一种区块链二部图不平衡数据集上的无监督异常用户检测方法
1.本发明涉及信息技术领域,尤其涉及一种不平衡区块链交易数据上的无监督异常用户检测方法。
背景技术:
2.图数据集上异常检测模型主要分为两类。一类是基于全局属性进行异常结构检测的模式挖掘算法;另一类主要利用图神经网络模型(gnn)对局部邻域信息进行特征聚合的特征学习方法。然而,单独使用其中一种方法时往往无法兼顾到图结构在全局和邻域上所表征出的信息,导致效果往往不尽如人意。因此现在趋向于结合两类模型实现更有效的异常检测。
3.异常检测方法面临的一个重大挑战是数据中的少数类与多数类存在样本数量差别极大的问题(数据不平衡问题),如在区块链数据中,异常用户群体数目远低于正常用户群体,这样造成了如果不能充分处理好不平衡数据中模型的训练方式,最终会造成模型会对少数类的异常用户产生过拟合而无法准确监测处异常用户。并且数据样本个体的邻域特征分布情况也不尽相同,例如对于一个少数类群体的边缘节点,其邻居节点中多数节点或与自身并不属于同一类。如果在区块链交易数据对应的用户-商品二部图上,不充分考虑这些情况,则会大大增加这些用户节点被误判的可能性。在不平衡数据集中存在的易被误判节点严重影响着最终模型的检测精度。
4.而对以上问题,现有针对不平衡数据集的模型训练方法多使用欠采样/过采样方式避免不平衡数据集上模型训练会出现的问题,或是通过人工生成少数类节点数据对象来进行规避。但针对在不平衡数据集训练无监督学习模型的有效方法似乎还没有较好的解决方式,即使是对这个问题做了针对性改进并且取得较好效果的pamful模型也只是将不平衡数据集中各不平衡类节点群体视为一个整体,对群体中个体总数在训练过程中进行一定补偿避免过拟合情况的出现。但这样的处理方式也并未充分挖掘二部图中各个节点的邻域拓扑结构信息,不可避免地造成了对易被误判节点的检测准确度不足的问题,从而也大大限制了pamful模型在无标签的区块链交易数据上异常用户的检测精度。
技术实现要素:
5.为了解决现有模型在无标签的不平衡数据集上遇到的问题,尤其是识别检测易被误判用户节点时存在的困难和挑战,本发明提供了一种区块链交易数据的无监督异常用户检测方法,拟通过充分挖掘二部图中各节点邻域拓扑结构信息,对不同类型的节点进行相应的补偿而避免出现模型训练的过拟合等情况,从而解决现有模型在无标签的二部图不平衡数据集中异常用户检测精度不足的问题。
6.一种针对区块链交易数据的无标签异常用户检测方法,其特征在于,包括以下步骤:
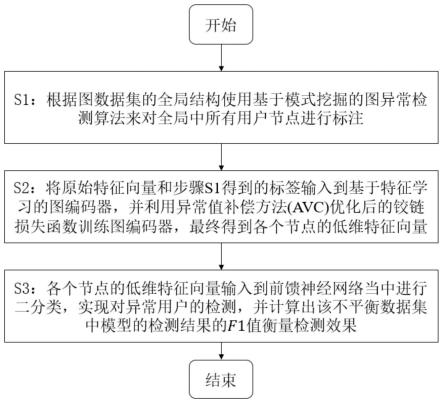
7.步骤1:根据区块链二部图不平衡数据集上的全局结构,使用基于模式挖掘的图异常检测算法来对全局中所有用户节点进行标签;
8.步骤2:将各个用户节点的原始特征向量和步骤s1得到的标签输入到基于特征学习的图编码器,再根据异常值补偿方法(anomaly value compensation,avc)优化的铰链损失函数训练图神经网络,得到各个节点的低维特征向量;
9.步骤3:将图编码器输出的各个节点的低维特征向量输入到前馈神经网络当中进行二分类,实现对异常用户的检测,并计算出该不平衡数据集中模型对测试集的f1值,根据f1值衡量检测效果。
10.优选的,所述步骤1主要任务为:
11.对于无监督的基于模式挖掘的图异常检测算法,主要可以将其分为两类:群体异常检测算法和个体异常检测算法,这些算法都是根据二部图的全局结构来对用户节点进行分类。
12.群体异常检测算法:群体异常检测算法是通过检测图邻接矩阵的密集块来发掘异常节用户。
13.个体异常检测算法:个体异常检测算法旨在根据各个节点的图结构信息来寻找整个图结构中的离群点以判定异常用户。
14.利用上述异常检测算法,完成步骤1所述的对所有用户节点标签的标注。
