模型预训练数据获取方法、模型预训练方法、装置及设备
本技术涉及神经网络模型预训练,更具体的说,是涉及一种模型预训练数据获取方法、模型预训练方法、装置及设备。
背景技术:
1、近年来,随着计算能力的提升和大规模文本数据的可用性,基于深度学习框架的语言模型对应的参数规模也在不断扩大,从而诞生了大语言模型(large language model,llm)。大语言模型能够呈现出一定的涌现能力,包括但不限于指令理解能力、上下文学习能力以及复杂推理能力等。
2、通用的大语言模型一般是基于互联网上开源的大量语料预训练的,通过前文预测下一个token的出现概率,在这个过程中,学习和记忆了丰富的上下文语言逻辑结构,进而记住了相关的知识。但是面向垂直领域,例如医疗、家装、司法等,往往呈现出专业知识不足的现象,不足以支撑完成垂直领域的特有任务。面对这样的现状,越来越多的领域大语言模型涌现出来。以医疗领域为例,涌现出如chatdoctor、medicalgpt-zh等模型。
3、但是,这些领域大语言模型中,有些跳过了利用领域语料进行预训练的过程,直接在通用大语言模型基础上进行领域指令微调fine-tuning,容易出现医学专业知识模型本身就不具备,从而无法应对下游任务的问题。另外一些模型仅采用部分医疗领域语料,按照通用大语言模型的训练方式进行了简单的预训练,并未考虑医疗领域语料数据的特点,使得医疗领域大语言模型无法充分的掌握医疗领域语料中的知识及知识间的关联关系,进而在处理下游任务时效果不佳。
技术实现思路
1、鉴于上述问题,提出了本技术以便提供一种模型预训练数据获取方法、模型预训练方法、装置及设备,以基于医疗领域数据特点构建训练数据,用于对医疗大语言模型进行预训练,帮助提升医疗大语言模型的能力。具体方案如下:
2、第一方面,提供了一种模型预训练数据获取方法,包括:
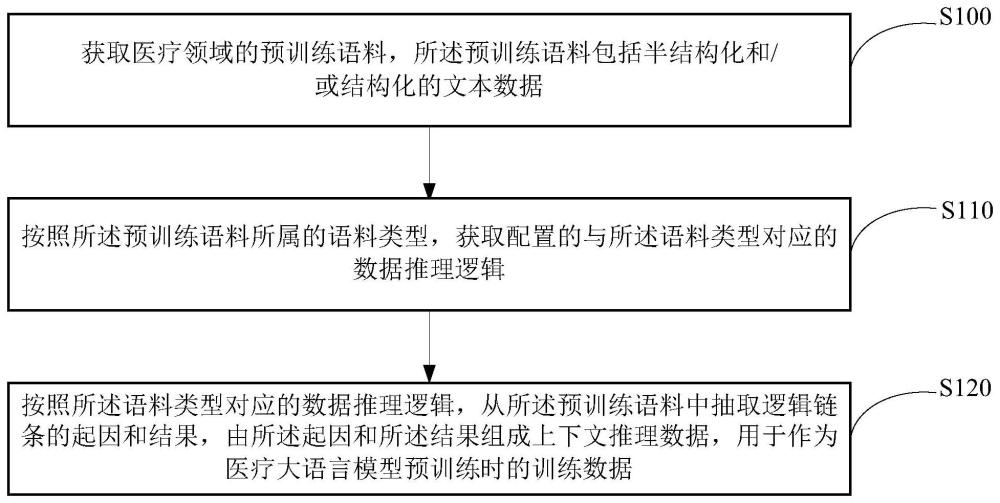
3、获取医疗领域的预训练语料,所述预训练语料包括半结构化和/或结构化的文本数据;
4、按照所述预训练语料所属的语料类型,获取配置的与所述语料类型对应的数据推理逻辑,所述数据推理逻辑用于表示所述语料类型对应语料内的不同医学知识间的因果推理关系;
5、按照所述语料类型对应的数据推理逻辑,从所述预训练语料中抽取逻辑链条的起因和结果,由所述起因和所述结果组成上下文推理数据,用于作为医疗大语言模型预训练时的训练数据。
6、优选地,按照所述语料类型对应的数据推理逻辑,从所述预训练语料中抽取逻辑链条的起因和结果的过程,包括:
7、遍历所述语料类型对应的每一条数据推理逻辑,获取预配置的当前遍历的数据推理逻辑中起因字段和结果字段各自在同一份所述预训练语料中的位置信息;
8、根据所述位置信息在所述预训练语料中定位所述起因字段和所述结果字段,并获取所述起因字段对应的字段值作为所述起因,以及获取所述结果字段对应的字段值作为所述结果。
9、优选地,所述预训练语料还包括非结构化的文本数据。
10、优选地,该方法还包括:
11、将所述预训练语料也作为所述医疗大语言模型预训练时的训练数据。
12、优选地,所述预训练语料中的半结构化文本数据包括病历数据。
13、优选地,在从所述预训练语料中抽取逻辑链条的起因和结果之前,还包括:对所述预训练语料进行去重处理,该过程包括:
14、将所述预训练语料按照所述语料类型进行划分;
15、对于每一语料类型下的每一份语料文本,抽取所述语料文本的代表词,对每一份语料文本的各所述代表词进行编码,得到每一份语料文本对应的向量表示;
16、计算同一语料类型下各份语料文本之间的向量相似度,并按照向量相似度对同一语料类型下的各份语料文本进行聚类,并进行类内去重,得到同一语料类型下去重后的语料文本。
