体步骤:
114.将各属性词的目标词向量依次输入解码器进行上下文预测,获得各属性词的上下文。
115.其中,解码器的训练方式,包括:
116.获取第二样本集,其中,第二样本集包括多个样本文本,各样本文本携带有样本风格标签;
117.提取第二样本文本中样本对象的各样本属性词,其中,第二样本文本为第二样本集中的任一样本文本;
118.根据各样本属性词和样本风格标签,计算各样本属性词的样本目标词向量;
119.利用解码器对各样本属性词的样本目标词向量进行解码,得到各样本属性词的预测上下文;
120.根据第二样本文本中各样本属性词的上下文和各样本属性词的预测上下文,对解码器进行训练。
121.解码器为一种文本生成模型,解码器可以根据输入向量表征的属性词的语义特征和风格特征生成属性词对应的属性词的上下文。文本生成模型可以为rnn模型(recurrent neural network,循环神经网络模型)、transformer模型等,在此不作限定。
122.第二样本集中的多个样本文本为针对至少一个样本对象的对象描述文本,其来源可以为开源文本数据库,也可以为利用样本生成模型生成得到的,在此不作限定。
123.样本目标词向量为具有样本属性词的语义特征和风格特征的特征向量。
124.将各属性词的目标词向量依次输入解码器进行上下文预测,获得各属性词的上下文,具体方式为,将各属性词的目标词向量依次输入解码器,解码器根据该前一个目标词向量对应的属性词的上下文,结合当前目标词向量的语义特征和风格特征,预测得到目标风格对应的属性词的上下文。
125.示例性地,将目标词向量:(1000620,3000820,2040126)依次输入解码器,解码器根据1000620中的语义特征(1060)和风格特征(002),预测得到属性词“红色”的上下文为
“……
的榨汁机,其整体外观精致明亮”,再根据该上下文,结合当前目标词向量3000820中的语义特征(3080)和风格特征(002),预测得到属性词“大容量”的上下文为“其次,
……
的榨汁桶,可以实现一次1l的榨汁量”。
126.根据各样本属性词和样本风格标签,计算各样本属性词的样本目标词向量,具体
方式为,根据各样本属性词的语义特征和样本风格标签对应的风格特征,得到语义特征向量和风格特征向量,根据语义特征向量和风格特征向量计算各样本属性词的样本目标词向量。
127.利用解码器对各样本属性词的样本目标词向量进行解码,得到各样本属性词的预测上下文,利用解码器依次对样本目标词向量进行解码,得到各样本属性词的预测上下文。更进一步地,解码器根据该前一个样本目标词向量对应的样本属性词的上下文,结合当前样本目标词向量的语义特征和风格特征,得到样本风格标签对应的样本属性词的预测上下文。
128.根据第二样本文本中各样本属性词的上下文和各样本属性词的预测上下文,对解码器进行训练,具体方式为,根据第二样本文本中各样本属性词的上下文和各样本属性词的预测上下文,计算解码器的损失值,根据损失值对解码器的参数进行调整,进行迭代训练,知道解码器的损失值满足预设损失值阈值,得到训练完成的解码器。
129.将各属性词的目标词向量依次输入预先训练的解码器进行上下文预测,获得各属性词的上下文。保证了生成的文本和属性词之间的对应关系,保证了后续得到的对象描述文本的语义一致性,提升了生成的对象描述文本的文本流畅度和准确性,通过解码器进行上下文预测,使得上下文具有目标风格,进一步增强了对象描述文本的适用性。
130.可选地,根据各样本属性词和样本风格标签,计算各样本属性词的样本目标词向量,包括如下具体步骤:
131.对各样本属性词分别进行嵌入计算,得到各样本属性词对应的初始词向量;
132.对各初始词向量进行掩码处理,得到各样本属性词对应的参考词向量;
133.根据样本风格标签,分别对各参考词向量进行嵌入计算,得到各样本属性词对应的样本风格向量;
134.分别将各样本属性词对应的样本风格向量与初始词向量进行融合,得到各样本属性词的样本目标词向量。
135.初始词向量为融合了样本属性词的语义特征和风格特征的特征向量。参考词向量为不包含样本属性词的语义特征的特征向量。样本风格向量为表征样本属性词的风格特征的特征向量。
136.对初始词向量进行掩码处理,得到参考词向量,具体方式为,利用预先训练的神经网络模型,对初始词向量中的语义特征的向量维度设置掩码,得到参考词向量。
