一种基于语义分割的大规模园林场景点云几何补全方法
本发明涉及一种点云几何补全方法,特别是一种基于语义分割的大规模园林场景点云几何补全方法。
背景技术:
1、场景点云几何补全方法旨在将场景点云中的空洞或缺失部分按照其所述类别或周边对象的语义特征进行补全,获取更为完整的场景点云。场景点云中的空洞或缺失通常是由设备扫描过程中物体之间的遮挡,或多视图重建时拍摄视角不够完备导致视角遮挡导致的。在场景点云之中,大规模园林场景是一类特殊的场景,其在空间尺度上分布范围大,点数量极多。场景内部对象非常繁多,分布密集且复杂,存在较多的缺失部分。同时,部分类别的对象存在较多且较为细节的局部结构。这些因素使得对大规模园林场景点云进行几何补全成为一个较难解决的问题。
2、针对大规模园林场景,现有技术提出了一些解决方法,例如,专利公开文件1:吴钦城.基于bim技术场景建造方法和系统及于园林景观数字建模中的应用[p].广东省:cn110298136a,2019-10-01.;专利公开文件2:张青萍,丁明静,梁慧琳.一种私家园林空间数字化测绘和三维可视化方法[p].江苏省:cn109945845a,2019-06-28.通过采集园林场景图像数据,然后利用软件处理得到场景的三维数据。上述方法只能够从园林场景的二维图像重建得到三维数据,无法保证重建结果不出现空洞或缺失部分,同时也无法对大规模园林场景进行几何补全。专利文件3:李长辉,古建筑园林三维激光测量建模关键技术研究与应用.广东省,广州市城市规划勘测设计研究院,2015-01-05.直接对园林场景进行三维激光测量建模,无法保证测量时不出现遮挡等情况导致结果出现空洞或缺失部分。
3、针对场景点云的几何补全问题,现有的一些方法通过将场景点云进行体素化后进行点云补全,以完成场景点云几何补全,如文献1:cherabier i,schonberger j l,oswaldm r,et al.learning priors for semantic 3d reconstruction[c]//proceedings ofthe european conference on computer vision(eccv).2018:314-330.;文献2:dai a,ritchie d,bokeloh m,et al.scancomplete:large-scale scene completion andsemantic segmentation for 3dscans[c]//proceedings of the ieee conference oncomputer vision and pattern recognition.2018:4578-4587.这类方法在体素表示上对场景进行语义补全以完成几何补全,但这类方法在应用到大规模园林场景上时存在两个问题:第一,大规模园林场景在空间尺度上分布范围大,体素化后进行处理会带来巨大的时间开销和计算成本;第二、园林场景中部分对象存在大量精细的局部结构,体素化会损失这些局部结构,从而导致补全结果精细度不足。
