融合检索和填空的文本数据增强方法、装置及电子设备与流程
本技术涉及文本数据处理,具体为一种融合检索和填空的文本数据增强方法、装置及电子设备。
背景技术:
1、任务型机器人的核心在于意图识别,本质上是一个分类任务,将用户问句预测到预先定义好的意图类别,并发送对应的回答完成对话。由于用户表达习惯、输入方式等方面的不同,一种意图类别的说法多样,但表达的意思相似。而模型的训练数据(有标签数据/监督数据)中往往只涵盖了部分常见的问法,导致很多属于该意图下的问句无法被模型预测。
2、为了提升模型分类效果,往往需要通过数据增强的技术手段获取更多的有标签数据。目前的数据增强方法主要基于词级别,短语级别,和句子级别。
3、其中,词级别的数据增强方法包括词的插入、删除、交换、同义词的替换等。同义词的来源可以是人工收集任务相关的同义词,也可通过语义嵌入寻找在特征空间距离相近的词。另一种生成式的单词替换方法基于预训练语言模型的mlm方法,以一定的概率随机掩盖句子中的单词,用模型预测被遮盖位置生成新的词替换原始词。基于短语的数据增强方法与词级别的数据增强方法类似,但短语相对单词来说,增强后的数据多样性与随机性更强。上述的方法虽然易于使用且不需要模型训练,但从业务层面出发,同义词或短语是有限的,且过多的替换容易丢失语义信息;另一方面,即使保留了原始句子语义,由于句子变化有限,模型可能原本就能预测正确大部分增强的数据,这样的数据即使再多,对模型效果提升也有限。
4、相比之下,句子级别从整个句子出发,多样性与应用型更强。典型的做法是回译,将句子翻译成外语,再从外语翻译回源语言,通过翻译变化原始句子的句式、语序、及句中单词,该方法虽然使用方便,保证了语义的不变性,但依赖于翻译器的效果,可控性和多样性有限。另一种序列到序列模型先通过编码器得到输入句子的特征表示,再将表征输入到解码器,生成新的相似句,该方法首先需要相似句对训练模型,且生成结果不可控。这两种方法都是根据现有数据生成新的数据,增强数据的数量和可利用率有限。而基于自训练的增强方法先在有标签数据上训练一个教师模型用来预测未标注的数据,将预测结果作为未标注文本数据的标签,和原始数据一起训练一个新的学生模型用于分类任务。也有方法进一步的通过相似句检索从海量无标签语料中提取相关领域数据作为教师模型的检索数据。
5、生成式的数据增强方法可控性低,且生成的数据对于模型性能的提升有限,在需要相似句对训练数据的情况下,训练成本高。结合意图识别的业务场景来看,线上有大量的未标注文本数据可用来做增强的语料库,但上述自训练方法并不适用于意图识别场景,由于未标注文本数据的可能意图范围(大部分无意图定义)明显大于有标签数据的意图定义范围,直接基于有标签数据的意图预测线上未标注文本数据,会造成大量错误标签预测,而标签错误的训练语料将直接影响最终模型的效果。除此之外,由于领域内训练数据相对线上大量的未标注文本数据来说只是小样本数据,对于bert之类的预训练语言模型,在少量样本上微调模型,模型效果提升有限甚至可能影响模型整体效果。
6、因此,需要一种未标注文本数据作为数据来源,同时在少量训练数据上也能取得较好效果的数据增强方法,能够预测更多线上数据,提升模型识别率和准确。
技术实现思路
1、本技术提供一种融合检索和填空的文本数据增强方法、装置及电子设备,以特定领域未标注文本数据作为数据来源,同时在少量训练数据上也能取得较好效果的数据增强方法,能够预测更多线上数据,提升模型识别率和准确。
2、本技术解决其技术问题所采用的技术方案是:一种融合检索和填空的文本数据增强方法,包括:
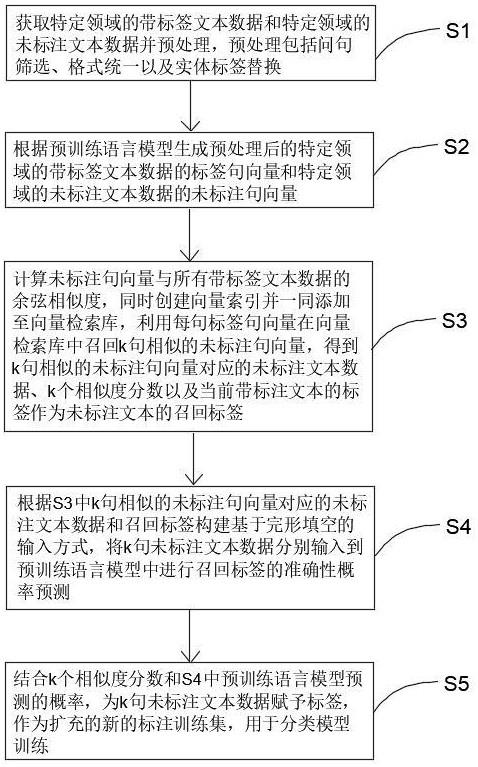
3、s1:获取特定领域的带标签文本数据和特定领域的未标注文本数据的字符格式并预处理,预处理包括问句筛选、格式统一以及实体标签替换;
4、s2:根据预训练语言模型生成预处理后的特定领域的带标签文本数据的标签句向量和特定领域的未标注文本数据的未标注句向量;
5、s3:计算未标注句向量与所有带标签文本数据的余弦相似度,同时创建向量索引并一同添加至向量检索库,利用每句标签句向量在向量检索库中召回k句相似的未标注句向量,得到k句相似的未标注句向量对应的未标注文本数据、k个相似度分数以及当前带标注文本的标签作为未标注文本的召回标签,k个未标注文本数据的召回标签即为当前带标签文本数据的真实标签,因此召回标签只有1个;
6、s4:根据s3中k句相似的未标注句向量对应的未标注文本数据和召回标签构建基于完形填空的输入方式,将k句未标注文本数据分别输入到微调过的预训练语言模型中进行召回标签的准确性概率预测;