137.示例性地,利用预先训练的神经网络模型,识别出初始词向量(1760,3480,2416)中的语义特征维度为维度2,对语义特征维度设置掩码,得到不包含语义特征的参考向量(1060,3080,2016),再根据样本风格标签“口语化风格”,进行嵌入计算得到样本风格向量(002)。
138.对各样本属性词分别进行嵌入计算,得到各样本属性词对应的初始词向量;对初始词向量中的预设维度设置掩码,得到参考词向量,其中,预设维度为表征语义特征的维度;根据样本风格标签,对参考词向量进行嵌入计算,得到样本风格向量;将样本风格向量分别与各样本属性词对应的初始词向量进行融合,得到各样本属性词的样本目标词向量。先通过嵌入计算得到初始词向量,再利用掩码机制,屏蔽掉其中的语义特征后,进行嵌入计算得到样本风格向量,利用样本风格向量和初始词向量进行融合,得到准确度更高的样本
目标词向量,提升了后续对解码器的训练效果,提升了解码器的性能,提升了后续得到的预测上下文的准确度。
139.可选地,述获取第二样本集,包括如下具体步骤:
140.从直播平台获取口语化风格的商品介绍台本,和/或,从电商平台获取书面化风格的商品介绍文章;
141.根据商品介绍台本和/或商品介绍文章,构建第二样本集。
142.直播平台为至少一个进行商品展示的平台,电商平台为至少一个进行在线商品销售的平台。商品介绍台本为直播平台中主播进行商品销售的台本,商品介绍台本中包括至少一个商品的属性词。商品介绍文章为电商平台的商品详情页上对于商品的介绍文章,商品介绍文章包括至少一个商品的属性词。
143.从直播平台获取口语化风格的商品介绍台本,可以为从直播平台获取商品展示的直播视频流,对直播视频流的语音数据进行语音识别,得到语音数据对应的文本,即为商品介绍台本。也可以为查询直播平台的服务端数据库,获取商品展示的直播文本数据,即为商品介绍台本。在此不作限定。
144.从电商平台获取书面化风格的商品介绍文章,可以为利用数据获取工具,从电商平台的商品详情页获取商品介绍文章,也可以为查询电商平台的数据库,获取商品介绍文章。在此不作限定。
145.根据商品介绍台本和/或商品介绍文章,构建第二样本集,具体方式为,对商品介绍台本进行标注,得到口语化风格的样本风格标签,对商品介绍文章进行标注,得到书面化风格的样本风格标签,将经过标注的商品介绍台本和/或商品介绍文章,根据商品和样本风格标签,构建得到第二样本集。
146.示例性地,从直播平台获取b手机的直播视频流,对直播视频流的语音数据进行语音识别,得到b手机的口语化风格的商品介绍台本“超快的处理速度,丰富多彩的颜色,久到不得了的续航能力”,利用数据获取工具,从电商平台的商品详情页获取b收集的书面化风格的商品介绍文章“4.3ghz的单核处理速度,包含了黑色、白色、蓝色、红色、绿色、金色的颜色样式,128个小时的续航时间”,对两者进行口语化风格和书面化风格的样本风格标签标注后,添加至第二样本集。
147.从直播平台获取口语化风格的商品介绍台本,和/或,从电商平台获取书面化风格的商品介绍文章,根据商品介绍台本和/或商品介绍文章,构建第二样本集。针对对象为商品、直播平台和电商平台这种商品数量多、商品更新速度快的应用场景,针对性地训练解码器,使得解码器更有针对性,提升了后续生成的针对商品的对象描述文本的生成效率和准确度。
148.可选地,在获取第二样本集之后,还包括如下具体步骤:
149.根据第三样本文本,生成第四样本文本,其中,第三样本文本为第二样本集中任一样本文本,第四样本文本与第三样本文本具有不同风格;
150.识别第四样本文本的文本特征;
151.根据第四样本文本的文本特征,计算第四样本文本的样本置信度;
152.若第四样本文本的样本置信度满足预设的样本置信度条件,将第四样本文本添加至第二样本集。
153.实际应用中,由于很难获取到的不同风格的样本,会造成训练得到的解码器预测的上下文倾向于某种样本文本数量较多的风格,降低了预测的属性词的上下文的准确度,降低了后续生成的对象描述文本的风格特征表征能力,降低了对象描述文本的适用性。因此,需要在已有样本文本的基础上,提升第二样本集中样本文本的风格丰富度。
154.第四样本文本的文本特征为表征第四样本文本的词语的语义特征和整体文本的风格特征的多种特征。