4、现有的单对象点云补全方法可以分为有监督方法和无监督方法。有监督方法利用完整的对象点云作为监督训练补全网络,如文献3:zhang w,yan q,xiao c.detailpreserved point cloud completion via separated feature aggregation[c]//computer vision–eccv 2020:16th european conference,glasgow,uk,august 23–28,2020,proceedings,part xxv 16.springer international publishing,2020:512-528.,但这类方法需要大量完整的对象点云作为强监督信息,由于园林场景没有完整的对象点云,无法使用该类方法进行对象点云补全。无监督方法不需要完整对象点云作为监督,通过设计网络结构或引入先验来完成对象点云补全,如文献4:zhang j,chen x,cai z,etal.unsupervised 3d shape completion through gan inversion[c]//proceedings ofthe ieee/cvf conference on computer vision and pattern recognition.2021:1768-1777.利用预训练的生成器和判别器模型引入先验信息,通过优化生成对象和残缺对象之间的距离损失来学习潜在向量和生成器模型,进而利用学习结果生成完成对象点云。
技术实现思路
1、发明目的:本发明所要解决的技术问题是针对现有技术的不足,提供一种基于语义分割的大规模园林场景点云几何补全方法。
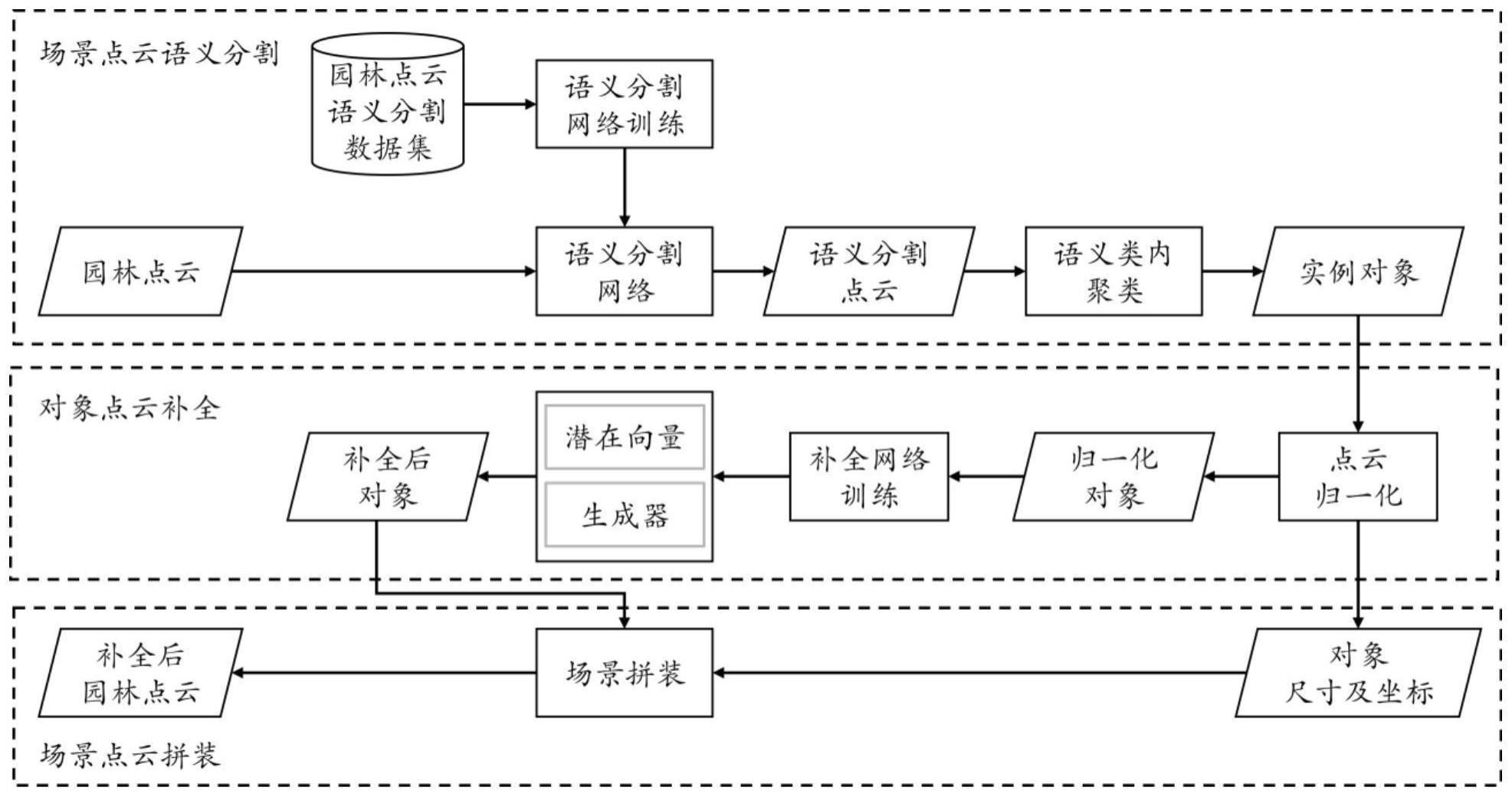
2、为了解决上述技术问题,本发明公开了一种基于语义分割的大规模园林场景点云几何补全方法,包括以下步骤:
3、步骤1,场景点云语义分割:使用在园林点云语义分割数据集上预训练得到的点云语义分割网络对输入的园林场景点云进行语义分割,再通过对各语义类别进行类内聚类得到实例对象;
4、进一步的,所述的的场景点云语义分割,具体过程包括以下步骤:
5、步骤1-1,利用园林点云语义分割数据集进行语义分割网络训练,获得语义分割网络fs;
6、进一步的,所述的语义分割网络fs如下:
7、使用现有处理场景点云的有监督语义分割方法,输入园林场景点云p∈rn×6,其中rn×6表示n×6维的实数域,n为园林场景点云的点数量,每一点包含xyz轴坐标信息和rgb颜色信息共计6维,输出语义分割结果ssem={s1,s2,…,scls},其中,scls表示第cls个语义分割结果,cls为园林场景语义类别个数,为第cls类语义类别点云,ncls为第cls类语义类别点云中的点数量。
8、步骤1-2,利用语义分割网络fs对输入的园林场景点云进行语义分割,得到不同的语义类别的分割结果;
9、步骤1-3,对各语义类别的点云分别进行类内聚类,获得实例级对象点云其中insn为实例对象的个数,为第insn个实例对象。
10、进一步的,所述的的类内聚类,具体过程包括以下步骤:
11、步骤1-3-1,输入语义分割结果ssem={s1,s2,…,scls},邻域半径eps,eps>0,最小邻域样本数minpts,minpts>1;
12、步骤1-3-2,若待聚类语义分割结果ssem=φ,则执行步骤1-3-8,其中φ代表空集;否则,从待聚类语义分割结果ssem中任取一个点云s={s1,s2,…,st},st∈r3,其中,st表示点云s中的第t个点,t为点云s中点的数量;更新ssem=ssem-{s};其中,更新时,待聚类点云的每一点仅采用3维xyz轴坐标信息;
13、步骤1-3-3,初始化当前类别标签k=0,初始化待处理队列l={},初始化逐点类别c={c1,c2,…,ct},ct=-1,其中ct表示第t个点的类别,t为点云s中点的数量;
