一种计算数据温度并进行分层存储管理的方法
本发明属于计算机数据处理领域,具体涉及一种计算数据温度并进行分层存储管理的方法。
背景技术:
1、数据中心的主要功能之一就是对数据的存储。近年来,数据中心的数据量以指数级的速度迅速增加,人们对数据管理和处理能力的需求日益增长,这对数据中心的存储能力提出了更高的要求。为了应对数据量的急剧增加,必须考虑对数据进行冷热识别,将数据分配到不同的存储介质上进行存储,以实现数据访问响应速度和数据中心运营成本之间的平衡。
2、hdd机械硬盘作为最常用的存储设备,价格较低但读取速度较慢,无法满足高速访问的需求,适合作为冷数据库的存储设备。相反,固态硬盘ssd的读取速度较快,但其价格较高,不能大规模应用,适合作为热数据库的存储设备。
3、当前大多发达城市土地开发接近饱和,水电等基础物质供应也处于紧张状态,而一些内陆地区新能源发展成效显著,电价更低,气温也相对较低,适合建设数据中心,“东数西存”得到了广泛的重视和发展,如何在新的数据管理需求和形势下进行数据管理是一个亟待研究和解决的问题。
4、在一段时间内,数据的访问满足“二八定律”,即大部分访问集中在小部分数据上。数据的冷热程度描述了被使用的频繁程度,热数据通常指被频繁访问的数据,冷数据指被访问频率较低,但需长期保留的数据。如果能够准确地识别数据的冷热程度,我们就可以把频繁使用的数据存储到本地性能更优的ssd上,把使用频率中等的数据存储到本地成本更低的hdd中,把使用频率较低的数据存储到远程容量更大的hdd中,实现数据分层存储。
5、对冷热数据识别的研究中,最常见的解决方法是缓存替换的两大经典算法lru(least recently used)和lfu(least frequently used)。但lru在面对偶发性、周期性数据访问时性能较差;lfu在访问模式经常变化时性能较差。后人在lru和lfu的基础上提出了lru-k和lfu-aging,lru-k在lru的基础上增加了计数器来统计数据访问次数,只有当数据访问次数达到k次时,数据才会进入热存储空间中;
6、lfu-aging在lfu的基础上增加了对访问时间的约束,来避免历史访问次数较多的数据驻留在热存储空间的问题。但利用简单的数据结构识别冷热数据无法在任意访问模式下都保持良好的性能。近年来出现了用数据温度值衡量数据热度的方法,但仍然只评估了访问时间、访问频率和访问关联性等基本访问特征,没有考虑数据访问中用户和数据的重要程度对数据热度的影响。
技术实现思路
1、本发明所要解决的技术问题是:
2、为了解决现有冷热数据识别方法中只评估了访问时间、访问频率和访问关联性等基本访问特征,没有考虑数据访问中用户和数据的重要程度对数据热度的影响,以及在对数据的存储管理中只考虑了本地不同介质的存储管理,没有综合考虑本地与远程的存储管理,本发明提供一种计算数据温度并进行分层存储管理的方法。
3、为了解决上述技术问题,本发明采用的技术方案为:
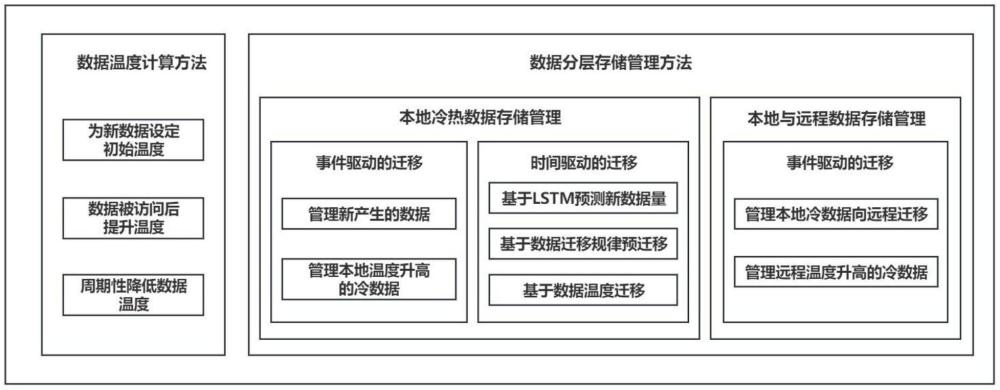
4、一种计算数据温度并进行分层存储管理的方法,其特征在于,包括:
5、根据数据访问时间、数据访问次数、数据属性和发出访问的用户属性,构建数据温度计算模型;
6、根据数据从冷数据库迁移至热数据库的时间,挖掘数据周期性迁移规律;
7、本地冷热数据存储管理:根据数据温度和数据周期性迁移规律,管理本地数据在本地冷热数据库之间迁移,迁移分为事件驱动的迁移和时间驱动的迁移,所述事件驱动包括新数据产生和本地冷数据温度升高;时间驱动为周期性发生;
8、本地与远程数据存储管理:根据数据温度,管理数据在本地数据库和远程数据库之间迁移,迁移为事件驱动的迁移,所述事件驱动包括远程冷数据温度升高和本地冷数据库存储空间不足。
9、本发明进一步的技术方案:所述的数据温度计算模型描述如下:
10、为新数据设定初始温度,将该新数据产生时热数据的平均温度设定为新数据的初始温度;初始温度的计算公式为:
11、
12、其中,hotdatacount表示热数据的个数,thotdata(i)表示第i个热数据的温度;
