一种基于视觉的目标行为意图预测的空地集群协同方法与流程
本发明涉及集群空地协同,尤其涉及一种基于视觉的目标行为意图预测的空地集群协同方法。
背景技术:
1、视觉预测是无人平台感知环境和认知的一种重要手段,且与其他传感器(如激光雷达、毫米波雷达、红外摄像头等)相比,价格低廉,感知的信息具有更丰富的特征,已成为各种无人平台广泛搭载的传感器之一。除此之外,基于视觉的目标行为意图理解与预测,不受场景中通信、定位设备的影响,形成效率更高的基于视觉的空地协同系统。
2、现有的空地集群协同方法,主要关注于空中无人平台在特定高度上对地面进行态势感知,并与地面平台的感知信息进行融合,辅助地面平台进行导航定位。
3、现有的空地协同方法主要通过空中无人机的高视角优势获得地面场景和障碍物信息,辅助地面无人车进行目标定位与路径规划,但是在不同场景下,缺少研究无人机飞行高度和位置拍摄的图像与无人车任务协同时是否是最优的,现有的空地集群协同方法中,空中无人机的飞行高度都是人工设定的,通过人工寻找最优的空地协同方式存在更大的困难,并且无人机需要根据无人车的实时位置与场景自主确定飞行动作。
技术实现思路
1、鉴于上述的分析,本发明实施例旨在提供一种基于视觉的目标行为意图预测的空地集群协同方法,用以解决现有空地协同方法中无人机与无人车协同方式效率低、人工设计困难的技术问题,以便提升空地协同模型在不同场景的适应能力,扩大使用范围。
2、本发明实施例提供了一种基于视觉的目标行为意图预测的空地集群协同方法,包括如下步骤:
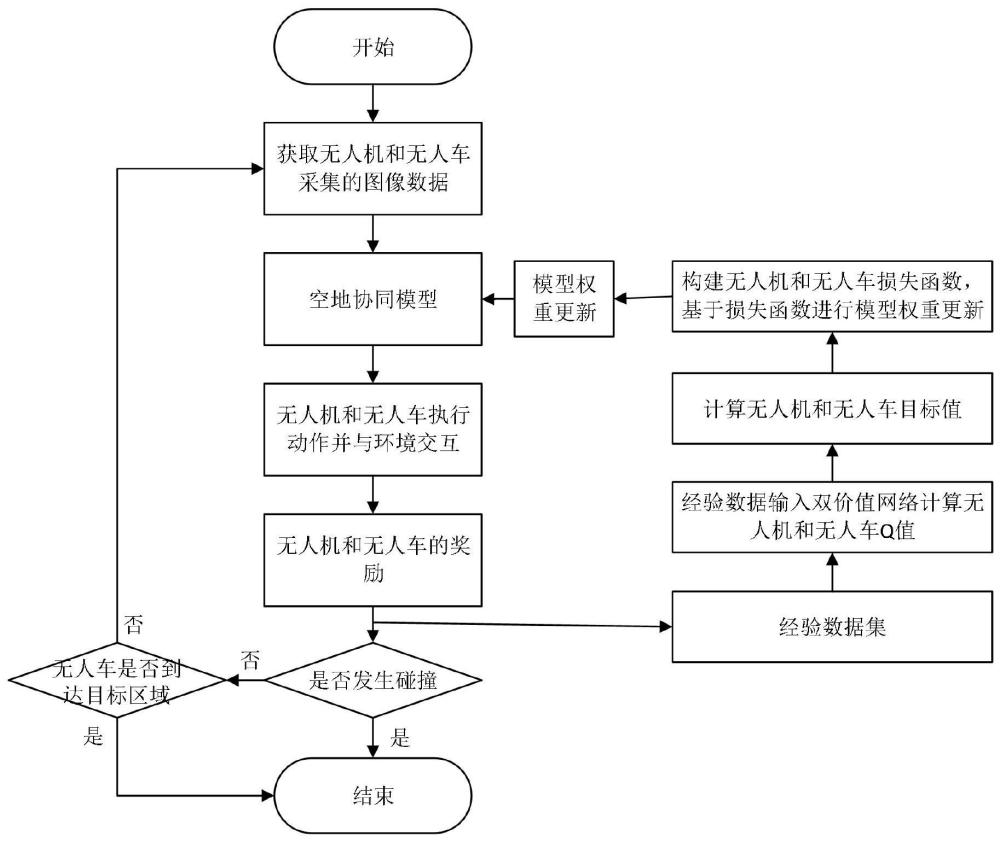
3、对无人机和无人车采集的图像进行预处理,将预处理后的图像作为状态输入空地协同模型得到无人机和无人车动作,将所述无人机和无人车动作作用于无人机和无人车得到下一状态及与环境交互的奖励,将所述状态、动作、奖励和下一状态作为一条经验,从而得到经验数据集;
4、从所述经验数据集中随机选取经验数据,将所述经验数据输入至双价值网络得到无人机和无人车的q值,并基于所述无人机和无人车的q值分别计算无人机和无人车的目标值,基于所述无人机和无人车的目标值和q值构建损失函数对所述空地协同模型权重更新,达到预定训练迭代次数后得到训练好的空地协同模型;
5、与真实环境交互,将实时采集的无人机和无人车图像预处理后作为状态输入所述训练好的空地协同模型,所述空地协同模型输出的无人机和无人车的动作控制无人机和无人车运动。
6、进一步地,所述无人机的采集的图像包括无人机感知的周向图像和对地图像;
7、所述无人车采集的图像为无人车感知到的周向图像。
8、进一步地,所述空地协同模型包括无人机周向感知与地面场景预测模型和无人车周向感知与目标区域搜索模型,两个模型分别通过深度强化神经网络构建;
9、所述无人机周向感知与地面场景预测模型的输入状态为预处理后的所述无人机感知的周向图像和对地图像,输出为无人机的动作;
10、所述无人车周向感知与目标区域搜索模型的输入状态为预处理后的所述无人机感知的对地图像和无人车感知的周向图像,输出为无人车的动作。
11、进一步地,所述一条经验还包括是否为当前回合中的最后一个时间步的标志end,多条经验累积构成经验数据集;
12、每个时间步的一条经验数据ei,如下:
13、
14、
15、其中,为无人机周向状态和对地状态,为无人车周向状态,为无人机和无人车动作,riuav、riugv为无人机和无人车奖励,为无人机周向状态和对地状态的下一状态,为无人机周向状态的下一状态;