155.根据第三样本文本,生成第四样本文本,具体方式为,提取第三样本文本中的属性词,根据第三样本文本的样本风格标签,确定第四样本文本的样本风格标签,根据属性词的语义特征和第四样本文本的样本风格标签,预测各属性词的上下文,对各属性词和上下文进行排列,生成第四样本文本。
156.识别第四样本文本的文本特征,具体方式为,利用预先训练的文本特征识别模型,识别第四样本文本的文本特征。
157.根据第四样本文本的文本特征,计算第四样本文本的样本置信度,具体方式为,将第四样本的文本特征中的至少一种特征设置为自变量,利用预设的样本置信度函数,计算第四样本文本的样本置信度。
158.样本置信度函数具体为:(特征i的参数)。其中,α为样本置信度,fi()为特征i的特征置信度计算公式,ωi为特征i的特征置信度的预先设定的权重。
159.示例性地,第三样本文本的样本风格标签为“口语化风格”,确定第四样本文本的样本风格标签为“书面化风格”、“文言文风格”等非“口语化风格”的样本风格标签。根据第三样本文本的属性词的语义特征和第四样本文本的样本风格标签,预测的各属性词的上下文,对各属性词和上下文进行排列,生成第四样本文本,利用预先训练的文本特征识别模型,识别第四样本文本的文本特征包括:特征1、特征2、特征3,利用上述样本置信度函数计算得到第四样本文本的样本置信度为0.77,预设样本置信度条件为0.60,第四样本文本的样本置信度满足预设样本置信度条件,将第四样本文本添加至第二样本集。
160.根据第三样本文本,生成第四样本文本,识别第四样本文本的文本特征,根据第四样本文本的文本特征,计算第四样本文本的样本置信度,若第四样本文本的样本置信度满足预设的样本置信度条件,将第四样本文本添加至第二样本集。在提升了第二样板集的样本数量的同时,提升了第二样本集的风格丰富度,使得后续训练的解码器可以更准确得到属性词的上下文,增强了对象描述文本的风格特征表征能力,增强了对象描述文本的适用性。
161.可选地,语义特征包括各词语间的关系特征、语义特征和样本风格标签中的至少一个;
162.对应地,识别第四样本文本的文本特征,包括以下步骤中的至少一个:
163.根据第四样本文本中各词语间的关系特征,计算第四样本文本的文本流畅度;
164.根据第四样本文本的文本特征和第二样本集中样本文本的语义特征,计算第四样本文本的语义相似度;
165.根据第四样本文本的样本风格标签和指定样本风格标签,计算第四样本文本的风格准确度。
166.指定样本标签为解码器预先根据第三样本文本的风格,生成的指定风格的标签。
167.各词语间的关系特征为表征文本中词语间语法关联关系和句子间语法关联关系的特征,包括例如,对于汉语而言,一般遵从“主语-谓语-宾语”的顺序语法结构,若生成的样本文本中出现了“宾语-谓语-主语”,通过这样关系特征可以认定该样本文本的文本流畅度不足,又或者,对于汉语而言,“包装”、“做工”、“精美”、“精良”,固定搭配为“包装精美”“做工精良”。
168.根据第四样本文本中各词语间的关系特征,计算第四样本文本的文本流畅度,具体方式为,根据第四样本文本中各词语间的关系特征,利用预先训练的神经网络模型,计算第四样本文本的文本流畅度。该神经网络模型为通过预先训练、具有各词语间的关系特征的特征置信度计算公式的计算功能的模型。
169.根据第四样本文本的文本特征和第二样本集中样本文本的语义特征,计算第四样本文本的语义相似度,具体方式为,根据第四样本文本的文本特征和第二样本集中样本文本的语义特征,利用预先训练的神经网络模型,计算第四样本文本的文本流畅度。该神经网络模型为通过预先训练、具有语义特征的特征置信度计算公式的计算功能的模型。
170.根据第四样本文本的样本风格标签和指定样本风格标签,计算第四样本文本的风格准确度,具体方式为,根据第四样本文本的样本风格标签和指定样本风格标签,利用预先训练的神经网络模型,计算第四样本文本的文本流畅度。该神经网络模型为通过预先训练、具有样本风格标签的特征置信度计算公式的计算功能的模型。
171.示例性地,根据第四样本文本中各词语间的关系特征,计算第四样本文本的文本流畅度为0.7,根据第四样本文本的文本特征和第二样本集中样本文本的语义特征,计算第四样本文本的语义相似度为0.3,根据第四样本文本的样本风格标签和指定样本风格标签,计算第四样本文本的风格准确度为0.9。
