一种知识蒸馏半自动可视化标注方法及系统与流程
本发明涉及数据标注,具体涉及一种知识蒸馏半自动可视化标注方法及系统。
背景技术:
1、随着深度学习在医学图像分析中的广泛应用,对大规模高质量标注数据的需求日益增长。然而,由专业医生进行手工标注费时费力,难以获取充足的标注数据。与此同时,医学院内积累了大量未标注的医学图像,直接丢弃这些数据将造成巨大浪费。近年来,自监督学习技术的发展为此带来机遇。通过设计预训练任务,自监督模型可以学习到数据的内在表征,而无需人工标注。而知识蒸馏技术可以让小型模型压缩大型模型的知识。如果能利用自监督学习预训练一个教师模型,再通过蒸馏使小学生模型模仿教师模型的输出,就可以训练出一个数据标注的“专家”模型。该模型可以为新采集的未标注图像提供自动化标注。医生只需要对其标注结果进行校验修正,就可以获得大量高质量标注数据。目前需要设计一种知识蒸馏半自动可视化标注方法及系统,其能够利用医院内现有的数据资源,满足自监督知识蒸馏的医学图像标注,减轻了医生工作负担,实现了自动化的协作标注和数据隐私的保护,提升了医学数据标注的效率和质量。
技术实现思路
1、本发明所要解决的技术问题是医生手动标注工作负担重,医学数据标注的效率和质量不高,目的在于提供一种知识蒸馏半自动可视化标注方法及系统,其能够利用医院内现有的数据资源,实现自监督知识蒸馏的医学图像标注,减轻了医生工作负担,满足了自动化的协作标注和数据隐私的保护,提升了医学数据标注的效率和质量。
2、本发明通过下述技术方案实现:
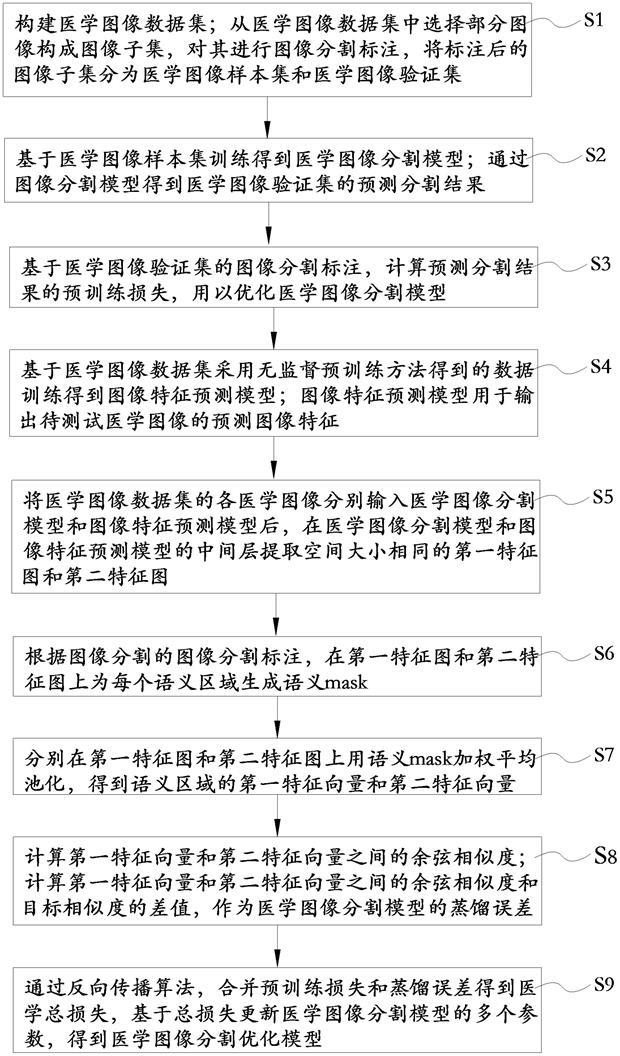
3、一种知识蒸馏半自动可视化标注方法,包括:s1:构建医学图像数据集;选择上述医学图像数据集中的部分图像构成图像子集,对上述图像子集进行图像分割标注,将标注后的上述图像子集分为医学图像样本集和医学图像验证集;s2:基于上述医学图像样本集训练得到医学图像分割模型;通过上述图像分割模型得到上述医学图像验证集的预测分割结果;s3:基于上述医学图像验证集的图像分割标注,计算上述预测分割结果的预训练损失,用以优化上述医学图像分割模型;s4:基于上述医学图像数据集采用无监督预训练方法得到的数据训练得到图像特征预测模型;上述图像特征预测模型用于输出待测试医学图像的预测图像特征;s5:将上述医学图像数据集的各医学图像分别输入上述医学图像分割模型和上述图像特征预测模型后,在上述医学图像分割模型和上述图像特征预测模型的中间层提取空间大小相同的第一特征图和第二特征图;s6:根据图像分割的图像分割标注,在上述第一特征图和上述第二特征图上为每个语义区域生成语义mask;s7:分别在上述第一特征图和上述第二特征图上用上述语义mask加权平均池化,得到语义区域的第一特征向量和第二特征向量;s8:计算上述第一特征向量和上述第二特征向量之间的余弦相似度;计算上述第一特征向量和上述第二特征向量之间的余弦相似度和目标相似度的差值,作为上述医学图像分割模型的蒸馏误差;s9:通过反向传播算法,合并上述预训练损失和上述蒸馏误差得到上述医学图像分割模型的总损失,并基于上述医学图像分割模型的总损失更新上述医学图像分割模型的多个参数,得到用于医学图像标注的医学图像分割优化模型。
4、上述一种知识蒸馏半自动可视化标注方法还包括:s10:利用上述医学图像分割优化模型给出上述医学图像数据集的其中一个待检测样本的预测标注结果;s11:获取上述医学图像数据集的图像分割标注;根据上述待检测样本的上述预测标注结果对上述图像分割标注进行修正;将上述待检测样本及修正后的最终标注结果输入上述医学图像分割优化模型训练;s12:重复步骤s2~s11,得到最优的上述医学图像分割优化模型,直到上述医学图像数据集的所有图像标注完成。
