一种基于日志与探针解析自动化运维方法与流程
本发明涉及一种基于日志与探针解析自动化运维方法,属于软件开发运维的。
背景技术:
1、随着移动互联网、云计算、大数据、物联网等技术的迅猛发展,各种业务应用不断出现,it应用复杂度呈现爆炸式增长,数据获取的高实时化、业务需求的快速迭代、以及产品和服务的即刻落地,这些高要求使开发和运维团队所承受的责任更加沉重,研发和运维工程师既要保证服务和产品的可靠性、稳定性,优化服务、快速定位故障、提升用户体验等,同时还要为业务决策提供数据支撑,引领业务创新。然而业务系统上线后,经常会存在以下几个问题:
2、1.某模块的响应速度很慢,但是不知道为什么这么慢,具体慢在哪里;
3、2.运维只有监控服务器的资源指标,单从服务器资源看不出为什么慢;
4、3.系统总是时常会异常,但不知道具体深入原因;
5、4.分布式服务系统中,出现性能问题,需要分析n台服务器系统日志,组件日志多而杂,无从下手分析。
技术实现思路
1、为了解决上述存在的问题,本发明公开了一种基于日志与探针解析自动化运维方法,其具体技术方案如下:
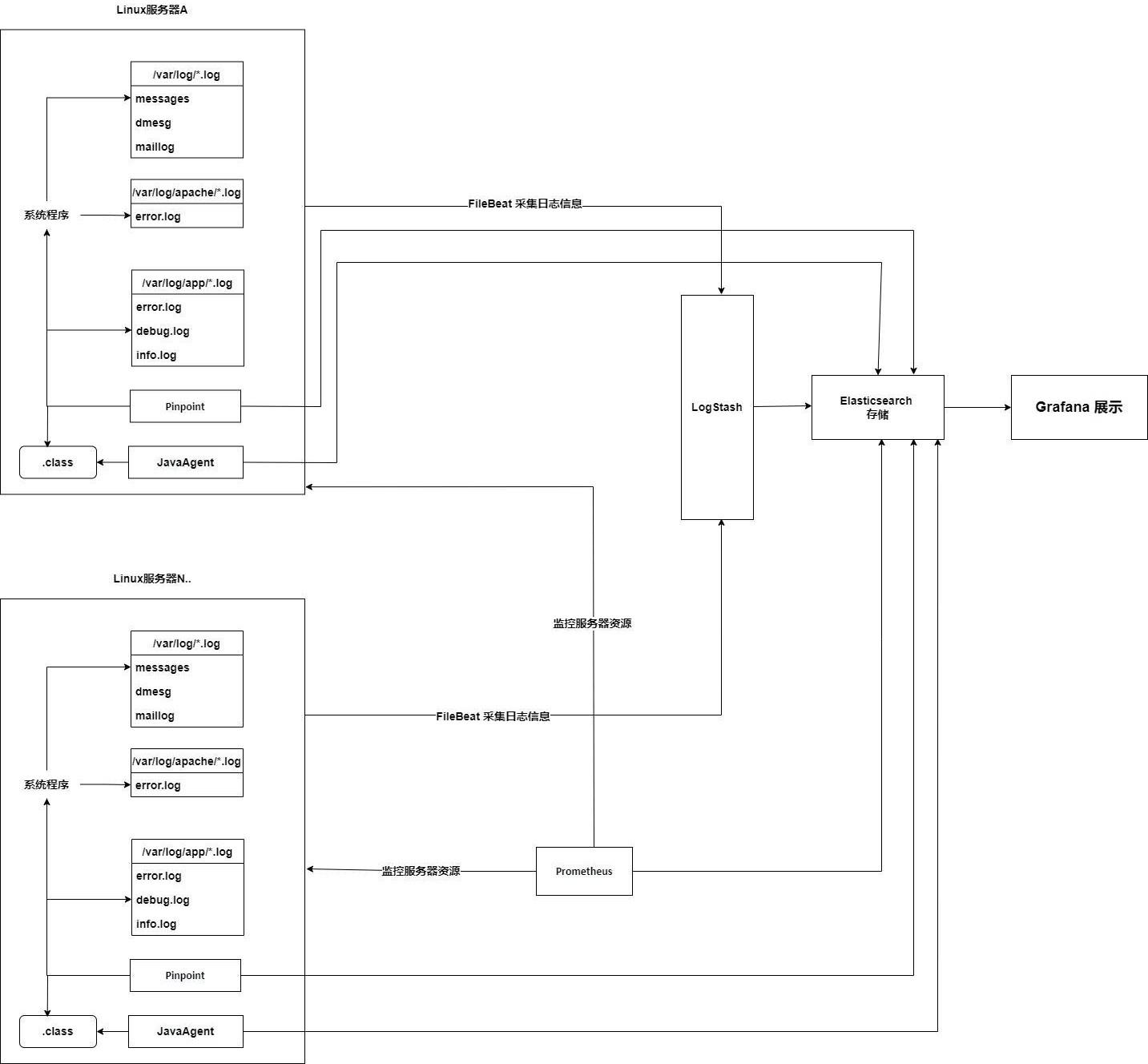
2、一种基于日志与探针解析自动化运维方法,包括以下步骤:
3、步骤s1,通过pinpoint分布式系统性能监控工具,监控第三方程序java heap与gc,class&object&method&field 元信息;
4、步骤s2,第三方jar包在class被加载之前,通过javaagent对其拦截,插入监听字节码,
5、步骤s3,javaagent通过bytebuddy框架解析监听字节码信息,将第三方jar中函数被调用的记录数据存储到elasticsearch(elasticsearch简称es)数据库中;
6、步骤s4,filebeat引擎实时采集第三方jar包自己产生的app.log日志文件;
7、步骤s5,filebeat引擎实时采集操作系统本身的日志;
8、步骤s6,将步骤s4-步骤s5中filebeat采集到的日志信息,实时同步到logstash组件中;
9、步骤s7,logstash组件将数据进行过滤预处理并实时存储到elasticsearch中;
10、步骤s8,prometheus监控第三方服务部署的所有服务器节点资源信息,服务器节点资源信息包括cpu, 内存,硬盘存储;
11、步骤s9, grafana通过连接es数据存储,通过es的查询并融合prometheus监控数据实时全链路展示服务画像,客户端画像,日志画像,端到端完整的应用链路,服务流图谱。
12、进一步的,所述步骤s3中javaagent通过bytebuddy框架解析监听字节码信息的具体过程为:当第三方jar启动后,javaagent会记录该jar包被哪些接口调用的记录,同时也会记录是否调用状态,调用状态包括正常,异常,报错记录到es数据库中。
13、进一步的,所述步骤s5中操作系统本身的日志包括centos系统中日志,具体为:
14、核心启动日志:/var/log/dmesg,
15、系统日志:/var/log/messages,
16、最近登录服务器ip日志:/var/log/lastlog。
17、进一步的,所述步骤s8中es的查询语法执行过程为:es中存储的数据,通过es的sql语句,按照监控第三方jar的启动的进程号作为唯一身份,查询多张表中的数据,展示全链路画像。
18、进一步的,所述服务画像包括服务拓扑图,服务拓扑图对整个系统中应用的调用关系进行了可视化的展示,grafana实时监控elasticsearch中数据在大屏中实时展示,可根据需要登录浏览器查看,查看时数据是实时展示,通过prometheus实现对所有部署第三方节点服务器的监控,通过grafana进行数据展示,单击某个服务节点,可显示该节点的详细信息,该节点的详细信息包括当前节点状态cpu使用情况, 内存使用情况,硬盘使用情况、网络吐出量及该节点接口的请求数量。
