一种基于人工智能的运行数据管理系统及方法与流程
本发明涉及运行数据管理,具体为一种基于人工智能的运行数据管理系统及方法。
背景技术:
1、在工厂生产过程中,运行数据通常是大量的,传输大量运行数据可能会导致网络拥堵和传输效率低下,使用缓存技术可以有效减少网络拥堵的发生;缓存是一种存储机制,可以存储经常访问的运行数据,以减少对原始数据库的访问次数;缓存可以显著减少直接从磁盘或远程服务器读取数据所需的延迟时间,因为缓存数据位于内存中,可以更快地被访问和读取,将更多数据存储在缓存中可以增加缓存命中的概率,从而减少需要从磁盘或远程服务器读取运行数据的次数,进一步提高系统的响应速度和吞吐量;在系统资源充足且负载较低的情况下,将更多的运行数据存储在缓存中不会导致系统资源的过度使用或负载增加,因此可以充分利用系统资源并提高系统的性能和效率;然而,缓存的大小始终是有限的,如何选择需要存储在缓存中的运行数据成为了一个需要解决的问题。
技术实现思路
1、本发明的目的在于提供一种基于人工智能的运行数据管理系统及方法,以解决上述背景技术中提出的问题。
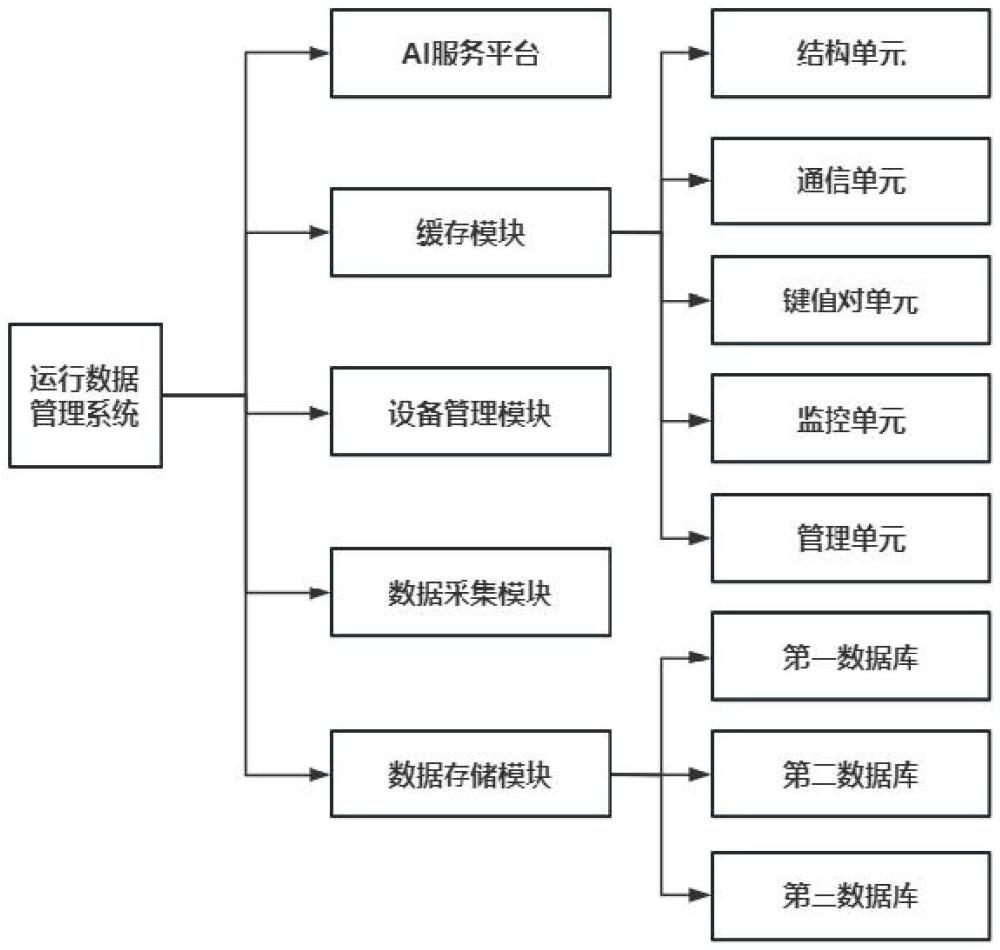
2、在本发明的一个方面,提供一种基于人工智能的运行数据管理系统,包括:缓存模块、数据存储模块、数据采集模块、ai服务平台和设备管理模块;所述缓存模块的输出端与所述设备管理模块的输入端相互连接,用于存储高使用率的运行数据,减少设备管理模块对数据存储模块的请求和访问;所述数据存储模块的输出端与所述缓存模块和所述设备管理模块的输入端相互连接,用于存储设备运行时产生的全部运行数据和运行数据的使用记录;所述数据采集模块的输出端与所述数据存储模块和所述设备管理模块的输入端相互连接,用于获取设备的运行数据;所述ai服务平台与所述数据存储模块相互连接,基于各个运行数据对访问时间的贡献,确定从数据存储模块存放到缓存模块的运行数据;所述设备管理模块基于接收的运行数据,对设备的运行状况进行控制,并对设备进行实时监控,在设备出现异常情况时进行报警。
3、具体地,所述缓存模块包括结构单元、键值对单元、通信单元、监控单元和管理单元;所述结构单元用于确定缓存中运行数据的组织和存储形式;所述键值对单元由键和值组成,所述键用于查找和访问缓存中的运行数据,所述值用于实际存储运行数据;所述通信单元用于和数据存储模块之间进行通信,读取运行数据;所述监控单元监控缓存模块的运行状态,用于发现和解决缓存模块出现的问题;所述管理单元存储缓存一致性算法和缓存淘汰算法,用于更新缓存模块的数据,优化缓存模块的性能。
4、具体地,所述数据存储模块还包括第一数据库单元、第二数据库单元和第三数据库单元,所述第一数据库单元用于存储缓存模块和数据存储模块中运行数据的响应时间,所述第二数据库单元用于存储运行数据的使用率;所述第三数据库单元用于存储运行数据的条件使用率,所述条件使用率指在已知部分运行数据被确定的情况下,其他运行数据的使用率。
5、具体地,所述ai服务平台通过遗传算法确定从数据存储模块存放到缓存模块中的运行数据,以二进制方式对存放到缓存模块中的运行数据和未存放到缓存模块中的运行数据进行编码,经过初始化、选择、交叉和变异,达到终止条件后得到的最大适应度个体作为最优解输出,将最优解对应的运行数据存储到缓存模块中。