172.根据第四样本文本中各词语间的关系特征,计算第四样本文本的文本流畅度,根据第四样本文本的文本特征和第二样本集中样本文本的语义特征,计算第四样本文本的语义相似度,根据第四样本文本的样本风格标签和指定样本风格标签,计算第四样本文本的风格准确度。为后续计算样本置信度提供了数据基础,保证了第二样本集的有效性,提升了后续对解码器的效果,提升了对象描述文本的适用性、文本流畅度和准确度。
173.可选地,对象属性信息包括商品属性信息,目标风格信息包括书面化风格信息和/或口语化风格信息,对象描述文本包括商品摘要文本;
174.对应地,步骤202中获取目标风格信息,包括如下具体步骤:
175.获取应用场景标识;
176.根据应用场景标识,确定目标风格信息;
177.在步骤210之后,还包括如下具体步骤:
178.在目标风格信息为口语化风格信息的情况下,将具有口语化风格的商品摘要文本发送至直播平台的主播客户端;
179.在目标风格信息为书面化风格信息的情况下,将具有书面化风格的商品摘要文本发送至电商平台的服务端。
180.应用场景标识为预先根据应用场景使用的商品摘要文本的风格确定的与该风格对应的场景标识,例如,针对电商平台的应用场景,商品摘要文本要求简洁、清楚的书面化风格,对应的应用场景标识为“电商平台”,针对直播平台的应用场景,商品摘要文本要求生
196.步骤304:提取得到原文本中的商品属性信息,其中商品属性信息包括多个商品属性词;
197.继续上述示例,提取得到原文本中的商品属性信息为:功效:去除黑头;卖点:轻轻按压;起泡程度:泡沫;成分原料:氨基酸;卖点:自带打泡器;功效:预防白头;主题:yy牌洗面奶。
198.步骤306:对风格文本进行风格识别,获得目标风格信息;
199.继续上述示例,对风格文本进行风格识别,得到目标风格信息分别为“口语化风格”和“书面化风格”。
200.步骤308:识别各商品属性词的商品属性类型;
201.继续上述示例,识别各商品属性词的商品属性类型为:功效、卖点、起泡程度、成分原料、卖点、功效和主题。
202.步骤310:根据各商品属性词的商品属性类型,利用预先训练的排列顺序生成模型,生成各商品属性词之间的排列顺序;
203.继续上述示例,生成排列顺序为:主题-卖点-卖点-起泡程度-成分原料-功效-功效。
204.步骤312:对各商品属性词分别进行嵌入计算,得到各商品属性词对应的初始词向量;
205.步骤314:对目标风格信息进行嵌入计算,得到风格向量;
206.其中,对目标风格信息进行嵌入计算后,利用掩码机制屏蔽掉其中的语义特征,再经过池化层进行降维处理,得到风格向量。
207.步骤316:将风格向量分别与各商品属性词对应的初始词向量进行融合,得到各商品属性词的目标词向量;
208.步骤318:将各商品属性词的目标词向量依次输入解码器进行上下文预测,获得各商品属性词的上下文;
209.继续上述示例,针对口语化风格,获得各商品属性词的上下文为“我们家这款
……
,非常非常的好用,它本身呢,
……
,我们在洗脸的时候呢,只需要呢,
……
,就能够起很多的
……
。同时呢,我们家的这个宝贝它还富含
……
,能够起到
……
和
……
的作用,我自己在用的时候又被这款产品圈粉到”;针对书面化风格,获得各商品属性词的上下文为
“……
,
……
设计,在洁面时,只需要
……
,就可以产生丰富的
……
,无须再购买打泡器,
……
活性配方,长期使用可以
……
并能
……”
。
210.步骤320:按照排列顺序,对各商品属性词和上下文进行排列,生成具有目标风格的商品摘要文本;
211.继续上述示例,按照排列顺序,对各商品属性词和上下文进行排列,生成具有目标风格的商品摘要文本。生成具有口语化风格的商品摘要文本为“我们家这款yy牌洗面奶,非常非常的好用,它本身呢,自带打泡器,我们在洗脸的时候呢,只需要呢,轻轻按压,就能够起很多的泡沫。同时呢,我们家的这个宝贝它还富含氨基酸,能够起到去除黑头和预防白头的作用,我自己在用的时候又被这款产品圈粉到”;生成具有书面化风格的商品摘要文本为“yy牌洗面奶,自带打泡器设计,在洁面时,只需要轻轻按压,就可以产生丰富的泡沫,无须再购买打泡器,氨基酸活性配方,长期使用可以去除黑头并能预防白头”。
212.步骤322:在目标风格信息为口语化风格信息的情况下,将具有口语化风格的商品摘要文本发送至直播平台的主播客户端;
