一种基于IVMD-LSTM-EBLS的水文时间序列预测模型构建方法
本发明属于水文预测,尤其涉及一种基于深度学习的水文时间序列预测模型构建方法。
背景技术:
1、水文预测为水文情况的预防和调度提供了科学依据。水文时间序列是按照时间变化进行采集的有序且离散的水文要素合集,非常依赖于数值在时间上的先后顺序,具有非线性、突变性、多噪音等特点,因此基于传统机器学习及统计学的模型预测效果往往差强人意,高精度预测的理论和方法越来越受到重视。
2、长短时记忆网络(long and short-term memory,lstm))在处理具有较长时间步长及非线性序列数据方面优势明显,在时间预测方面已经取得了优异的成果。但是受到深层结构的影响,基于lstm的水文时间预测模型普遍存在易陷入局部最优的缺点,这主要是由于lstm训练时需要循环调整权重所造成的,因此单一模型不能完全捕捉径流序列非线性特征,研究成果表明混合模型有助于提高预测精度。
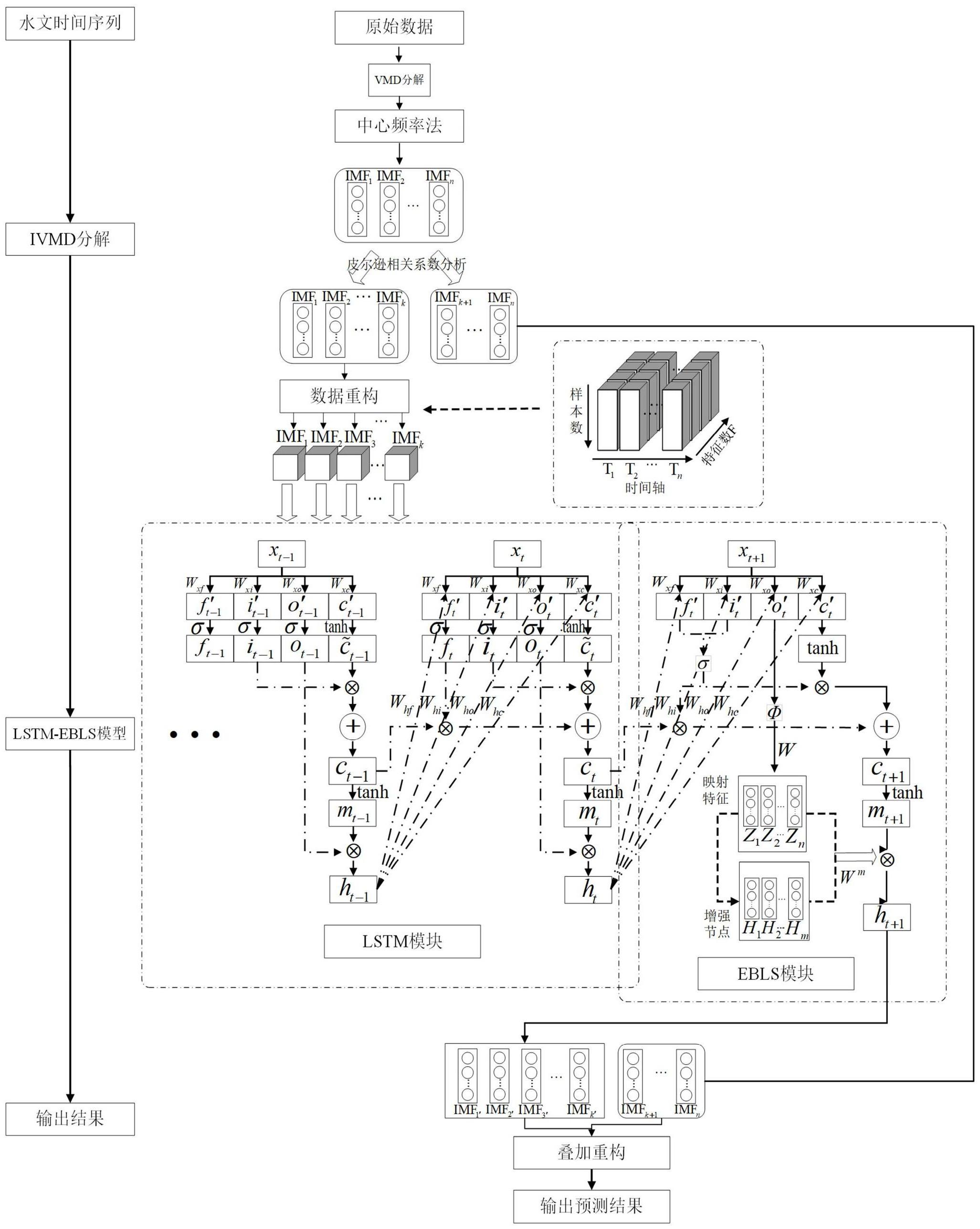
3、变分模态分解(variational mode decomposition,vmd)分解可以有效减少中心频率混叠的问题,使数据更加平稳,分解形成的多组模态数据可以使小样本数据集数据按照频率层次进行多次特征提取;但是传统的vmd分解把所有模态全部放到模型训练,不相关模态数据经过模型训练造成损失值偏差被放大,影响最终权重值和阈值的计算。
4、宽度学习系统(broad learning system,bls)可以直接计算权重,能够直接从训练数据中学习深层重要特征的优点,解决了纯深度学习组合模型易陷入局部最优的缺陷;但是,bls中输入层与特征节点的权重以及特征节点到增强节点的权重是随机初生成的,对于不同的学习任务,权重的生成完全独立于样本,这种方式缺少可解释性。
技术实现思路
1、发明目的:针对水文时间序列预测存在多噪音、非平稳等问题,导致预测结果容易出现偏差,本发明提出一种基于ivmd-lstm-ebls的水文时间序列预测模型构建方法。改进的ivmd(improved variational mode decomposition,ivmd)分解模块使得分解得到的子信号更加趋于平稳,更利于模型进行特征提取,同时结合ebls(enhanced broad learningsystem,ebls)增强了模型与原始数据之间的关系,解决梯度爆炸现象的出现。
2、技术方案:为实现本发明的目的,本发明所采用的技术方案是:
3、一种基于ivmd-lstm-ebls的水文时间序列预测模型构建方法,包括如下步骤:
4、步骤1、数据准备:获取历史记录中水文时间序列数据,确定训练集和测试集;
5、步骤2、利用ivmd分解和重构训练集的原始水文时间序列:中心频率法和皮尔逊相关系数法确定分解模态数k;剩余指数最小化准则确定步长τ;
6、步骤3、数据重构:将ivmd分解后的一维模态分量imf数据,叠加重构为包括时间步长、样本数和特征数的三维数据,作为两层lstm模型的第一层输入数据;
7、步骤4、使用两层lstm模型对重构的三维数据进行特征提取,每一层lstm后增加dropout层,得到初步的水文时间序列数据特征;
8、步骤5、利用ebls对步骤4得到的数据特征进行深层特征提取,完成预测模型的构建,利用训练集对预测模型进行训练,得到预测模型最终权重值和阈值;
9、步骤6、将测试集输入训练完成的预测模型中,验证方法可行性和提出模型的性能。
