一种基于双层分布式和集成贝叶斯推理的故障检测方法与流程
本发明涉及工业系统故障检测,具体涉及一种基于双层分布式和集成贝叶斯推理的故障检测方法。
背景技术:
1、随着现代工业规模的不断扩大,日趋复杂化的工业系统更容易导致重大安全事故的发生。为了保障工业系统能够长期稳定运行,及时发现并精准检测故障是工业领域的研究难点。
2、现有的主成分分析(pca)方法,假定数据服从高斯分布,且假定不同时间的样本是独立的。然而,在实际工业中,并不一定满足上述假定。为此,动态pca(dpca)模型和慢特征分析被提出来解决动态相关性问题,独立分量分析(ica)、动态独立分量分析(dica)被提出来处理非高斯过程。然而上述集中式方法不能很好的处理大规模的工业数据,在最近的研究中,有学者用分布式方法来处理大规模数据,比如用分布式主成分分析、分布式慢特征分析、分布式协整分析和分布式典型相关分析。然而,上述分布式方法并未考虑数据的分布特征,导致每个块同时包含高斯变量和非高斯变量,仍然采用相同的方法对具有不同分布特征的变量进行处理,从而影响检测结果。虽然有学者结合pca和ica各自的优势来解决高斯和非高斯过程并发的问题,但是未能从变量的相似性角度挖掘数据的局部结构特征,无法强调各个局部模型的不同贡献信息,从而导致检测性能较差。
技术实现思路
1、本发明解决现有工业系统故障检测方法未能全面考虑数据的分布特征、变量的动态相关性、局部相似性,以及无法强调各个局部模型的不同贡献信息,最终导致检测性能较差的问题,提供一种基于双层分布式和集成贝叶斯推理的故障检测方法。
2、本发明要求保护的技术方案如下:
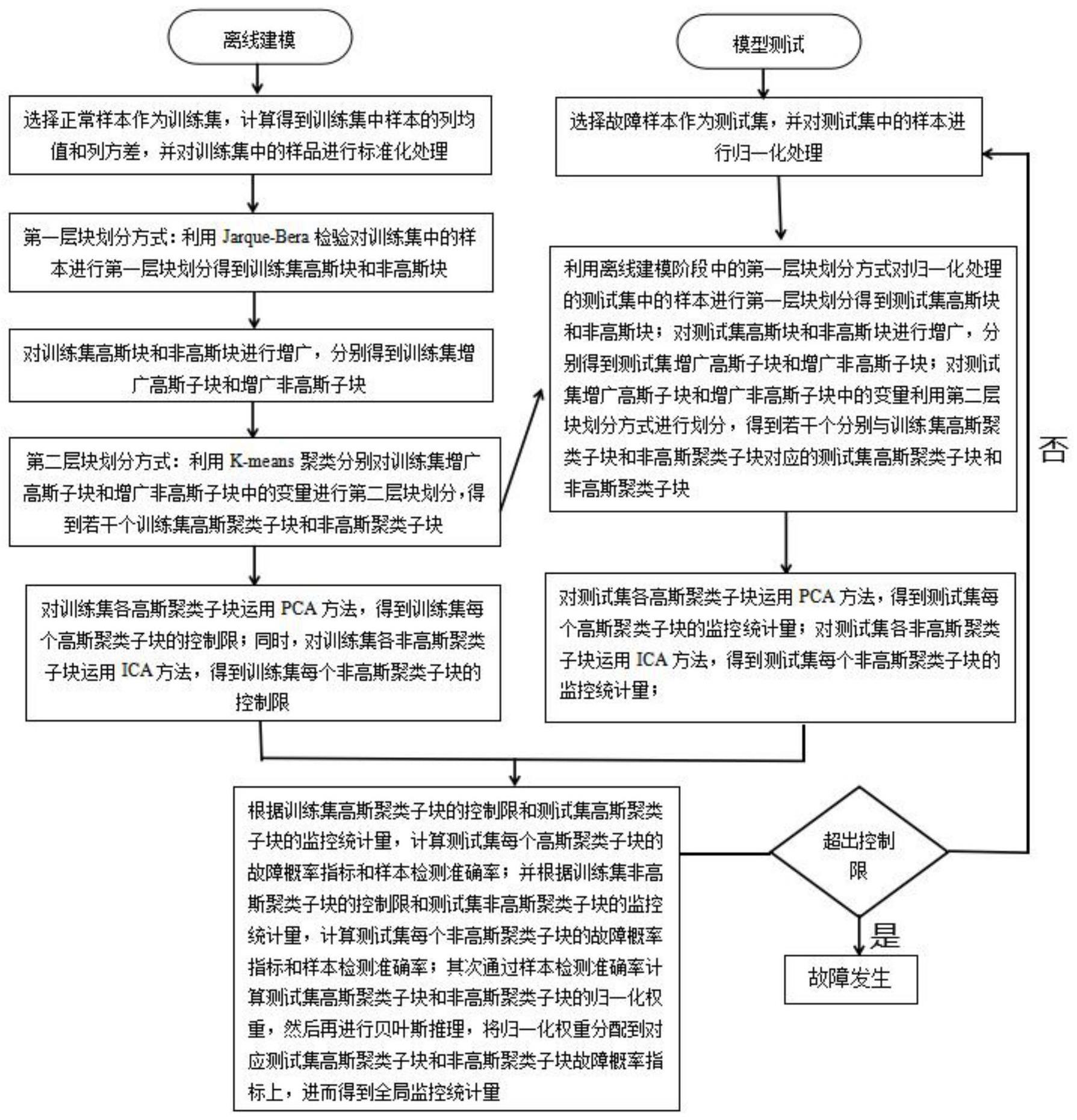
3、一种基于双层分布式和集成贝叶斯推理的故障检测方法,在工业系统重要节点处安装状态参数监测传感器,对状态参数进行采集和处理,得到包含n个样本和m个变量的样本集x=[x1,x2,...,xm]∈rn×m,所述样本集x既有正常样本也有故障样本,包括离线建模阶段和模型测试阶段;所述离线建模阶段包括如下步骤:
4、s11:选择正常样本作为训练集,计算得到训练集中样本的列均值和列方差,并对训练集中的样本进行标准化处理;
5、s12:第一层块划分方式:利用jarque-bera检验对训练集中的样本进行第一层块划分得到训练集高斯块和非高斯块;所述高斯块包含高斯变量,所述非高斯块包含非高斯变量;
6、s13:对s12得到的训练集高斯块和非高斯块进行增广,分别得到训练集增广高斯子块和增广非高斯子块。
7、s14:第二层块划分方式:利用k-means聚类分别对s13中训练集增广高斯子块和增广非高斯子块中的变量进行第二层块划分,得到若干个训练集高斯聚类子块和非高斯聚类子块;
8、s15:对s14中训练集各高斯聚类子块运用pca方法,得到训练集每个高斯聚类子块的控制限;同时,对s14中训练集各非高斯聚类子块运用ica方法,得到训练集每个非高斯聚类子块的控制限;
9、所述模型测试阶段包括如下步骤:
10、s21:选择故障样本作为测试集,并对测试集中的样本进行归一化处理;所述归一化处理是将样本的每列值减去s11中训练集样本的列均值再除以s11中训练集样本的列方差;