15.优选的,所述步骤2包括以下步骤:
16.步骤2.1:构建基于特征学习的图编码器,对编码器进行定义,根据异常值补偿方法(avc)构建图编码器损失函数;
17.步骤2.2:将数据集中各个节点的原始特征向量及标签输入图编码器;
18.步骤2.3:以最小化图编码器损失函数为目标,使用随机梯度下降法对图编码器进行更新,得到最终各个用户节点的低维特征向量;
19.优选的,所述基于特征学习的图编码器的构建步骤如下所述:
20.定义用户节点u基于模式挖掘的图异常检测算法得到的标签为yu;
21.定义输入空间input space:
22.定义输出空间output space:
23.定义神经网络模型neural network:φ(;w):x
→
f;
24.神经网络模型权重w={w1,
…
,w
l
},l∈n,n为隐藏层层数;
25.定义训练数据:x={u1,
…
,un}
26.定义函数f:u
→
rd;
27.定义函数g:u
×u→
r用于描述用户节点u和u
′
的相似度为:
28.g(u,u
′
)=f(u)
t
·
f(u
′
)
29.构造图编码器损失函数为:
[0030][0031]
其中,v是用户节点u的邻居用户,mu是异常值补偿方法(avc)计算出的补偿内容。
[0032]
优选的,所述步骤3包括以下步骤:
[0033]
步骤3.1:构建用于二分类的前馈神经网络,对前馈神经网络进行定义;
[0034]
步骤3.2:将步骤2中图编码器输出的用户节点的低维特征向量输入到前馈神经网络中;
[0035]
步骤3.3:以前馈神经网络损失函数最小为目标,使用随机梯度下降法对前馈神经网络进行更新,实现对所有节点的分类;
[0036]
步骤3.4:根据测试集的检测结果,计算出相应的精确率(precision),召回率(recall)和f1值,根据得到的f1值衡量异常用户检测性能的优劣;
[0037]
优选的,在构建需要的基于特征学习的图编码器时,使用异常值补偿方法(avc)对传统的铰链损失函数进行补偿来构造新的损失函数。
[0038]
定义的异常值补偿方法(avc)将对用户节点u的补偿分为两个部分:群体异常值(group anomaly value,gav)和个体异常值(individual anomaly value,iav)。其中个体异常值又分为了两个部分:连接离群值(connectivity outlier value,cov)和分布偏移值(distribution deviation value,ddv)。异常值补偿方法(avc)的计算步骤为:
[0039]
步骤2.3.1:计算群体异常值(gav),即将同一类节点视为一个群体,根据该群体中个体数量进行补偿,定义用户节点u的群体异常值(gav)为:
[0040][0041]
其中,为标签为yu的用户总数,c为常数。
[0042]
步骤2.3.2:计算个体异常值(iav),即根据各个节点的邻域拓扑结构所蕴含的特征信息来实现对损失函数的一个补偿。个体异常值(iav)的补偿内容又分为了连接离群值(cov)和分布偏移值(ddv)两部分。
[0043]
步骤2.3.2.1:计算连接离群值(cov)。
[0044]
首先规定在二部图中,用户群体中各用户节点的二跳邻居节点为该用户节点的邻居用户。
[0045]
在用户集合u中,用户个体总数记为|u|,其中用户v的标签记为
[0046]yv
则用户v的非同类节点标签记为其中对于用户v,其邻居用户的集合记为该集合中个体总数即为节点v的邻居用户总数记为dv。在此之上。定义用户邻居分布矩阵和全局连接状态矩阵来计算个体异常值(iav)。
[0047]
用户邻居分布矩阵:用户邻居分布矩阵是用来表示各个用户节点不同类
[0048]