5、上述分别在上述第一特征图和上述第二特征图上用上述语义mask加权平均池化,得到语义区域的第一特征向量和第二特征向量,通过如下公式计算得到:va=∑i xi*mi/∑i mi;vb=∑j xj*mj/∑j mj;
6、式中,va表示上述第一特征向量;vb表示上述第二特征向量;i表示上述第一特征图的位置标识,j表示上述第二特征图的位置标识;xi表示上述第一特征图的第i个位置上的特征值;xj表示上述第二特征图的j个位置上的特征值;mi表示上述第一特征图第i个位置的注意力权重;mj表示上述第二特征图第j个位置的注意力权重;∑i mi表示第i个上述第一特征图的注意力权重的归一化因子;∑j mj表示第j个上述第二特征图的注意力权重的归一化因子;上述第一特征图/上述第二特征图的上述语义mask基于对应位置的上述注意力权重的归一化因子处理后得到上述注意力权重。
7、上述计算上述预测分割结果的预训练损失采用交叉熵损失函数,表示为:lseg=-∑k yk log(pk);
8、式中,lseg表示上述医学图像分割模型的交叉熵损失;yk表示图像中第k个像素的真实类别;pk表示第k个像素预测为yk类别的概率。
9、上述计算上述第一特征向量和上述第二特征向量之间的余弦相似度,表示为:sim(va,vb)=va·vb/(||va||*||vb||);
10、式中,sim(va,vb)表示上述第一特征向量和上述第二特征向量之间的余弦相似度;va表示上述第一特征向量;vb表示上述第二特征向量;||va||表示上述第一特征向量的向量范数;||vb||表示上述第二特征向量的向量范数。
11、上述计算上述第一特征向量和上述第二特征向量之间的余弦相似度和目标相似度的差值,作为上述医学图像分割模型和上述图像特征预测模型之间的蒸馏误差,表示为:
12、lkd=||sim(va,vb)-sim(ta,tb)||;
13、式中,lkd表示上述医学图像分割模型和上述图像特征预测模型之间的蒸馏误差;va表示上述第一特征向量;vb表示上述第二特征向量;sim(va,vb)表示上述第一特征向量和上述第二特征向量之间的余弦相似度;ta表示上述第一特征向量;tb表示上述第二特征向量;sim(ta,tb)表示上述第一特征向量和上述第二特征向量之间的目标相似度;||sim(va,vb)-sim(ta,tb)||表示上述第一特征向量和上述第二特征向量之间的余弦相似度和目标相似度的差值绝对值。
14、上述基于上述医学图像数据集采用无监督预训练方法得到的数据训练得到图像特征预测模型,包括:
15、随机旋转上述医学图像数据集的所有图像,获得真实角度;将上述医学图像数据集的各图像分别输入预训练的上述图像特征预测模型,得到预测角度;
16、计算上述医学图像数据集的所有图像的上述预测角度与上述真实角度的均方误差,作为预训练损失,表示为:lθ=∑i(θi-θi')^2;
17、式中,θi表示上述医学图像数据集第i个图像的实际旋转角度,θi'表示上述角度预测优化模型输出图像i的上述预测旋转角度;上述预训练损失通过损失反向传播算法更新上述图像特征预测模型的参数。
18、上述通过反向传播算法,合并上述预训练损失和上述蒸馏误差得到上述医学图像分割模型的总损失,通过如下公式计算得到:l=lseg+α*lkd;
19、式中,l表示上述医学图像分割模型的总损失;lseg表示上述医学图像分割模型的预训练损失;lkd表示上述医学图像分割模型的蒸馏误差;α表示上述医学图像分割模型的蒸馏误差权重系数。
20、上述基于上述医学图像分割模型的总损失更新上述医学图像分割模型的多个参数,包括:
21、上述医学图像分割模型的总损失表示为:
22、l=f(x1,x2,...,xn);
23、其中,x1,x2,...,xn表示上述医学图像分割模型的多个参数;
24、采用如下公式表示上述医学图像分割模型的总损失的梯度向量:;