6、在本发明的另一个方面,提供一种基于人工智能的运行数据管理方法,包括以下步骤:
7、s5-1,获取运行数据和运行数据的使用记录;
8、s5-2,根据运行数据的使用记录,构建第二和第三数据库;
9、s5-3,通过遗传算法确定需要存储到缓存模块中的运行数据;
10、s5-4,设备管理模块接收运行数据,对设备的运行状况进行控制和监控。
11、在步骤s5-2中,建立第二和第三数据库包括以下步骤:
12、s6-1,以a1、a2、…、an表示不同的运行数据,n表示运行数据的数量;以p1、p2、…、pn分别表示运行数据a1、a2、…、an的使用率,所述运行数据的使用率为各个运行数据的请求次数与总请求次数的比值;以pi,j表示运行数据ai和aj共同的使用率,所述运行数据ai和aj共同的使用率为运行数据ai和aj同时被设备管理模块请求次数与总请求次数的比值;以pi,j,k表示运行数据ai、aj和ak共同的使用率,所述运行数据ai、aj和ak共同的使用率为运行数据ai、aj和ak同时被设备管理模块请求次数与总请求次数的比值;以p1*、p2*、…、pn*分别表示运行数据a1、a2、…、an单独的使用率,所述运行数据单独的使用率为各个运行数据单独被设备管理模块的请求次数与总请求次数的比值;i、j和k的取值范围是区间[1,n]之间的正整数,i、j和k互不相同;将运行数据使用率存储到第二数据库中;
13、s6-2,以ab表示被确定的运行数据,b的取值范围是区间[1,n]之间的正整数;当运行数据ab被确定时,运行数据ai和ab共同的使用率由pi,b变成pi,b/pb,运行数据ai、aj和ab共同的使用率由pi,j,b变成pi,j,b/pb,将运行数据的条件使用率存储到第三数据库中;
14、将后续计算需要的数据存储到数据库中,在用到对应数据时直接从数据库进行调用,减少重复计算;在运行数据的使用记录发生变化时,大部分运行数据的使用率的变化都是由总请求次数变化引起的,可在已有的模型上自动进行更新,简化操作步骤。
15、在步骤s5-2中,通过遗传算法确定需要存储到缓存模块中的运行数据包括以下步骤:
16、s7-1,以二进制方式对运行数据进行编码,得到二进制串,二进制串中每个位对应一个运行数据,每个二进制串对应一个个体;若运行数据被存储到缓存模块中,则运行数据对应二进制串位的值为1,否则运行数据对应二进制串位的值为0;
17、在存储运行数据时,染色体属性为范畴型,通过0和1的区分运行数据是否需要被存储到缓存模块中,以0和1的不同组合对应不同的运行数据存储方式;在搜索过程中引入新的基因组合和变异,可得到新的运行数据存储方式,利于打破局部最优解;
18、s7-2,计算出每个运行数据的贡献值,基于运行数据的贡献值创建初始种群,将迭代次数置为0;
19、初始种群中所有个体都需要满足约束条件,每个个体对应的运行数据存储方式,缓存中运行数据的总数据量应该小于阈值;
20、s7-3,计算种群中每个个体的适应度值;随着迭代次数增加,适应度值会增加;