213.步骤324:在目标风格信息为书面化风格信息的情况下,将具有书面化风格的商品摘要文本发送至电商平台的服务端。
214.图4示出了本说明书一个实施例提供的一种应用于商品摘要文本的文本生成方法的数据流向示意图。
215.如图4所示,对于原文本,首先提取得到商品属性信息,其中,商品属性信息包括商品属性词,其次对商品属性词进行识别得到商品属性类型,再根据商品属性类型和商品属性词,利用排列顺序生成模型,生成各商品属性词的排列顺序,最后利用transformer的编码层,对商品属性词进行编码,得到初始词向量。对于风格文本,首先进行风格识别,得到目标风格信息,其次利用transformer的编码层对目标风格信息进行编码,再利用掩码机制屏蔽其中的语义特征,最后经过池化层的降维处理,得到风格向量。进一步地,将风格向量和初始词向量进行融合,得到目标词向量,将目标词向量依次输入transformer的解码层,得到商品属性词的上下文,按照各商品属性词的排列顺序,将商品属性词和商品属性词的上下文进行排列,得到商品摘要文本。
216.本说明书实施中,根据各商品属性词的排列顺序对各商品属性词和上下文进行排列,保证了生成的商品摘要文本和商品属性词之间的对应关系,保证了生成的商品摘要文本的语义一致性,提升了生成的商品摘要文本的文本流畅度和准确性,根据各商品属性词及目标风格信息,计算目标词向量,再进一步根据目标词向量预测各商品属性词的上下文,使得各商品属性词的上下文可以体现出目标风格的风格特征,增强了商品摘要文本的适用性,根据商品摘要文本的风格将商品摘要文本发送给对应的平台,使得平台在面对商品数量众多、商品更新速度快的问题时,可以高效快速地生成具有适应的风格且文本流畅性和准确度高的文本,节省了成本。
217.与上述方法实施例相对应,本说明书还提供了文本生成装置实施例,图5示出了本说明书一个实施例提供的一种文本生成装置的结构示意图。如图5所示,该装置包括:
218.获取模块502,被配置为获取对象属性信息和目标风格信息,其中,对象属性信息包括至少一个属性词;
219.排列顺序生成模块504,被配置为根据各属性词,生成各属性词之间的排列顺序;
220.计算模块506,被配置为根据各属性词及目标风格信息,计算各属性词的目标词向量,其中,目标词向量融合了目标风格信息的风格特征;
221.预测模块508,被配置为根据各属性词的目标词向量,预测各属性词的上下文;
222.生成模块510,被配置为按照排列顺序,对各属性词和上下文进行排列,生成具有目标风格的对象描述文本。
223.可选地,排列顺序生成模块504被进一步配置为:
224.识别各属性词的属性类型,根据各属性词的属性类型,利用预先训练的排列顺序生成模型,生成各属性词之间的排列顺序。
225.可选地,该装置还包括:
226.排列顺序生成模型训练模块,被配置为获取第一样本集,其中,第一样本集包括多个样本文本,提取第一样本文本中样本对象的各样本属性词,其中,第一样本文本为第一样
本集中的任一样本文本,根据各样本属性词在第一样本文本中的相对位置关系,构建第一样本文本对应的属性词拓扑图,利用多个样本文本及各样本文本对应的属性词拓扑图,对预设学习模型进行训练,得到排列顺序生成模型。
227.可选地,计算模块506被进一步配置为:
228.对各属性词分别进行嵌入计算,得到各属性词对应的初始词向量,对目标风格信息进行嵌入计算,得到风格向量,将风格向量分别与各属性词对应的初始词向量进行融合,得到各属性词的目标词向量。
229.可选地,预测模块508被进一步配置为:
230.将各属性词的目标词向量依次输入解码器进行上下文预测,获得各属性词的上下文;
231.对应地,该装置还包括:
232.解码器训练模块,被配置为获取第二样本集,其中,第二样本集包括多个样本文本,各样本文本携带有样本风格标签,提取第二样本文本中样本对象的各样本属性词,其中,第二样本文本为第二样本集中的任一样本文本,根据各样本属性词和样本风格标签,计算各样本属性词的样本目标词向量,利用解码器对各样本属性词的样本目标词向量进行解码,得到各样本属性词的预测上下文,根据第二样本文本中各样本属性词的上下文和各样本属性词的预测上下文,对解码器进行训练。
233.可选地,解码器训练模块被进一步配置为:
234.对各样本属性词分别进行嵌入计算,得到各样本属性词对应的初始词向量;对各初始词向量进行掩码处理,得到各样本属性词对应的参考词向量;根据样本风格标签,分别对各参考词向量进行嵌入计算,得到各样本属性词对应的样本风格向量;分别将各样本属性词对应的样本风格向量与初始词向量进行融合,得到各样本属性词的样本目标词向量。
235.可选地,解码器训练模块被进一步配置为:
236.从直播平台获取口语化风格的商品介绍台本,和/或,从电商平台获取书面化风格的商品介绍文章,根据商品介绍台本和/或商品介绍文章,构建第二样本集。
237.可选地,该装置还包括:
238.样本增强模块,被配置为根据第三样本文本,生成第四样本文本,其中,第三样本文本为第二样本集中任一样本文本,第四样本文本与第三样本文本具有不同风格,识别第四样本文本的文本特征,根据第四样本文本的文本特征,计算第四样本文本的样本置信度,若第四样本文本的样本置信度满足预设的样本置信度条件,将第四样本文本添加至第二样本集。
239.可选地,语义特征包括各词语间的关系特征、语义特征和样本风格标签中的至少一个对应地,该装置还包括:
240.语义特征识别模块,被配置为根据第四样本文本中各词语间的关系特征,计算第四样本文本的文本流畅度;根据第四样本文本的文本特征和第二样本集中样本文本的语义特征,计算第四样本文本的语义相似度;根据第四样本文本的样本风格标签和指定样本风格标签,计算第四样本文本的风格准确度。
241.可选地,对象属性信息包括商品属性信息,目标风格信息包括书面化风格信息和/或口语化风格信息,对象描述文本包括商品摘要文本;
242.对应地,获取模块502可以被进一步配置为:
243.获取应用场景标识,根据应用场景标识,确定目标风格信息;
244.对应地,该装置还包括:
245.发送模块,被配置为在目标风格信息为口语化风格信息的情况下,将具有口语化风格的商品摘要文本发送至直播平台的主播客户端,在目标风格信息为书面化风格信息的情况下,将具有书面化风格的商品摘要文本发送至电商平台的服务端。
246.可选地,获取模块502被进一步配置为:
247.获取风格文本,风格文本进行风格识别,获得目标风格信息。
248.本说明书实施例中,获取对象属性信息和目标风格信息,其中,对象属性信息包括至少一个属性词,根据各属性词,生成各属性词之间的排列顺序,根据各属性词及目标风格信息,计算各属性词的目标词向量,其中,目标词向量融合了目标风格信息的风格特征,根据各属性词的目标词向量,预测各属性词的上下文,按照排列顺序,对各属性词和上下文进行排列,生成具有目标风格的对象描述文本。根据各属性词的排列顺序对各属性词和上下文进行排列,保证了生成的文本和属性词之间的对应关系,保证了生成的对象描述文本的语义一致性,提升了生成的对象描述文本的文本流畅度和准确性,根据各属性词及目标风格信息,计算目标词向量,再进一步根据目标词向量预测各属性词的上下文,使得各属性词的上下文可以体现出目标风格的风格特征,增强了对象描述文本的适用性。
249.上述为本实施例的一种文本生成装置的示意性方案。需要说明的是,该文本生成装置的技术方案与上述的文本生成方法的技术方案属于同一构思,文本生成装置的技术方案未详细描述的细节内容,均可以参见上述文本生成方法的技术方案的描述。
250.图6示出了本说明书一个实施例提供的一种计算设备的结构框图。该计算设备600的部件包括但不限于存储器610和处理器620。处理器620与存储器610通过总线630相连接,数据库650用于保存数据。
251.计算设备600还包括接入设备640,接入设备640使得计算设备600能够经由一个或多个网络660通信。这些网络的示例包括公用交换电话网(pstn,public switched telephone network)、局域网(lan,local area network)、广域网(wan,wide area network)、个域网(pan,personal area network)或诸如因特网的通信网络的组合。接入设备640可以包括有线或无线的任何类型的网络接口(例如,网络接口卡(nic,network interface controller))中的一个或多个,诸如ieee802.11无线局域网(wlan,wireless local area networks)无线接口、全球微波互联接入(wi-max,world interoperability for microwave access)接口、以太网接口、通用串行总线(usb,universal serial bus)接口、蜂窝网络接口、蓝牙接口、近场通信(nfc,near field communication)接口,等等。