14、步骤1-3-4,若待聚类点云s=φ,执行步骤1-3-2,其中φ代表空集;否则,从点云s中任取一点s,更新s=s-{s};计算点s与其他所有点的欧几里得距离,并从中选取距离小于邻域半径eps的点作为点s的邻域neighbors;若|neighbors|<minpts,则重新执行步骤1-3-4,否则执行步骤1-3-5,其中|·|代表统计集合·中元素的个数;
15、步骤1-3-5,更新k=k+1,更新点s的类别标签c=k,更新待处理队列l=neighbors;
16、步骤1-3-6,若待处理队列l=φ,则返回步骤1-3-4;否则,从待处理队列l中取出一点p,更新队列l=l-{p},若点p的类别标签cp=-1,则更新cp=k,执行步骤1-3-7;否则,则重新执行步骤1-3-6;
17、步骤1-3-7,计算点p与其他所有点的欧几里得距离,并从中选取距离小于邻域半径eps的点作为点p的邻域neighborsp;若|neighborsp|≥minpts,则更新队列l=l∪neighborsp,否则不进行任何操作,返回步骤136继续执行;
18、步骤1-3-8,对所有语义类别中,聚类标签大于0的点按照聚类标签进行切分,得到单个实例对象,合并所有语义类别的实例对象,得到园林场景点云语义分割后的所有实例对象集合
19、步骤2,对象点云补全:将实例对象归一化后进行补全网络训练,拟合得到单实例对象对应的潜在向量和生成器,并利用潜在向量和生成器进一步获得补全后的实例对象;
20、进一步的,所述的对象点云补全,具体过程包括以下步骤:
21、步骤2-1,对实例对象集合iins中的各实例对象分别进行归一化操作,得到归一化实例对象集合以及各对象的尺寸scale={sc1,sc2,…,scn}和原坐标coord={co1,co2,…,con};其中,scn表示第n个对象的尺寸,con表示第n个对象的原坐标,表示第normn个归一化实例对象,normn表示归一化实例对象的个数;
22、进一步的,所述的的归一化操作,具体如下:
23、从初始实例对象集合iins中任取一对象i∈rm×3,其中m表示对象i的点数量,统计其xyz轴坐标中各坐标轴的最小值作为原坐标(xmin,ymin,zmin),计算方式如下:
24、xmin=min(i[0,:])
25、ymin=min(i[1,:])
26、zmin=min(i[2,:])
27、其中,min表示统计矩阵所有数据中的最小值,i[0,:]表示对象i所有点的x轴坐标,i[1,:]表示对象i所有点的y轴坐标,i[2,:]表示对象i所有点的z轴坐标;
28、然后根据统计的值将对象坐标(x,y,z)平移到原点,计算方式如下:
29、x=i[0,:]-xmin
30、y=i[1,:]-ymin
31、z=i[2,:]-zmin
32、再对平移后的对象坐标统计所有坐标轴中的最大值作为对象尺寸,并将对象缩放到[0,1]之间,计算方式如下:
33、sc=amax(x,y,z)
34、xnorm=x/sc
35、ynorm=y/sc
36、znorm=z/sc
37、其中,amax表示统计输入的所有矩阵中的最大值元素;xnorm表示对象i所有点缩放后的x轴坐标,ynorm表示对象i所有点缩放后的y轴坐标,znorm表示对象i所有点缩放后的z轴坐标;
38、缩放后的对象即为归一化对象,同时获得该对象尺寸sc,以及该对象原坐标co=[xmin,ymin,zmin];对初始实例对象集合iins中每一对象进行该过程,得到归一化实例对象集合inorm。