13、提升被访问后的数据温度,计算公式为:
14、tnew=tpre+α+β×i+γ×q
15、其中,i和q表示发出访问的用户属性和数据属性,tpre为访问前数据的温度,α、β和γ分别表示在一次访问中,基础访问、用户属性和数据属性对温度贡献的权重;
16、周期性降低数据温度,计算公式为:
17、tnew=δ*tpre
18、其中,tpre为降低之前的数据温度,δ为温度削弱系数。
19、本发明进一步的技术方案:挖掘数据周期性迁移规律的具体方法如下:
20、用二维数组coldtohotperiod[d,y]记录冷数据d第y次被迁移至热数据库所在的周期数;当冷数据d第y次被迁移至热数据库,且y≥4时,计算:
21、gapi=coldtohot[d,y-i]-coldtohot[d,y-i-1],i=0,1,2
22、若满足:
23、gap0=gap1=gap2
24、则认为冷数据d从冷数据库到热数据库的迁移具有周期性规律,周期gap为:
25、gap=gap0=gap1=gap2
26、预测下次迁移发生在第n周期,n的计算公式为:
27、n=coldtohot[d,y]+gap
28、在第n-1周期末对数据d进行预迁移,每条规律的有效期为m个周期gap。
29、本发明进一步的技术方案:在本地冷热数据存储管理中,所述新数据时发生迁移描述如下:
30、将新数据存放至本地热数据库,若热数据库可用存储空间不足,需要按照温度由低到高的顺序淘汰若干热数据至本地冷数据库。
31、本发明进一步的技术方案:在本地冷热数据存储管理中,所述本地冷数据温度升高时发生迁移描述如下:
32、在冷数据被访问且温度更新后,判断其温度是否达到了热数据温度标准值,若是,则将其迁移至热数据库以满足数据访问需要;
33、若热数据库可用存储空间不足,需要按照温度由低到高的顺序淘汰若干热数据至本地冷数据库。
34、本发明进一步的技术方案:在本地冷热数据存储管理中,所述时间驱动的迁移具体方法如下:
35、设置迁移周期,在每个周期末进行本地冷热数据库之间的数据迁移,将预测下个周期即将被迁移至热数据库的数据以及当前温度最高的数据存储在热数据库,同时保证迁移完成后热数据库已用存储空间不超过上限阈值;
36、步骤1-1:计算上限阈值;
37、上限阈值表示时间驱动的迁移完成后热数据库已用存储空间的上限;基于lstm预测下个周期产生的新数据量e,用c表示热数据库总存储容量,上限阈ζ值的计算公式为:
38、ζ=c-0.5×e
39、步骤1-2:基于周期性迁移规律筛选出需要预迁移的数据集合;
40、设本次迁移的上限阈值为ζ,按照温度由高到低的顺序遍历冷数据,选出需要预迁移的数据组成集合d1={d1,d2,…,dn},对应的数据大小集合v1={v1,v2,…,vn},集合d1包括所有预迁移的数据,或满足且
41、步骤1-3:基于数据温度筛选出需要迁移的数据集合;
42、计算热数据库剩余可用空间vr,计算公式为:
43、
44、设全集u为所有数据,在u-d1集合中按照温度由高到低的顺序选出数据组成集合d2={dn+1,dn+2,…,dm},对应的数据大小集合v2={vn+1,vn+2,…,vm},满足且
45、步骤1-4:迁移数据;
46、设集合d=d1+d2,先将热数据库中不属于集合d的数据迁移至冷数据库,再将集合d中位于冷数据库的数据迁移至热数据库。
47、本发明进一步的技术方案:基于lstm预测下个周期产生的新数据量的具体方法如下:
48、训练lstm模型的步骤如下:
49、步骤2-1:采集过去240周共1680条数据作为数据集,并将数据集中的所有数据标准化;
50、步骤2-2:构造输入和输出样本,每条输入样本共84条数据,即i(i)={xi,xi+1,…,xi+83},每条输出样本共7条数据,即o(i)={xi+84,xi+85,…,xi+90},并将样本集的80%作为训练集,20%作为测试集;
