一种基于混洗器联邦差分隐私的矩阵分解推荐方法
本发明属于计算机推荐系统和信息安全领域,涉及一种基于混洗器联邦差分隐私的矩阵分解推荐方法。
背景技术:
1、推荐系统在当今数字化时代具有极其重要的地位和广泛应用,可以帮助企业提高销售额、用户满意度和用户留存率,同时也可以帮助用户节省时间和精力,提高信息获取效率和准确性。但如果这些数据被不当地收集、存储、使用或传播,可能会导致用户的隐私泄露,对用户造成潜在的风险和损失。在这种背景下,推荐系统需要考虑用户的隐私安全。
2、差分隐私是一种通过给数据加入噪音来保护隐私的技术,即使攻击者知道其他数据点的值,也无法确定给定数据点的真实值。该技术提供了数学证明方法来检测和提高隐私保护强度。联邦学习是一种多个参与方协同学习的技术,在保护数据隐私的同时提高模型训练效果。现在主流的联邦学习分为中心模型和本地模型两种,其中本地模型的差分隐私保护中,改变任意一个用户的数据,其对数据集处理结果的影响微乎其微,攻击者无法推测出任何单个用户的隐私信息。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种基于混洗器联邦差分隐私的矩阵分解推荐方法,实现在服务器不可信时推荐模型在安全性和可用性之间的良好平衡。
2、为达到上述目的,本发明提供如下技术方案:
3、一种基于混洗器联邦差分隐私的矩阵分解推荐方法,具体包括以下步骤:
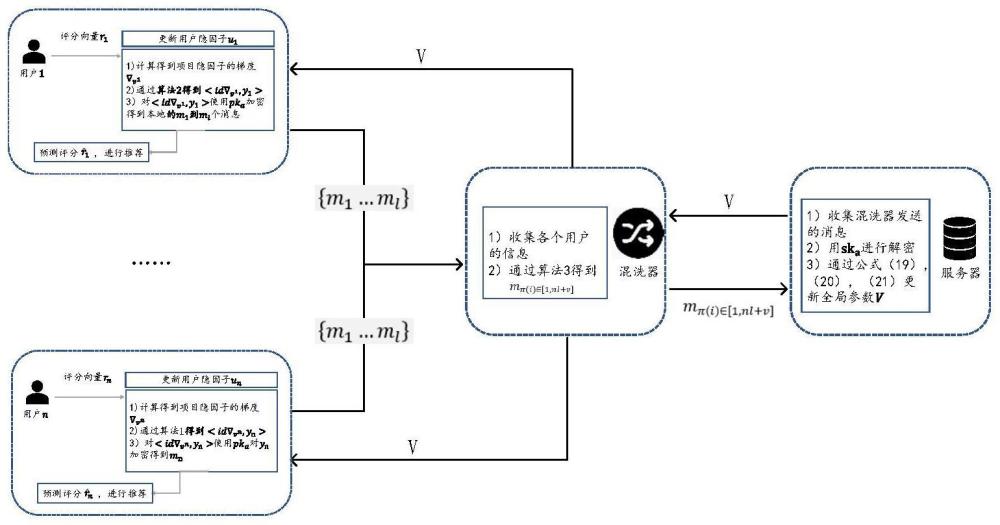
4、s1:用户对项目的评分矩阵其中用表示用户i对项目j的评分;训练的过程分别由服务器s,混洗器s,本地用户i∈[1,n]三方组成;其中n表示用户的个数,m表示项目的个数;
5、s2:随机初始化矩阵其中是用户隐因子矩阵,表示矩阵u的第i行,代表第i个用户的隐因子向量,在本地用户i中保存;是项目隐因子矩阵,表示矩阵v的第j行,代表第j个项目的隐因子向量,在s中更新;d表示隐因子向量的维度;
6、s3:针对所有用户i∈[1,n];用户i收到来自s的vt-1,结合用户i本身评分向量ri、第(t-1)轮的用户隐因子向量通过目标函数l(u,v),求解得到其中t∈[1,t]表示训练的轮数,t代表要更新训练的总轮数;表示梯度;vi表示用户i的项目矩阵;
7、s4:针对所有用户i∈[1,n];每个用户i本地跟新得到项目梯度矩阵为了方便表示将设定等于xi;用户i通过从xi中选取k*l个不重复的梯度索引,其中k个为最大的梯度对应的索引,剩余的k(l-1)个索引从除了最大k个索引之外随机选择;对其中最大的k个索引所对应的梯度使用pm机制进行扰动,其他索引所对应的值从pm机制对0进行扰动的分布中随机选取;进一步对用户i选取的k*l的索引及其对应位置通过pm机制产生的值生成生成idxi和yi;其中πr是对索引进行的一个随机排列操作,用于打乱排列顺序;将idxi和yi平均分成l条记录,得到将yj∈[1,l]通过公钥pka和加密函数e进行加密,将其与idxj∈[1,l]组合生成其中每个加密结果mj∈[1,l]由k个元素;pka为公钥,可以被参与的三方s、s、用户i知道;
8、s5:s收到mi∈[1,n];对f∈[1,d]每个维度中,加入nn,f=np-npm,f个随机噪音;需要个虚假消息进行填充;其中每个消息有k个索引以及对应的随机噪音;进一步对u∈[1,v],得到其中idxn+u为填充k个元素对应的索引,其中idxn+u从nn,f>0中取k个不重复的索引,索引每被选择一次对应nn,f的值减一;是其使用pm机制对0进行扰动的分布中随机选取k个值进行pka加密后的结果;s打乱mi∈[1,nl+v]得到mπ(i)∈[1,nl+v];其中nl个是来自n个用户的消息(每个用户l个);v个是s填充的消息;npm,f为第f个维度来自mi∈[1,n]的数目的总和;np是每个维度需要的总值;d=d*m表示项目矩阵v的维度,也是需要在服务端聚合的的维度;这里,π是对索引进行的一个排列操作,意为打乱顺序
