社交媒体用户属性值缺失填补模型的训练方法和填补方法
本发明涉及计算机,尤其涉及社交媒体用户属性值缺失填补模型的训练方法和填补方法。
背景技术:
1、近年来,随着网络互联、移动计算等各种信息技术的飞速发展,新浪微博、腾讯微信、twitter、facebook等国内外社交服务平台正逐步成为民众生活不可或缺的重要组成部分。海量的社交网络数据持续不断地产生于民众使用网络交友、资讯共享等社交服务的过程中。数据缺失现象在社交网络数据中普遍存在。例如,大量新浪微博用户档案中的工作属性值与教育属性值为空,淘宝网的很多商品评论只有文字信息而没有图片信息。社交网络数据缺失值的大量存在,对现有的模式发现算法提出挑战,同时也给网络空间安全留有隐患。现有的模式发现算法主要是针对完全信息设计的,处理这类信息不完全的数据时通常将含有缺失值的社交网络数据删除,而实际上,含有部分缺失值的数据中可能含有十分重要的已知值,应该充分利用它们。
2、若能将缺失值近似地估计出来,则含缺失值的不完全数据中的已知值就可以被利用。
3、社交媒体用户属性值缺失填补方法的研究可以为社交网络大数据的分析与利用提供技术支撑,对不完全信息挖掘具有重要理论意义与应用价值。
4、社交网络用户的点赞、评论、转发等社交行为与发布的包含主题情感信息的社交文本信息往往蕴含着丰富的知识,这些知识对缺失属性值预测有着的积极辅助作用。
5、传统的基于数理统计的缺失值填充方法都是尝试利用隐藏在非完备信息中的知识来进行缺失属性值填充,没有考虑社交媒体用户的社交行为与社交文本信息,这使得填充效果不尽人意。
技术实现思路
1、针对现有技术存在的问题,本发明提供了社交媒体用户属性值缺失填补方法,可以挖掘社交媒体用户的社交文本的主题情感分布与社交行为的语义表示来辅助重建用户档案,有效提升社交媒体用户属性值的缺失填补性能。
2、为实现上述发明目的,本发明的技术方案如下:
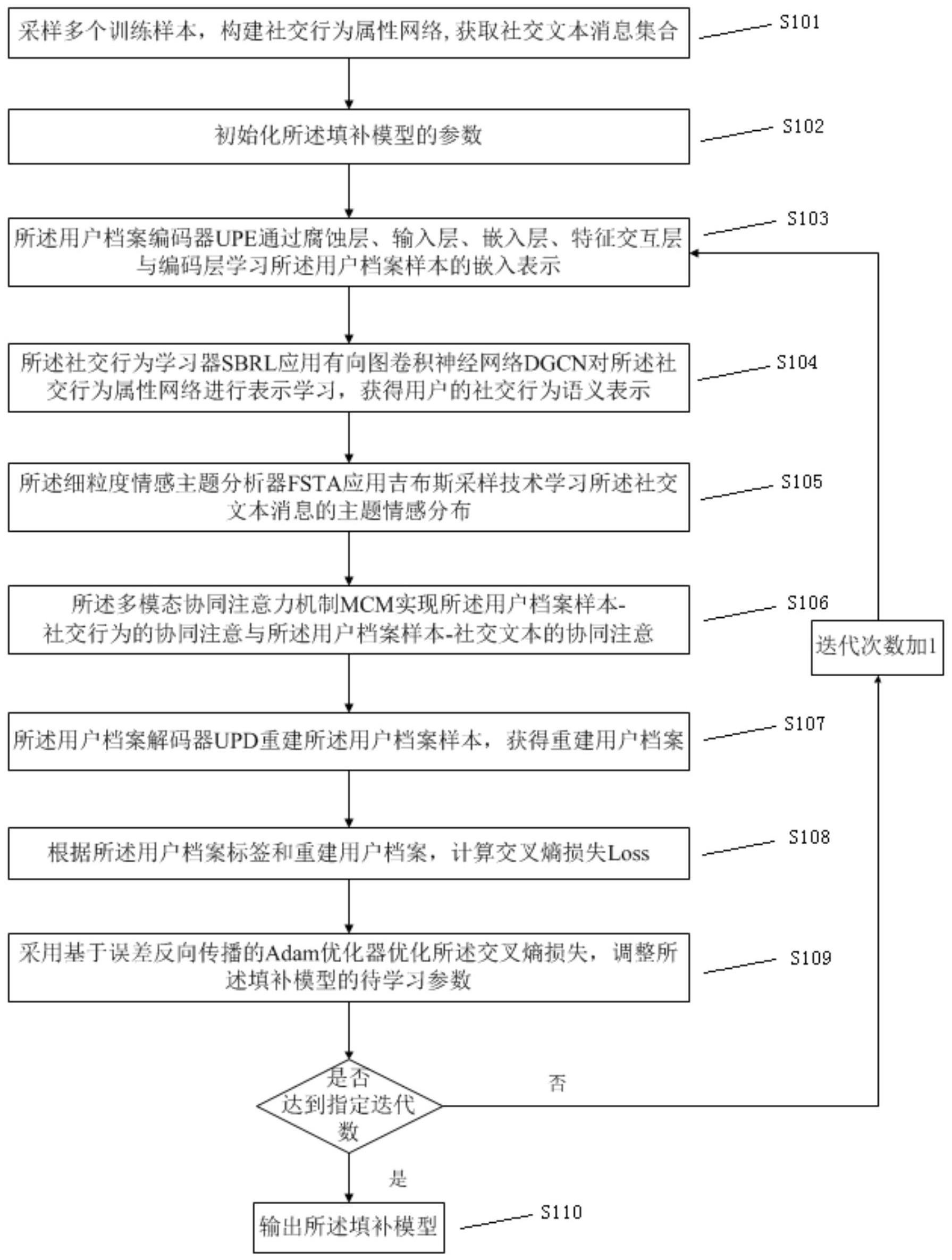
3、本发明提供了一种社交媒体用户属性值缺失填补模型的训练方法,应用于社交媒体用户网络,所述填补模型包括:用户档案编码器upe、社交行为学习器sbrl、细粒度情感主题分析器fsta、多模态协同注意力机制mcm和用户档案解码器upd,所述训练方法包括:
4、s101,采样多个训练样本,得训练样本集,其中,每个训练样本包括用户档案样本、所述用户档案样本对应的用户档案标签;
5、基于训练样本集获得采样子网络,基于采样子网络节点对应用户的社交行为构建社交行为属性网络,
6、获取采样子网络节点对应用户在一定时间范围内发表的社交文本消息集合;
7、s102,初始化所述填补模型的参数;
8、s103,所述用户档案编码器upe通过腐蚀层、输入层、嵌入层、特征交互层与编码层学习所述用户档案样本的嵌入表示;
9、s104,所述社交行为学习器sbrl应用有向图卷积神经网络dgcn对所述社交行为属性网络进行表示学习,获得用户的社交行为语义表示;