别的邻居用户的分布比例,其计算方式为:
[0049][0050]
表示用户集合u中用户i其邻居用户中标签为yv=j邻居的所占比例。
[0051]
全局连接状态矩阵:全局连接状态矩阵是用来表示在整个用户集合中,每种标签的用户的不同类别邻居用户分布比例的平均值,其计算方式为:
[0052]
[0053]
结合以上定义,为描述易被误判的用户节点,即那些邻居用户的标签分布与该类别的邻居用户分布的平均值存在较大差距的节点,使用js散度(jensen-shannon divergence)将用户节点u的连接离群值(cov)计算方式定义为:
[0054][0055]
步骤2.3.2.2:计算分布偏移值(ddv)。
[0056]
对于离群点v,为计算出其邻居用户的标签分布比例与该类别邻居用户分布比例平均值之间的偏移量,即计算相较于偏移程度,以对图编码器损失函数进行更精确的补偿,定义了分布偏移值(ddv)衡量这一指标。结合以上规定,在向量空间内,将
[0057]
用户节点u的分布偏移值(ddv)定义为:
[0058][0059]
最终,通过对连接离群值(cov)和分布偏移值(ddv)乘上合适的系数并相加,便实现了对单独节点邻域拓扑结构的较为完整的描述,借此挖掘出各个节点邻域拓扑结构所蕴含的结构信息,从而对用户节点u个体异常值(iav)的计算定义为:
[0060][0061]
其中,α,β为超参数;
[0062]
步骤2.3.3:将分别从群体角度和各个节点邻域拓扑结构的角度出发计算得到的群体异常值(gav)和个体异常值(iav)相加便是异常值补偿方法(avc)中最终对铰链损失函数中间隔(margin)的针对性补偿,定义为:
[0063][0064]
得到最终异常值补偿方法(avc)改进后的铰链损失函数用于图编码器的训练,其表达式为:
[0065][0066]
本发明的增益效果包括:
[0067]
1.本发明提出的异常用户检测模型可以充分挖掘二部图中全局结构中的群体特征信息和各节点邻域拓扑结构信息,实现无标签的区块链交易数据上的异常用户有效检测。
[0068]
2.本发明中提出的异常值补偿方法(avc)具有普适性,可以应用于任意使用铰链损失函数进行训练的图编码器。
[0069]
3.本发明提出的模型识别精度高。由于现实中用于异常用户检测的真实数据集往往会出现异常用户群体与正常用户群体数量差距极大,且部分群体边缘个体由于邻域拓扑结构的特殊性易被误判的情况。本发明中的异常值补偿方法(avc)可以根据各个节点所在类别的群体特征信息和邻域拓扑结构特征信息在模型训练过程中进行相应补偿,避免了不平衡数据集上容易出现的过拟合等问题,从而较好地对不平衡数据集中易被误判节点进行处理,最终较大的提升了异常用户检测模型对不平衡数据集中异常用户的识别精度。
附图说明
[0070]
图1为本发明提出的一种区块链二部图不平衡数据集上的无监督异常用户检测及评估方法的流程图。
[0071]
图2为本发明中在区块链数据集上邻居用户节点选取的示意图。
[0072]
图3为各用户节点相关特征向量在向量空间中的分布示意图。
具体实施方式
[0073]
为使本技术实施例的目的、技术方案和有点更加清楚,下面结合本技术实施例中幅图,对本实施例中的技术方案进行清楚、完整地描述,显然。所描述的实施例近视本技术一部分实施例,而不是全部的实施例。
[0074]
下面结合附图1到附图3对本发明的具体实施例做详细的说明:
[0075]
一种区块链二部图不平衡数据集上的无监督异常用户检测方法,其特征在于,包括以下步骤:
[0076]
步骤1:根据区块链二部图不平衡数据集上的全局结构,使用基于模式挖掘的图异常检测算法来对所有用户节点进行标签;
[0077]
本实施例中所采用的数据集是一个
‘