16、所述经验数据集为e={e0,e1,...,ei,...};
17、所述一个回合是指从第一个状态开始至无人机或无人车发生碰撞、或无人车达到目标区域,每个回合包括多个时间步,每个时间步对应一条经验。
18、进一步地,所述基于所述无人机q值计算无人机的目标值包括:
19、如果end是当前回合的最后一个时间步,则无人机的目标值yiuav,如下:
20、yiuav=riuav+riugv
21、否则,如果end不是当前回合的最后一个时间步,无人机的目标值如下:
22、
23、
24、其中,γ为折扣因子,q()为某个状态下采取具体动作的期望值,为使得q值最大的动作,为第i个时间步无人机周向感知与地面场景预测模型的参数,为双价值网络中目标网络的参数。
25、进一步地,所述基于双价值网络计算所述无人车目标值包括:
26、如果end是当前回合的最后一个时间步,则无人车的目标值yiugv,如下:
27、yiugv=riugv
28、否则,如果end不是当前回合的最后一个时间步,则无人车的目标值yiugv,如下:
29、
30、
31、其中,为第i个时间步无人车周向感知与目标区域搜索模型的参数,为双价值网络中目标网络的参数。
32、进一步地,无人机的损失函数如下:
33、
34、基于该损失函数利用梯度下降训练更新所述无人机周向感知与地面场景预测模型的权重。
35、进一步地,无人车的损失函数如下:
36、
37、基于该损失函数利用梯度下降训练更新所述无人车周向感知与目标区域搜索模型的权重。
38、进一步地,所述无人机发生碰撞奖励为-1,不发生碰撞奖励为0;
39、所述无人车发生碰撞奖励设置为-1,到达目标位置奖励设置为1;
40、所述无人机动作包括前进、左转、右转、上升、下降和悬停6个动作;
41、所述无人车的动作包括前进、左转、右转和停止4个动作。
42、进一步地,所述无人机周向感知与地面场景预测模型和所述无人车周向感知与目标区域搜索模型分别包括:
43、两个输入层,分别用于接收一种图像,并将图像处理为张量;
44、两个特征提取模块,用于分别提取一种图像的特征;
45、特征融合层,用于将两种图像的特征进行拼接,得到完整特征;
46、全连接层,接收所述完整特征,输出动作。
47、与现有技术相比,本发明至少可实现如下有益效果之一:
48、1、提出了一种基于视觉目标行为意图预测的空地集群协同方法,不依赖于场景中的定位信号,通过感知预测周边其他无人平台的行为意图,实现空地集群协同;
49、2、无人机通过周向感知,实现无人机与其他障碍物之间的避障;
50、3、无人机通过对地方向感知,实现对地面无人车行为意图的理解与预测;
51、4、无人机通过周向感知与对地方向感知相结合,并将无人车的奖励与无人机的奖励相叠加,实现与地面无人车更好的协同方式,包括无人机飞行位置和高度;
52、5、地面无人车通过周向感知,实现无人车与其他障碍物之间的避障;
53、6、地面无人车通过周向感知与无人机对地感知相结合,实现快速的目标区域搜索以抵达目标区域。
54、本发明中,上述各技术方案之间还可以相互组合,以实现更多的优选组合方案。本发明的其他特征和优点将在随后的说明书中阐述,并且,部分优点可从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过说明书以及附图中所特别指出的内容中来实现和获得。
- 还没有人留言评论。精彩留言会获得点赞!