25、式中,表示上述医学图像分割模型的总损失的梯度向量;表示上述医学图像分割模型的各参数的偏导数;
26、采用梯度下降优化算法减小,通过如下公式分别计算更新后的上述医学图像分割模型的多个参数;;
27、式中,表示参数xi(i=1,2,...,n)的新值,表示参数的学习率,是相对于参数的偏导数。
28、一种知识蒸馏半自动可视化标注系统,包括:医学图像采集模块:用于构建医学图像数据集;选择上述医学图像数据集中的部分图像构成图像子集,对上述图像子集进行图像分割标注,将标注后的上述图像子集分为医学图像样本集和医学图像验证集;图像分割预训练模块:用于基于上述医学图像样本集训练得到医学图像分割模型;通过上述图像分割模型得到上述医学图像验证集的预测分割结果;图像分割优化模块:用于基于上述医学图像验证集的图像分割标注,计算上述预测分割结果的预训练损失,用以优化上述医学图像分割模型;图像特征预训练模块:用于基于上述医学图像数据集采用无监督预训练方法得到的数据训练得到图像特征预测模型;上述图像特征预测模型用于输出待测试医学图像的预测图像特征;图像特征优化模块:用于将上述医学图像数据集的各医学图像分别输入上述医学图像分割模型和上述图像特征预测模型后,在上述医学图像分割模型和上述图像特征预测模型的中间层提取空间大小相同的第一特征图和第二特征图;图像语义生成模块:用于根据图像分割的图像分割标注,在上述第一特征图和上述第二特征图上为每个语义区域生成语义mask;图像特征分析模块:用于分别在上述第一特征图和上述第二特征图上用上述语义mask加权平均池化,得到语义区域的第一特征向量和第二特征向量;蒸馏误差分析模块:用于计算上述第一特征向量和上述第二特征向量之间的余弦相似度;计算上述第一特征向量和上述第二特征向量之间的余弦相似度和目标相似度的差值,作为上述医学图像分割模型的蒸馏误差;图像分割修正模块:用于通过反向传播算法,合并上述预训练损失和上述蒸馏误差得到上述医学图像分割模型的总损失,并基于上述医学图像分割模型的总损失更新上述医学图像分割模型的多个参数,得到用于医学图像标注的医学图像分割优化模型。
29、本发明与现有技术相比,具有如下的优点和有益效果:
30、本技术提供一种知识蒸馏半自动可视化标注方法,通过构建医学图像数据集,并从中选择部分数据进行图像分割标注后得到医学图像样本集和医学图像验证集,用于后续医学图像分割模型的初步训练;基于医学图像样本集训练得到医学图像分割模型,然后通过模型得到医学图像验证集的预测分割结果;基于医学图像验证集的图像分割标注,计算预测分割结果的预训练损失,从而用以优化医学图像分割模型;基于医学图像数据集采用无监督预训练方法得到的特征数据训练得到图像特征预测模型,用于输出待测试医学图像的预测图像特征;将医学图像数据集的各医学图像分别输入医学图像分割模型和图像特征预测模型后,在中间层各自提取空间大小相同的第一特征图和第二特征图;根据图像分割的实际标注,在第一特征图和上述第二特征图上为每个语义区域生成语义mask;分别在第一特征图和第二特征图上用语义mask加权平均池化,得到语义区域的第一特征向量和第二特征向量;计算第一特征向量和第二特征向量之间的余弦相似度;计算第一特征向量和第二特征向量之间的余弦相似度和目标相似度的差值,作为医学图像分割模型的蒸馏误差;通过反向传播算法,合并预训练损失和蒸馏误差得到上述医学图像分割模型的总损失,并基于述医学图像分割模型的总损失更新医学图像分割模型的多个参数,得到用于医学图像标注的医学图像分割优化模型。本发明利用医院内现有的数据资源实现自监督知识蒸馏的医学图像标注,减轻了医生工作负担,满足了自动化的协作标注和数据隐私的保护,解决了医生手动标注工作负担重,医学数据标注的效率和质量不高的问题。
- 还没有人留言评论。精彩留言会获得点赞!