19、进一步的,所述客户端画像包括实时活跃线程图,实时活跃线程图监控应用内活跃线程的执行情况,对应用的线程执行性能有直观的了解;监控应用内活跃线程的方法为:javaagent,pinpoint,grafanajvm,以上每个方法对应的不同的场景,兼容不同语言开发的程序。
20、进一步的,所述日志画像包括请求响应散点图,请求响应散点图以时间维度进行请求计数和响应时间的展示,系统统计的数据秒级别实时同步到es数据库中,grafana对es中的数据进行5分钟时间粒度在界面的轮询展示,通过拖动图表选择对应的请求查看执行的详细情况。
21、进一步的,所述端到端完整的应用链路包括调用栈查看,调用栈查看对分布式环境中每个请求提供了代码维度的可见性,在页面中查看请求针对到代码维度的执行详情,帮助查找请求的瓶颈和故障原因。
22、进一步的,所述服务流图谱包括应用状态、机器状态检查,应用状态、机器状态检查通过prometheus实时监控进程名和检测服务器节点的信息,可查看相关应用程序的详细信息;
23、进程名和检测服务器节点的信息包括程序是否异常,节点cpu;相关应用程序的详细信息cpu使用情况,内存状态、垃圾收集状态,tps和jvm信息参数。
24、进一步的,所述调用栈查看具体过程为:
25、(1)当grafana界面提供告警,点击告警信息,
26、(2)可查看告警信息所在服务器,
27、(3)在对应服务器上点击正在进行的告警提示,
28、(4)查看到该进行的 jvm堆栈信息及linux服务器系统日志,
29、(5)等3分钟范围差内的日志信息,
30、(6)点击查看详细,展示完整日志信息。
31、本发明的工作原理是:
32、本发明通过开源pinpoint分布式系统性能监控工具,监控第三方服务实时活跃线程图,请求响应散点图,调用栈查看等功能,同时完善pinpoint不能监控的点,增加javaagent探针技术,在第三方jar包. class 被加载之前对其拦截,插入监听字节码。javaagent通过bytebuddy框架解析字节码信息,将代码维度的执行详情写入到elasticsearch数据库(简称es); filebeat实时采集系统级别的message日志信息和第三方应用自身的app.log日志信息,实时同步到logstash组件中。 logstash将数据预处理后实时存储到es中。该方法同时使用prometheus监控第三方服务部署的服务器节点,最终通过grafana连接es数据存储,使用es的查询多维度查询融合prometheus监控数据实时全链路展示服务器画像,客户端画像,日志画像,端到端完整的应用链路,服务流图谱。
33、本发明的有益效果是:
34、1.本发明具体为系统运维领域根据数据分析,可以勾画出准确的服务画像,客户端画像,日志画像,端到端完整的应用链路,服务流图谱。
35、2. 客户可以快速知道系统是否发生问题,简单问题可以按照系统的提示进行操作,快速保证的第三方系统的正常运行,减少因系统问题导致到损失。
36、3. 使用不同系统的运维人员可以按照更快的定位程序的问题,可以极大降低定位问题花费的时间。
37、4. 对于不同系统的开发人员可以快速知道程序的bug所在,快速修复问题。
38、5. 使用效果的优势:正常情况下当系统出现问题时,客户反馈给系统的开发厂家,厂家远程指导客户排查,当客户非专业人员时,不能解决问题,厂家会优先安排运维工程师去解决,但是一些bug运维工程师花费大量时间排查后,不能解决,还需要安排研发工程师去解决,整个过程可能需要几天的时间去定位,但是对于客户的系统不能使用带来的损失不可估量,系统开发厂家的运维成本也增加很多,有了该方法后就可以极大缩减了定位问题和解决bug的时间。
- 还没有人留言评论。精彩留言会获得点赞!