bitcoinalpha’数据集,该数据集是alpha平台上区块链交易用户的信任度网络,图数据集中的每条边都带有一个相关的权重表示一名用户的评分。该数据集中的二部图网络是由3275个用户和3742个项目节点组成。每个用户都有一个由独热编码组成的维度为148的特征向量来表示每个用户评分情况、两次评分时间间隔等用户特征。
[0078]
所述步骤1主要任务为:
[0079]
对于无监督的基于模式挖掘的图异常检测算法,主要可以将其分为两类:群体异常检测算法和个体异常检测算法,这些算法都是根据二部图的全局结构来对用户节点进行分类。
[0080]
群体异常检测算法:群体异常检测算法是通过检测图邻接矩阵的密集块来发掘异常节用户。
[0081]
个体异常检测算法:个体异常检测算法旨在根据各个节点的图结构信息来寻找整个图结构中的离群点以判定异常用户。
[0082]
在本次实施例中,共选用了涵盖了群体异常检测和个体异常检测算法的七种主流的图异常检测算法对数据集中的用户进行标注,分别为:
[0083]
群体异常检测算法:
[0084]
lockinfer:根据区块链数据集中原始数据,在图的邻接矩阵和谱子空间的视角下筛选出异常群体,以此对各个节点进行标注;
[0085]
fraudar:根据区块链数据集中原始数据,根据图中子网络计算出的理论边界密度捕获善于伪装的异常用户。
[0086]
catchsync:根据区块链数据集中原始数据,通过捕获评级网络和社交网络中的同步行为模式来检测异常用户。
[0087]
个体异常检测算法:
[0088]
lockinfer_r:与lockinfer检测算法相反,先检测出多个密度块直到剩余节点组
成的密度块密度极低,视这些节点为异常节点。
[0089]
fraudar_r:与fraudar检测算法相反,先检测出多个密度块直到剩余节点组成的密度块密度极低,视这些节点为异常节点。
[0090]
fraudeagle:使用置信度传播算法(belief propagation算法),对每个用户节点赋予一个分数用以表示其成为欺诈用户置信度,那些与大多数用户不同的边缘用户分数较高将并视其为异常用户;
[0091]
birdnest:通过利用贝叶斯模型对用户评分时间戳和评分分布进行排序实现异常用户检测;
[0092]
根据上述现在主流的七种图异常检测算法,可以实现在无标签的区块链交易数据中对用户群体内所有个体进行标签,并将该标签作为一个独热编码用于后续的图编码器的训练和最终前馈神经网络中用户个体的二分类。
[0093]
步骤2:将各个用户节点的原始特征向量和步骤s1得到的标签输入到基于特征学习的图编码器,再根据异常值补偿方法(avc)优化的铰链损失函数训练图神经网络,得到各个节点的低维特征向量;
[0094]
所述步骤2包括以下步骤:
[0095]
步骤2.1:构建基于特征学习的图编码器,对编码器进行定义,根据异常值补偿方法(avc)构建图编码器损失函数;
[0096]
步骤2.2:将数据集中各个节点的原始特征向量及标签输入图编码器;
[0097]
步骤2.3:以最小化图编码器损失函数为目标,使用随机梯度下降法对图编码器进行更新,得到最终各个用户节点的低维特征向量;
[0098]
对于所述步骤2.1,在本实施例中,基于特征学习图编码器选用graphsage模型。使用2层图神经网络来搭建本次实例中的graphsage图编码器。在单层图神经网络各个用户节点特征向量聚合的过程中,使用随机游走算法选取与目标节点余弦相似度最高的15个节点作为邻居节点进行聚合,在实现较好的特征向量聚合效果的同时,又避免了数据集中邻居用户节点过多导致聚合过程运算成本过高的问题。而对graphsage图编码器中单层图神经网络的定义为:
[0099]
定义输入空间input space:
[0100]