9、s6:s收到mπ(i)∈[1,nl+v],通过sks解密,以及无偏估计,得到然后结合vt-1得到vt;其中sks为私钥,只有s拥有;
10、s7:重复s3到s6一共t次;
11、s8:经过t轮迭代后,根据公式进行预测;当用户需要推荐时,本地ui会与服务器的v矩阵相乘,以生成预测评分,将没有用户i没有评分top-n评分对应的项目推荐给用户i
12、进一步,在所述步骤s3中,求解的步骤具体如下:
13、s31:确定目标函数l(u,v)为:
14、
15、其中ω是在r中已评分的用户-项目对集合,m=|ω|是ω中元素的数量,λ>0是正则化参数;其余参数的含义参考s1和s2
16、s32:根据随机梯度下降(sgd)方法,u的第i个用户向量和v的第j个项目向量在第t次迭代中会如下迭代学习。方程如下:
17、
18、
19、其中η为学习率,t代表训练轮次,和分别为ui和vj的梯度。其中:
20、
21、
22、s33:
23、矩阵分解模型在联邦学习中,推荐服务器从所有用户处收集并将它们组合起来构建梯度矩阵如下:
24、
25、其中是用户i的梯度矩阵,其中:
26、
27、其中j:(i,j)∈ω,代表用户i评过分的项目的集合。
28、进一步,在所述步骤s4中,对xi被选取的部分使用pm机制使其保证差分隐私的步骤具体如下:
29、s41:对要加入噪声的值先裁剪,然后再将其归一化到(-1,1),具体公式如下:
30、
31、其中xi,j是xi被选中要进行pm扰动的梯度,j∈[1,d*m]的一个取值;c表示对梯度裁剪的值。对使用pm机制,具体公式如下:
32、
33、其中∈ld表示隐私预算,分段机制(pm)是一种应用于有界值的扰动机制,以满足差分隐私。它定义如下:
34、分段机制(pm):对于输入值则扰动输出值是从[-cp,cp]中采样得到,其中:
35、
36、的概率密度函数是一个阶梯状的常数函数,表示为:
37、
38、其中,
39、
40、
41、b2=b1+cp-1
42、进一步,在所述步骤s6中,通过sks解密,以及无偏估计,更新得到vt的步骤具体如下:
43、s61:其中通过sks解密的步骤具体如下:
44、
45、s62:其中无偏估计的具体步骤如下:
46、
47、
48、其中k为s4选取的最大索引的数目,为在s中聚合得到的值,为最后无偏估计得到的值,cp为进行pm扰动的裁剪范数。
49、s63:其中vt的具体步骤如下:
50、
51、本发明的有益效果在于:本发明针对联邦学习下差分隐私矩阵分解推荐方法中的隐私泄露问题,结合pm分段机制和混洗模型,采样本地梯度中topk个梯度进行加噪声处理。引入了一个混洗器,在用户,服务器,混洗器三方互不串通的情况下显著减少算法的隐私预算。一方面混洗算法通过重新排列原始数据集,提升隐私保护效果;另一方面,为避免在所有梯度上加入过多噪声,本方法从d个本地梯度中选择topk个梯度(k<<d)进行扰动,从而在增强隐私的同时,显著提高了推荐系统的准确性。本算法在确保推荐模型可用的同时能保证用户隐私数据的安全。
52、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
- 还没有人留言评论。精彩留言会获得点赞!