21、s7-4,选择当前种群中有优势的个体,个体的适应度值与优势成正相关;适应度值越高,个体被选择的概率越大;适应度值低的个体仍然有较低的机会被选择,不会完全抛弃低适应度值个体;
22、s7-5,从选择的个体中,随机选择部分个体进行交叉操作,交换染色体的部分创造新的个体,若新的个体不满足约束条件,则将新的个体从种群中排除,所述不满足约束条件指个体二进制串对应的运行数据量超过了缓存模块的阈值;若新的个体满足约束条件,则成为有效解;
23、s7-5,以低概率对种群中的个体进行变异操作;若变异后得到的新个体不满足约束条件,则将新的个体从种群中排除;若变异后得到的新个体满足约束条件,则成为有效解;
24、s7-6,迭代次数加1,判断是否满足终止条件,若是,则停止算法,基于适应度值最高的个体,按照个体二进制串对应存储运行数据到缓存模块中;若不是,则返回步骤s7-3;所述终止条件指迭代次数达到了设定值。
25、具体地,在步骤s7-2中,所述计算出每个运行数据的贡献值,包括以下步骤:
26、确定每个运行数据的贡献率frei,所有参数从第二数据库和第三数据库中获取;
27、对于式中将其分解为pn(pi,n/pn-pi,1,n/pn-pi,2,n/pn-…-pi,n-1,n/pn),括号中所有比值项都可从第三数据库中查找;
28、运行数据的贡献率由个体贡献率和群体贡献率组成,个体贡献率为运行数据自身单独被设备管理模块请求的概率,群体贡献率为2个或者多个运行数据同时被设备管理模块请求的概率;对于运行数据ai,pi*为其单独被设备管理模块请求的概率;p1是运行数据a1被设备管理模块请求的概率,运行数据ai和运行数据a1一起被设备管理模块请求的只占了运行数据a1被设备管理模块请求的一部分,首先是运行数据a1依概率被设备管理模块请求,接着才是运行数据ai和运行数据a1依概率一起被设备管理模块请求,这里是条件概率模型p{a1}p{ai|a1},所以贡献率frei的第二项是p1pi,1/p1;对于贡献率frei的第三项,由于第二项中已经包括了运行数据a1、a2和a1一起被设备管理模块请求这一情况,因此需要减去重复的情况,为p{a1}p{ai-aia2|a1},这里的i不等于1和2,i等于1或2时,也是类似方式进行分析;推广到全部n个运行数据,就得到了运行数据ai的贡献率frei;
29、计算出每个运行数据的贡献值xi,式中是运行数据ai在数据存储模块中的响应时间,式中是运行数据ai在缓存模块中的响应时间,vi是ai的数据量;
30、是运行数据ai存储在缓存模块中时,响应一次设备管理模块请求减少的时间,为单位数据量减少的响应时间,越大,利用相同的缓存大小减少的响应时间就越多;贡献率frei与运行数据ai被设备管理模块请求的概率成正相关,得到运行数据ai的贡献值,响应次数越多,单次响应单位数据量减少的响应时间越多,贡献值越高。
31、具体地,基于运行数据的贡献值创建初始种群,包括以下步骤:
32、s9-1,将所有运行数据的贡献值xi拼接成一个完整区间,并得到n个子区间,子区间分别为[0,x1]、[x1,x1+x2]、…、[x1+x2+…+xn-1,x1+x2+…+xn],子区间与运行数据一一对应;