39、步骤2-2,对各归一化实例对象分别进行补全网络训练,拟合得到各对象的潜在向量z={z1,z2,…,zn}和生成器模型g={g1,g2,…,gn};
40、进一步的,所述的的进行补全网络训练,具体过程包括以下步骤:
41、步骤2-2-1,输入归一化对象ig∈rm×3,输入迭代次数epoch,epoch>50,输入保留点数量k,k>0,随机初始化潜在向量z和生成器g;
42、步骤2-2-2,将潜在向量z输入生成器g生成得到点云t;
43、步骤2-2-3,从归一化对象ig中任取一点ii∈r3,计算其与点云t中所有点的距离,并获取最小的k个点的索引idx,计算方式如下:
44、idx=argmin(sum(pow(ii-t,2),1),k)
45、其中,pow(ii-t,2)表示对ii-t矩阵的每一个元素计算二次方结果,sum(pow,1)表示对pow的运算结果的第二维进行求和,argmin(sum,k)表示对sum的运算结果取前k个最小值的索引;
46、步骤2-2-4,对归一化对象ig中每一点重复步骤2-2-3,得到所有点的索引后进行合并,并根据合并后的索引从点云t中选取子集tmap;
47、步骤2-2-5,计算子集tmap和归一化对象ig之间的chamfer距离dcd;
48、进一步的,所述的chamfer距离dcd,具体的计算方式如下:
49、
50、其中,表示计算两点x和y之间的欧几里得距离,min表示选择最小的距离,σ表示对所有元素进行求和。
51、步骤2-2-6,将chamfer距离dcd作为损失分别传回潜在向量z和生成器g,进行梯度下降更新参数,将步骤2-2-2至步骤2-2-6重复epoch次,得到优化后的潜在向量z和生成器g;
52、步骤2-2-7,对所有归一化目标进行上述操作,得到各对象的潜在向量z={z1,z2,…,zn}和生成器模型g={g1,g2,…,gn}。
53、步骤2-3,将步骤2-2得到的各对象的潜在向量z={z1,z2,…,zn}分别输入对应的生成器模型g={g1,g2,…,gn},生成得到补全后的实例对象其中,表示第compn个补全后实例对象,compn表示补全后实例对象的个数。
54、步骤3,场景点云拼装:根据实例对象归一化时保存的对象尺寸及坐标,将补全后的实例对象进行还原拼装得到补全后的园林点云。
55、进一步的,所述的场景点云拼装,具体过程包括以下步骤:
56、步骤3-1,使用步骤2-1中得到的各对象的尺寸scale={sc1,sc2,…,scn}和原坐标coord={co1,co2,…,con}对各补全对象进行尺寸和坐标还原,得到还原后补全对象其中,scn表示第n个对象的尺寸,con表示第n个对象的原坐标,表示第fcn个还原后补全对象,fcn表示还原后补全对象的个数;
57、进一步的,所述进行尺寸和坐标还原,具体方式如下:
58、对于补全后的实例对象icomp中的任一对象利用其尺寸sci和原坐标coi将其还原为还原后补全对象计算方式如下:
59、
60、对补全后的实例对象icomp中的所有对象进行如上操作。
61、步骤3-2,将中所有的对象进行拼装得到补全后的园林场景点云pcomp∈rn×3。
62、有益效果:
63、1、针对大规模园林场景点云几何补全问题,本发明提出了一种基于语义分割的方法,将园林语义分割为多个实例对象后,对单对象进行补全后,拼装得到完整场景。
64、2、本发明采用无监督的方法进行对象点云补全,由于园林场景没有完整的对象点云作为监督,使用无监督的方法能够避免人工补全和标注所带来的时间和金钱成本。
- 还没有人留言评论。精彩留言会获得点赞!