10、进一步的,步骤2中利用ivmd分解和重构原始水文时间序列的过程为:
11、s2.1、利用vmd将原始水文时间序列分解成k个模态,并获得每个imf的中心频率值,分析中心频率,确定最终k值;
12、s2.2、引入残差指数法确定更新步长τ;当残差指数rei值最小时,采用当前τ的取值进行vmd分解得到的各模态分解信号叠加重构后最接近原始水文时间序列;
13、设置τ初始取值范围为[0,1],步长为0.01,对确定好k值的原始水文时间序列进行若干次vmd分解,计算对应当前τ值的rei值,得到rei取得最小值时τ的取值;
14、s2.3、采用皮尔逊相关系数法,将k个imf分别与原始水文时间序列做皮尔逊相关系数分析,排除相关性最小的imf,剩余的imf进行重组获得新的时间序列数据。
15、进一步的,利用ebls进行深层特征提取的过程为:
16、s3.1、将前两层lstm提取的特征信息数据作为bls输入数据;利用lstm传输来的输入向量与输出门之间的权重作为bls的初始权重进行线性变换生成映射特征;
17、s3.2、通过映射特征生成多个映射节点;
18、s3.3、将映射节点进行线性变换生成增强节点;
19、s3.4、映射节点和增强节点通过矩阵求逆计算权重值;结合bls记忆单元中输入门和遗忘门的权重值和阈值对矩阵求逆得到的权重值进行校正,得到最终权重值和阈值。
20、有益效果:与现有技术相比,本发明的技术方案具有以下有益的技术效果:
21、在仿真分析中发现,lstm与bls模型的耦合叠加仍受深层结构影响,出现梯度爆炸的问题,本发明引入ebls(增强bls)改进lstm用于水文时间序列预测。改进的ivmd分解模块使得分解得到的子信号更加趋于平稳,更利于模型进行特征提取,同时结合ebls增强了模型与原始数据之间的关系,解决梯度爆炸现象的出现。
22、在运算效率方面,ivmd去除了荣誉模态对模型的影响,同时结合了ebls快速计算的优势,进一步提升了模型的运算效率。本发明模型不仅在预测数值的准确性、模型的高效性和运算效率方面均有明显的优势,且对于不同类型的小样本数据集水文时间序列数据均具备适用性,进一步提升了对极端天气情况下径流量剧烈变化的预测精度,具备极高可信度,可以为真实水文情况做出指导性的预防和调度建议。
技术特征:
1.一种基于ivmd-lstm-ebls的水文时间序列预测模型构建方法,其特征在于,所述方法包括如下步骤:
2.根据权利要求1所述基于ivmd-lstm-ebls的水文时间序列预测模型构建方法,其特征在于,步骤2中利用ivmd分解和重构原始水文时间序列的过程为:
3.根据权利要求1所述基于ivmd-lstm-ebls的水文时间序列预测模型构建方法,其特征在于,利用ebls进行深层特征提取的过程为:
技术总结
本发明公开了一种基于IVMD‑LSTM‑EBLS的水文时间序列预测模型构建方法,根据历史降水与径流变化预测未来水文情况。所述方法包括:获取历史记录中水文时间序列数据;根据历史记录中时间序列的变化,利用IVMD进行分解和重构;根据重构后的水文时间序列建立新的特征集合;利用LSTM提取新特征集合的特征数据;使用EBLS对提取到的特征数据进行线性变换生成映射特征,进一步提取深层特征信息并计算最终权重。本发明可以有效提高时间序列数据预测精度,同时也能提升预测效率,提高资源利用率。
技术研发人员:赵芮晗,韩莹,闫加宁,曹允重,张凌珺
受保护的技术使用者:南京信息工程大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!