33、s9-2,在区间[0,x1+x2+…+xn]生成一个随机数,找到随机数所处的子区间对应的运行数据,将该运行数据的二进制值赋为1;当随机到重复的子区间或者随机数位于区间端点处时,则重新生成随机数进行判断;
34、缓存模块中运行数据的整体贡献值越高,能够减少的响应时间就越多,所以运行数据被选中的概率和贡献值成正比;为了防止陷入局部最优解,不直接选择贡献值最高的运行数据存储到缓存模块中,而是通过随机数使得贡献值低的运行数据也有可能被存储到缓存模块中;
35、s9-3,判断二进制值为1的运行数据的数据量总和是否达到缓存模块的阈值,若未达到阈值,则进入s9-2;若达到阈值,则得到一个个体,进入s9-4;
36、s9-4,重复执行步骤s9-2和s9-3,直到获得l个不同个体,l是初始种群的规模。
37、具体地,计算种群中每个个体的适应度值包括以下步骤:
38、基于个体的二进制串,找到二进制值为1的运行数据ab,这些运行数据已被确定,以py表示被确定的运行数据的使用率,表示未被确定的运行数据的使用率,将未被确定的运行数据的使用率全部逐个进行置零,当为零且出现在分母上时,仍然可以进行计算;被确定的运行数据的使用率py保持不变,按照贡献率freb的计算公式计算得到条件贡献率cfreb,在贡献率freb的计算公式中,每一项至多存在一个运行数据的使用率被置零;
39、当运行数据未被存储到缓存中时,对响应时间没有任何贡献,因此通过将未被确定的运行数据的使用率全部置零实现,当为零且出现在分母上时,仍然可以进行计算;
40、例如,对于公式当p2和pn被逐个进行置零时,对于项p2被置零,通过实际意义可以知道p1,2必定小于p2,因此小于1,由于无穷小乘上另一个无穷小或者常数仍然为无穷小,则为0;对于项pn被置为0,p2不被置零,每一项至多存在一个运行数据的使用率被置零,将其分解为pn(p1,n/pn-p1,2,n/pn-p1,3,n/pn-…-p1,n-1,n/pn),同理可知,p1,n/pn、p1,2,n/pn、p1,3,n/pn、…、p1,n-1,n/pn全部都是小于1的常数或者无穷小,而n是常数,因为运行数据的数量不可能有无限多个,有限个无穷小或者常数相加减后仍然是无穷小或者常数,因此为0,对于项不作出任何改变,按照从数据库中查找的值进行计算;
41、计算出二进制值为1的运行数据ab的条件贡献值cxb,将所有二进制值为1的运行数据ab的条件贡献值cxb相加得到个体的适应度值;每个存储在缓存中的运行数据都能够减少响应时间,将缓存中运行数据的贡献值相加得到一个完整的个体适应度值。
42、与现有技术相比,本发明所达到的有益效果是:将运行数据存储在缓存中,能够显著提高系统性能,减少从远程服务器获取数据的次数,缓存数据存储在本地,访问速度更快,响应时间更短;通过遗传算法确定需要存储到缓存中的运行数据,在一个大型搜索空间内寻找最优解,利于找到全局最优解,对初始解的依赖性较小,即使初始解较差,也能通过选择、交叉和变异操作找到最优解,具有一定的自适应性、鲁棒性和容错性。
- 还没有人留言评论。精彩留言会获得点赞!