11、s22:利用离线建模阶段中的第一层块划分方式对归一化处理的测试集中的样本进行第一层块划分得到测试集高斯块和非高斯块;对测试集高斯块和非高斯块进行增广,分别得到测试集增广高斯子块和增广非高斯子块;对测试集增广高斯子块和增广非高斯子块中的变量利用离线建模阶段中的第二层块划分方式进行划分,得到若干个分别与s14中训练集高斯聚类子块和非高斯聚类子块对应的测试集高斯聚类子块和非高斯聚类子块;
12、s23:对s22中测试集各高斯聚类子块运用pca方法,得到测试集每个高斯聚类子块的监控统计量;对s22中测试集各非高斯聚类子块运用ica方法,得到测试集每个非高斯聚类子块的监控统计量;
13、s24:根据离线建模阶段s15中训练集高斯聚类子块的控制限和s23中得到的测试集高斯聚类子块的监控统计量,计算出s22中测试集每个高斯聚类子块的故障概率指标和样本检测准确率;并根据离线建模阶段s15中训练集非高斯聚类子块的控制限和s23中得到的测试集非高斯聚类子块的监控统计量,计算出s22中测试集每个非高斯聚类子块故障概率指标和样本检测准确率;其次通过样本检测准确率计算s22中对应测试集高斯聚类子块和非高斯聚类子块的归一化权重,然后再进行贝叶斯推理,将归一化权重分配到对应测试集高斯聚类子块和非高斯聚类子块故障概率指标上,进而得到全局监控统计量;
14、s25:判断s24所述全局监控统计量是否超过阈值,若是,说明检测到故障,离线建模阶段完成;若否,重新回到s11继续进行离线建模。
15、优选地,所述标准化处理是指将训练集中每个样本的每列元素减去其所在列的均值,再除以所在列的标准差,从而使每列元素服从均值为0,标准差为1的正态分布。
16、优选地,s13和s22中所述增广通过在高斯块中和非高斯块中加入变量时间滞后值的方式进行。
17、s15所述训练集每个高斯聚类子块的控制限的计算,包括如下步骤:
18、s1511:通过pca将训练集第i个高斯聚类子块xig进行分解,公式如下:
19、
20、其中,t∈rn×k,分别表示得分矩阵、载荷矩阵和残差矩阵,k代表主成分个数,通过计算累积方差百分比(cpv)得到;n表示样本个数;mi表示训练集第i个高斯聚类子块中的变量个数;(·)t表示转置运算;
21、s1512:通过公式计算得到ti2统计量和spei统计量,所述公式如下:
22、
23、
24、其中,表示训练集第i个高斯聚类子块;表示载荷矩阵;λk由主成分的协方差矩阵的前k个最大特征值组成;i表示单位矩阵;(·)t表示转置运算;
25、s1513:通过公式计算s1512中统计量和spei统计量对应的训练集第i个高斯聚类子块控制限,所述公式如下:
26、
27、
28、其中,k表示自由度;n表示样本个数;fk,n-k,α表示第一自由度为k,第二自由度为n-k的f分布;α表示显著性水平;cα是对应于高斯分布的标准偏差。
29、s15所述训练集每个非高斯聚类子块的控制限的计算,包括如下步骤:
30、s1521:通过ica将训练集第j个非高斯聚类子块xjng进行分解,公式如下:
31、
32、其中,a∈rn×d,e分别表示混合矩阵、独立成分矩阵和残差矩阵;n表示样本个数;mj表示训练集第j个非高斯聚类子块中的变量个数;d表示独立成分的数量;
33、s1522:采用fastica方法将分解为w和的乘积:
34、
35、其中,表示重构源信号矩阵;w表示分离矩阵;为训练集第j个非高斯聚类子块;对样本协方差矩阵c进行特征值分解,公式如下:
36、c=uδut (8)