51、步骤2-3:构建lstm网络,使用keras深度学习框架建立sequential模型,向其中加入3层lstm,1层全连接层和1层输出层,在第一层lstm中设置the_units,input_shape,activation和return_sequences,第二层lstm去掉input_shape,第三层lstm去掉input_shape和return_sequences,dropout值设置为0.1,激活函数使用relu;
52、步骤2-4:编译lstm网络,优化器选用adam,损失函数选用mse,评估函数选用mape;
53、使用训练好的lstm模型进行预测时,将最近12周每日的新数据量共84条数据进行标准化作为输入,将输出序列反标准化得到预测的未来1周7天每日的新数据量序列。
54、本发明进一步的技术方案:在本地与远程数据存储管理中,所述远程冷数据温度升高时发生迁移描述如下:
55、在冷数据被访问且温度更新后,判断其温度是否达到了热数据温度标准值,若是,则将其迁移至热数据库以满足数据访问需要;
56、若热数据库可用存储空间不足,需要按照温度由低到高的顺序淘汰若干热数据至本地冷数据库。
57、本发明进一步的技术方案:热数据库存储空间不足时淘汰热数据的具体方法如下:
58、步骤3-1:判断本周期内是否已经构建热数据链表,若未构建则构建热数据链表,链表结点存储数据名称、数据温度和数据大小;
59、步骤3-2:按照数据温度值由大到小的顺序,对热数据链表进行排序;
60、步骤3-3:淘汰当前温度最低的数据至冷数据库;
61、步骤3-4:判断热数据库存储空间是否充足,若是,转到步骤3-5;若否,转到步骤3-3;
62、步骤3-5:将要迁移至热数据库的冷数据进行迁移,同时将数据信息插入热数据链表。
63、本发明进一步的技术方案:在本地与远程数据存储管理中,所述本地冷数据库存储空间不足时发生迁移描述如下:
64、设本地冷数据库存储空间的上限阈值为本地冷数据库总存储容量的90%,达到上限阈值时,说明本地冷数据库的存储空间不足,触发本地冷数据向远程的迁移;
65、基于存储成本计算单位数据存储在远程相比于存储在本地的收益,计算方法如下:
66、存储成本cost包括金钱成本expcost和时延成本dlycost,用costl表示冷数据在本地的存储成本,计算公式为:
67、costl=expcostl+θ*dlycostl
68、用costr表示冷数据在远程的存储成本,计算公式为:
69、costr=expcostr+θ*dlycostr
70、expcost的计算公式为:
71、expcost=s*e*ep
72、其中,s表示数据文件的大小,e表示存储单位数据的功率,ep表示电费单价;
73、dlycost的计算公式为:
74、
75、其中,bw表示带宽,pd表示传播时延,dlycostr中的pdr通过测量短消息的时延获得,dlycostl中的pdl忽略不计;t'对数据温度t进行了归一化处理,计算公式为:
76、
77、其中,tmin和tmax分别表示本地冷数据中温度的最低值和最高值;
78、用udy表示单位数据存储在远程相比于存储在本地的收益,计算公式为:
79、
80、其中,θ为时延成本相对于金钱成本的权重,epdiff表示本地与远程电费单价的差值;通过调整θ的值来改变迁移至远程的数据量。
81、本发明的有益效果在于:
82、本发明提供的一种计算数据温度并进行分层存储管理的方法,相比于现有技术其有益效果如下:
83、(1)本发明基于不同的用户属性和数据属性,对数据访问划分类别,不同类别的访问对数据温度具有不同的贡献值,能够在资源有限的情况下优先满足重要用户的满意度。
84、(2)本发明使用lstm预测下个周期新数据的量,基于新数据量的预测值对时间驱动迁移的上限阈值进行决策,能够平衡热存储空间使用率和数据迁移开销。
85、(3)本发明通过分析数据的周期性访问规律和序列访问模式,把预测即将发生数据迁移的数据提前进行迁移,能够避免数据温度变化后,数据迁移存在时间滞后性的问题。
86、(4)本发明对数据中心中数据的实时冷热程度进行了量化,分层存储能够在存储海量数据的情况下保持较高的热数据库命中率和较快的访问响应时间。
87、(5)本发明提出了一种本地与远程数据存储管理方案。
- 还没有人留言评论。精彩留言会获得点赞!