7、s5:结合k个相似度分数和s4中预训练语言模型预测的概率,为k句未标注文本数据赋予标签,作为扩充的新的标注训练集,用于分类模型训练。
8、本融合检索和填空的文本数据增强方法采用基于相似句检索的候选句召回方式和基于完形填空输入方式的分类任务进行特定领域增强数据的筛选,在保证候选问句与原始问句标签一致的基础上,获取多样的增强数据用于分类模型的训练,提高分类模型的识别率及分类准确率,采用的完形填空的输入方式使语言模型在预测和预训练时的输入方式更加一致,充分发挥模型预训练时在无监督任务中学习到的先验知识,在训练数据较少的情况下也能取得较好的效果。
9、作为优选,在数据预处理阶段,目的是统一标准化带标签文本数据和未标注文本数据的字符格式,确保数据质量,并去除潜在的噪声,减少因不同格式引发的数据损失,带标签文本数据来源为直接使用特定领域的训练数据,未标注文本数据来源为线上设置了特定领域的所有店铺数据,其中未能识别出特定意图的数据被视为未标注文本数据的语料库。本技术选择线上未识别数据作为潜在的数据增强来源,因此召回的数据量越大,线上店铺的数据识别率也将随之提升,这里的线上指的是能获取到的特定领域的在线智能客服平台。由于不包含任何中文字符的问句一般不包含有用的语义信息因此预处理时采用正则表达式筛选含中文字符的问句,过滤不包含任何中文字符的问句,然后统一数据格式,具体的统一规则包括:去除问句中的表情符号;将全角符号转为半角;大写字母转为小写字母;保留问句中的中文符号、英文字母、数字、逗号和问号以及去除连续的逗号、问号、空格及句子首尾的空格。数据格式统一后根据领域特性抽取数据中的实体词汇并进行实体标签替换。
10、作为优选,在句向量生成阶段,旨在将经过预处理的句子通过句向量进行表征,使其能够为后续的应用步骤提供基础数据。尽管存在通用的大型语言模型,如bert(bidirectional encoder representations from transformers),但这些模型可能并不总是最佳选择,尤其当处理特定垂直领域的数据时。因此,需要针对特定领域训练一个专门的语言模型,本技术的预训练语言模型训练过程如下:
11、s21:准备训练数据:从特定领域中利用步骤s1筛选出属于该领域的数据;
12、s22:模型架构选择与初始化:选择bert作为基础架构,使用通用预训练的bert模型作为初始参数;
13、s23:模型正负样本构建:由于bert结构在训练过程中引入了随机dropout机制,相同的输入句子会产生两个略有差异的向量,因此可以将同一个句子的2个向量视作正样本,而与另一个句子的向量视作负样本,因此本技术将同一个句子xi连续两次输入到bert模型的编码器中,分别得到向量hi和hi’视作正样本,hi和其他句子的句向量hj视作负样本,根据向量hi, hi’和hj定义损失函数;
14、s24:模型训练:使用优化算法对损失函数进行优化,不断调整模型的参数直到损失函数收敛;
15、s25:模型存储:将训练完成的预训练语言模型进行存储备用。
16、作为优选,在句向量生成后,需要将生成的句向量入库存储并生成索引,由于未标注文本数据的数量级较大,两两计算的耗时也相对较大,为了提高计算效率,利用相似向量检索库faiss进行向量检索。具体的,计算未标注句向量与所有带标签文本数据的余弦相似度,同时创建向量索引并一同添加至向量检索库,遍历标签句向量在索引中召回前k个余弦相似度得分最高的未标注句向量,得到距离矩阵和索引矩阵,m为带标签文本数据的数量,d表示每条带标签文本数据与相似句的余弦相似度,i表示带标签文本数据召回的未标注相似句在所有未标注文本数据语料库中的索引位置,余弦相似度计算公式为:
17、,表示标签句向量,表示未标注句向量,得到k句相似的未标注句向量对应的未标注文本数据、k个相似度分数以及当前带标注文本的标签作为未标注文本的召回标签。
18、检索结束后,得到每条带标签文本数据及其召回的未标注文本数据相似句和对应的相似分数,对应的其中一种带标签文本数据的存储格式如下,{“label_data”:label_data_i,“label”:label_i,“recall_data_list”:[{“recall_data”:unlabel_data_j,“score”:score_ij}...,{}]}。汇总每一条被召回的未标注文本数据,统计其被召回的标签,若同一标签有多个召回源,则计算平均相似分数,并存储记录。其中一种未标注文本数据的存储格式如下,{“unlabel_data_1”:[{“recall_label”:label_1,“recall_score”:avg_socre_1},...,{“recall_label”:label_i,“recall_score”:avg_socre_i}]}。