37、其中,u代表特征向量,δ代表特征值组成的对角矩阵;
38、接着进行白化变换,即:
39、
40、其中,矩阵表示训练集第j个非高斯聚类子块;
41、引入正交矩阵b计算矩阵q:
42、z=qas=bs (10)
43、其中,a∈rn×d,分别表示混合矩阵、独立成分矩阵;n表示样本个数;mj表示训练集第j个非高斯聚类子块中的变量个数;d表示独立成分的数量;
44、因此,可以通过下式进行估计:
45、
46、s1523:由累积方差百分比(cpv)确定独立成分的数量d,最终得到训练集第j个非高斯聚类子块的和spej监控统计量:
47、
48、
49、其中,
50、s1524:采用核密度估计和spej监控统计量的控制限和spelimj;所述核密度估计是从一组随机样本中使用合适的平滑概率密度函数对数据集进行拟合的过程,被广泛应用于概率密度函数的估计;控制限和spelimj由各自的概率密度函数估算值计算得到;所述控制限和spelimj就是训练集第j个非高斯聚类子块的控制限。
51、s23中所述对s22测试集各高斯聚类子块运用pca方法,具体如下:在t2统计量下通过如下公式计算得到在线检测阶段测试集第i个高斯聚类子块发生故障的概率:
52、
53、其中,n和f表示正常和故障状态,表示测试集第i个高斯聚类子块对应的t2统计量,表示测试集第i个高斯聚类子块对应的控制限;表示测试集第i个高斯聚类子块;α表示设定的置信度。
54、s24中所述归一化权重用和表示,和分别表示测试集高斯聚类子块和测试集非高斯聚类子块的归一化权重,测试集第i个高斯聚类子块和测试集第j个非高斯子块归一化权重计算公式如下:
55、
56、其中,表示测试集第i个高斯聚类子块的样本检测准确率,表示测试集第j个非高斯聚类子块的样本检测准确率,所述样本检测准确率为被正确检测出所属状态的样本占总样本的比率。
57、全局监控统计量bic-c2的计算公式如下:
58、
59、其中,h表示测试集高斯聚类子块的数量;和分别表示测试集第i个高斯聚类子块和测试集第j个非高斯聚类子块的归一化权重;n和f分别表示正常和故障状态;表示测试集第i个高斯聚类子块;表示测试集第j个非高斯聚类子块;表示对于t2统计量,已知有故障发生的条件下,发生故障的概率;表示在t2统计量下,对于发生故障的概率;表示对于i2统计量,已知有故障发生的条件下,发生故障的概率;表示在i2统计量下,发生故障的概率;
60、全局监控统计量bic-spe的计算公式如下:
61、
62、其中n和f分别表示正常和故障状态;表示测试集第i个高斯聚类子块;表示测试集第j个非高斯聚类子块;和分别表示在spe统计量下,和的归一化权重;表示在spe统计量下,已知有故障发生的条件下,发生故障的概率;表示在spe统计量下,已知有故障发生的条件下,发生故障的概率;表示在spe统计量下,对于发生故障的概率;表示在spe统计量下,发生故障的概率。
63、优选地,基于双层分布式和集成贝叶斯推理的故障检测方法,还包括在线监测阶段;所述在线监测阶段,包括如下步骤:
64、s31:选择在线样本作为监测集,并对监测集中的样本进行归一化处理;所述归一化处理是将样本的每列值减去s11中训练集样本的列均值再除以s11中训练集样本的列方差;
