一种个性化特征选择的风险预测方法
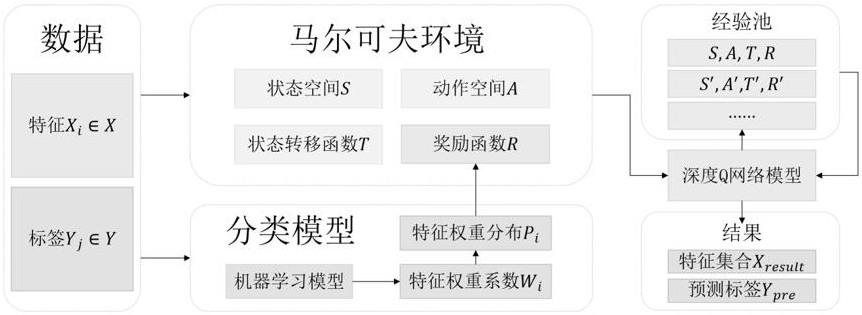
本发明涉及特征工程和分类预测领域,具体地说是一种个性化特征选择的风险预测方法。通过个性化特征选择方法得到样本的个性化特征和风险预测结果,有效优化了风险预测任务中的特征选择效果和预测效果,为风险分析和风险预测提供支持。
背景技术:
1、风险预测任务由于其能识别评估对象面临的各种风险、评估风险概率、可能带来的负面影响、确定组织或个人承受风险的能力、确定风险消减和控制的优先等级以及推荐风险消减对策等原因一直在包括金融、医疗等领域备受关注。此类任务通常依据数据中的特征和标签使用包括cox、随机生存森林、逻辑回归以及决策树模型等来进行风险分析和预测。考虑到数据质量差、数据数量不足、需要寻找关键特征、需要个性化风险分析等问题,现有的风险预测方法往往不能有效的同时完成个性化的特征选择和风险预测。因此,如何结合风险预测和特征选择中的问题并有效利用和探索数据解决这些问题至关重要。
2、目前特征工程中普遍适用的特征选择方法主要包括过滤法、包装法、嵌入法和混合法等,特征选择的方式包括使用卡方检验或相关系数等方法计算每一维度的特征得分并过滤、生成不同的特征子集组合评估效果、训练模型挑选提高指标最有效的特征以及混合上述多种方法选择特征等。但是,对于风险预测任务,个性化的特征选择并完成风险预测既要考虑选择的特征的可靠性,又要考虑特征选择的个性化,还要保证风险预测结果的有效性,因此,如何结合并解决寻找风险预测任务中的重要特征,针对不同样本完成个性化的风险预测以及得到更好的风险预测效果等问题十分重要。
3、现有技术的特征选择结果稳定性差,无法保证选择的特征的有效性;风险预测结果精度低,难以支持风险分析;并且,风险预测和特征选择方法结合不足,只能完成单方面的任务需求,缺少同时考虑个性化特征选择和风险预测的适用方法,需要高成本的人工分析补足。
技术实现思路
1、本发明的目的是针对现有技术的不足而提供的一种个性化特征选择的风险预测方法,采用马尔可夫环境建模模块和深度q网络模型的方法,通过个性化特征选择方法得到样本的个性化重要特征和风险预测结果,有效优化了风险预测任务中的特征选择效果和预测效果。马尔可夫环境建模模块依据输入的特征和标签建模出状态空间、动作空间和状态转移函数,并将特征和标签用于训练可获得特征权重系数或特征重要性的机器学习模型,从训练好的机器学习模型中得到特征权重系数或特征重要性并经过softmax转化为对应的特征权重分布作为带权重的奖励函数;深度q网络模型基于上述马尔可夫环境提供的状态空间、动作空间、状态转移函数和奖励函数进行深度q网络模型更新,学习出当前环境下的最优选择策略,基于不同样本即不同状态表示得到个性化的特征选择结果,并基于选择的特征完成风险预测,有效优化了风险预测任务中的特征选择效果和预测效果,为风险分析和风险预测提供支持。这一方法结合了风险预测和特征选择任务,能选择出个性化特征并得到更准确的风险预测结果,能够在医学生存分析、金融风险预测等真实场景中应用,具有广泛的实用意义和应用前景。
2、实现本发明目的的具体技术方案是:
3、一种个性化特征选择的风险预测方法,其特点是该方法采用马尔可夫环境建模模块和深度q网络模型完成个性化的特征选择同时进行了风险预测;所述马尔可夫环境建模模块依据输入的特征和标签建模出状态空间、动作空间和状态转移函数,并将特征和标签用于训练可得到模型权重参数或特征重要性的机器学习模型,从训练好的机器学习模型中得到特征权重系数或特征重要性并经过softmax转化为对应的特征权重分布作为带权重的奖励函数;所述深度q网络模型基于所述马尔可夫环境提供的状态空间、动作空间、状态转移函数和奖励函数进行深度q网络模型更新,学习出当前环境下的最优选择策略,基于不同样本即不同状态表示得到个性化的特征选择结果特征集合,并基于选择的特征完成风险预测得到预测标签,具体包括如下步骤:
4、1)建立马尔可夫环境建模模块,该模块在给定数据输入特征∈和标签的条件下,建模出状态空间、动作空间和状态转移函数,并将特征和标签用于训练可获得特征权重系数或特征重要性的机器学习模型,从训练好的机器学习模型中得到特征权重系数或特征重要性并经过softmax转化为对应的特征权重分布作为带权重的奖励函数。其中:
5、1.1状态空间由下述公式表示:
6、