252.在本说明书的一个实施例中,计算设备600的上述部件以及图6中未示出的其他部件也可以彼此相连接,例如通过总线。应当理解,图6所示的计算设备结构框图仅仅是出于示例的目的,而不是对本说明书范围的限制。本领域技术人员可以根据需要,增添或替换其他部件。
253.计算设备600可以是任何类型的静止或移动计算设备,包括移动计算机或移动计算设备(例如,平板计算机、个人数字助理、膝上型计算机、笔记本计算机、上网本等)、移动电话(例如,智能手机)、可佩戴的计算设备(例如,智能手表、智能眼镜等)或其他类型的移
动设备,或者诸如台式计算机或pc的静止计算设备。计算设备600还可以是移动式或静止式的服务器。
254.其中,处理器620用于执行如下计算机可执行指令,该计算机可执行指令被处理器执行时实现上述文本生成方法的步骤。
255.上述为本实施例的一种计算设备的示意性方案。需要说明的是,该计算设备的技术方案与上述的文本生成方法的技术方案属于同一构思,计算设备的技术方案未详细描述的细节内容,均可以参见上述文本生成方法的技术方案的描述。
256.本说明书一实施例还提供一种计算机可读存储介质,其存储有计算机可执行指令,该计算机可执行指令被处理器执行时实现上述文本生成方法的步骤。
257.上述为本实施例的一种计算机可读存储介质的示意性方案。需要说明的是,该存储介质的技术方案与上述的文本生成方法的技术方案属于同一构思,存储介质的技术方案未详细描述的细节内容,均可以参见上述文本生成方法的技术方案的描述。
258.本说明书一实施例还提供一种计算机程序,其中,当计算机程序在计算机中执行时,令计算机执行上述文本生成方法的步骤。
259.上述为本实施例的一种计算机程序的示意性方案。需要说明的是,该计算机程序的技术方案与上述的文本生成方法的技术方案属于同一构思,计算机程序的技术方案未详细描述的细节内容,均可以参见上述文本生成方法的技术方案的描述。
260.上述对本说明书特定实施例进行了描述。其它实施例在所附权利要求书的范围内。在一些情况下,在权利要求书中记载的动作或步骤可以按照不同于实施例中的顺序来执行并且仍然可以实现期望的结果。另外,在附图中描绘的过程不一定要求示出的特定顺序或者连续顺序才能实现期望的结果。在某些实施方式中,多任务处理和并行处理也是可以的或者可能是有利的。
261.计算机指令包括计算机程序代码,计算机程序代码可以为源代码形式、对象代码形式、可执行文件或某些中间形式等。计算机可读介质可以包括:能够携带计算机程序代码的任何实体或装置、记录介质、u盘、移动硬盘、磁碟、光盘、计算机存储器、只读存储器(rom,read-only memory)、随机存取存储器(ram,random access memory)、电载波信号、电信信号以及软件分发介质等。
262.需要说明的是,对于前述的各方法实施例,为了简便描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本说明书实施例并不受所描述的动作顺序的限制,因为依据本说明书实施例,某些步骤可以采用其它顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于优选实施例,所涉及的动作和模块并不一定都是本说明书实施例所必须的。
263.在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其它实施例的相关描述。
264.以上公开的本说明书优选实施例只是用于帮助阐述本说明书。可选实施例并没有详尽叙述所有的细节,也不限制该发明仅为的具体实施方式。显然,根据本说明书实施例的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本说明书实施例的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本说明书。本说明书仅受权利要求书及其全部范围和等效物的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1