65、s32:利用离线建模阶段中的第一层块划分方式对归一化处理的监测集中的样本进行第一层块划分得到监测集高斯块和非高斯块;对监测集高斯块和非高斯块进行增广,分别得到监测集增广高斯子块和增广非高斯子块;对监测集增广高斯子块和增广非高斯子块中的变量利用离线建模阶段中的第二层块划分方式进行划分,得到若干个分别与s14中监测集高斯聚类子块和非高斯聚类子块对应的监测集高斯聚类子块和非高斯聚类子块;
66、s33:对s32中监测集各高斯聚类子块运用pca方法,得到监测集每个高斯聚类子块的监控统计量;对s32中监测集各非高斯聚类子块运用ica方法,得到监测集每个非高斯聚类子块的监控统计量;
67、s34:根据离线建模阶段s15中训练集高斯聚类子块的控制限和s33中得到的监测集高斯聚类子块的监控统计量,计算出s32中监测集每个高斯聚类子块故障概率指标和样本检测准确率;并根据离线建模阶段s15中训练集非高斯聚类子块的控制限和s33中得到的监测集非高斯聚类子块的监控统计量,计算出s32中监测集每个非高斯聚类子块的故障概率指标和样本检测准确率;其次通过样本检测准确率计算s32中对应监测集高斯聚类子块和非高斯聚类子块的归一化权重,然后再进行贝叶斯推理,将归一化权重分配到对应监测集高斯聚类子块和非高斯聚类子块故障概率指标上,进而得到全局监控统计量;
68、s35:判断得到的全局监控统计量是否超过阈值,若是,说明检测到故障;若否,说明系统正常工作,重新回到s31继续进行在线监控。
69、有益效果:
70、本发明提供一种基于双层分布式和集成贝叶斯推理的故障检测方法,用于工业系统的故障检测,采用双层分布式策略,选择正常样本作为训练集,利用jarque-bera检验对训练集中的每一个样本进行第一层块划分将样本划分成训练集高斯块和非高斯块,考虑到训练集高斯块和非高斯块中各个监测变量存在的自相关或者互相关问题,对训练集高斯块和非高斯块进行增广解决此动态性问题,再利用k-means聚类方法对训练集增广高斯子块和增广非高斯子块中的变量进行第二层块划分得到训练集高斯聚类子块和非高斯聚类子块,使得所述每个聚类子块中的变量具有相同分布特征(高斯或非高斯性)和局部相似性,从而实现对监测数据分布特性、动态性、相似性等局部信息的充分挖掘,解决现有工业系统故障检测方法未能全面考虑数据的分布特征、变量的动态相关性、局部相似性的问题。由于上述各聚类子块监测结果的不确定性和不一致性,本发明提出集成贝叶斯推理突出不同局部监控模型的贡献,即将上述各聚类子块的样本检测准确率作为权重分配到各聚类子块故障概率指标上,得到综合的全局监控统计量最终有效地提高了故障检测的性能,解决现有工业系统故障检测方法无法强调各个局部模型的不同贡献信息,最终导致检测性能较差的问题。
71、本发明首先选择正常样本作为训练集,并对训练集中的样本进行第一层块划分和第二层块划分得到若干训练集高斯聚类子块和非高斯聚类子块,并计算上述各个聚类子块的控制限,然而,训练集中样本得到的每个聚类子块的控制限无法评价本发明所提方法的故障检测性能,因此选择已知为故障的故障样本来评估本发明方法的故障检测性能,为此选择故障样本组成测试集,利用本发明s22-s25的方法预测样本是否为故障样本,通过比较预测结果和实际结果,得到整个测试集的故障检测率,进而可以根据该故障检测率评价所提方法的故障检测性能。对于实际中未知的待检测样本,可以直接对其利用s31-s35所述步骤进行在线检测,判断该未知样本是否为故障样本。
- 还没有人留言评论。精彩留言会获得点赞!