19、作为优选,在标签预测阶段,旨在进一步过滤通过相似度检索的未标注文本数据,由于在字面或语义上相似的句子不一定属于同一数据标签领域,所以需要进一步筛选出每个标签的数据,具体的,完形填空的模型输入方式具体为:在s3中召回的未标注句向量对应的未标注文本数据的基础上拼接任务描述作为模板p(x),模板p(x) 中表示是非判断的字词用[mask]符号掩盖,被遮盖的位置填充可映射到真实标签l的软标签y,最终实现问句和标签的二分类判断。模型预测被遮盖位置的输出字符,将预测概率最大的软标签作为问句的二分类判断结果。
20、作为优选,模板p(x) = [x]这句话属于[l]意图吗?[mask],其中,x表示原始问句,l表示当前召回的标签,[mask]为表示是非判断的字词的位置,不同类别的软标签y的字符数相等,软标签y设定为[是]和[否],分别映射到真实标签[t]和[f],[t]类别的数据为特定领域的训练数据中每一个标签对应的训练数据,[f]类别的数据为每一个标签对应的错误数据,错误数据的来源为线上预测到该标签,但预测错误的数据,预训练分类模型微调完成后,利用存储的模型和上述构造的输入模板p(x),将召回的未标签数据中的每一个标签分别输入到模型中,并预测概率。其中一种可能的存储方式为,{“unlabel_data_1”:[{“recall_label”:label_1,“recall_score”:avg_socre_1,“predict_score”:predict_socre_1},...,{“recall_label”:label_i,“recall_score”:avg_socre_i,“predict_score”:predict_socre_i}]}。
21、作为优选,为k句未标注文本数据赋予标签时,判断每个未标注句向量是否属于所赋予标签时,若未标注句向量仅存在一种召回标签且综合分数符合要求则认为属于该标签,若未标注句向量存在大于一种标签则选择综合得分最高的标签作为唯一的召回标签,当唯一的召回标签的综合分数符合要求则认为属于该标签。
22、本技术提供了一种特定领域语言分类增强装置,包括:
23、预处理单元:用于获取特定领域的带标签文本数据和特定领域的未标注文本数据的字符格式并预处理,预处理包括问句筛选、格式统一以及实体标签替换;
24、向量生成单元:用于根据预训练语言模型生成预处理后的特定领域的带标签文本数据的标签句向量和特定领域的未标注文本数据的未标注句向量;
25、相似向量召回单元:用于计算未标注句向量与所有带标签文本数据的余弦相似度,同时创建向量索引并一同添加至向量检索库,利用每句标签句向量在向量检索库中召回k句相似的未标注句向量,得到k句相似的未标注句向量对应的未标注文本数据、k个相似度分数以及当前带标注文本的标签作为未标注文本的召回标签;
26、标签类别预测单元:用于根据s3中k句相似的未标注句向量对应的未标注文本数据和召回标签构建基于完形填空的输入方式,将k句未标注文本数据分别输入到微调过的预训练语言模型中进行召回标签的准确性概率预测;
27、标签赋予单元:用于结合k个相似度分数和s4中预训练语言模型预测的概率,为k句未标注文本数据赋予标签,作为扩充的新的标注训练集,用于分类模型训练。
28、一种电子设备,包括存储器和处理器,所述存储器用于存储一条或多条计算机指令,其中,所述一条或多条计算机指令被所述处理器执行以实现如上述中任一项所述的融合检索和填空的文本数据增强方法。
29、本技术的实质性效果是:
30、本融合检索和填空的文本数据增强方法以特定领域未标注文本数据作为数据来源,同时在少量训练数据上也能取得较好效果的数据增强方法,能够预测更多线上数据,提升模型识别率和准确;
31、本融合检索和填空的文本数据增强方法是一种可以扩充特定领域数据的数据增强方法,解决训练数据和未标注文本数据意图分布不一样的问题;
32、本融合检索和填空的文本数据增强方法基于相似句检索的候选句召回方式,和基于完形填空输入方式的分类任务进行特定领域增强数据的筛选,在保证候选问句与原始问句标签一致的基础上,获取多样的增强数据用于分类模型的训练,提高分类模型的识别率及分类准确率;
33、本融合检索和填空的文本数据增强方法采用的完形填空的输入方式类似bert模型预训练时的mlm(masked language model)任务,使语言模型在预测和预训练时的输入方式更加一致,充分发挥模型预训练时在无监督任务中学习到的先验知识,在训练数据较少的情况下也能取得较好的效果,适用于标签数据较少的所有领域。
- 还没有人留言评论。精彩留言会获得点赞!