10、s105,所述细粒度情感主题分析器fsta应用吉布斯采样技术学习所述社交文本消息的主题情感分布;
11、s106,所述多模态协同注意力机制mcm实现所述用户档案样本-社交行为的协同注意与所述用户档案样本-社交文本的协同注意;
12、s107,所述用户档案解码器upd重建所述用户档案样本,获得重建用户档案;
13、s108,根据所述用户档案标签和重建用户档案,计算交叉熵损失loss;
14、s109,采用基于误差反向传播的adam优化器优化所述交叉熵损失,调整所述填补模型的待学习参数;
15、s110,重复s103到s109达到指定迭代数,输出所述填补模型。
16、进一步地,所述s103包括以下步骤:
17、s31,所述用户档案编码器upe通过腐蚀层对所述用户档案样本缺失属性值以均值或众数方式进行填充;
18、s32,所述用户档案编码器upe通过输入层对所述用户档案样本属性值进行独热或多热表示;
19、s33,所述用户档案编码器upe通过嵌入层对以独热或多热表示的用户档案样本数据进行嵌入表示;
20、s34,所述用户档案编码器upe通过特征交互层对所述用户档案样本数据的嵌入表示特征进行二阶交互;
21、s35,所述用户档案编码器upe的编码层利用一个前馈层对所述用户档案样本数据的嵌入表示特征与二阶交互特征以非线性变换方式进行集成。
22、进一步地,所述s104中所述有向图卷积网络dgcn计算方法如下:
23、
24、
25、
26、
27、
28、
29、
30、
31、
32、
33、
34、其中,ui和uj表示用户i和用户j,au、和用于描述用户之间不同的关联关系,au为对称的用户关联矩阵,若用户i关注用户j,则其元素au(i,j)为1,否则为0;为一阶用户关联相似矩阵,若用户i关注用户j或者用户j关注用户i,则其元素为1,否则为0;为二阶入度用户关联矩阵,其元素描述用户i与用户j的共同被关注的现象;为二阶出度用户关联矩阵,其元素描述用户i与用户j的共同关注的现象;分别对进行规范化,f1、f2,in和f2,out是卷积操作的函数,分别从关注、共同被关注和共同关注进行卷积操作,分别表示关注、共同被关注与共同关注三个不同交互关系;是用户社交交互属性矩阵,|u|为用户数,d1为交互属性数,diag为对角化函数,rowsum为行求和函数,是一个过滤器待学习参数,d2为用户交互属性的嵌入维度,λ是用户指定参数,i为单位矩阵,λ1与λ2是不同相亲度重要性的平衡因子,concat将3个向量(f1,λ1f2,in,λ2f2,out)连接拼接成一个更大的向量,ub为用户的社交行为语义表示。
35、进一步地,
36、所述s105方法如下:
37、根据条件后验分布p(ti=t,li=l|t-i,l-i,w),利用吉布斯采样技术估计用户-情感分布h、主题-情感-词语分布b与用户-消息-情感-主题分布a,计算方法如下:
38、