定义输出空间output space:
[0101]
定义神经网络模型neural network:φ(;w):x
→
f;
[0102]
神经网络模型权重w={w1,
…
,w
l
},l∈n,n为隐藏层层数;
[0103]
定义用户节点u基于模式挖掘的图异常检测算法得到的标签为yu;
[0104]
定义训练数据:x={u1,
…
,un};
[0105]
定义函数f:u
→
rd;
[0106]
定义函数g:u
×u→
r用于描述用户节点u和u
′
的相似度为:
[0107]
g(u,u
′
)=f(u)
t
·
f(u
′
)
[0108]
构造图编码器损失函数为:
[0109][0110]
其中,v是用户节点u的邻居用户,mu是异常值补偿方法(avc)计算出的补偿内容。
[0111]
所述步骤2.3中使用异常值补偿方法(avc)来构造用于训练图编码器的损失函数。定义的异常值补偿方法(avc)将对用户节点u的补偿分为两个部分:群体异常值(gav)和个体异常值(iav)。其中个体异常值又分为了两个部分:连接离群值(cov)和分布偏移值(ddv)。在不平衡的区块链数据集中,具体的计算步骤为:
[0112]
步骤2.3.1:计算群体异常值(gav),即将同一类节点视为一个群体,根据该群体中个体数量进行补偿,定义用户节点u的群体异常值(gav)为:
[0113][0114]
其中,为用户集合u中标签为yu的用户总数,c为常数。在本实施例中,实验得超参数c取得20时效果最佳。
[0115]
步骤2.3.2:计算个体异常值(iav),即根据各个节点的邻域拓扑结构所蕴含的特征信息来实现对损失函数的一个补偿。个体异常值(iav)的补偿内容又分为了连接离群值(cov)和分布偏移值(ddv)两部分。
[0116]
步骤2.3.2.1:计算连接离群值(cov)。
[0117]
首先规定在二部图中,用户群体中各用户节点的二跳邻居节点为该用户节点的邻居用户。
[0118]
在用户集合u中,用户个体总数记为|u|,其中用户v的标签记为yv,则用户v的非同类节点标签记为其中对于用户v,其邻居用户的集合记为该集合中个体总数即为节点v的邻居用户总数记为dv。在此之上。定义用户邻居分布矩阵和全局连接状态矩阵来计算个体异常值(iav)。
[0119]
用户邻居分布矩阵:用户邻居分布矩阵是用来表示各个用户节点不同类
[0120]
别的邻居用户的分布比例,其计算方式为:
[0121][0122]
表示用户集合u中用户i其邻居用户中标签为yv=j邻居的所占比例。
[0123]
全局连接状态矩阵:全局连接状态矩阵是用来表示在整个用户集合中,每种标签的用户的不同类别邻居用户分布比例的平均值,其计算方式为:
[0124][0125]
在本实施例的区块链交易数据集中,根据以上规定,连接有相同那个项目节点的用户节点互为二跳邻居节点,因此它们互为邻居节点,在进行用户邻居分布矩阵和全局连接状态矩阵的计算时均是以这些邻居节点作为原始数据进行计算。对不平衡的区块链二部图数据而言,如图2所示,用户集合u中用户个体u2,u3,u5为用户u1的二跳邻居节点,也就是在用户集合u中用户u1的邻居用户。
[0126]
经过定义公式可以计算得到用户邻居分布矩阵来描述区块链中数据集中3275个用户节点的邻居用户的标签分布比例和全局连接状态矩阵来描述两
种标签的用户群体其邻居用户标签分布比例的整体特性。
[0127]
结合以上定义,为描述易被误判的用户节点,即那些邻居用户的标签分布与该类别的邻居用户分布的平均值存在较大差距的节点,使用js散度(jensen-shannon divergence)将用户节点u的连接离群值(cov)计算方式定义为:
[0128][0129]