7、其中,为在当前时间步下未知的特征值的常数代替值,为在当前时间步下已知的特征值,为设定的最大特征选择轮数;
8、1.2动作空间由下述公式表示:
9、
10、其中,为选择某一类标签j进行预测的动作,为选择某一类特征进行询问的动作;
11、1.3状态转移函数由下述公式表示:
12、
13、其中,s为在当前时间步下样本对应的状态表示,a∈为深度q网络模型基于训练得到的策略在当前状态表示s条件下选择的动作,为动作a为选择某一类特征进行询问时得到的下一步将加入状态表示s的特征值;
14、1.4对于奖励函数,以分类模型逻辑回归为例,逻辑回归模型的目标函数h/由下述公式表示为:
15、
16、其中,σ(t为经过线性变换t与sigmoid激活函数转换得到输入数据样本属于某个类别的概率的表达式;为线性回归的表达式;即为对应特征的权重系数。为sigmoid激活函数,将线性回归的返回值转换为区间[0,1内的值,用于表示自变量属于某个类别的概率。
17、为得到特征权重系数,逻辑回归模型需优化的损失函数目标由下述公式表示为:
18、
19、其中,为损失函数,y∈表示数据中的第i条样本的标签;x∈表示数据中第i条样本的所有特征;h/x为第i条样本的目标函数;经过损失函数的优化来训练逻辑回归模型可得到模型中对应特征的权重系数。
20、得到特征权重系数后,将特征权重系数经过softmax转化为其在n个特征中的特征权重分布,所述特征权重分布由下述公式表示:
21、
22、其中,为每一类特征值对应的特征权重系数的元素值。
23、最终,将特征权重分布作为带权重的奖励函数,所述奖励函数由下述公式表示:
24、
25、其中,α∈[0,1]为预先设定的用于奖惩预测动作正误的系数值,j=!uelable指预测结果正确,j=falselable指预测结果错误。
26、2)建立深度q网络模型,设置特征选择的最大轮数为并将从马尔可夫环境建模模块得到的状态空间、动作空间、状态转移函数和带权重的奖励函数输入深度q网络模型。深度q网络模型基于当前第轮的状态表示s∈以∈=g!eedy策略选择动作a。当动作a为时,深度q网络模型在这一轮选择询问特征值的动作,并根据状态转移函数更新状态表示s得到下一轮的状态表示s+1,继续下一轮的动作选择;当动作a为时,深度q网络模型则选择基于当前轮数对应的状态表示s进行生存预测,此时,基于当前样本的特征选择和生存预测任务全部完成,深度q网络模型基于当前样本的训练回合结束。在确定选择动作a后,深度q网络模型能得到状态空间、动作空间、状态转移函数和奖励函数的四元组信息并将其保存入经验池,在随后的训练中从经验池中抽取四元组信息基于最小化损失函数完成网络参数θ的更新。所述损失函数由下述公式表示:
27、
28、其中,e[·]为求括号内公式期望值的期望函数,!为选择动作a后得到的对应奖励值,γ为调整奖励值影响程度的衰减系数,q·为状态动作价值函数,qs,a;θ为在参数θ对应的策略下基于状态s选择动作a得到的状态动作值,为在参数θ对应的策略下基于状态s′选择能使状态动作值最大的动作a′得到的状态动作值。
29、按照上述公式,深度q网络模型更新到预先设定的循环数或损失最小时即可确定动作的选择策略,基于此策略能在不同样本即不同状态表示条件下生成个性化的特征选择结果特征集合,并基于选择的特征完成风险预测得到预测标签。
30、本发明步骤1)中所述的特征权重系数或特征重要性的机器学习模型,包括逻辑回归、决策树、梯度提升决策树、随机森林、极端随机树、自适应提升等模型,其余可得到特征权重系数或特征重要性的机器学习模型也都适用于上述描述的奖励函数建模方法。
31、本发明与现有技术相比具有以下显著的技术进步和有益效果优点:
32、1、适用性:相较于过去的方法能适用于风险预测和个性化特征选择任务,能在完成个性化特征选择的同时基于选择出来的特征完成风险预测。只要能基于数据建模马尔可夫环境,即可进行风险预测和个性化的特征选择。
33、2、有效性:将数据建模成马尔可夫环境,依靠深度q网络模型进行动作选择和策略优化,能有效完成个性化的特征选择并选择出更重要,数量更少的特征,优化了风险预测任务中的特征选择和风险预测效果,为风险分析和风险预测提供支持。
34、3、实用性:该方法具有广泛的实用意义,能够在真实场景中应用,比如医学生存分析、金融风险预测等任务。
- 还没有人留言评论。精彩留言会获得点赞!