39、其中:为用户u所发消息m具有情感l且隶属于主题t的概率,表示用户u发表的消息m中隶属主题t与情感极性l的词语计数,nu,m,l表示用户u发表的消息m中隶属情感极性l的词语计数,t是预定义的主题数,α是指具有情感极性l的主题t在消息m中出现的先验次数;
40、
41、其中:为在消息集中,词语w具有情感l且隶属于主题t的概率,表示词语w同时隶属主题t与情感极性l的频数,nl,t表示同时隶属主题t与情感极性l的词语总频数,v是词汇表大小,β是指词语w在具有情感极性l的主题t中出现的先验次数;
42、
43、其中:为用户u具有情感l的概率,表示用户u发表的所有消息中隶属情感极性l的词语频数,nu表示用户u发表的所有消息中的词语总频数,ηl是指情感极性l在消息m中出现的先验次数,l是情感极性数;
44、
45、其中:ti、li分别是第i个位置的词语的主题编号与情感标签,t-i与l-i分别表示除了消息m中的第i个位置的词语外,其他所有词语的主题向量与情感向量;表示在用户u发布的消息m中,除了其中第i个位置上的单词外,主题t且情感极性l的频数;表示在用户u发布的消息m中,除了其中第i个位置上的单词外,情感极性l的频数;表示在所有用户消息集合中,除了其中第i个位置上的单词外,词语w同时主题t与情感极性l的频数;表示在所有用户消息集合中,除消息m中第i个位置上的元素外,所有其他具有主题t和情感极性l的词语频数;表示在用户u发布的消息集合中,除消息m中第i个位置上的元素外,所有其他具有情感极性l的词语频数;{nu}-i表示在用户u发布的消息集合中,除消息m中第i个位置上的元素外,所有其他词语的频数。
46、进一步地,
47、所述s106中:
48、所述用户档案样本-社交行为协同注意方法如下:
49、spb=tanh((up)twpbub)
50、其中:up为用户档案信息,ub为用户的社交行为语义表示,t为矩阵转置,wpb为待学习参数,spb为用户档案信息up和用户的社交行为语义表示ub的相亲度,tanh为双曲正切函数;
51、
52、其中:wp为针对up的待学习参数,wb为针对ub的待学习参数,为spb的转置,hp为用户档案信息up的注意特征;
53、hb=tanh(wbub+(wpup)spb)
54、其中:hb为用户的社交行为语义表示ub的注意特征;
55、
56、其中:为针对hp的待学习参数,ap为对线性变换后的hp进行归一化;
57、
58、其中:为针对hb的待学习参数,ab为对线性变换后的hb进行归一化;
59、
60、其中:为用户j的档案属性特征向量,|u|为用户数,为用户j档案的注意力系数,为进行基于用户档案属性的注意力集成;
61、
62、其中:为用户j的行为属性特征向量,|u|是用户数,为是用户j行为的注意力系数,为进行基于用户行为属性的注意力集成;
63、所述用户档案样本-社交消息协同注意方法如下:
64、spm=tanh((up)twpmum)
65、其中:um为用户社交消息的主题情感分布特征,t为矩阵转置,wpm为待学习参数,spm为用户档案信息up和用户社交消息的主题情感分布特征um的相亲度;
66、