根据以上分析,对于易被误判的用户节点,其邻居用户的标签分布与该类别的邻居用户分布的平均值存在较大的差距,把这些点称为“连接离群点”。为了准确分离出这些“连接离群点”,在连接离群值(cov)的计算过程中,使用js散度(jensen-shannon divergence)来衡量两个分布的相似程度。越大,即和越不相似,说明节点v越倾向于被认为是“连接离群点”。接着再比较和的相似程度,越小,即和越相似,节点v的邻居标签分布与非本类连接模式相似,说明节点v越倾向于被认为是“连接离群点”。
[0130]
这样做的动机在于:对于离群程度较高的节点,希望通过计算出更大连接离群值(cov)来增大对铰链损失函数中的margin值的补偿,使模型能够更清晰的将这些“连接离群点”分离出来而避免分类出错。
[0131]
步骤2.3.2.2:计算分布偏移值(ddv)。
[0132]
对于离群点v,为计算出其邻居用户的标签分布比例与该类别邻居用户分布比例平均值之间的偏移量,即计算相较于偏移程度,以对图编码器损失函数进行更精确的补偿,定义了分布偏移值(ddv)衡量这一指标。结合以上规定,在向量空间内,将
[0133]
用户节点u的分布偏移值(ddv)定义为:
[0134][0135]
这样若在向量空间中记向量向量为向量在向量方向上的投影。在区块链数据集中,对于非“连接离群点”而言,其相关特征在向量空间上的分布如图3(a)所示,此时节点v的分布偏移值通常为负且绝对值极小或直接取得正值。而对于“连接离群点”而言,其相关特征在向量空间内的分布如图3(b)所示,因为与相偏离而与相接近,使得此时通常为负且绝对值较大。因此通过在前加上合适的负系数便可以实现对“连接离群点”施加更大的补偿从而使得模型更清晰的将这些离群点分离出来。
[0136]
通过对连接离群值(cov)和分布偏移值(ddv)乘上合适的系数并相加,便实现了对单独节点邻域拓扑结构的描述,借此挖掘出各个节点邻域拓扑结构所蕴含的结构信息实现了对用户节点u个体异常值(iav)的计算为:
[0137][0138]
其中,α,β为超参数;
[0139]
步骤2.3.3:将分别从群体角度和各个节点邻域拓扑结构的角度出发计算得到的群体异常值(gav)和个体异常值(iav)相加便是异常值补偿方法(avc)中最终对铰链损失函数中间隔(margin)的针对性补偿,定义为:
[0140][0141]
得到最终异常值补偿方法(avc)改进后的铰链损失函数用于图编码器的训练,其表达式为:
[0142][0143]
步骤3:将图编码器输出的各个节点的低维特征向量输入到前馈神经网络当中进行二分类,实现对异常用户的检测,并计算出该不平衡数据集中模型对测试集的f1值,根据f1值衡量检测效果。
[0144]
所述步骤3主要包括以下步骤:
[0145]
步骤3.1:构建用于二分类的前馈神经网络,对前馈神经网络进行定义;
[0146]
步骤3.2:将步骤2中图编码器输出的用户节点的低维特征向量输入到前馈神经网络中;
[0147]
本实施例中,使用3层全联接的前馈神经网络(多层感知机,mlp)将所有节点进行二分类,以graphsage图编码器产生的低维特征向量作为输入内容,二维的独热编码作为最后一层前馈神经网络的输出内容,实现对数据集中所有用户节点的分类。
[0148]
步骤3.3:以前馈神经网络损失函数最小为目标,使用随机梯度下降法对前馈神经网络更新,实现对所有节点的分类;
[0149]
本实施例中,用于训练二分类前馈神经网络的损失函数是log_softmax损失函数。
[0150]
步骤3.4:根据测试集的检测结果,计算出相应的精确率(precision),召回率(recall)和f1值,根据得到的f1值衡量异常用户检测性能的优劣;
[0151]