17、优选地,抽取所述语料文本的代表词的过程,包括:
18、统计所述语料文本中各词的出现次数,选取出现次数最高的topn1个高频词,作为所述语料文本的代表词;
19、对于每一语料类型下的每份语料文本,计算其中每个词的词频-逆文本频率tfidf分数,选取tfidf分数最高的topn2个高分词,作为所述语料文本的代表词。
20、第二方面,提供了一种模型预训练方法,包括:
21、获取前述的模型预训练数据获取方法所得到的训练数据,利用所述训练数据对医疗大语言模型进行预训练。
22、优选地,利用所述训练数据对医疗大语言模型进行预训练的过程,包括:
23、以所述上下文推理数据中的所述起因作为输入,以所述结果作为预测目标,对所述医疗大语言模型进行预训练。
24、优选地,在所述训练数据包括所述预训练语料时,利用所述训练数据对医疗大语言模型进行预训练的过程,还包括:
25、确定所述预训练语料中的医学实体词,以预测所述预训练语料中的所述医学实体词为预训练任务,对所述医疗大语言模型进行训练。
26、优选地,利用所述训练数据对医疗大语言模型进行预训练的过程,还包括:
27、对所述预训练语料进行切分,并利用切分得到的上文作为输入,切分得到的下文作为预测目标,对所述医疗大语言模型进行预训练。
28、优选地,所述医疗大语言模型采用自回归模型、自编码模型或编解码模型。
29、第三方面,提供了一种模型预测训练数据获取装置,包括:
30、预训练语料获取单元,用于获取医疗领域的预训练语料,所述预训练语料包括半结构化和/或结构化的文本数据;
31、推理逻辑获取单元,用于按照所述预训练语料所属的语料类型,获取配置的与所述语料类型对应的数据推理逻辑,所述数据推理逻辑用于表示所述语料类型对应语料内的不同医学知识间的因果推理关系;
32、逻辑链条抽取单元,用于按照所述语料类型对应的数据推理逻辑,从所述预训练语料中抽取逻辑链条的起因和结果,由所述起因和所述结果组成上下文推理数据,用于作为医疗大语言模型预训练时的训练数据。
33、第四方面,提供了一种模型预训练装置,包括:
34、预训练数据获取单元,用于获取前述的模型预训练数据获取方法所得到的训练数据;
35、模型训练单元,用于利用所述训练数据对医疗大语言模型进行预训练。
36、第五方面,提供了一种终端设备,包括:存储器和处理器;
37、所述存储器,用于存储程序;
38、所述处理器,用于执行所述程序,实现如前所述的模型预训练数据获取方法的各个步骤,或者,实现如前所述的模型预训练方法的各个步骤。
39、借由上述技术方案,本技术针对半结构化和/或结构化的预训练语料文本,按照其所属语料类型预先配置了对应的数据推理逻辑,也即本技术根据医学领域下预训练语料的特点挖掘了半结构化、结构化的预训练语料的内部数据推理逻辑,能够表语料内不同医学知识间的因果推理关系,示例如针对病历这种半结构化语料,数据推理逻辑可以包括病历中不同章节内不同数据字段之间的因果关系,如依据诊断结果可以推导治疗科室等推理逻辑,上述数据推理逻辑在预训练语料中可能并非连续的上下文,因而通过传统的基于上文预测下一个token的出现概率的训练方式无法学习到该数据推理逻辑。为了提升模型的学习能力,本技术按照语料类型对应的数据推理逻辑,从预训练语料中抽取逻辑链条的起因和结果,由起因和结果组成上下文推理数据,进而用于作为医疗大语言模型预训练时的训练数据。显然,采用本技术得到的上下文推理数据,在训练医疗大语言模型时,可以使得模型学习到逻辑链条中从起因到结果的推理逻辑,也即学习到语料内部医学知识间的推理逻辑,能够提升医疗大语言模型的能力。
- 还没有人留言评论。精彩留言会获得点赞!