67、其中:为spm的转置,wm为针对用户社交消息的主题情感分布特征um的待学习参数,w′p为针对用户档案信息up的待学习参数,hp′为用户档案信息up的注意特征;
68、hm=tanh(wmum+(wp′up)spm)
69、其中:hm为用户社交消息的主题情感分布特征um的注意特征;
70、ap′=softmax((w′hp)thp′)
71、其中,(w′hp)t为针对hp′的待学习参数,ap′为对线性变换后的hp′进行归一化;
72、
73、其中,为针对hm的待学习参数,am为对线性变换后的hm进行归一化;
74、
75、其中,为用户j的社交行为特征向量,为用户j社交行为的注意力系数,为进行基于用户社交行为属性的注意力集成;
76、
77、其中,为用户j的用户社交消息的主题情感分布特征,为用户j社交消息的注意力系数,为进行基于用户社交消息的注意力集成,|u|为用户数。
78、进一步地,所述s107计算方法如下:
79、
80、其中,concat将4个向量连接成一个更大的向量,激活函数relu是一个简单的计算,如果输入大于0,直接返回作为输入提供的值;如果输入是0或更小,返回值0,与为待学习参数,分别对应线性变换的权重与偏置,为所述重建用户档案中所述填补模型对用户的档案属性j的填充值。
81、进一步地,
82、所述s108中的交叉熵损失loss为:
83、
84、其中,为所述用户档案标签中用户i的档案属性j的真实值,为所述重建用户档案中所述填补模型对用户i的档案属性j的填充值,|u|是用户数,d是用户的档案属性数,θ为所述填补模型的待学习参数的集合。
85、本发明还提供了一种社交媒体用户属性值缺失填补方法,包括:
86、s201,获取用户在所属社交媒体用户网络的社交行为和一定时间范围内发表的社交文本信息,以及含属性值缺失的用户档案,还包括:
87、基于用户社交行为构建社交行为属性网络;
88、s202,将所述用户一定时间范围内发表的社交文本信息、含属性值缺失的用户档案、和社交行为属性网络输入填补模型,填充缺失属性值,所述填补模型是所述的社交媒体用户属性值缺失填补模型的训练方法训练得到的。
89、与现有技术相比,本发明具有如下有益效果:
90、1、本发明提供的社交媒体用户属性值缺失填补模型的训练方法,用户档案编码器学习用户档案样本的嵌入表示;社交行为学习器sbrl对社交行为属性网络进行表示学习,获得用户的社交行为语义表示;细粒度情感主题分析器fsta学习社交文本消息的主题情感分布;多模态协同注意力机制mcm实现用户档案样本-社交行为的协同注意与用户档案样本-社交文本的协同注意;用户档案解码器upd重建用户档案样本,获得重建用户档案;再根据用户档案标签和重建用户档案的交叉熵损失loss,调整填补模型的待学习参数,对填补模型进行迭代训练。本发明提供的填补方法,可以挖掘社交媒体用户的社交文本的主题情感分布与社交行为的语义表示来辅助重建用户档案,有效提升社交媒体用户属性值的缺失填补性能。
- 还没有人留言评论。精彩留言会获得点赞!