在本实施例中,前馈神经网络的最终分类结果就是最终在区块链不平衡数据集中异常用户的检测结果,其中检测出的正常用户标签为1异常用户标签为0。由于在该区块链数据集中,异常用户数量与正常用户数量存在较大差距,因此f1值更适合作为衡量异常用户检测性能优劣的指标,其中精确率(precision),召回率(recall)和f1值的具体计算公式如下:
[0152]
记正常用户为p,异常用户为n,t代表预测正确,f代表预测错误,则使用tp、fp、fn、tn记录各点预测标签与实际标签的分布情况如表1所示:
[0153]
表1各类型节点预测标签与实际标签的分布情况
[0154][0155]
精确度
[0156]
召回率
[0157][0158]
在无标签的区块链二部图不平衡数据集上,七种基于模式挖掘的图异常检测算法(包括三种群体异常检测算法和四种个体异常检测算法)与graphsage图编码器组成pamful模型的异常检测结果数据作为基线和本实施例中提出的异常值补偿方法(avc)改进后的模型其异常检测结果数据对比,如表2所示:
[0159]
表2本实施例中各个模型试验结果数据及基线数据
[0160]
[0161]
[0162][0163]
(其中异常值补偿方法(avc)括号内的α,β分别表示对不同pamful模型得到最佳优化效果时对应的超参数取值)
[0164]
从表2可以发现:
[0165]
(1)通过异常值补偿方法(avc)的优化,7种常用的图挖掘算法分别和graphsage图编码器所组成的用异常值补偿方法(avc)的改进模型其性能都得到了不同程度的提升。对于分别由群体异常检测和个体异常检测算法组成的pamful模型而言,异常值补偿方法(avc)的优化均取得了较好的效果。
[0166]
(2)在所有的7种pamful模型当中,异常值补偿方法(avc)对由fraudeagle与graphsage所组成的pamful模型提升效果最为显著。当超参数设置为α=0,β=-2.5时,异常值补偿方法(avc)将该模型在测试集上的f1值从0.6250提升到了0.7719,提升幅度达到了0.1469。
[0167]
(3)部分情况下,当α=0时,异常值补偿方法(avc)对pamful模型的改进效果得到最佳。原因可能是对于该图挖掘算法组成的pamful模型,分布偏移值(ddv)已经能够较好的反映出易被误判点的异常情况,使异常值补偿方法(avc)仅通过分布偏移值就可以对确定出这些易被误判点的margin较为合适的补偿。
[0168]
因此,在实际的不平衡图数据集上,异常值补偿方法(avc)对于不平衡学习有较为理想的提升效果,使数据集中的异常节点检测精度得到较为理想的提升。
[0169]
综上所述,本发明针对区块链交易数据提出的无监督异常用户检测方法具有较高精度检测精度的优点。通过在不平衡数据集上使用异常值补偿方法(avc)根据各个节点所在类别的群体特征信息和邻域拓扑结构特征信息在模型训练过程中进行相应补偿,避免了不平衡数据集上容易出现的过拟合问题,从而较好地对不平衡数据集中易被误判节点进行处理,最终较大的提升了异常用户检测模型对不平衡数据集中异常用户的识别精度。并且在实际的数据集上,根据不同数据集选择合适的超参数进行调整,使异常值补偿方法(avc)对损失函数最终进行一个合理的补偿,可以普遍得到相较于传统异常检测模型一个较为理想的提升效果。通过本发明,相关金融、社交媒体等平台可以借助该模型实现对模型内用户拓扑结构中异常用户的检测,从而规避相关的风险。
[0170]
以上所述实施例仅表达了本技术的具体实施方式,其描述较为具体和详细,但并不能因此而理解为对本技术保护范围的限制。应当指出的是,对于本领域的普通技术人员来说在不脱离本技术技术方案构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1